SDOH 데이터 세트 - 변환(프리뷰)에서 공개 데이터 세트 준비
[이 문서는 시험판 문서이며 변경될 수 있습니다.]
SDOH 공개 데이터 세트에는 정부 기관 및 대학과 같은 기타 공식 출처에서 발행한 집계된 SDOH(의료 서비스의 사회적 결정 요인) 데이터가 포함되어 있습니다. 이러한 데이터 세트는 주, 카운티 또는 우편 번호와 같은 지리적 수준에서 다양한 SDOH 매개 변수를 통합합니다. SDOH 데이터 세트 - 변환(프리뷰)을 사용하면 이러한 지리 수준 데이터 세트를 CSV(쉼표로 구분된 값) 또는 XLSX(Excel Open XML 스프레드시트) 형식으로 수집하고 사용자 지정 데이터 모델로 정규화할 수 있습니다.
프리뷰 릴리스는 브론즈, 실버 및 골드 레이크하우스 레이어를 통해 데이터 파이프라인을 실행하고 데이터 변환을 탐색하는 데 도움이 되도록 다양한 SDOH 도메인에서 다음과 같은 8가지 샘플 SDOH 데이터 세트를 제공합니다.
USDA의 Food Environment Atlas: 상점/레스토랑 근접성, 식품 가격, 영양 지원 프로그램 및 지역 사회 특성과 같은 요소를 포함합니다. 이러한 요인은 음식 선택, 식단의 질, 그리고 궁극적으로 건강 결과에 영향을 미칩니다.
USDA의 Rural Atlas: 사람, 직업, 카운티 분류, 소득 및 재향 군인과 같은 사회 경제적 요인에 대한 통계를 제공합니다.
AHRQ의 SDOH 데이터: 5가지 주요 SDOH 도메인에 대한 세부 정보를 제공합니다.
- 연령, 인종/민족, 군복무 여부와 같은 사회적 컨텍스트.
- 소득, 실업률과 같은 경제적 컨텍스트.
- 교육 서비스업
- 주택, 범죄, 교통과 같은 물리적 인프라.
- 건강 보험과 같은 의료 컨텍스트.
위치 경제성 지수: 이웃 수준에서 가구 주택 및 교통비를 추정합니다.
환경 정의 지수: 여러 출처의 데이터를 모아 모든 인구 조사 구역에서 건강에 미치는 환경적 불의의 누적 영향을 순위를 매깁니다.
ACS 교육 성취도: 진행 중인 대규모 인구 통계 조사에서 파생된 지리적 영역에 대한 교육 인사이트를 제공합니다.
Australian SEIFA: 소득, 교육, 고용 및 주택과 같은 호주 인구 조사 데이터를 결합하여 지역의 사회 경제적 특성을 요약합니다.
영국 박탈 지수: 다양한 차원을 포괄하는 소규모 지역의 빈곤을 평가하기 위해 영국 내에서 널리 사용되는 사회 경제적 척도입니다.
여기서
- USDA: United States Department of Agriculture
- AHRQ: Agency for Healthcare Research and Quality
- ACS: American Community Survey
- SEIFA: Socio-Economic Indexes for Areas
중요
이러한 데이터 세트는 단순한 샘플이 아니라 각 조직에서 게시한 완전한 실제 데이터 세트입니다. 해당 지역의 SDOH 프로파일을 정확하게 표현합니다. 연방 기관의 공식 간행물이므로 수정할 때 주의하십시오.
폴더 구조
SDOH 데이터 세트 - 변환(프리뷰)의 랜딩 존은 Ingest, Process, Failed의 세 가지 폴더로 구성됩니다. 이러한 폴더에 대한 자세한 내용은 통합 폴더 구조를 참조하세요.
수집하기 전에 SDOH 데이터 세트 준비
SDOH 공개 데이터 세트를 수집하기 전에 성공적으로 수집할 준비가 되었는지 확인합니다. 다음 섹션에서는 두 가지 시나리오에 대해 간략하게 설명합니다.
- 자체 데이터 세트 사용
- 샘플 데이터 세트 사용
자체 데이터 세트 사용
SDOH 공개 데이터 세트는 형식, 볼륨 및 구조 면에서 게시 조직마다 크게 다릅니다. 캡처된 정보를 수집하고 교환하기 위한 확립된 표준이 부족합니다. 따라서 데이터 모델 내에서 표현하기 전에 공통 모양으로 통합하는 것이 중요합니다.
선택한 SDOH 공개 데이터 세트를 수집하고 변환하려면 다음 세 가지 주요 정보를 추가합니다.
레이아웃: SDOH 데이터를 캡처하기 위한 표준 코드 세트가 없기 때문에 각 필드의 의미를 이해하는 것이 어렵습니다. 이 문제를 해결하려면 레이아웃이라는 새 시트를 추가하여 데이터 세트에 대한 데이터 사전을 만듭니다(데이터 세트가 XLSX 형식인 경우). 또는 다음 예에 표시된 열이 포함된 새 CSV 파일을 만듭니다(데이터 세트가 CSV 형식인 경우).
