자습서: Apache Spark를 통해 Notebook을 사용하여 KQL 데이터베이스 쿼리
Notebook은 데이터 분석 설명과 결과를 포함하는 읽을 수 있는 문서이며, 데이터 분석을 수행하기 위해 실행할 수 있는 실행 가능한 문서 모두를 의미합니다. 이 문서에서는 Microsoft Fabric Notebook을 사용하여 Apache Spark를 통해 KQL 데이터베이스에서 데이터를 읽고 쓰는 방법을 알아봅니다. 이 자습서에서는 실시간 인텔리전스 및 Microsoft Fabric의 데이터 엔지니어 환경 모두에서 미리 생성된 데이터 세트 및 Notebook을 사용합니다. Notebook에 대한 자세한 내용은 Microsoft Fabric Notebook을 사용하는 방법을 참조하세요.
특히 다음 방법을 알아봅니다.
- KQL 데이터베이스 만들기
- Notebook 가져오기
- Apache Spark를 사용하여 KQL 데이터베이스에 데이터 쓰기
- KQL 데이터베이스에서 데이터 쿼리
필수 조건
1 - KQL 데이터베이스 만들기
왼쪽 탐색 모음에서 작업 영역을 선택합니다.
다음 단계 중 하나를 수행하여 eventstream 만들기를 시작합니다.
- 새 항목을 선택한 다음, Eventhouse을 선택하세요. Eventhouse 이름 필드에 nycGreenTaxi를 입력한 다음, 만들기를 선택합니다. KQL 데이터베이스는 동일한 이름으로 생성됩니다.
- 기존 이벤트하우스에서 데이터베이스을 선택합니다. KQL 데이터베이스 에서 +선택한 후, KQL 데이터베이스 이름 필드에 nycGreenTaxi를 입력하고, 만들기을 선택합니다.
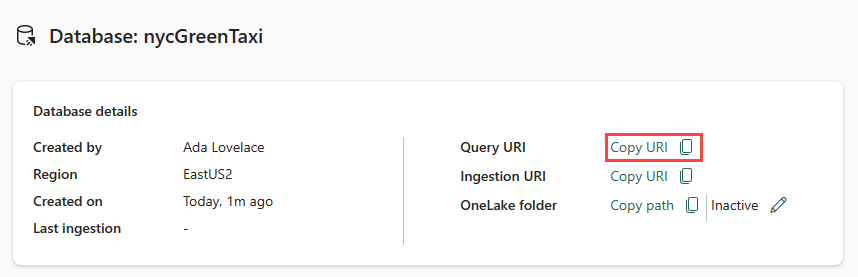
데이터베이스 대시보드의 데이터베이스 세부 정보 카드에서 쿼리 URI를 복사하고 메모장 등 나중에 사용할 위치에 붙여넣습니다.
2 - NYC GreenTaxi Notebook 다운로드
Spark 커넥터를 사용하여 데이터베이스에 데이터를 로드하는 데 필요한 모든 단계를 안내하는 샘플 Notebook을 만들었습니다.
GitHub에서 Fabric 샘플 리포지토리를 열어 NYC GreenTaxi KQL Notebook을 다운로드합니다.
Notebook을 디바이스에 로컬로 저장합니다.
참고 항목
Notebook을
.ipynb파일 형식으로 저장해야 합니다.

