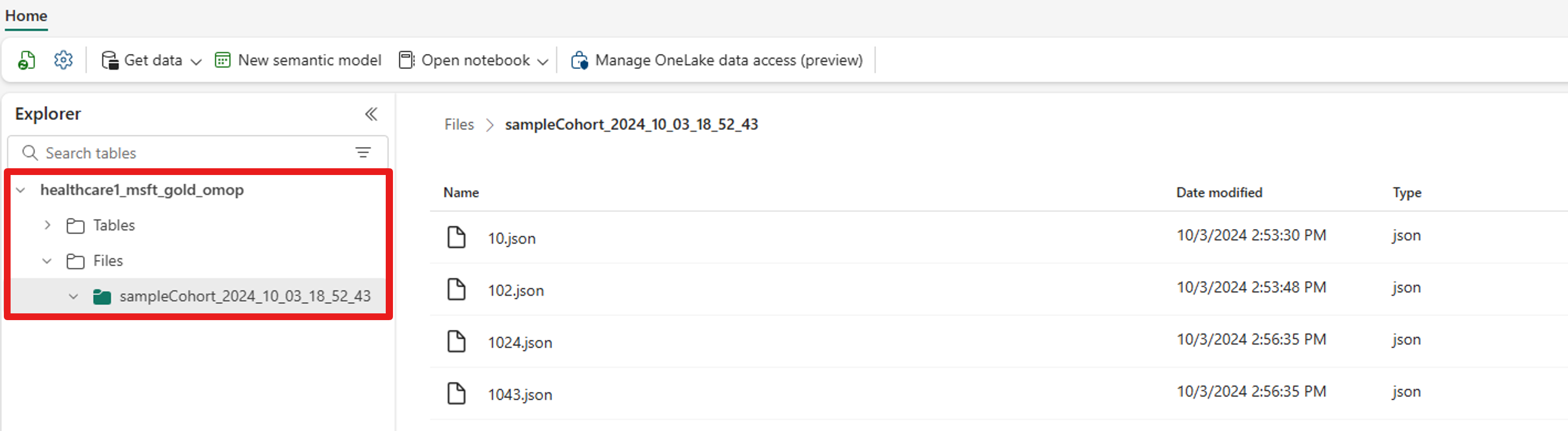
코호트 검색 및 구축(프리뷰)에서 생성형 AI를 사용하여 환자 코호트 빌드
[이 문서는 시험판 문서이며 변경될 수 있습니다.]
코호트 검색 및 구축(프리뷰)은 생성형 AI를 사용하여 고급 프로그래밍 기술 없이도 환자 코호트를 더 빠르고 쉽게 구축할 수 있도록 지원합니다. 코호트는 다음과 같은 다양한 목적으로 사용할 수 있습니다.
- 건강 추세 연구
- 품질 평가
- 임상 시험
- 기록 연구
생성형 AI로 쿼리를 작성하는 것은 반복적인 프로세스입니다. 다음은 개략적인 개요입니다.
- 자연어 입력을 사용하여 쿼리 기준 생성: 생성형 AI Copilot 환경에서 자연어를 입력하여 대상 환자 그룹을 설명합니다.
- 쿼리 기준 구체화: 더 많은 자연어 입력을 제공하거나 조건을 수동으로 편집하여 필요에 따라 쿼리를 조정합니다.
- 쿼리 실행: 쿼리를 실행하여 코호트에 대한 환자 검색의 효과를 평가합니다.
- 반복: 결과를 평가하고 필요에 따라 프로세스를 반복합니다.
- 데이터 저장: 최종 코호트 데이터를 레이크하우스에 저장합니다.
쿼리 생성 프로세스를 살펴보기 전에 의료 데이터 솔루션에서 코호트 검색 및 구축(프리뷰) 설정의 단계를 완료하세요.
자연어 입력으로 쿼리 생성
코호트 검색 및 구축(프리뷰)는 AI를 사용하여 쿼리를 디자인하는 데 도움을 줍니다.
의료 데이터 솔루션 환경에서 의료 코호트 항목을 엽니다.
오른쪽 창에서 쿼리 작성기를 선택합니다.
프리뷰 약관과 AI 투명성 참고 사항을 검토한 후 시작하기를 선택하세요.
쿼리 작성기 텍스트 상자에 질문을 입력한 다음 종이 비행기 아이콘을 선택합니다. 채팅 창에 몇 가지 예가 표시되는 것을 볼 수 있습니다. 입력할 수 있는 내용에 대한 더 많은 예를 보려면 자연어 입력을 사용하여 데이터 필터링을 참조하세요.
