복사 작업에서 SQL 데이터베이스 구성(미리 보기)
이 문서에서는 데이터 파이프라인의 복사 작업을 사용하여 SQL 데이터베이스에서 데이터를 복사하는 방법을 간략하게 설명합니다.
지원되는 구성
복사 작업에서 각 탭의 구성에 대해 각각 다음 섹션으로 이동합니다.
일반
일반 설정 지침을 참조하여 일반 설정 탭을 구성합니다.
근원
복사 작업의 원본 탭에서 SQL 데이터베이스에 대해 지원되는 속성은 다음과 같습니다.

다음 속성은 필수.
연결: 이 문서의 단계에 따라 참조할 기존 SQL 데이터베이스를 선택합니다.
쿼리사용: 테이블, 쿼리, 또는 저장 프로시저을 선택할 수 있습니다. 다음 목록에서는 각 설정의 구성을 설명합니다.
테이블: 데이터를 읽을 SQL 데이터베이스의 이름을 지정합니다. 드롭다운 목록에서 기존 테이블을 선택하거나 수동으로 입력하여 스키마 및 테이블 이름을 입력합니다.
쿼리: 데이터를 읽을 사용자 지정 SQL 쿼리를 지정합니다. 예를 들어서,
select * from MyTable입니다. 또는 코드 편집기에서 편집할 연필 아이콘을 선택합니다.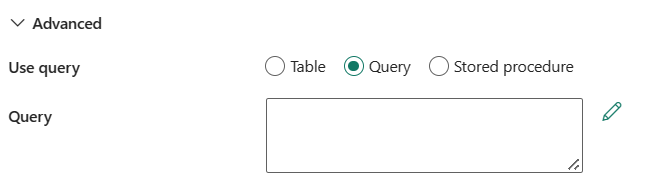
저장 프로시저: 드롭다운 목록에서 저장 프로시저를 선택합니다.

고급아래에서 다음 필드를 지정할 수 있습니다.
쿼리 제한 시간(분): 쿼리 명령 실행에 대한 시간 제한을 지정합니다. 기본값은 120분입니다. 이 속성에 대해 매개 변수를 설정한 경우 허용되는 값은 시간 범위(예: "02:00:00"(120분)입니다.
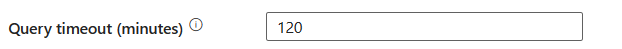
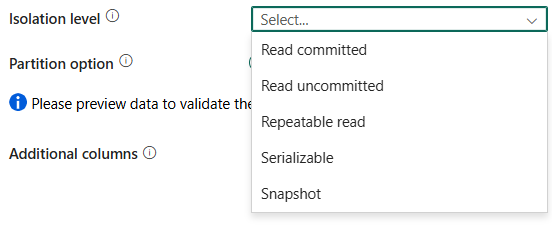
격리 수준: SQL 원본에 대한 트랜잭션 잠금 동작을 지정합니다. 허용되는 값은 커밋된 읽기, 커밋되지 않은 읽기, 반복 가능한 읽기, 직렬화 가능또는 스냅샷입니다. 자세한 내용은 IsolationLevel 열거형 참조하세요.
격리 수준 설정을 보여 주는
파티션 옵션: SQL 데이터베이스에서 데이터를 로드하는 데 사용되는 데이터 분할 옵션을 지정합니다. 허용되는 값은 없음(기본값), 테이블실제 파티션 및 동적 범위. 파티션 옵션을 사용하는 경우(즉, 없음아님) SQL 데이터베이스에서 데이터를 동시에 로드하는 병렬 처리 수준은 복사 작업 설정 탭에서 복사 병렬 처리 수준 의해 제어됩니다.
없음: 파티션을 사용하지 않도록 이 설정을 선택합니다.
