Microsoft Fabric의 Data Factory에 있는 구분된 텍스트 형식
이 문서에서는 Microsoft Fabric의 Data Factory 데이터 파이프라인에서 구분된 텍스트 형식을 구성하는 방법에 대해 간략히 설명합니다.
지원되는 기능
구분된 텍스트 형식은 원본 및 목적지로서 다음 작업과 커넥터에 대해 지원됩니다.
복사 작업의 구분된 텍스트 형식
구분된 텍스트 형식을 구성하려면 데이터 파이프라인 복사 작업의 원본 또는 목적지에서 연결을 선택한 다음, 파일 형식의 드롭다운 목록에서 DelimitedText를 선택합니다. 이 형식을 추가로 구성하려면 설정을 선택하세요.
구분된 텍스트가 원본인 경우
파일 형식 섹션에서 설정을 선택하면 다음 속성이 팝업 파일 형식 설정 대화 상자에 표시됩니다.
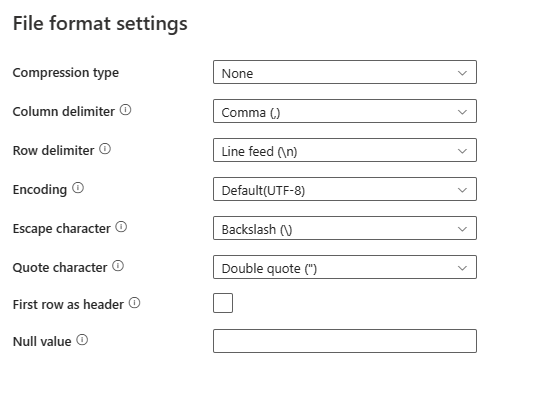
압축 유형: 구분된 텍스트 파일을 읽는 데 사용되는 압축 코덱입니다. 드롭다운 목록에서 없음, bzip2, gzip, deflate, ZipDeflate, TarGzip 또는 tar 유형 중에서 선택할 수 있습니다.
압축 유형으로 ZipDeflate를 선택하면 원본 탭의 고급 설정 아래에 zip 파일 이름을 폴더로 유지가 나타납니다.
- Zip 파일 이름을 폴더로 유지: 원본 Zip 파일 이름을 복사 중에 폴더 구조로 유지할지 여부를 나타냅니다.
- 이 상자를 선택하면(기본값), 서비스는 압축을 푼 파일을
<specified file path>/<folder named as source zip file>/에 씁니다. - 이 상자를 선택 취소하면, 서비스는 압축을 푼 파일을
<specified file path>에 직접 씁니다. 경합 또는 예기치 않은 동작을 방지하기 위해, 다른 원본 zip 파일에 중복된 파일 이름이 없는지 확인합니다.
- 이 상자를 선택하면(기본값), 서비스는 압축을 푼 파일을
압축 유형으로 TarGzip/tar를 선택하면 원본 탭의 고급 설정 아래에 압축 파일 이름을 폴더로 유지가 나타납니다.
- 압축 파일 이름을 폴더로 유지: 원본 압축 파일 이름을 복사 중에 폴더 구조로 유지할지 여부를 나타냅니다.
- 이 상자를 선택하면(기본값), 서비스는 압축을 푼 파일을
<specified file path>/<folder named as source compressed file>/에 씁니다. - 이 상자를 선택 취소하면, 서비스는 압축을 푼 파일을
<specified file path>에 직접 씁니다. 경합 또는 예기치 않은 동작을 방지하기 위해, 다른 원본 zip 파일에 중복된 파일 이름이 없는지 확인합니다.
- 이 상자를 선택하면(기본값), 서비스는 압축을 푼 파일을
- Zip 파일 이름을 폴더로 유지: 원본 Zip 파일 이름을 복사 중에 폴더 구조로 유지할지 여부를 나타냅니다.
압축 수준: 압축 유형을 선택할 때 압축 비율을 지정합니다. 최적 또는 가장 빠름 중에서 선택할 수 있습니다.
- 가장 빠름: 결과 파일이 최적으로 압축되지 않은 경우에도 압축 작업을 최대한 빨리 완료해야 합니다.
- 최적: 작업이 완료되는데 시간이 오래 걸리더라도 압축 작업이 최적으로 압축되어야 합니다. 자세한 내용은 압축 수준 항목을 참조하세요.
열 구분 기호: 파일의 열을 구분하는 데 사용되는 문자입니다. 기본값은 쉼표(
,)입니다.행 구분 기호: 파일의 행을 구분하는 데 사용되는 문자를 지정합니다. 하나의 문자만 허용됩니다. 기본값은 줄 바꿈
\n입니다.인코딩: 테스트 파일을 읽고 쓰는 데 사용되는 인코딩 형식입니다. 기본값은 UTF-8입니다.
