복사 작업에서 Azure Database for PostgreSQL 구성
이 문서에서는 데이터 파이프라인의 복사 작업을 사용하여 Azure Database for PostgreSQL에서 데이터를 복사하는 방법에 대해 설명합니다.
지원되는 구성
복사 작업 아래의 각 탭을 구성하려면 각각 다음 섹션으로 이동합니다.
일반
일반 설정 탭을 구성하려면 일반 설정 지침을 참조하세요.
원본
원본 탭으로 이동하여 복사 작업 원본을 구성합니다. 자세한 구성은 다음 내용을 참조하세요.
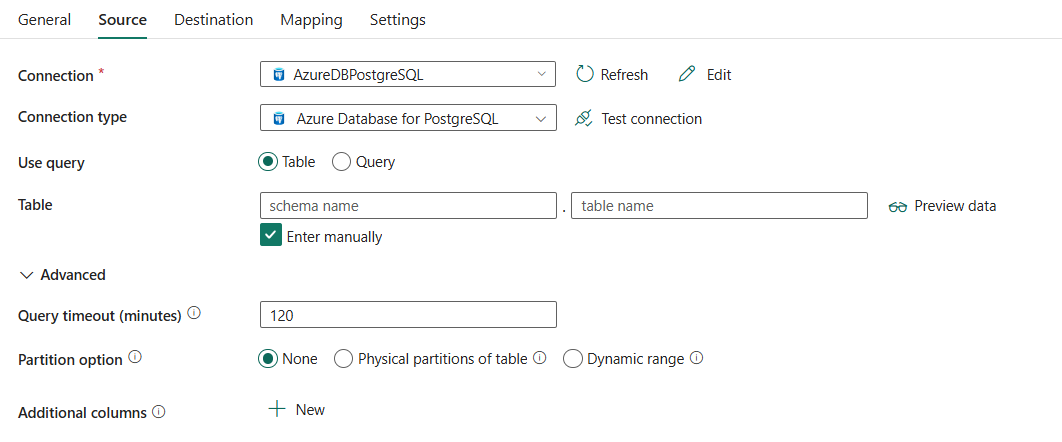
다음 3개의 속성은 필수입니다.
- 연결: 연결 목록에서 Azure Database for PostgreSQL 연결을 선택합니다. 연결이 없으면 새 Azure Database for PostgreSQL 연결을 만듭니다.
- 연결 형식: Azure Database for PostgreSQL을 선택합니다.
-
쿼리 사용: 테이블을 선택하여 지정된 테이블에서 데이터를 읽거나 쿼리를 사용하여 데이터를 읽을 쿼리를 선택합니다.
테이블을 선택한 경우:
테이블: 드롭다운 목록에서 테이블을 선택하거나 수동으로 입력하여 데이터를 읽도록 수동으로 입력합니다.

쿼리를 선택하는 경우:
쿼리: 데이터를 읽는 사용자 지정 SQL 쿼리를 지정합니다. 예를 들어
SELECT * FROM mytable또는SELECT * FROM "MyTable"입니다.참고 항목
PostgreSQL에서 엔터티 이름은 따옴표로 묶지 않은 경우 대/소문자를 구분하지 않는 것으로 취급됩니다.

고급에서 다음 필드를 지정할 수 있습니다.
쿼리 시간 제한(분): 명령 실행 시도를 종료하고 오류를 생성하기 전에 대기 시간을 지정합니다. 기본값은 120분입니다. 이 속성에 대해 매개 변수를 설정한 경우 허용되는 값은 시간 범위(예: "02:00:00"(120분)입니다. 자세한 내용은 CommandTimeout참조하세요.
파티션 옵션: Azure Database for PostgreSQL에서 데이터를 로드하는 데 사용되는 데이터 분할 옵션을 지정합니다. 파티션 옵션이 활성화된 경우(즉, 없음이 아닐 때), Azure Database for PostgreSQL에서 데이터를 동시에 로드하는 병렬 처리 수준은 복사 작업 설정 탭에서 복사 병렬 처리 수준으로 제어됩니다.
없음을 선택하면 파티션을 사용하지 않도록 선택합니다.
테이블의 실제 파티션을 선택하는 경우:
파티션 이름: 복사해야 하는 실제 파티션의 목록을 지정합니다.
쿼리를 사용하여 원본 데이터를 검색하는 경우 WHERE 절에서
?AdfTabularPartitionName를 후크합니다. 예제는 Azure Database for PostgreSQL의 병렬 복사 섹션을 참조하세요.