테이블의 실제 파티션
: 실제 파티션을 사용하는 경우 파티션 열 및 메커니즘은 실제 테이블 정의에 따라 자동으로 결정됩니다. 동적 범위: 병렬 사용 쿼리를 사용하는 경우 범위 파티션 매개 변수(
?DfDynamicRangePartitionCondition)가 필요합니다. 샘플 쿼리:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.파티션 열 이름: 병렬 복사를 위해 범위 분할에 사용되는 정수 또는 date/datetime 형식(
int,smallint,bigint,date,smalldatetime,datetime,datetime2또는datetimeoffset)의 원본 열 이름을 지정합니다. 지정하지 않으면 테이블의 인덱스 또는 기본 키가 자동으로 검색되고 파티션 열로 사용됩니다.쿼리를 사용하여 원본 데이터를 검색할 때 WHERE 절에
?DfDynamicRangePartitionCondition을(를) 설정합니다. 예를 들어 SQL 데이터베이스 섹션의병렬 복사본을 참조하세요. 파티션 상한: 파티션 범위 분할에 대한 파티션 열의 최대값을 지정합니다. 이 값은 테이블의 행을 필터링하는 것이 아니라 파티션 스트라이드를 결정하는 데 사용됩니다. 테이블 또는 쿼리 결과의 모든 행이 분할되고 복사됩니다. 지정하지 않으면 복사 활동에서 값을 자동으로 감지합니다. 예를 들어 SQL 데이터베이스 섹션의
병렬 복사본을 참조하세요. 파티션 하한: 파티션 열의 최소값을 파티션 범위 분할 목적으로 지정합니다. 이 값은 테이블의 행을 필터링하는 것이 아니라 파티션 스트라이드를 결정하는 데 사용됩니다. 테이블 또는 쿼리 결과의 모든 행이 분할되고 복사됩니다. 지정하지 않으면 복사 작업에서 값을 자동으로 감지합니다. 예를 들어 SQL 데이터베이스 섹션의
병렬 복사본을 참조하세요.
추가 열: 원본 파일의 상대 경로 또는 정적 값을 저장할 데이터 열을 더 추가합니다. 후자에 대한 표현이 지원됩니다. 자세한 내용은 복사 중에서 추가 열
로 이동하십시오.


목적지
복사 작업의 대상 탭에서 SQL 데이터베이스에 대해 다음 속성이 지원됩니다.
대상 탭을 보여 주는 
다음 속성은 필수.
연결: 이 문서단계를 참조하는 기존 SQL 데이터베이스 선택합니다.
테이블 옵션: 기존 사용을 선택하거나 테이블자동 생성을 선택합니다.
기존을(를) 사용하려면
을(를) 선택하십시오: - 테이블: 데이터를 쓸 SQL 데이터베이스의 이름을 지정합니다. 드롭다운 목록에서 기존 테이블을 선택하거나 직접 입력하려면 을 선택하여 스키마 및 테이블 이름을 입력합니다.
자동 테이블 생성을 선택하는 경우:
- 테이블: 원본 스키마에 존재하지 않는 경우 자동으로 테이블이 생성됩니다. 이는 저장 프로시저가 쓰기 동작으로 사용될 때는 지원되지 않습니다.
고급아래에서 다음 필드를 지정할 수 있습니다.
쓰기 동작: 원본이 파일 기반 데이터 저장소의 파일인 경우 쓰기 동작을 정의합니다. 삽입, Upsert 또는 저장 프로시저를 선택할 수 있습니다.

삽입 : 원본 데이터에 삽입이 있는 경우 이 옵션을 선택합니다.
Upsert: 원본 데이터가 삽입과 업데이트를 모두 포함하는 경우 이 옵션을 선택합니다.
TempDB사용: 전역 임시 테이블 또는 실제 테이블을 upsert의 중간 테이블로 사용할지 여부를 지정합니다. 기본적으로 서비스는 전역 임시 테이블을 중간 테이블로 사용하고 이 확인란을 선택합니다.