이스케이프 문자: 따옴표로 묶인 값 안에서 따옴표를 이스케이프할 단일 문자입니다. 기본값은 백슬래시
\입니다. 이스케이프 문자가 빈 스트링으로 정의된 경우 따옴표 문자도 빈 스트링으로 설정해야 합니다. 이 경우 모든 열 값에 구분 기호가 포함되지 않도록 해야 합니다.따옴표 문자: 열 구분 기호를 포함하는 경우 열 값을 따옴표로 묶을 단일 문자입니다. 기본값은 큰따옴표
"입니다. 따옴표 문자가 빈 스트링으로 정의된 경우 따옴표 문자가 없고 열 값도 따옴표로 묶이지 않았으며, 이스케이프 문자가 열 구분 기호와 그 자체를 이스케이프하는 데 사용됩니다.첫 번째 행을 머리글로: 첫 번째 행을 열의 이름을 가진 머리글 줄로 처리할지 여부를 지정합니다. 허용되는 값은 선택됨 및 선택 해제됨입니다(기본값). 머리글인 첫 번째 행을 선택 해제하면 UI 데이터 프리뷰 및 조회 작업 출력은 열 이름을 Prop_{n}(0부터 시작)으로 자동 생성하고, 복사 작업은 원본에서 목적지까지 명시적인 매핑이 필요하며 서수(1부터 시작)로 열을 찾습니다.
null 값: null 값의 스트링 표현을 지정합니다. 기본값은 빈 문자열입니다.
원본 탭의 고급 설정에서 기타 구분된 텍스트 형식 관련 속성이 노출됩니다.
구분된 텍스트 형식이 목적지인 경우
파일 형식 섹션에서 설정을 선택하면 다음 속성이 팝업 파일 형식 설정 대화 상자에 표시됩니다.
압축 유형: 구분된 텍스트 파일을 쓰는 데 사용되는 압축 코덱입니다. 드롭다운 목록에서 없음, bzip2, gzip, deflate, ZipDeflate, TarGzip 또는 tar 유형 중에서 선택할 수 있습니다.
압축 수준: 압축 유형을 선택할 때 압축 비율을 지정합니다. 최적 또는 가장 빠름 중에서 선택할 수 있습니다.
- 가장 빠름: 결과 파일이 최적으로 압축되지 않은 경우에도 압축 작업을 최대한 빨리 완료해야 합니다.
- 최적: 작업이 완료되는데 시간이 오래 걸리더라도 압축 작업이 최적으로 압축되어야 합니다. 자세한 내용은 압축 수준 항목을 참조하세요.
열 구분 기호: 파일의 열을 구분하는 데 사용되는 문자입니다. 기본값은 쉼표(
,)입니다.행 구분 기호: 파일의 행을 구분하는 데 사용되는 문자입니다. 하나의 문자만 허용됩니다. 기본값은 줄 바꿈
\n입니다.인코딩: 테스트 파일을 쓰는 데 사용되는 인코딩 형식입니다. 기본값은 UTF-8입니다.
이스케이프 문자: 따옴표로 묶인 값 안에서 따옴표를 이스케이프할 단일 문자입니다. 기본값은 백슬래시
\입니다. 이스케이프 문자가 빈 스트링으로 정의된 경우 따옴표 문자도 빈 스트링으로 설정해야 합니다. 이 경우 모든 열 값에 구분 기호가 포함되지 않도록 해야 합니다.따옴표 문자: 열 구분 기호를 포함하는 경우 열 값을 따옴표로 묶을 단일 문자입니다. 기본값은 큰따옴표
"입니다. 따옴표 문자가 빈 스트링으로 정의된 경우 따옴표 문자가 없고 열 값도 따옴표로 묶이지 않았으며, 이스케이프 문자가 열 구분 기호와 그 자체를 이스케이프하는 데 사용됩니다.첫 번째 행을 머리글로: 첫 번째 행을 열의 이름을 가진 머리글 줄로 처리할지 여부를 지정합니다. 허용되는 값은 선택됨 및 선택 해제됨입니다(기본값). 머리글인 첫 번째 행을 선택 해제하면 UI 데이터 프리뷰 및 조회 작업 출력은 열 이름을 Prop_{n}(0부터 시작)으로 자동 생성하고, 복사 작업은 원본에서 목적지까지 명시적인 매핑이 필요하며 서수(1부터 시작)로 열을 찾습니다.
null 값: null 값의 스트링 표현을 지정합니다. 기본값은 빈 문자열입니다.
목적지 탭의 고급 설정에서 추가로 구분된 텍스트 형식 관련 속성이 표시됩니다.
모든 텍스트 인용: 모든 값을 따옴표로 묶습니다.
