dbt를 사용하여 데이터 변환
참고 항목
Apache Airflow 작업은 Apache Airflow에서 구동됩니다.
dbt(데이터 빌드 도구)는 복잡한 SQL 코드를 구조화되고 유지 관리 가능한 방식으로 관리하여 데이터 웨어하우스 내에서 데이터 변환 및 모델링을 간소화하는 오픈 소스 CLI(명령줄 인터페이스) 입니다. 이를 통해 데이터 팀은 분석 파이프라인의 핵심에서 신뢰할 수 있고 테스트 가능한 변환을 만들 수 있습니다.
Apache Airflow와 쌍을 이루는 경우 Airflow의 일정, 오케스트레이션 및 작업 관리 기능을 통해 dbt의 변환 기능이 향상됩니다. Airflow의 워크플로 관리와 함께 dbt의 변환 전문 지식을 사용하는 이 결합된 접근 방식은 효율적이고 강력한 데이터 파이프라인을 제공하여 궁극적으로 더 빠르고 통찰력 있는 데이터 기반 의사 결정으로 이어집니다.
이 자습서에서는 dbt를 사용하여 Microsoft Fabric Data Warehouse에 저장된 데이터를 변환하는 Apache Airflow DAG를 만드는 방법을 보여 줍니다.
필수 조건
시작하려면 먼저 다음 필수 조건을 완료해야 합니다.
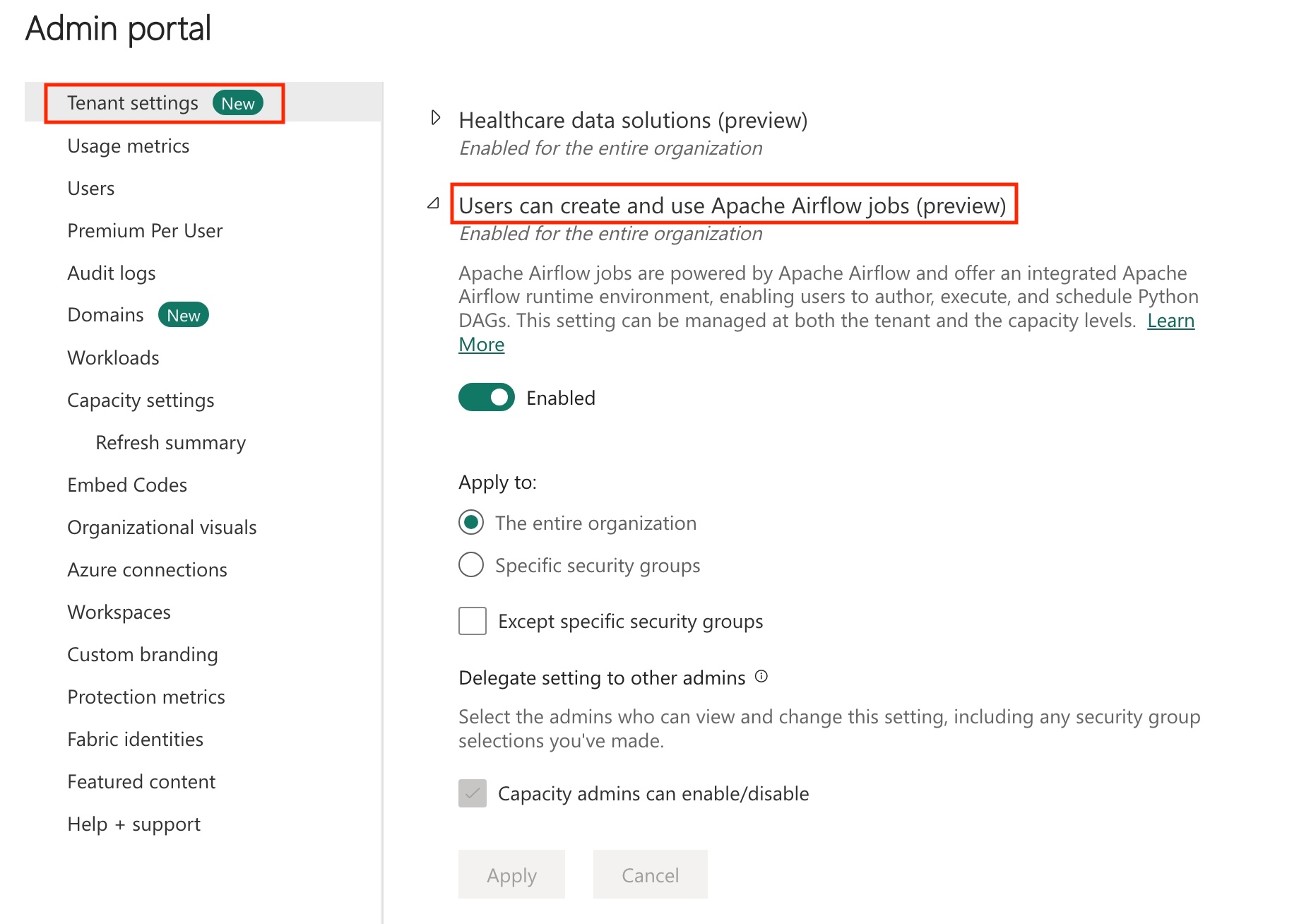
테넌트에서 Apache Airflow 작업을 사용하도록 설정합니다.