SQL 데이터베이스에 대량의 데이터를 쓰는 경우, 체크를 해제하고 Data Factory가 준비 테이블을 만들어 업스트림 데이터를 로드하고 완료 시 자동으로 정리할 스키마 이름을 지정해야 합니다. 사용자에게 데이터베이스에 테이블 만들기 권한이 있는지 확인하고 스키마에 대한 사용 권한을 변경합니다. 지정하지 않으면 전역 임시 테이블이 스테이징으로 사용됩니다.tempDB 사용을 선택하는

사용자 DB 스키마선택: TempDB 사용 선택되지 않은 경우, Data Factory가 스테이징 테이블을 만들어 업스트림 데이터를 로드하고 완료 시 자동으로 정리할 수 있는 스키마 이름을 지정합니다. 데이터베이스에 테이블 만들기 권한이 있는지 확인하고 스키마에 대한 권한을 변경합니다.
메모
테이블을 만들고 삭제할 수 있는 권한이 있어야 합니다. 기본적으로 중간 테이블은 대상 테이블과 동일한 스키마를 공유합니다.
tempDB 사용을 선택하지 않음을 보여 주는
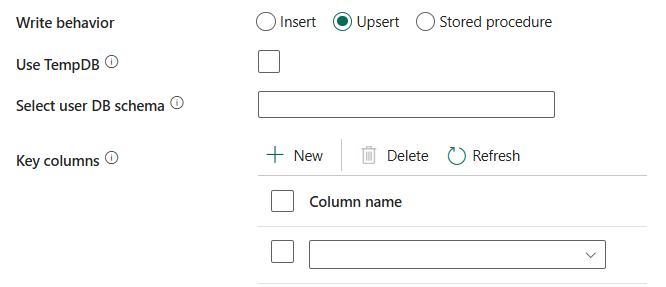
키 열: 원본의 행이 대상의 행과 일치하는지 확인하는 데 사용할 열을 선택합니다.
저장 프로시저 이름: 드롭다운 목록에서 저장 프로시저를 선택합니다.
대량 삽입 테이블 잠금: 예 또는 아니요를 선택합니다. 이 설정을 사용하여 여러 클라이언트의 인덱스가 없는 테이블에서 대량 삽입 작업을 수행하는 동안 복사 성능을 향상시킬 수 있습니다. 자세한 정보를 보려면 BULK INSERT(Transact-SQL)으로 이동하세요.
사전 복사 스크립트: 각 실행에서 대상 테이블에 데이터를 쓰기 전에 실행할 복사 작업의 스크립트를 지정합니다. 이 속성을 사용하여 미리 로드된 데이터를 정리할 수 있습니다.
일괄 쓰기 시간 제한: 일괄 쓰기 작업이 시간 초과되기 전에 완료될 대기 시간을 지정합니다. 허용되는 값은 시간 간격입니다. 기본값은 "00:30:00"(30분)입니다.
쓰기 일괄 처리 크기: 일괄 처리당 SQL 테이블에 삽입할 행 수를 지정합니다. 허용되는 값은 정수(행 수)입니다. 기본적으로 서비스는 행 크기에 따라 적절한 일괄 처리 크기를 동적으로 결정합니다.
최대 동시 연결: 활동 실행 중에 데이터 저장소에 설정된 동시 연결의 상한을 지정합니다. 동시 연결을 제한하려는 경우에만 값을 지정합니다.


매핑
매핑 탭 구성을 위해, SQL 데이터베이스를 자동 테이블 생성 기능이 있는 대상으로 적용하지 않는 경우, 매핑로 이동합니다.
매핑구성에서 설명된 것을 제외하고, 자동 생성 테이블을 대상지로 하는 SQL 데이터베이스를 적용하는 경우, 대상 열의 형식을 편집할 수 있습니다.
예를 들어 원본에서 ID 열의 형식은 int이며 대상 열에 매핑할 때 부동 형식으로 변경할 수 있습니다.

설정
SQL 데이터베이스에서 병렬 복사
복사 작업의 SQL 데이터베이스 커넥터는 데이터를 병렬로 복사하는 기본 제공 데이터 분할을 제공합니다. 복사 작업의 원본 탭에서 데이터 분할 옵션을 찾을 수 있습니다.