동적 범위를 선택하는 경우:
파티션 열 이름: 병렬 복사를 위해 범위 분할에서 사용할 원본 열의 이름을 정수 또는 날짜/날짜 시간 형식(
int,smallint,bigint,date,timestamp without time zone,timestamp with time zone, 또는time without time zone)으로 지정합니다. 지정하지 않으면 테이블의 기본 키가 자동으로 검색되어 파티션 열로 사용됩니다.쿼리를 사용하여 원본 데이터를 검색하는 경우 WHERE 절에서
?AdfRangePartitionColumnName를 후크합니다. 예제는 Azure Database for PostgreSQL의 병렬 복사 섹션을 참조하세요.파티션 상한: 데이터를 복사할 파티션 열의 최대값을 지정합니다.
쿼리를 사용하여 원본 데이터를 검색하는 경우 WHERE 절에서
?AdfRangePartitionUpbound를 후크합니다. 예제는 Azure Database for PostgreSQL의 병렬 복사 섹션을 참조하세요. .파티션 하한: 데이터를 복사할 파티션 열의 최소값을 지정합니다.
쿼리를 사용하여 원본 데이터를 검색하는 경우 WHERE 절에서
?AdfRangePartitionLowbound를 후크합니다. 예제는 Azure Database for PostgreSQL의 병렬 복사 섹션을 참조하세요.
추가 열: 데이터 열을 추가하여 원본 파일의 상대 경로 또는 정적 값을 저장하세요. 식은 정적 값에 대해 지원됩니다.
대상
대상 탭으로 이동하여 복사 작업 대상을 구성합니다. 자세한 구성은 다음 내용을 참조하세요.
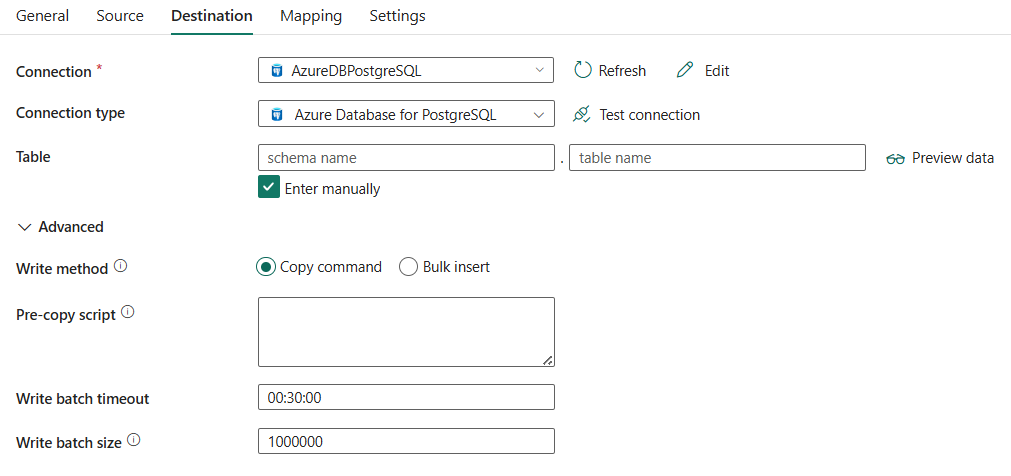
다음 3개의 속성은 필수입니다.
- 연결: 연결 목록에서 Azure Database for PostgreSQL 연결을 선택합니다. 연결이 없으면 새 Azure Database for PostgreSQL 연결을 만듭니다.
- 연결 형식: Azure Database for PostgreSQL을 선택합니다.
- 테이블: 드롭다운 목록에서 테이블을 선택하거나 수동으로 입력을 선택하여 데이터를 씁니다.
고급에서 다음 필드를 지정할 수 있습니다.
Write 메서드: Azure Database for PostgreSQL에 데이터를 쓰기 위해 사용되는 메서드를 선택합니다. Copy 명령(기본값, 성능이 더 좋음) 및 대량 삽입 중에서 선택합니다.
복사 전 스크립트: 각 실행에서 Azure Database for PostgreSQL에 데이터를 쓰기 전에 실행할 복사 작업에 대한 SQL 쿼리를 지정합니다. 이 속성을 사용하여 미리 로드된 데이터를 정리할 수 있습니다.
쓰기 일괄 처리 시간 제한: 일괄 처리 삽입 작업이 시간 초과되기 전에 완료될 때까지의 대기 시간을 지정합니다. 허용되는 값은 시간 간격입니다. 기본값은 00:30:00(30분)입니다.
쓰기 일괄 처리 크기: 각 일괄 처리에서 Azure Database for PostgreSQL에 로드되는 데이터의 행 수를 지정합니다. 허용되는 값은 행 수를 나타내는 정수입니다. 기본값은 1,000,000입니다.