쿼리 기준을 검토합니다. 필요에 따라 기준을 수동으로 편집할 수도 있습니다. 원하는 결과를 얻을 때까지 4단계와 5단계를 반복합니다.
자연어 입력을 사용하여 데이터 필터링
이 예제에서는 자연어를 사용하여 진단, 약물, 인구 통계, 프로시저, 인카운터 및 날짜를 기반으로 환자 데이터를 필터링하는 방법을 보여줍니다.
진단 필터링
- 단일 조건: 담석 진단을 받은 환자를 찾습니다.
- 여러 조건: 고콜레스테롤 및 당뇨병 진단을 받은 환자를 식별합니다.
약물 이력 필터링
- 단일 약물: 리시노프릴 10mg 경구용 정제를 복용한 환자를 검색합니다.
- 여러 약물: 1ml 에포에틴 알파 4000 단위 주사를 받고 프레드니손도 복용한 환자를 찾습니다.
인구 통계학적 필터링
- 35세 이상의 여성 환자를 검색합니다.
- 아프리카계 미국인 환자를 찾습니다.
- 히스패닉 환자를 찾습니다.
프로시저 필터링
- 충수 절제술을 받은 환자를 찾습니다.
인카운터 필터링
- 2020년 1월 1일 이후에 충수 절제술을 받은 환자를 식별합니다.
날짜 필터링
- 2023년 7월 10일 이후에 프레드니손을 복용한 환자를 회수합니다.
관찰 필터링
- 출혈이 있는 환자를 찾습니다.
측정 필터링
- 혈액에 사이코신이 있는 환자를 찾습니다.
교차 조건 필터링
Patients with {Diagnosis} x {Medication} x {Demographics} x {Procedure} x {Encounter}와 같이 여러 조건을 결합할 수 있습니다. 예:
- 1ml 에포에틴 알파 4000 단위 주사를 받고 프레드니손을 복용한 30세 이상 환자.
- 간질 및 천식 진단을 받은 환자 또는 당뇨병만 진단된 환자.
쿼리 조건을 수동으로 구체화합니다