파일 확장: 출력 파일의 이름을 지정하는 데 사용되는 파일 확장명입니다(예:
.csv,.txt).파일당 최대 행 수: 폴더에 데이터를 쓸 때 여러 파일에 쓰도록 선택하고 파일당 최대 행 수를 지정할 수 있습니다.
파일 이름 접두사: 파일당 최대 행 수가 구성된 경우에 적용됩니다. 여러 파일에 데이터를 쓸 때 파일 이름 접두사를 지정합니다. 이 패턴은
<fileNamePrefix>_00000.<fileExtension>입니다. 지정하지 않으면 파일 이름 접두사가 자동으로 생성됩니다. 원본이 파일 기반 저장소 또는 파티션 옵션 사용 데이터 저장소인 경우에는 이 속성이 적용되지 않습니다.
테이블 요약
원본으로서의 구분된 텍스트
구분된 텍스트 형식을 사용할 때 복사 작업 원본 섹션에서는 다음 속성이 지원됩니다.
| 이름 | 설명 | 값 | 필수 | JSON 스크립트 속성 |
|---|---|---|---|---|
| 파일 형식 | 사용하려는 파일 형식입니다. | DelimitedText | 예 | 유형(datasetSettings 에서):DelimitedText |
| 압축 유형 | 분리된 텍스트 파일을 읽는 데 사용되는 압축 코덱입니다. | 다음 중에서 선택합니다. 없음 bzip2 gzip deflate ZipDeflate TarGzip tar |
아니요 | 유형(compression 에서): bzip2 gzip deflate ZipDeflate TarGzip tar |
| Zip 파일 이름을 폴더로 유지 | 원본 zip 파일 이름을 복사 중에 폴더 구조로 유지할지 여부를 나타냅니다. ZipDeflate 압축을 선택하면 적용됩니다. | 선택됨 또는 선택 해제됨 | 아님 | preserveZipFileNameAsFolder ( compressionProperties->type 아래 ZipDeflateReadSettings으로) |
| 압축 파일 이름을 폴더로 유지 | 원본 압축 파일 이름을 복사 중에 폴더 구조로 유지할지 여부를 나타냅니다. TarGzip/tar 압축을 선택하면 적용됩니다. | 선택됨 또는 선택 해제됨 | 아니요 | preserveCompressionFileNameAsFolder ( compressionProperties->type 아래 TarGZipReadSettings 또는 TarReadSettings으로) |
| 압축 수준 | 압축 비율입니다. 허용되는 값은 최적 또는 가장 빠름입니다. | 최적 또는 가장 빠름 | 아님 | 수준(compression 아래): 가장 빠름 최적 |
| 열 구분 기호 | 파일의 열을 구분하는 데 사용되는 문자입니다. | < 선택한 열 구분 기호 > 쉼표 , (기본값으로) |
아니요 | columnDelimiter |
| 행 구분 기호 | 파일의 행을 구분하는 데 사용되는 문자입니다. | < 선택한 행 구분 기호 > \r,\n (기본값으로) 또는 r\n |
아님 | rowDelimiter |
| 인코딩 | 테스트 파일을 읽고 쓰는 데 사용되는 인코딩 형식입니다. | "UTF-8"(기본값으로),"UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | 아님 | encodingName |
| 이스케이프 문자 | 따옴표로 묶인 값 안에서 따옴표를 이스케이프할 단일 문자입니다. 이스케이프 문자가 빈 스트링으로 정의된 경우 따옴표 문자도 빈 스트링으로 설정해야 합니다. 이 경우 모든 열 값에 구분 기호가 포함되지 않도록 해야 합니다. | < 선택한 이스케이프 문자 > 백슬래시 \ (기본값으로) |
아니요 | escapeChar |
| 따옴표 문자 | 열 구분 기호를 포함하는 경우 열 값을 따옴표로 묶을 단일 문자입니다. 따옴표 문자가 빈 스트링으로 정의된 경우 따옴표 문자가 없고 열 값도 따옴표로 묶이지 않았으며, 이스케이프 문자가 열 구분 기호와 그 자체를 이스케이프하는 데 사용됩니다. | < 선택한 따옴표 문자 > 큰따옴표 " (기본값으로) |
아니요 | quoteChar |
| 첫 번째 행을 머리글로 | 지정된 워크시트/범위의 첫 번째 행을 열 이름의 머리글 줄로 처리할지 여부를 지정합니다. | 선택됨 또는 선택 해제됨 | 아니요 | firstRowAsHeader: true 또는 false(기본값) |
| null 값 | Null 값의 문자열 표현을 지정합니다. 기본값은 빈 문자열입니다. | < null 값의 스트링 표현입니다.> 빈 스트링(기본값으로) |
아니요 | nullValue |
구분된 텍스트가 목적지인 경우
구분된 텍스트 형식을 사용할 때 복사 작업 목적지 섹션에서는 다음 속성이 지원됩니다.
