대형매장 판매에 대한 예측 모델 개발, 평가 및 점수 매기기
이 자습서에서는 Microsoft Fabric에서 Synapse 데이터 과학 워크플로의 엔드투엔드 예시를 제공합니다. 이 시나리오에서는 과거 판매 데이터를 사용하여 대형매장에서 제품 범주 판매를 예측하는 예측 모델을 빌드합니다.
판매에 있어서 예측은 중요한 자산입니다. 이는 기록 데이터와 예측 방법을 결합하여 향후 추세에 대한 인사이트를 제공합니다. 예측은 과거 판매를 분석하여 패턴을 식별하고 소비자 행동에서 학습하여 재고, 생산 및 마케팅 전략을 최적화할 수 있습니다. 이 사전 예방적 접근 방식은 동적 마켓플레이스에서 기업의 적응성, 응답성 및 전반적인 성능을 향상시킵니다.
이 자습서에서는 다음 단계를 다룹니다.
- 데이터 로드
- 탐색적 데이터 분석을 사용하여 데이터 이해 및 처리
- 오픈 소스 소프트웨어 패키지를 통해 기계 학습 모델 학습, MLflow 및 Fabric 자동 로깅 기능을 통해 실험 추적
- 최종 기계 학습 모델을 저장하고 예측 수행
- Power BI 시각화를 사용하여 모델 성능 표시
필수 조건
Microsoft Fabric 구독을 구매합니다. 또는 무료 Microsoft Fabric 평가판에 등록합니다.
Microsoft Fabric에 로그인합니다.
홈페이지 왼쪽의 환경 전환기를 사용하여 Synapse 데이터 과학 환경으로 전환합니다.

- 필요한 경우 Microsoft Fabric에서 레이크하우스 만들기에 설명된 대로 Microsoft Fabric 레이크하우스를 만듭니다.
Notebook에서 따라 하기
다음 옵션 중 하나를 선택하여 Notebook에서 따라할 수 있습니다.
- Synapse 데이터 과학 환경에서 기본 제공 Notebook을 열고 실행
- GitHub에서 Synapse 데이터 과학 환경으로 Notebook 업로드
기본 제공 Notebook 열기
이 자습서에는 샘플 판매 예측 Notebook이 함께 제공됩니다.
Synapse 데이터 과학 환경에서 자습서의 기본 제공 샘플 Notebook을 열려면 다음을 수행합니다.
Synapse 데이터 과학 홈페이지로 이동합니다.
샘플 사용을 선택합니다.
해당 샘플을 선택합니다.
- 샘플이 Python 자습서용인 경우 기본 엔드투엔드 워크플로(Python) 탭에서 선택합니다.
- 샘플이 R 자습서용인 경우 엔드투엔드 워크플로(R) 탭에서 선택합니다.
- 샘플이 빠른 자습서용인 경우 빠른 자습서 탭에서 선택합니다.
코드 실행을 시작하기 전에 Notebook에 레이크하우스를 연결합니다.
GitHub에서 Notebook 가져오기
이 자습서에는 AIsample - Superstore Forecast.ipynb Notebook이 함께 제공됩니다.
이 자습서에 함께 제공되는 Notebook을 열려면 데이터 과학 자습서를 위한 시스템 준비의 지침에 따라 Notebook을 작업 영역으로 가져옵니다.
이 페이지에서 코드를 복사하여 붙여넣으려는 경우 새 Notebook을 만들 수 있습니다.
코드 실행을 시작하기 전에 Notebook에 레이크하우스를 연결해야 합니다.
1단계: 데이터 로드
데이터 세트에는 다양한 제품의 9,995개의 판매 인스턴스가 포함되어 있습니다. 또한 21개의 특성이 포함되어 있습니다. 이 테이블은 이 Notebook에 사용되는 Superstore.xlsx 파일에서 가져온 것입니다.