매핑
매핑 탭 구성의 경우 매핑 탭에서 매핑 구성을 참조하세요.
설정
설정 탭을 구성하려면 설정 탭에서 기타 설정 구성으로 이동합니다.
Azure Database for PostgreSQL의 병렬 복사
복사 작업의 Azure Database for PostgreSQL 커넥터는 데이터를 병렬로 복사하는 기본 제공 데이터 분할을 제공합니다. 복사 작업의 원본 탭에서 데이터 분할 옵션을 찾을 수 있습니다.
분할된 복사본을 사용하도록 설정하면 복사 작업이 Azure Database for PostgreSQL 원본에 대해 병렬 쿼리를 실행하여 파티션별로 데이터를 로드합니다. 병렬 수준은 복사 작업 설정 탭의 복사 병렬 처리 수준에 의해 제어됩니다. 예를 들어 복사 병렬 처리 수준을 4로 설정하면 서비스는 지정된 파티션 옵션 및 설정에 따라 4개의 쿼리를 동시에 생성하고 실행하며 각 쿼리는 Azure Database for PostgreSQL에서 데이터의 일부를 검색합니다.
특히 Azure Database for PostgreSQL에서 대량의 데이터를 로드하는 경우 특별히 데이터 분할로 병렬 복사를 사용하도록 설정하는 것이 좋습니다. 다양한 시나리오에 대해 권장되는 구성은 다음과 같습니다. 파일 기반 데이터 저장소에 데이터를 복사할 때 여러 파일로 폴더에 쓰는 것이 좋습니다(폴더 이름만 지정). 이 경우 단일 파일에 쓰는 것보다 성능이 좋습니다.
| 시나리오 | 제안된 설정 |
|---|---|
| 실제 파티션이 있는 대형 테이블에서 전체 로드 |
파티션 옵션: 테이블의 실제 파티션 실행하는 동안 서비스에서 실제 파티션을 자동으로 검색하여 데이터를 파티션별로 복사합니다. |
| 데이터 분할을 위해 물리적 파티션을 사용하지 않지만 정수 열을 사용하여 대형 테이블에서 전체 로드합니다. |
파티션 옵션: 동적 범위입니다. 파티션 열: 데이터를 분할하는 데 사용되는 열을 지정합니다. 지정하지 않으면 기본 키 열이 사용됩니다. |
| 사용자 지정 쿼리를 사용하여 물리적 파티션과 함께 대량의 데이터를 로드합니다. |
파티션 옵션: 테이블의 실제 파티션 쿼리: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.파티션 이름: 데이터를 복사할 파티션 이름을 지정합니다. 지정하지 않으면 서비스는 PostgreSQL 데이터 세트에서 지정한 테이블의 물리적 파티션을 자동으로 검색합니다. 실행하는 동안 서비스는 ?AdfTabularPartitionName을 실제 파티션 이름으로 바꾸고 Azure Database for PostgreSQL로 보냅니다. |
| 물리적 파티션이 없는 사용자 지정 쿼리를 사용하여 대량의 데이터를 로드하는 동시에 데이터 분할을 위한 정수 열을 사용합니다. |
파티션 옵션: 동적 범위입니다. 쿼리: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.파티션 열: 데이터를 분할하는 데 사용되는 열을 지정합니다. 정수, 날짜 또는 날짜/시간 데이터 형식의 열에 대해 분할할 수 있습니다. 파티션 상한 및 파티션 하한: 파티션 열에 대해 필터링하려는 하한과 상한 범위 사이에서만 데이터를 검색하도록 지정합니다. 실행하는 동안 서비스는 ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound, ?AdfRangePartitionLowbound를 각 파티션의 실제 열 이름과 값 범위로 바꾸고 Azure Database for PostgreSQL로 보냅니다. 예를 들어 파티션 열 “ID”의 하한이 1로 설정되고 상한이 80으로 설정된 경우 병렬 복사를 4로 설정하면 서비스는 4개의 파티션으로 데이터를 검색합니다. 해당 ID는 [1, 20], [21, 40], [41, 60] 및 [61, 80] 사이에 각각 있습니다. |
파티션 옵션을 사용하여 데이터를 로드하는 모범 사례:
- 데이터 기울이기를 방지하려면 고유한 열(예: 기본 키 또는 고유 키)을 분할 열로 선택합니다.
- 테이블에 기본 제공 파티션이 있는 경우 "테이블의 실제 파티션" 파티션 옵션을 사용하여 성능을 향상시킵니다.