코호트 검색 및 구축(프리뷰)은 AI를 사용하여 자연어 요청을 쿼리 조건으로 변환합니다. 그러나 결과의 정확도가 다를 수 있습니다. AI가 생성한 쿼리를 수동으로 조정하거나 기준 빌더를 사용하여 새 쿼리를 작성할 수 있습니다. 기준 빌더는 레이크하우스에 연결된 데이터 세트를 기반으로 필드를 자동으로 채웁니다. 기준을 설정하고, 연산자를 선택하고, 값을 지정하여 검색을 구체화할 수 있습니다. 더 복잡한 검색의 경우 AND 또는 OR연산자를 사용하여 여러 조건을 결합합니다.
기준 캔버스에서 연필 아이콘을 선택합니다.
기준 빌더 창에서 기준을 구체화하십시오. 기준 빌더 대화 상자는 필터링에 사용할 수 있는 데이터 필드를 탐색하는 데 유용한 도구입니다. 예를 들어 생년월일, 개념 코드별 상태 또는 성별과 같은 필드를 확장하여 환자 데이터를 필터링할 수 있습니다.
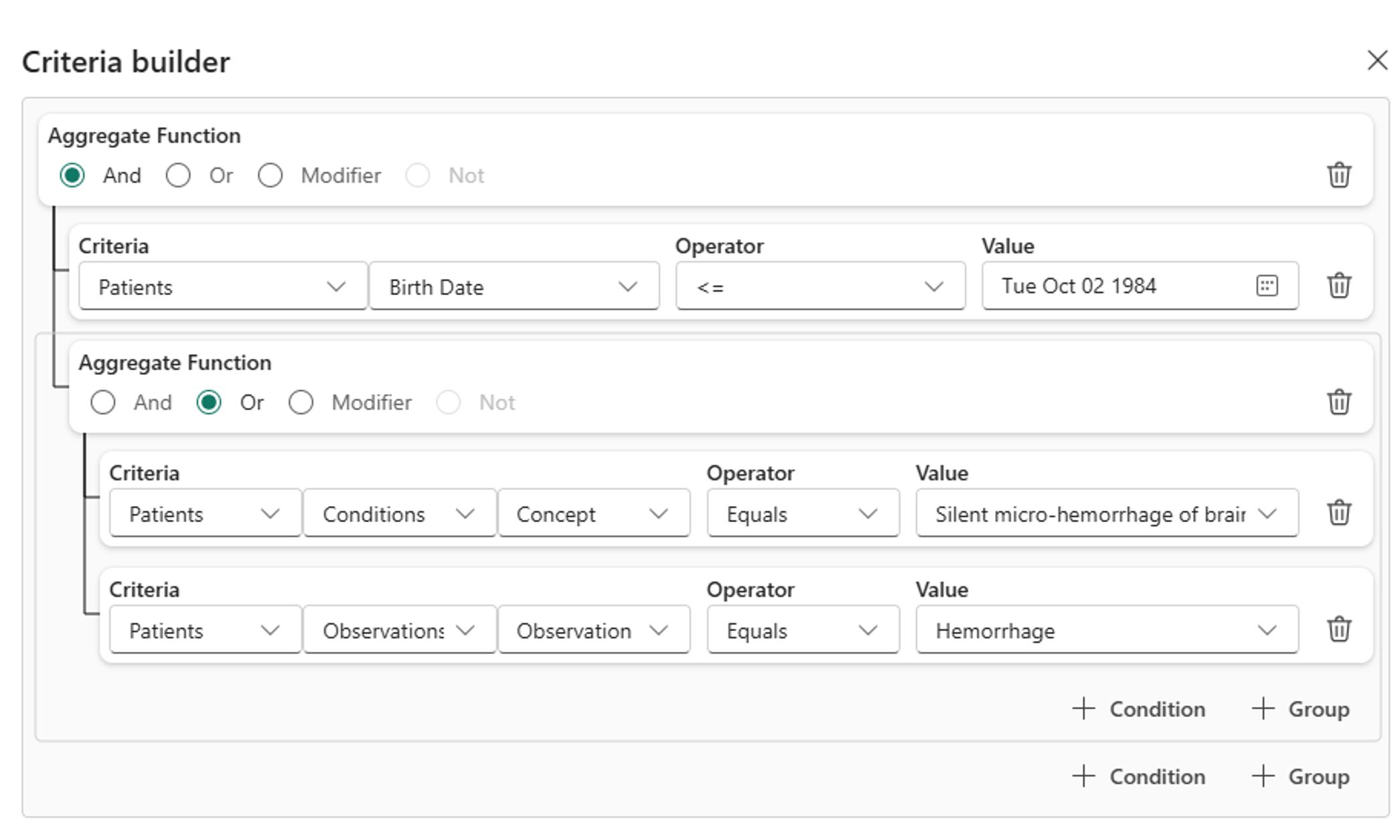
기준 업데이트를 선택합니다.
쿼리 실행
쿼리를 실행하는 방법에는 두 가지가 있습니다.
- 기준 캔버스에서 쿼리 실행 버튼을 선택합니다 . 코호트 검색 및 구축(프리뷰)는 쿼리 기준에 따라 SQL 코드를 생성하고 데이터 세트에 대해 SQL 쿼리를 실행하여 코호트를 만듭니다.
OR
- 상단 도구 모음에서 실행 드롭다운 목록을 확장하고 SQL 생성, SQL 실행, SQL 생성 및 실행 중 하나를 선택합니다.
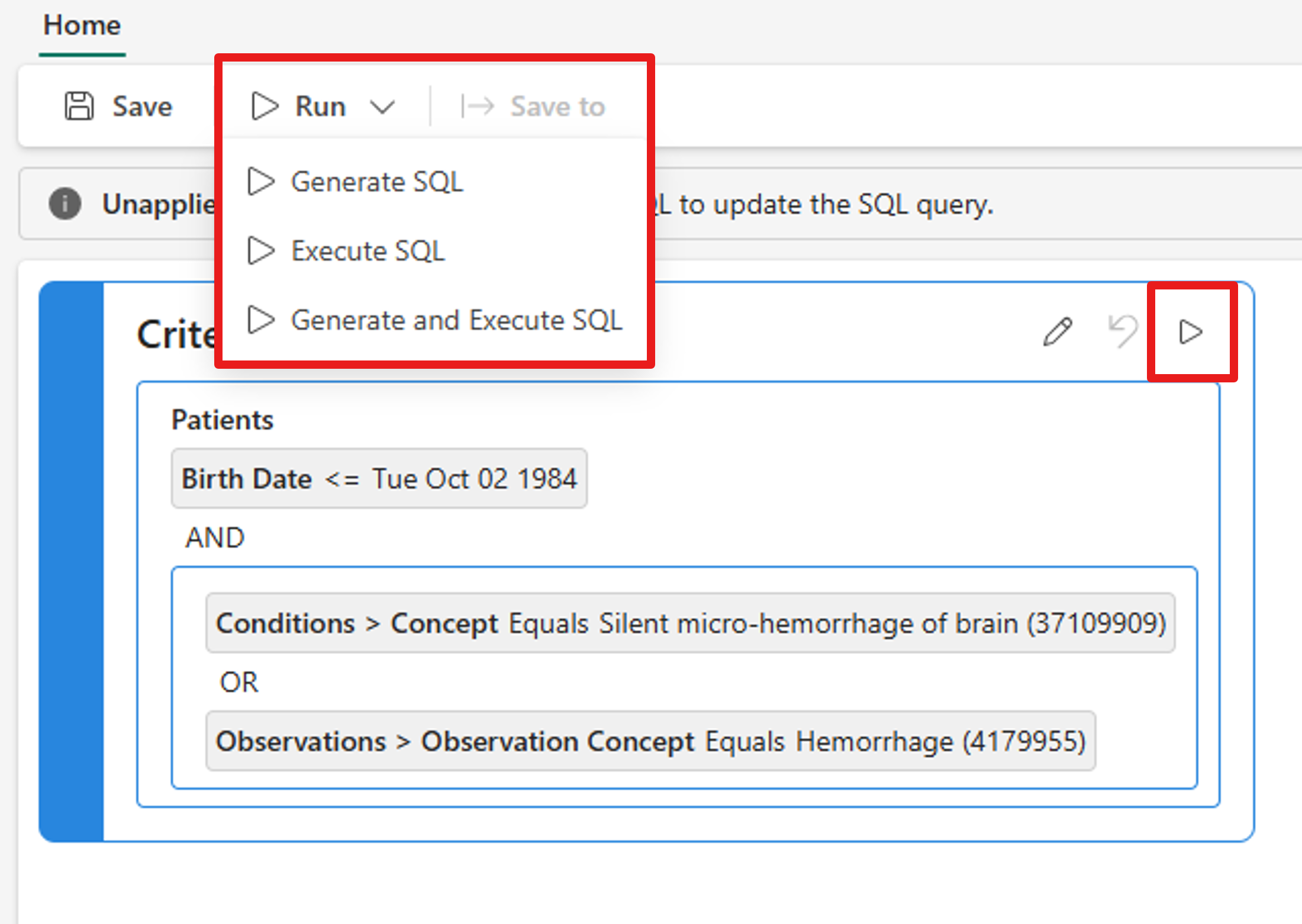
쿼리에 대한 SQL 코드 보기
쿼리의 SQL 코드를 보려면 하단 도구 모음에서 쿼리를 선택하세요.
아직 SQL 생성을 실행하지 않았다면 이 페이지는 비어 있을 것입니다. SQL 생성 후 여기에서 정확한 쿼리를 볼 수 있습니다.
