series_outliers()
적용 대상: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
계열의 이상 점수를 채점합니다.
함수는 동적 숫자 배열이 있는 식을 입력으로 사용하고 동일한 길이의 동적 숫자 배열을 생성합니다. 배열의 각 값은 "Tukey의 테스트"를 사용하여 가능한 변칙의 점수를 나타냅니다. 입력의 동일한 요소에서 1.5보다 큰 값은 상승 변칙을 나타냅니다. -1.5보다 작은 값은 감소 변칙을 나타냅니다.
구문
series_outliers(series [, kind ] [, ignore_val ] [ , min_percentile ] [, max_percentile ])
구문 규칙에 대해 자세히 알아봅니다.
매개 변수
| 이름 | Type | 필수 | 설명 |
|---|---|---|---|
| 시리즈 | dynamic |
✔️ | 숫자 값의 배열입니다. |
| kind | string |
이상값 검색에 사용할 알고리즘입니다. 지원되는 "tukey"옵션은 기존의 "Tukey"이며 "ctukey"사용자 지정 "Tukey"입니다. 기본값은 "ctukey"입니다. |
|
| ignore_val | int, long 또는 real | 계열에서 누락된 값을 나타내는 숫자 값입니다. 기본값은 null)입니다double(. null 및 무시 값의 점수가 .로 0설정됩니다. |
|
| min_percentile | int, long 또는 real | 일반 분위수 간 범위를 계산하는 데 사용할 최소 백분위수입니다. 기본값은 10입니다. 값은 범위에 [2.0, 98.0]있어야 합니다. 이 매개 변수는 종류에만 관련됩니다."ctukey" |
|
| max_percentile | int, long 또는 real | 일반 분위수 간 범위를 계산하는 데 사용할 최대 백분위수입니다. 기본값은 90입니다. 값은 범위에 [2.0, 98.0]있어야 합니다. 이 매개 변수는 종류에만 관련됩니다."ctukey" |
다음 표에서는 차이점과 "ctukey"다음의 "tukey" 차이점을 설명합니다.
| 알고리즘 | 기본 분위수 범위 | 사용자 지정 변위치 범위 지원 |
|---|---|---|
"tukey" |
25% / 75% | 아니요 |
"ctukey" |
10% / 90% | 예 |
팁
이 함수를 사용하는 가장 좋은 방법은 메이크 시리즈 연산자의 결과에 적용하는 것입니다.
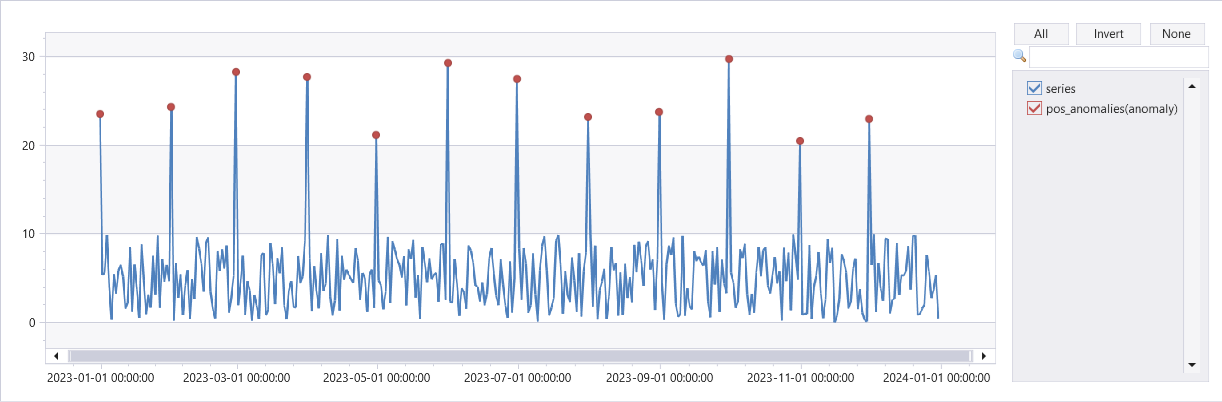
예시
range x from 0 to 364 step 1
| extend t = datetime(2023-01-01) + 1d*x
| extend y = rand() * 10
| extend y = iff(monthofyear(t) != monthofyear(prev(t)), y+20, y) // generate a sample series with outliers at first day of each month
| summarize t = make_list(t), series = make_list(y)
| extend outliers=series_outliers(series)
| extend pos_anomalies = array_iff(series_greater_equals(outliers, 1.5), 1, 0)
| render anomalychart with(xcolumn=t, ycolumns=series, anomalycolumns=pos_anomalies)