분할된 복사를 사용하도록 설정하면 복사 작업은 SQL 데이터베이스 원본에 대해 병렬 쿼리를 실행하여 파티션별로 데이터를 로드합니다. 병렬 수준은 복사 작업 설정 탭의 복사 병렬 처리 수준 의해 제어됩니다. 예를 들어 복사 병렬 처리 수준을 4로 설정하면 서비스는 지정된 파티션 옵션 및 설정에 따라 4개의 쿼리를 동시에 생성하고 실행하며 각 쿼리는 SQL 데이터베이스에서 데이터의 일부를 검색합니다.
특히 SQL 데이터베이스에서 대량의 데이터를 로드할 때 데이터 분할을 사용하여 병렬 복사를 사용하도록 설정하는 것이 좋습니다. 다음은 다양한 시나리오에 대한 권장 구성입니다. 데이터를 파일 기반 데이터 저장소에 복사할 때 폴더에 여러 파일(폴더 이름만 지정)으로 쓰는 것이 좋습니다. 이 경우 단일 파일에 쓰는 것보다 성능이 더 좋습니다.
| 시나리오 | 권장 설정 |
|---|---|
| 실제 파티션을 사용하여 큰 테이블에서 데이터를 전체 로드합니다. |
파티션 옵션: 테이블의 실제 파티션입니다. 실행하는 동안 서비스는 실제 파티션을 자동으로 검색하고 파티션별로 데이터를 복사합니다. 테이블에 실제 파티션이 있는지 확인하려면 이 쿼리을 참조할 수 있습니다. |
| 정수 또는 날짜/시간 열을 사용하여 데이터 분할을 하는 동안 실제 파티션 없이 큰 테이블에서 전체 데이터를 로드합니다. |
파티션 옵션: 동적 범위 파티션입니다. 파티션 열(선택 사항): 데이터를 분할하는 데 사용되는 열을 지정합니다. 지정하지 않으면 인덱스 또는 기본 키 열이 사용됩니다. 파티션 상한 및 파티션 하한(선택 사항): 파티션 보폭을 결정할지 여부를 지정합니다. 테이블의 행을 필터링하는 것이 아니라 테이블의 모든 행이 분할되고 복사됩니다. 지정하지 않으면 복사 작업에서 값을 자동으로 검색하고 MIN 및 MAX 값에 따라 시간이 오래 걸릴 수 있습니다. 상한선과 하한선을 제공하는 것이 바람직합니다. 예를 들어 파티션 열 "ID"의 값 범위가 1에서 100까지이고 하한을 20으로 설정하고 상한을 80으로 설정하는 경우 서비스는 4개의 파티션으로 데이터를 검색합니다. 즉, 범위의 ID <는 각각 =20, [21, 50], [51, 80] 및 >=81입니다. |
| 데이터 분할을 위해 정수 또는 날짜/날짜/시간 열과 함께 실제 파티션 없이 사용자 지정 쿼리를 사용하여 많은 양의 데이터를 로드합니다. |
파티션 옵션: 동적 범위 파티션입니다. 쿼리: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.파티션 열: 데이터를 분할하는 데 사용되는 열을 지정합니다. 파티션 상한 및 파티션 하한(선택 사항): 파티션 스트라이드를 결정할지 여부를 지정합니다. 테이블의 행을 필터링하는 것이 아니라 쿼리 결과의 모든 행이 분할되고 복사됩니다. 지정하지 않으면 복사 작업이 값을 자동으로 감지합니다. 예를 들어, 파티션 열 "ID"의 값이 1에서 100까지 범위로 주어졌고 하한을 20, 상한을 80으로 설정한 경우, 병렬 복사 개수를 4로 설정하면, 서비스는 네 개의 파티션으로 데이터를 검색합니다: ID 범위는 <=20, [21, 50], [51, 80], 그리고 >=81입니다. 다양한 시나리오에 대한 추가 샘플 쿼리는 다음과 같습니다. • 전체 테이블을 쿼리합니다. SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• 특정 열 선택과 추가 조건 필터를 사용하여 테이블에서 쿼리 실행: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• 하위 쿼리를 사용하여 쿼리: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• 하위 쿼리 내 파티션을 사용한 쿼리: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
파티션 옵션을 사용하여 데이터를 로드하는 모범 사례:
- 데이터 불균형을 방지하려면 특정한 열을 기본 키나 고유 키와 같은 파티션 열로 선택하세요.