| 행 ID | 주문 ID | 주문 날짜 | 운송 날짜 | 운송 모드 | 고객 ID | 고객 이름 | 세그먼트 | 국가 | 시/군/구 | 시 | 우편 번호 | 지역 | 제품 ID | 범주 | 하위 범주 | 제품 이름 | 판매 | 수량 | 할인 | 이윤 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | 표준 클래스 | SO-20335 | Sean O'Donnell | 소비자 | United States | Fort Lauderdale | Florida | 33311 | South | FUR-TA-10000577 | 가구 | 테이블 | Bretford CR4500 시리즈 슬림 사각형 테이블 | 957.5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | 표준 클래스 | 표준 클래스 | Brosina Hoffman | 소비자 | United States | Los Angeles | California | 90032 | West | FUR-TA-10001539 | 가구 | 테이블 | Chromcraft 사각형 회의 테이블 | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | 표준 클래스 | TB-21520 | Tracy Blumstein | 소비자 | United States | 필라델피아 | 펜실베이니아 | 19140 | 동부 | OFF-EN-10001509 | 사무용품 | 봉투 | 폴리 스트링 타이 봉투 | 3.264 | 2 | 0.2 | 1.1016 |
이러한 매개 변수를 정의하여 다양한 데이터 세트와 함께 이 Notebook을 사용할 수 있도록 합니다.
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
데이터 세트 다운로드 및 레이크하우스에 업로드
이 코드는 공개적으로 사용 가능한 버전의 데이터 세트를 다운로드한 다음 Fabric 레이크하우스에 저장합니다.
중요 사항
실행하기 전에 Notebook에 레이크하우스를 추가해야 합니다. 추가하지 않으면 오류가 표시됩니다.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
MLflow 실험 추적 설정
Microsoft Fabric은 기계 학습 모델을 학습할 때 입력 매개 변수 및 출력 메트릭 값을 자동으로 캡처합니다. 이를 통해 MLflow 자동 로깅 기능이 확장됩니다. 그런 다음 이 정보는 작업 영역에 기록되며, 여기에서 MLflow API 또는 작업 영역의 해당 실험을 통해 액세스하고시각화할 수 있습니다. 자동 로깅에 대한 자세한 내용은 Microsoft Fabric의 자동 로깅을 참조하세요.
Notebook 세션에서 Microsoft Fabric 자동 로깅을 사용하지 않도록 설정하려면 mlflow.autolog()을 호출하고 disable=True를 설정합니다.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
레이크하우스에서 원시 데이터 읽기
레이크하우스의 파일 섹션에서 원시 데이터를 읽습니다. 다른 날짜 부분에 대한 열을 더 추가합니다. 분할된 델타 테이블을 만드는 데도 동일한 정보가 사용됩니다. 원시 데이터는 Excel 파일로 저장되므로 Pandas를 사용하여 읽어야 합니다.
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
2단계: 탐색적 데이터 분석 수행
라이브러리 가져오기
분석하기 전에 필요한 라이브러리를 가져옵니다.
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
원시 데이터 표시
데이터 세트 자체를 더 잘 이해하기 위해 수동으로 데이터 하위 집합을 검토하고 display 함수를 사용하여 DataFrame을 인쇄합니다. 또한 Chart 보기를 통해 데이터 세트의 하위 집합을 쉽게 시각화할 수 있습니다.
display(df)
이 Notebook은 주로 Furniture 범주 판매를 예측하는 데 중점을 두고 있습니다. 이는 계산 속도를 높이고 모델의 성능을 보여주는 데 도움이 됩니다. 그러나 이 Notebook은 적응형 기술을 사용합니다. 이러한 기술을 확장하여 다른 제품 범주의 판매를 예측할 수 있습니다.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
데이터 전처리
실제 비즈니스 시나리오에서는 세 가지 고유 범주로 판매를 예측해야 하는 경우가 많습니다.
- 특정 제품 범주
- 특정 고객 범주
- 제품 범주와 고객 범주의 특정 조합
먼저 불필요한 열을 삭제하여 데이터를 전처리합니다. 일부 열(Row ID, Order ID, Customer ID및 Customer Name)은 아무런 영향을 미치지 않으므로 불필요합니다. 특정 제품 범주(Furniture)에 대한 주 및 지역 전체의 전체 매출을 예측하고자 하므로 State, Region, Country, City, Postal Code 열을 삭제할 수 있습니다. 특정 위치 또는 범주에 대한 판매를 예측하려면 그에 따라 전처리 단계를 조정해야 할 수 있습니다.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
데이터 세트는 일일 기준으로 구성됩니다. 월별로 매출을 예측하는 모델을 개발하고자 하기 때문에 Order Date 열을 다시 샘플링해야 합니다.
먼저 Furniture 범주를 Order Date로 그룹화합니다. 그런 다음 각 그룹에 대한 Sales 열의 합계를 계산하여 각 고유 Order Date 값에 대한 총 매출을 결정합니다. Sales 열을 MS 빈도로 다시 샘플링하여 월별로 데이터를 집계합니다. 마지막으로, 각 월별 평균 판매액을 계산합니다.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Order Date 범주에 대해 Sales에 대한 Furniture의 영향을 보여 줍니다.