3 - Notebook 가져오기
이 워크플로의 나머지 부분은 제품의 데이터 엔지니어링 섹션에서 발생하며 Spark Notebook을 사용하여 KQL 데이터베이스에서 데이터를 로드하고 쿼리합니다.
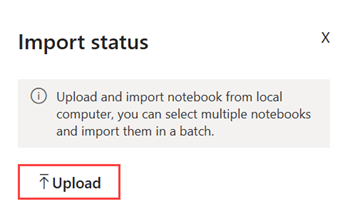
작업 영역에서 가져오기>전자 필기장>이 컴퓨터에서>업로드을 선택한 다음 이전 단계에서 다운로드한 NYC GreenTaxi Notebook을 선택합니다.
가져오기가 완료되면 작업 영역에서 Notebook을 엽니다.
4 - 데이터 가져오기
Spark 커넥터를 사용하여 데이터베이스를 쿼리하려면 NYC GreenTaxi Blob 컨테이너에 대한 읽기 및 쓰기 권한을 부여해야 합니다.
재생 버튼을 선택하여 다음 셀을 실행하거나 셀을 선택하고 Shift+ Enter를 누릅니다. 각 코드 셀에서 이 단계를 반복합니다.
참고 항목
다음 셀을 실행하기 전에 완료 확인 표시가 나타날 때까지 기다립니다.
NYC GreenTaxi Blob 컨테이너에 액세스할 수 있도록 다음 셀을 실행합니다.
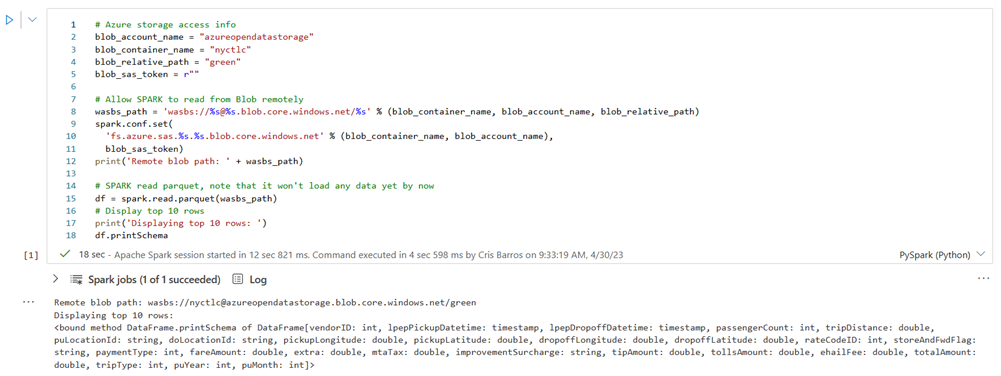
KustoURI에서 자리 표시자 텍스트 대신 이전에 복사한 쿼리 URI를 붙여넣습니다.
자리 표시자 데이터베이스 이름을 nycGreenTaxi로 변경합니다.
자리 표시자 데이터베이스 이름을 GreenTaxiData로 변경합니다.

셀을 실행합니다.
다음 셀을 실행하여 데이터베이스에 데이터를 씁니다. 이 단계를 완료하는 데 몇 분 정도 걸릴 수 있습니다.




이제 데이터베이스에 GreenTaxiData라는 테이블에 데이터가 로드되었습니다.
5 - 노트북 실행
나머지 두 셀을 순차적으로 실행하여 테이블에서 데이터를 쿼리합니다. 결과에서는 연도별로 기록된 상위 20개의 최고 및 최저 택시 요금과 거리를 보여줍니다.

6 - 리소스 정리
만든 작업 영역으로 이동하여 만든 항목을 정리합니다.
작업 영역에서 삭제하려는 Notebook에 커서를 대고 추가 메뉴 [...] >삭제를 선택합니다.
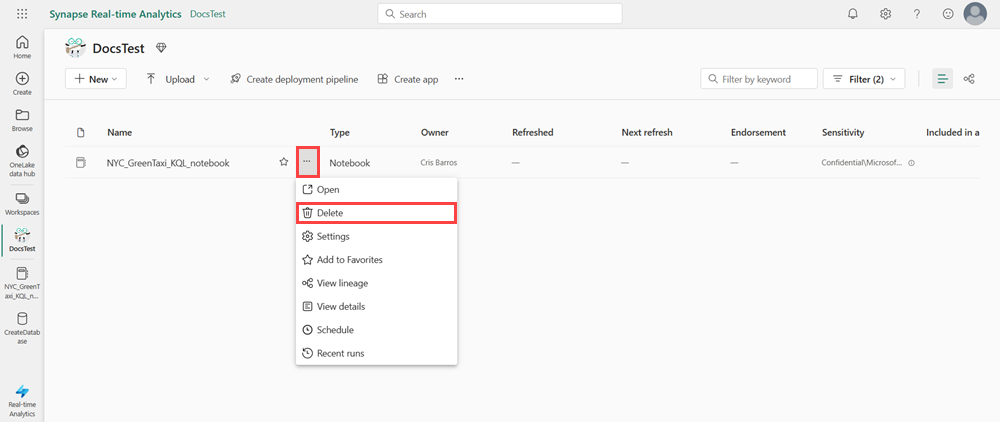
삭제를 선택합니다. Notebook을 삭제한 후에는 복구할 수 없습니다.