- 테이블에 기본 제공 파티션이 있는 경우 성능 향상을 위해 테이블 실제 파티션
파티션 옵션을 사용합니다.
실제 파티션을 확인하는 샘플 쿼리
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
테이블에 실제 파티션이 있는 경우 다음과 같이 "HasPartition"이 "예"로 표시됩니다.

테이블 요약
다음 표에는 SQL 데이터베이스의 복사 활동에 대한 자세한 정보가 포함되어 있습니다.
근원
| 이름 | 묘사 | 값 | 필수 | JSON 스크립트 속성 |
|---|---|---|---|---|
| 연결 | 원본 데이터 저장소에 대한 연결입니다. | <연결> | 예 | 연결 |
| 쿼리 사용 | 데이터를 읽는 방법입니다. 테이블 적용하여 지정된 테이블에서 데이터를 읽거나 쿼리 적용하여 SQL 쿼리를 사용하여 데이터를 읽습니다. | • 테이블 • 쿼리 • 저장 프로시저 |
예 | / |
| 테이블 | ||||
| 스키마 이름 | 스키마의 이름입니다. | < 스키마 이름 > | 아니요 | 스키마 |
| 테이블 이름 | 테이블 이름. | < 당신의 테이블 이름 > | 아니요 | 테이블 |
| 쿼리 | ||||
| 쿼리 | 데이터를 읽을 사용자 지정 SQL 쿼리를 지정합니다. 예: SELECT * FROM MyTable. |
< SQL 쿼리 > | 아니요 | sqlReaderQuery |
| 저장 프로시저 | ||||
| 저장 프로시저 이름 | 저장 프로시저의 이름입니다. | < 저장 프로시저 이름 > | 아니요 | sqlReaderStoredProcedureName |
| 쿼리 시간 제한(분) | 쿼리 명령 실행에 대한 시간 제한(기본값은 120분)입니다. 이 속성에 대해 매개 변수를 설정한 경우 허용되는 값은 시간 범위(예: "02:00:00"(120분)입니다. | 시간 범위 | 아니요 | queryTimeout |
| 격리 수준 | SQL 원본에 대한 트랜잭션 잠금 동작을 지정합니다. | • 커밋된 읽기 • 커밋되지 않은 읽기 • 반복 가능한 읽기 •직렬화 •스냅 사진 |
아니요 | 고립 수준 • 읽기 커밋됨 (ReadCommitted) • 읽기 비커밋 (ReadUncommitted) • 반복 가능한 읽기 •직렬화 •스냅 사진 |
| 파티션 옵션 | SQL 데이터베이스에서 데이터를 로드하는 데 사용되는 데이터 분할 옵션입니다. | •없음 • 테이블의 물리적 파티션 • 동적 범위 |
아니요 | 파티션 옵션: 테이블의 물리적 파티션 • DynamicRange |
| 동적 범위 | ||||
| 파티션 열 이름 |
정수 또는 date/datetime 형식의 소스 열 이름(int, smallint, bigint, date, smalldatetime, datetime, datetime2또는 datetimeoffset)은 병렬 복사를 위해 범위 분할에 사용됩니다. 지정하지 않으면 테이블의 인덱스 또는 기본 키가 자동으로 검색되고 파티션 열로 사용됩니다. 쿼리를 사용하여 원본 데이터를 검색하는 경우 WHERE 절에 ?DfDynamicRangePartitionCondition을 연결합니다. |
<의 파티션 열 이름 > | 아니요 | partitionColumnName |
| 파티션 상한 | 파티션 범위를 분할하기 위한 파티션 열의 최대값입니다. 이 값은 테이블의 행을 필터링하는 것이 아니라, 파티션 간격을 결정하는 데 사용됩니다. 테이블 또는 쿼리 결과의 모든 행이 분할되고 복사됩니다. 지정하지 않으면 복사 작업에서 값을 자동으로 감지합니다. | < 파티션 상한 > | 아니요 | partitionUpperBound |