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
통계 분석 전에 statsmodels Python 모듈을 가져와야 합니다. 많은 통계 모델의 추정을 위한 클래스와 함수를 제공합니다. 또한 통계 테스트 및 통계 데이터 탐색을 수행할 수 있는 클래스와 함수를 제공합니다.
import statsmodels.api as sm
통계 분석 수행
시계열은 이러한 데이터 요소를 설정된 간격으로 추적하여 시계열 패턴에서 해당 요소의 변형을 결정합니다.
수준: 특정 기간의 평균 값을 나타내는 기본 구성 요소
추세: 시계열이 시간이 지남에 따라 감소하는지, 일정하게 유지되는지 또는 증가하는지 설명합니다.
계절성: 시계열의 주기적 신호를 설명하고 증가 또는 감소하는 시계열 패턴에 영향을 주는 주기적 발생을 찾습니다.
노이즈/잔차: 모델에서 설명할 수 없는 시계열 데이터의 무작위 변동 및 가변성을 나타냅니다.
이 코드에서는 전처리 후 데이터 세트에 대한 이러한 요소를 관찰합니다.
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
플롯은 예측 데이터의 계절성, 추세 및 노이즈를 설명합니다. 기본 패턴을 파악하고 무작위 변동에 탄력적인 정확한 예측을 만드는 모델을 개발할 수 있습니다.
3단계: 모델 학습 및 추적
이제 사용 가능한 데이터가 있으므로예측 모델을 정의할 수 있습니다. 이 Notebook에서는 계절적 자동 회귀 통합 이동 평균 외인성 요인(SARIMAX)이라는 예측 모델을 적용합니다. SARIMAX는 AR(자기 회귀) 및 MA(이동 평균) 구성 요소, 계절적 차이점, 외부 예측 변수를 결합하여 시계열 데이터에 대한 정확하고 유연한 예측을 제공합니다.
또한 MLflow 및 Fabric 자동 로깅을 사용하여 실험을 추적합니다. 여기서는 레이크하우스에서 델타 테이블을 로드합니다. 레이크하우스를 원본으로 간주하는 다른 델타 테이블을 사용할 수도 있습니다.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
하이퍼 매개 변수 튜닝
SARIMAX는 일반 ARIMA(자동 회귀 통합 이동 평균) 모드(p, d,q)와 관련된 매개 변수를 고려하여 계절성 매개 변수(P, D, Q, s)를 추가합니다. 이러한 SARIMAX 모델 인수는 각각 순서(p, d, q) 및 계절 순서(P, D, Q, s)라고 합니다. 따라서 모델을 학습하려면 먼저 7개의 매개 변수를 조정해야 합니다.
매개 변수의 순서
p: 현재 값을 예측하는 데 사용된 시계열의 과거 관찰 수를 나타내는 AR 구성 요소의 순서입니다.일반적으로 이 매개 변수는 음수가 아닌 정수여야 합니다. 공통 값의 범위는
0~3이지만, 특정 데이터 특성에 따라 더 높은 값도 가능합니다.p값이 높을수록 모델에서 과거 값에 대한 메모리가 더 길다는 것을 나타냅니다.d: 시계열이 정상을 달성하기 위해 차분해야 하는 횟수를 나타내는 차분 순서입니다.이 매개 변수는 음수가 아닌 정수여야 합니다. 공통 값의 범위는
0~2입니다.d의0값은 시계열이 이미 고정되어 있다는 것을 의미합니다. 값이 높을수록 고정 상태로 만드는 데 필요한 차분 연산의 수를 나타냅니다.q: 현재 값을 예측하는 데 사용된 과거 백색 노이즈 오차항의 수를 나타내는 MA 구성 요소의 순서입니다.이 매개 변수는 음수가 아닌 정수여야 합니다. 공통 값의 범위는
0~3이지만 특정 시계열에는 더 높은 값이 필요할 수 있습니다.q값이 높을수록 예측하는 데 과거 오차항에 더 많이 의존함을 나타냅니다.