쿼리 기준과 일치하는 환자 보기
코호트의 환자 메타데이터를 보려면 하단 도구 모음에서 데이터를 선택하세요. 이 페이지에서는 OMOP 데이터 세트의 Person 테이블에 대한 간단한 보기를 제공합니다.
일치하는 환자 레코드를 보려면 아래쪽 도구 모음에서 뷰어를 선택합니다. 이 페이지에는 메모 및 이미지를 포함한 특정 환자 파일이 표시됩니다.
데이터 세트에 대한 인구 통계 보기
코호트 검색 및 구축(프리뷰)은 데이터 세트에 대해 집계된 인구 통계가 포함된 Power BI 보고서를 생성합니다. 이 보고서는 SQL 작업을 실행할 때마다 자동으로 업데이트됩니다.
처음에 보고서는 전체 데이터 세트를 나타내는 단일 레이크하우스 페이지로 구성됩니다. 첫 번째 SQL 작업을 실행하면 필터링된 데이터를 나타내는 코호트 페이지가 포함되도록 보고서가 업데이트됩니다. 두 페이지 모두 통계 범위를 더 좁힐 수 있는 person_id 필터가 포함되어 있습니다.
이 보고서를 보려면 아래쪽 도구 모음에서 대시보드를 선택합니다.
최종 데이터 세트 저장
최종 데이터 세트를 저장하려면 상단 도구 모음에서 Save to를 선택합니다.
저장 프로세스를 안내하는 마법사가 나타납니다. 현재 이 기능은 데이터를 저장하는 두 가지 옵션을 제공합니다.
전체 환자 데이터 세트를 레이크하우스에 저장합니다.
환자 ID 및 메타데이터를 다운로드합니다.
전체 환자 데이터 세트를 저장하려면 옵션 1을 선택하고 코호트 이름, 파일 형식 및 대상 레이크하우스를 제공합니다.
내보내기 작업이 완료되면 파일이 대상 레이크하우스의 필터 폴더 아래에 나타납니다. 레이크하우스는 각 내보내기에 대해 새 하위 폴더를 만들며, 각 파일은 단일 환자에 해당합니다. 예를 들어 다음과 같습니다.