표 요약
다음 표에는 Azure Database for PostgreSQL의 복사 활동에 대한 자세한 정보가 포함되어 있습니다.
원본 정보
| 이름 | 설명 | 값 | 필수 | JSON 스크립트 속성 |
|---|---|---|---|---|
| 연결 | 원본 데이터 저장소에 대한 연결입니다. | < Azure Database for PostgreSQL 연결 > | 예 | connection |
| 연결 형식 | 원본 연결 형식입니다. | Azure Database for PostgreSQL | 예 | / |
| 쿼리 사용 | 데이터를 읽는 방법. 테이블을 적용하여 지정된 테이블에서 데이터를 읽거나 쿼리를 적용하여 쿼리를 사용하여 데이터를 읽습니다. | • 테이블 • 쿼리 |
예 | • typeProperties(typeProperties - >source)- 스키마 - 테이블 • 쿼리 |
| 쿼리 시간 제한(분) | 명령 실행 시도를 종료하고 오류를 생성하기 전의 대기 시간(기본값은 120분)입니다. 이 속성에 대해 매개 변수를 설정한 경우 허용되는 값은 시간 범위(예: "02:00:00"(120분)입니다. 자세한 내용은 CommandTimeout참조하세요. | timespan | 아니요 | queryTimeout |
| 파티션 이름 | 복사해야 하는 물리적 파티션 목록입니다. 쿼리를 사용하여 원본 데이터를 검색하는 경우 WHERE 절에서 ?AdfTabularPartitionName를 후크합니다. |
< 파티션 이름 > | 아니요 | partitionNames |
| 파티션 열 이름 | 병렬 복사를 위해 범위 분할에서 사용할 원본 열의 이름으로 정수 또는 날짜/날짜/시간 형식(int, smallint, bigint, date, timestamp without time zone, timestamp with time zone, 또는 time without time zone) 형식으로 지정됩니다. 지정하지 않으면 테이블의 기본 키가 자동으로 검색되어 파티션 열로 사용됩니다. |
< 파티션 열 이름 > | 아니요 | partitionColumnName |
| 파티션 상한 | 데이터를 복사할 파티션 열의 최대값입니다. 쿼리를 사용하여 원본 데이터를 검색하는 경우 WHERE 절에 후크 ?AdfRangePartitionUpbound을(를) 연결합니다. |
< 파티션 상한 > | 아니요 | partitionUpperBound |
| 파티션 하한 | 데이터를 복사할 파티션 열의 최소값입니다. 쿼리를 사용하여 원본 데이터를 검색하는 경우 WHERE 절에 후크 ?AdfRangePartitionLowbound을(를) 연결합니다. |
< 파티션 하한 > | 아니요 | partitionLowerBound |
| 추가 열 | 데이터 열을 추가하여 원본 파일의 상대 경로 또는 정적 값을 저장하세요. 식은 정적 값에 대해 지원됩니다. | • 이름 • 값 |
아니요 | additionalColumns: • 이름 • 값 |
대상 정보
| 이름 | 설명 | 값 | 필수 | JSON 스크립트 속성 |
|---|---|---|---|---|
| 연결 | 대상 데이터 저장소에 대한 연결입니다. | < Azure Database for PostgreSQL 연결 > | 예 | connection |
| 연결 형식 | 대상 연결 형식입니다. | Azure Database for PostgreSQL | 예 | / |
| 테이블 | 데이터를 쓸 대상 데이터 테이블입니다. | < 대상 테이블의 이름 > | 예 | typeProperties(typeProperties - >sink)- 스키마 - 테이블 |
| Write 메서드 | Azure Database for PostgreSQL에 데이터를 쓰기 위해 사용되는 메서드입니다. | • Copy 명령 (기본값) • 대량 삽입 |
아니요 | writeMethod: • CopyCommand • BulkInsert |
| 사전 복사 스크립트 | 각 실행에서 Azure Database for PostgreSQL에 데이터를 쓰기 전에 실행할 복사 작업에 대한 SQL 쿼리입니다. 이 속성을 사용하여 미리 로드된 데이터를 정리할 수 있습니다. | < 복사 전 스크립트 > | 아니요 | preCopyScript |
| 쓰기 일괄 처리 시간 제한 | 시간 초과되기 전에 배치 삽입 작업을 완료하기 위한 대기 시간입니다. | timespan (기본값은 00:30:00 - 30분) |
아니요 | writeBatchTimeout |
| 쓰기 일괄 처리 크기 | 일괄 처리당 Azure Database for PostgreSQL에 로드되는 행 수입니다. | 정수 (기본값은 1,000,000입니다.) |
아니요 | writeBatchSize |