계절별 주문 매개 변수:
P: AR 구성 요소의 계절 순서는p와 유사하지만 계절 부분에 대한 것입니다.D: 계절적 차분 순서는d와 유사하지만 계절 부분에 대한 것입니다.Q: MA 구성 요소의 계절 순서는q와 유사하지만 계절 부분에 대한 것입니다.s: 계절 주기당 시간 단계 수(예: 연간 계절성이 있는 월별 데이터의 경우 12)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX에는 다른 매개 변수도 있습니다.
enforce_stationarity: SARIMAX 모델을 맞추기 전에 모델이 시계열 데이터에 고정성을 적용해야 하는지 여부입니다.enforce_stationarity를True(기본값)로 설정한 경우 SARIMAX 모델이 시계열 데이터에 고정성을 적용해야 함을 나타냅니다. 그런 다음 SARIMAX 모델은 모델에 맞추기 전에 데이터에 자동으로 차분을 적용하여d및D순서에 명시된 대로 고정 상태로 만듭니다. 이는 SARIMAX를 비롯한 많은 시계열 모델은 데이터가 고정되어 있다고 가정하기 때문에 일반적인 관행입니다.비정상 시계열(예: 추세 또는 계절성을 나타냄)의 경우
enforce_stationarity을True로 설정하고 SARIMAX 모델이 차분을 처리하여 고정성을 달성하는 것이 좋습니다. 고정된 시계열(예: 추세 또는 계절성이 없는 시계열)의 경우 불필요한 차분을 방지하도록enforce_stationarity을False로 설정합니다.enforce_invertibility: 최적화 프로세스 중에 모델이 추정된 매개 변수에 가역성을 적용해야 하는지 여부를 제어합니다.enforce_invertibility이True(기본값)로 설정된 경우 SARIMAX 모델이 추정된 매개 변수에 가역성을 적용해야 함을 나타냅니다. 가역성은 모델이 잘 정의되고 추정된 AR 및 MA 계수가 고정 범위 내에 도달하도록 보장합니다.가역성 적용은 SARIMAX 모델이 안정적인 시계열 모델에 대한 이론적 요구 사항을 준수하는 데 도움이 됩니다. 또한 모델 예측 및 안정성 문제를 방지하는 데 도움이 됩니다.
기본값은 AR(1) 모델입니다. 이 참조는 (1, 0, 0)를 의미합니다. 그러나 순서 매개 변수와 계절별 순서 매개 변수의 다양한 조합을 시도하고 데이터 세트에 대한 모델 성능을 평가하는 것이 일반적인 관행입니다. 적절한 값은 시계열마다 달라질 수 있습니다.
최적의 값을 결정하려면 시계열 데이터의 ACF(자기 상관 함수) 및 PACF(부분 자기 상관 함수) 분석이 포함되는 경우가 많습니다. 또한 AIC(Akaike 정보 기준) 또는 BIC(Bayesian 정보 기준)와 같은 모델 선택 조건을 사용하는 경우가 많습니다.
하이퍼 매개 변수 조정:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
앞의 결과를 평가한 후에는 순서 매개 변수와 계절적 순서 매개 변수의 값을 모두 확인할 수 있습니다. 선택은 order=(0, 1, 1) 및 seasonal_order=(0, 1, 1, 12)이며, 가장 낮은 AIC(예: 279.58)를 제공합니다. 이러한 값을 사용하여 모델을 학습합니다.
모델 학습
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
이 코드는 가구 판매 데이터에 대한 시계열 예측을 시각화합니다. 표시된 결과는 관찰된 데이터와 한 단계 앞의 예측을 모두 보여주며, 신뢰 구간에 대한 음영 처리된 영역이 있습니다.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
실제 값과 대조하여 모델의 성능을 평가하려면 predictions을 사용할 수 있습니다. predictions_future 값은 향후 예측을 나타냅니다.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
4단계: 모델 점수 매기기 및 예측 저장
실제 값을 예측 값과 통합하여 Power BI 보고서를 만듭니다. 이러한 결과를 레이크하우스 내의 테이블에 저장합니다.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
5단계: Power BI에서 시각화
Power BI 보고서에는 MAPE(평균 절대 백분율 오차)가 16.58임을 보여줍니다. MAPE 메트릭은 예측 방법의 정확도를 정의합니다. 이는 실제 수량과 비교하여 예측된 수량의 정확도를 나타냅니다.
MAPE는 간단한 메트릭입니다. 10% MAPE는 편차가 양수인지 음수인지에 관계없이 예측 값과 실제 값 사이의 평균 편차가 10%임을 나타냅니다. 바람직한 MAPE 값의 표준은 산업마다 다릅니다.