| 이름 | 설명 | 값 | 필수 | JSON 스크립트 속성 |
|---|---|---|---|---|
| 파일 형식 | 사용하려는 파일 형식입니다. | DelimitedText | 예 | 유형(datasetSettings 에서):DelimitedText |
| 압축 유형 | 분리된 텍스트 파일을 작성하는 데 사용되는 압축 코덱입니다. | 다음 중에서 선택합니다. 없음 bzip2 gzip deflate ZipDeflate TarGzip tar |
아니요 | 유형(compression 에서): bzip2 gzip deflate ZipDeflate TarGzip tar |
| Zip 파일 이름을 폴더로 유지 | 원본 zip 파일 이름을 복사 중에 폴더 구조로 유지할지 여부를 나타냅니다. | 선택됨 또는 선택 해제됨 | 아님 | preserveZipFileNameAsFolder ( compressionProperties->type 아래 ZipDeflateReadSettings으로) |
| 압축 파일 이름을 폴더로 유지 | 원본 압축 파일 이름을 복사 중에 폴더 구조로 유지할지 여부를 나타냅니다. | 선택됨 또는 선택 해제됨 | 아니요 | preserveCompressionFileNameAsFolder ( compressionProperties->type 아래 TarGZipReadSettings 또는 TarReadSettings으로) |
| 압축 수준 | 압축 비율입니다. 허용되는 값은 최적 또는 가장 빠름입니다. | 최적 또는 가장 빠름 | 아님 | 수준(compression 아래): 가장 빠름 최적 |
| 열 구분 기호 | 파일의 열을 구분하는 데 사용되는 문자입니다. | < 선택한 열 구분 기호 > 쉼표 , (기본값으로) |
아니요 | columnDelimiter |
| 행 구분 기호 | 파일의 행을 구분하는 데 사용되는 문자입니다. | < 선택한 행 구분 기호 > \r,\n (기본값으로) 또는 r\n |
아님 | rowDelimiter |
| 인코딩 | 테스트 파일을 읽고 쓰는 데 사용되는 인코딩 형식입니다. | "UTF-8"(기본값으로),"UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | 아님 | encodingName |
| 이스케이프 문자 | 따옴표로 묶인 값 안에서 따옴표를 이스케이프할 단일 문자입니다. 이스케이프 문자가 빈 스트링으로 정의된 경우 따옴표 문자도 빈 스트링으로 설정해야 합니다. 이 경우 모든 열 값에 구분 기호가 포함되지 않도록 해야 합니다. | < 선택한 이스케이프 문자 > 백슬래시 \ (기본값으로) |
아니요 | escapeChar |
| 따옴표 문자 | 열 구분 기호를 포함하는 경우 열 값을 따옴표로 묶을 단일 문자입니다. 따옴표 문자가 빈 스트링으로 정의된 경우 따옴표 문자가 없고 열 값도 따옴표로 묶이지 않았으며, 이스케이프 문자가 열 구분 기호와 그 자체를 이스케이프하는 데 사용됩니다. | < 선택한 따옴표 문자 > 큰따옴표 " (기본값으로) |
아니요 | quoteChar |
| 첫 번째 행을 머리글로 | 지정된 워크시트/범위의 첫 번째 행을 열 이름의 머리글 줄로 처리할지 여부를 지정합니다. | 선택됨 또는 선택 해제됨 | 아니요 | firstRowAsHeader: true 또는 false(기본값) |
| 모든 텍스트 인용 | 모든 값을 따옴표로 묶습니다. | 선택됨(기본값) 또는 선택 해제됨 | 아니요 | quoteAllText: true(기본값) 또는 false |
| 파일 확장명 | 출력 파일의 이름을 지정하는 데 사용되는 파일 확장명입니다. | < 파일 확장 > .txt(기본값) |
아니요 | fileExtension |
| 파일당 최대 행 수 | 폴더에 데이터를 쓸 때 여러 파일에 쓰도록 선택하고 파일당 최대 행 수를 지정할 수 있습니다. | < 파일당 최대 행 수 > | 아니요 | maxRowsPerFile |
| 파일 이름 접두사 | 파일당 최대 행 수가 구성된 경우에 적용됩니다. 여러 파일에 데이터를 쓸 때 파일 이름 접두사를 지정합니다. 이 패턴은 <fileNamePrefix>_00000.<fileExtension>입니다. 지정하지 않으면 파일 이름 접두사가 자동으로 생성됩니다. 원본이 파일 기반 저장소 또는 파티션 옵션 사용 데이터 저장소인 경우에는 이 속성이 적용되지 않습니다. |
< 파일 이름 접두사 > | 아니요 | fileNamePrefix |