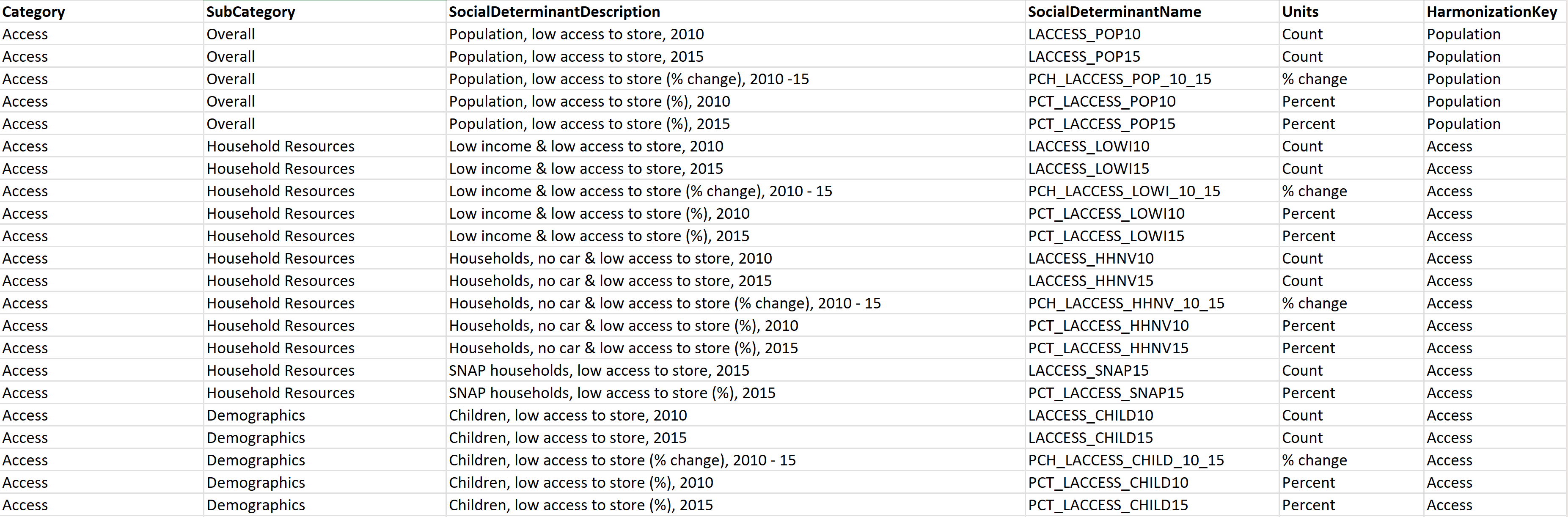
DataSetMetadata: SDOH 데이터 세트는 서로 다른 게시자에서 제공되므로 데이터 세트에 대한 주요 세부 정보를 기록하는 것이 중요합니다. DataSetMetadata라는 새 시트를 추가하거나(데이터 세트가 XLSX 형식인 경우) 다음 예제에 표시된 열을 사용하여 새 CSV 파일(데이터 세트가 CSV 형식인 경우)을 만듭니다.

LocationConfiguration: 지역마다 다양한 방식으로 위치 데이터를 정의하고 구성합니다. SDOH 파이프라인이 데이터 세트의 지리적 구조를 이해하는 데 도움이 되도록 LocationConfiguration(데이터 세트가 XLSX 형식인 경우)이라는 새 시트를 추가하거나 다음 예제와 같이 표시된 열을 사용하여 새 CSV 파일(데이터 세트가 CSV 형식인 경우)을 만듭니다.
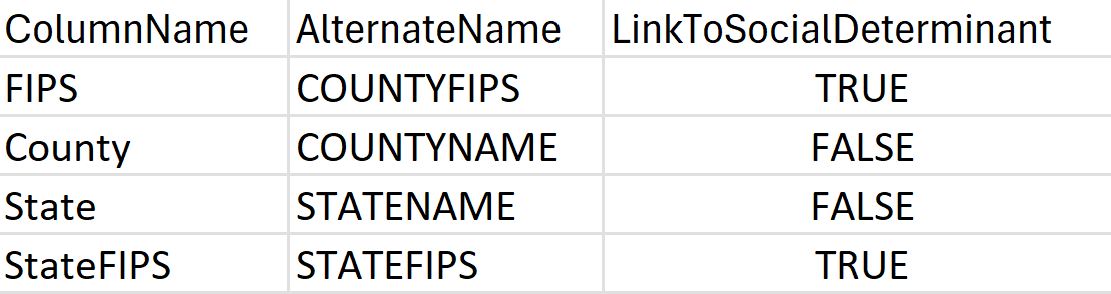



또한:
- 샘플 SDOH 데이터 세트의 구조를 참조하여 사회적 결정 요인 범주, 메타데이터 및 조화 키와 같은 필수 정보를 채울 수 있습니다.