이 그래프의 연한 파란색 선은 실제 판매 값을 나타냅니다. 진한 파란색 선은 예측된 판매 값을 나타냅니다. 실제 판매와 예측 판매를 비교한 결과, 해당 모델은 2023년 상반기 동안 Furniture 범주의 판매를 효과적으로 예측하는 것으로 나타났습니다.
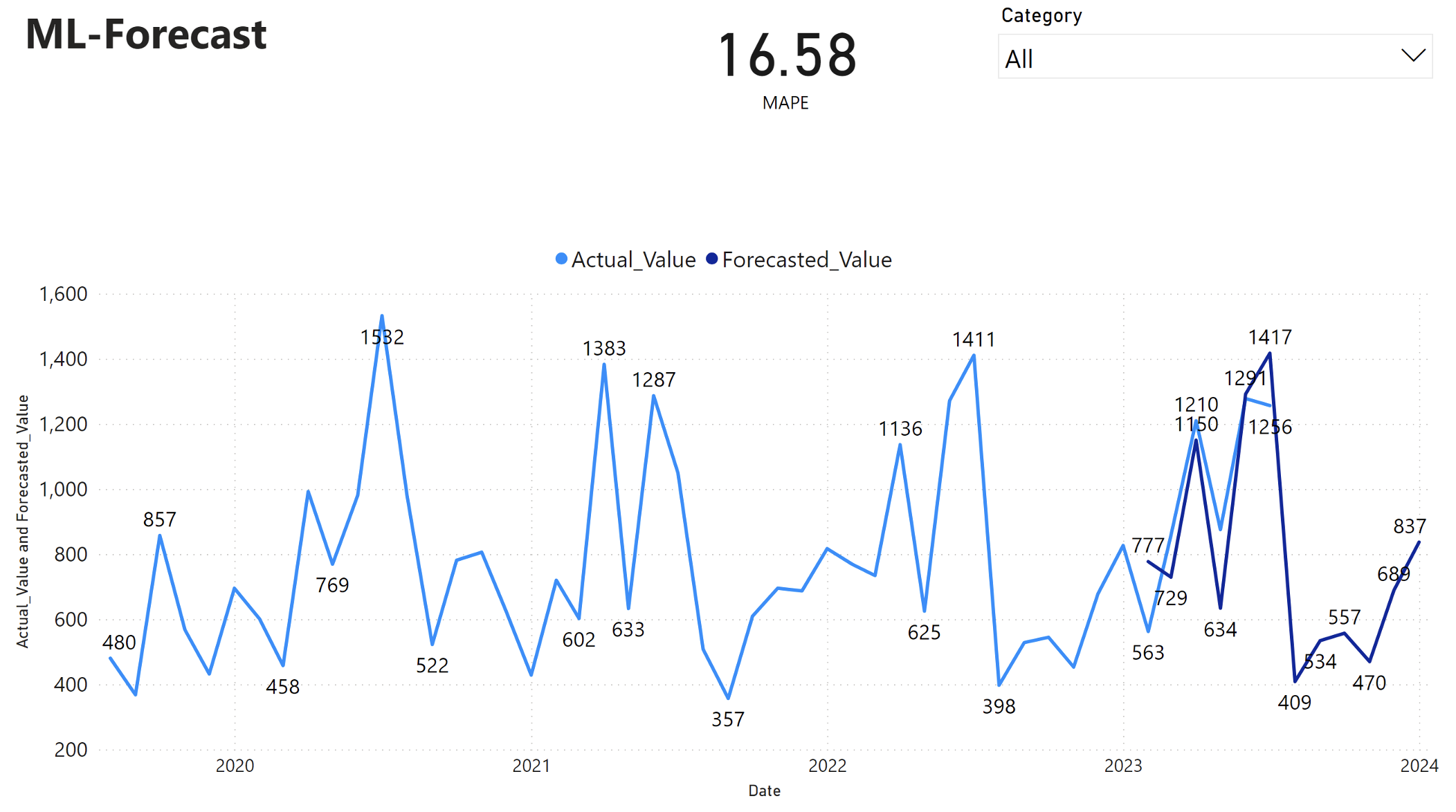
이러한 관찰을 바탕으로, 2023년 하반기 동안의 전체 매출과 2024년까지 확장된 모델의 예측 기능에 대한 확신을 가질 수 있습니다. 이러한 확신은 재고 관리, 원자재 조달 및 기타 비즈니스 관련 고려 사항에 대한 전략적 결정에 도움이 될 수 있습니다.