| 파티션 하한 | 파티션 범위 분할을 위한 파티션 열의 최소값입니다. 이 값은 테이블의 행을 필터링하는 것이 아니라 파티션 스트라이드를 결정하는 데 사용됩니다. 테이블 또는 쿼리 결과의 모든 행이 분할되고 복사됩니다. 지정하지 않으면 복사 작업에서 값을 자동으로 감지합니다. | < 당신의 파티션 하한 > | 아니요 | 파티션 하한값 |
| 추가 열 | 원본 파일의 상대 경로 또는 정적 값을 저장할 데이터 열을 더 추가합니다. 표현식은 후자에 대해 지원됩니다. | •이름 •값 |
아니요 | 추가열: •이름 •값 |
목적지
| 이름 | 묘사 | 값 | 필수 | JSON 스크립트 속성 |
|---|---|---|---|---|
| 연결 | 대상 데이터 저장소에 대한 연결입니다. | <귀하의 연결 > | 예 | 연결 |
| 테이블 옵션 | 목적지 데이터 테이블입니다. 기존 테이블 사용하기 또는 테이블 자동 생성하기중에서 선택합니다. | 기존의 것을 사용 • 테이블 자동 만들기 |
예 | 스키마 테이블 |
| 쓰기 동작 방식 | 원본이 파일 기반 데이터 저장소의 파일인 경우 쓰기 동작을 정의합니다. | • 삽입 • 업서트 • 저장 프로시저 |
아니요 | 쓰기 동작 •삽입하다 • 업서트(업데이트 또는 삽입) • sqlWriterStoredProcedureName (SQL 작성자 저장 프로시저 이름) |
| 대량 삽입 테이블 잠금 | 이 설정을 사용하여 여러 클라이언트의 인덱스가 없는 테이블에서 대량 삽입 작업을 수행하는 동안 복사 성능을 향상시킬 수 있습니다. | 예 또는 아니요(기본값) | 아니요 | sqlWriterUseTableLock: true 또는 false(기본값) |
| 용 업서트 | ||||
| TempDB 사용 | 전역 임시 테이블 또는 실제 테이블을 upsert의 중간 테이블로 사용할지 여부입니다. | 선택됨(기본값) 또는 선택 취소됨 | 아니요 | useTempDB: true(기본값) 또는 false |
| 주요 열 |
원본의 행이 대상의 행과 일치하는지 확인하는 데 사용할 열을 선택합니다. | 키 열 <> | 아니요 | 열쇠 |
| 저장 프로시저 | ||||
| 저장 프로시저 이름 | 이 속성은 원본 테이블에서 데이터를 읽는 저장 프로시저의 이름입니다. 마지막 SQL 문은 저장 프로시저의 SELECT 문이어야 합니다. | 저장 프로시저 이름 <> | 아니요 | sqlWriter저장프로시저이름 |
| 사전 복사 스크립트 | 각 실행에서 대상 테이블에 데이터를 쓰기 전에 실행할 복사 작업에 대한 스크립트입니다. 이 속성을 사용하여 미리 로드된 데이터를 정리할 수 있습니다. | 사전 복사 스크립트 <> (string) |
아니요 | preCopyScript |
| 쓰기 일괄 처리 시간 제한 | 일괄 처리 삽입 작업이 시간 초과되기 전에 완료될 때까지의 대기 시간입니다. 허용 가능한 값은 "시간 범위"입니다. 기본값은 "00:30:00"(30분)입니다. | 시간 범위 | 아니요 | writeBatchTimeout |
| 쓰기 일괄 처리 크기 | 일괄 처리당 SQL 테이블에 삽입할 행 수입니다. 기본적으로 서비스는 행 크기에 따라 적절한 일괄 처리 크기를 동적으로 결정합니다. |
<행 수> (정수) |
아니요 | 쓰기 배치 크기 |
| 최대 동시 연결 | 작업 실행 중에 데이터 저장소에 설정된 동시 연결의 상한입니다. 동시 연결을 제한하려는 경우에만 값을 지정합니다. | 동시 연결의 최대 한도 <> (정수) |
아니요 | 최대동시연결(maxConcurrentConnections) |