- 원본 데이터 세트에서 특정 필드를 수집하지 않으려면 데이터 시트에서 해당 필드를 제거하거나 레이아웃 시트에서 해당 세부 정보를 비워 둡니다. 두 경우 모두 실버 데이터 모델에 포함되지 않습니다.
- 이름, 게시 날짜 및 게시자가 동일한 데이터 세트는 중복으로 처리됩니다.
샘플 데이터 세트 사용
의료 데이터 솔루션과 함께 제공되는 샘플 SDOH 데이터 세트는 모든 필수 구성 요소 정보로 미리 채워져 있으며 OneLake에서 사용할 수 있습니다. 로컬에서 추출할 수 있습니다.
Fabric 작업 영역에 데이터 세트 업로드
데이터 세트가 준비되면 다음 두 가지 옵션 중 하나를 선택하여 업로드합니다. SDOH 데이터 세트 - 변환(프리뷰)와 함께 제공되는 샘플 데이터 세트를 사용하는 경우에만 옵션 2를 사용할 수 있습니다.
- 옵션 1: 데이터 세트를 수동으로 업로드합니다.
- 옵션 2: 스크립트를 사용하여 데이터 세트를 업로드합니다.
데이터 세트 수동 업로드
의료 데이터 솔루션 환경에서 healthcare#_msft_bronze 레이크하우스를 선택합니다.
Ingest 폴더를 엽니다. 자세한 내용은 폴더 설명을 참조하십시오.
폴더 이름 옆에 있는 줄임표(...)를 선택하고 폴더 업로드를 선택하세요.
로컬 시스템에서 데이터 세트를 업로드합니다. OneLake 파일 탐색기를 사용하여 다음 경로
<workspace name>\healthcare#.HealthDataManager\DMHSampleData\8SdohPublicDataset에서 데이터 세트를 찾습니다.Ingest 폴더를 새로 고칩니다. 이제 SDOH 하위 폴더 내에 데이터 세트 파일이 표시됩니다.
스크립트를 사용하여 데이터 세트를 업로드합니다
중요
제공된 샘플 데이터 세트를 사용하는 경우에만 이 옵션을 사용합니다.
의료 데이터 솔루션 Fabric 작업 영역으로 이동하세요.
+ 새 항목을 선택합니다.
새 항목 창에서 Notebook을 검색하여 선택합니다.
다음 코드 조각을 Notebook에 복사합니다.
workspace_id = '<workspace_id>' # Workspace ID. Retrieve the value from the healthcare#_msft_config_notebook. one_lake_endpoint = "<OneLake_endpoint>" # OneLake endpoint. Retrieve the value from the healthcare#_msft_config_notebook. solution_id = "<solution_id>" # Solution ID. Retrieve the value from the healthcare#_msft_config_notebook. bronze_lakehouse_id = "<bronze_lakehouse_id>" # To locate the bronze lakehouse ID, open the bronze lakehouse and check the URL in the browser's address bar: https://{baseurl}/lakehouse/{GUID}/details). The {GUID} value in the URL is the bronze lakehouse ID. def copy_source_files_and_folders(source_path, destination_path): # List the contents of the source directory source_contents = mssparkutils.fs.ls(source_path) # List the contents of the destination directory try: destination_contents = mssparkutils.fs.ls(destination_path) destination_files = {item.path.split('/')[-1]: item.path for item in destination_contents} except Exception as e: print(f"Destination path {destination_path} does not exist or is empty. Creating the path.") destination_files = {} mssparkutils.fs.mkdirs(destination_path) # Copy each item inside the source directory to the destination directory for item in source_contents: item_path = item.path item_name = item_path.split('/')[-1] destination_item_path = f"{destination_path}/{item_name}" if item.isDir: # Recursively copy the contents of the directory copy_source_files_and_folders(item_path, destination_item_path) else: if item_name in destination_files: print(f"File already exists, skipping: {destination_item_path}") else: print(f"Creating new file: {destination_item_path}") mssparkutils.fs.cp(item_path, destination_item_path, recurse=True) # Define the source and destination paths with placeholder values data_manager_solution_path = f"abfss://{workspace_id}@{one_lake_endpoint}/{solution_id}" data_manager_sample_data_path = f"{data_manager_solution_path}/DMHSampleData" sdoh_csv_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/csv" sdoh_xlsx_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/xlsx" destination_path_csv = f"abfss://{workspace_id}@{one_lake_endpoint}/{bronze_lakehouse_id}/Files/Ingest/SDOH/CSV" destination_path_xlsx = f"abfss://{workspace_id}@{one_lake_endpoint}/{bronze_lakehouse_id}/Files/Ingest/SDOH/XLSX" # Copy the files along with their parent folders copy_source_files_and_folders(sdoh_csv_data_path, destination_path_csv) copy_source_files_and_folders(sdoh_xlsx_data_path, destination_path_xlsx)Notebook을 실행합니다. 이제 샘플 SDOH 데이터 세트가 Ingest 폴더 내의 지정된 위치로 이동합니다.
이제 SDOH 데이터 세트를 수집할 준비가 되었습니다.