dcount()(집계 함수)
적용 대상: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
요약 그룹의 스칼라 식에서 가져온 고유 값 수의 예상값을 계산합니다.
Null 값은 무시되며 계산에 영향을 주지 않습니다.
참고 항목
dcount() 집계 함수는 주로 거대한 집합의 카디널리티를 예측하는 데 유용합니다. 성능에 대한 정확도를 거래하며 실행마다 다른 결과를 반환할 수 있습니다. 입력 순서가 출력에 영향을 미칠 수 있습니다.
참고 항목
이 함수는 summarize 연산자와 함께 사용됩니다.
구문
dcount(expr[, 정확도])
구문 규칙에 대해 자세히 알아봅니다.
매개 변수
| 이름 | Type | 필수 | 설명 |
|---|---|---|---|
| expr | string |
✔️ | 고유 값을 계산할 입력입니다. |
| 정밀 | int |
요청된 추정 정확도를 정의하는 값입니다. 기본값은 1입니다. 지원되는 값에 대한 예측 정확도를 참조하세요. |
반품
그룹에서 expr의 고유 값 수에 대한 추정값을 반환합니다.
예시
이 예제에서는 각 상태에서 발생한 Storm 이벤트의 유형 수를 보여 줍니다.
StormEvents
| summarize DifferentEvents=dcount(EventType) by State
| order by DifferentEvents
표시된 결과 테이블에는 처음 10개의 행만 포함됩니다.
| State(상태) | DifferentEvents |
|---|---|
| TEXAS | 27 |
| 캘리포니아 | 26 |
| PENNSYLVANIA | 25 |
| 그루지야 | 24 |
| 일리노이주 | 23 |
| MARYLAND | 23 |
| 노스캐롤라이나주 | 23 |
| 미시간 | 22 |
| 플로리다 | 22 |
| OREGON | 21 |
| KANSAS | 21 |
| ... | ... |
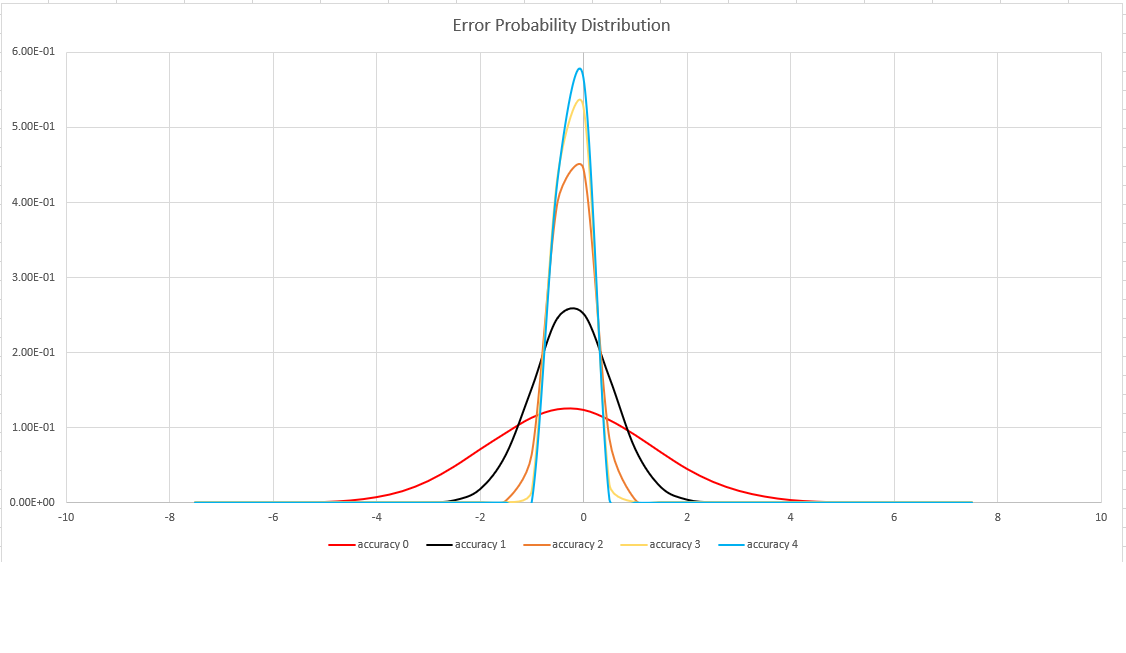
추정 정확도
이 함수는 집합 카디널리티의 확률적 추정을 수행하는 HLL(HyperLogLog) 알고리즘의 변형을 사용합니다. 알고리즘은 메모리 크기당 정확도 및 실행 시간의 균형을 맞추는 데 사용할 수 있는 "노브"를 제공합니다.
| 정확도(Accuracy) | 오류(%) | 항목 수 |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0.8 | 214 |
| 2 | 0.4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
참고 항목
"항목 수" 열은 HLL 구현에서 1 바이트 카운터의 수입니다.
알고리즘에는 집합 카디널리티가 충분히 작은 경우 완벽한 개수(오류 0개)를 수행하기 위한 몇 가지 프로비저닝이 포함됩니다.
- 정확도 수준이
1이면 1000개의 값이 반환됩니다. - 정확도 수준이
2이면 8000개의 값이 반환됩니다.
바인딩된 오류는 이론적 바운드가 아닌 확률입니다. 값은 오류 분포의 표준 편차(시그마)이며 예측의 99.7%는 3 x 시그마 미만의 상대 오차를 갖습니다.
다음 이미지는 지원되는 모든 정확도 설정에 대한 상대 예측 오류의 확률 분포 함수를 백분율로 보여 줍니다.