참고 항목
Apache Airflow 작업은 미리 보기 상태이므로 테넌트 관리자를 통해 사용하도록 설정해야 합니다. Apache Airflow 작업이 이미 표시되는 경우 테넌트 관리자가 이미 사용하도록 설정했을 수 있습니다.
관리 포털 - 테넌트 설정 ->> Microsoft Fabric>에서 "사용자가 Apache Airflow 작업(미리 보기)을 만들고 사용할 수 있습니다." 섹션으로 이동합니다.
적용을 선택합니다.
서비스 주체 만들기 데이터 웨어하우스를 만드는 작업 영역에 서비스 주체
Contributor를 추가합니다.없는 경우 Fabric Warehouse 생성을 합니다. 데이터 파이프라인을 사용하여 샘플 데이터를 Warehouse에 수집합니다. 이 자습서에서는 NYC Taxi-Green 샘플을 사용합니다.

dbt를 사용하여 Fabric Warehouse의 저장된 데이터 변환
이 섹션에서 다음 단계를 진행할 수 있습니다.
- 요구 사항을 지정합니다.
- Apache Airflow 작업에서 제공하는 패브릭 관리 스토리지에 dbt 프로젝트를 만듭니다.
- dbt 작업을 오케스트레이션하는 Apache Airflow DAG 만들기
요구 사항 지정
dags 폴더에서 requirements.txt인 새 파일을 만듭니다. Apache Airflow 요구 사항으로 다음 패키지를 추가합니다.
astronomer-cosmos: 이 패키지는 Apache Airflow dags 및 작업 그룹으로 dbt 핵심 프로젝트를 실행하는 데 사용됩니다.
dbt-fabric: 이 패키지는 dbt 프로젝트를 만드는 데 사용되며, 그런 다음 패브릭 데이터 웨어하우스에 배포할 수 있습니다.
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Apache Airflow 작업에서 제공하는 패브릭 관리 스토리지에 dbt 프로젝트를 만듭니다.
이 섹션에서는 다음 디렉터리 구조를 사용하여 데이터 세트
nyc_taxi_green에 대한 Apache Airflow 작업에서 샘플 dbt 프로젝트를 만듭니다.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetprofiles.yml파일이 있는dags폴더에nyc_taxi_green라는 이름의 폴더를 만듭니다. 이 폴더에는 dbt 프로젝트에 필요한 모든 파일이 포함되어 있습니다.
다음 콘텐츠를
profiles.yml에 복사합니다. 이 구성 파일에는 dbt에서 사용하는 데이터베이스 연결 세부 정보 및 프로필이 포함되어 있습니다. 자리 표시자 값을 업데이트하고 파일을 저장합니다.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>dbt_project.yml파일을 만들고 다음 내용을 복사합니다. 이 파일은 프로젝트 수준 구성을 지정합니다.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tablenyc_taxi_green폴더에서models폴더를 만듭니다. 이 자습서에서는 공급업체당 일별 여정 수를 보여 주는 테이블을 만드는nyc_trip_count.sql파일의 샘플 모델을 만듭니다. 다음 콘텐츠를 파일에 복사합니다.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


dbt 작업을 오케스트레이션하는 Apache Airflow DAG 만들기
폴더에 명명된
my_cosmos_dag.pydags파일을 만들고 그 안에 다음 내용을 붙여넣습니다.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
DAG 실행
Apache Airflow 작업 내에서 DAG를 실행합니다.
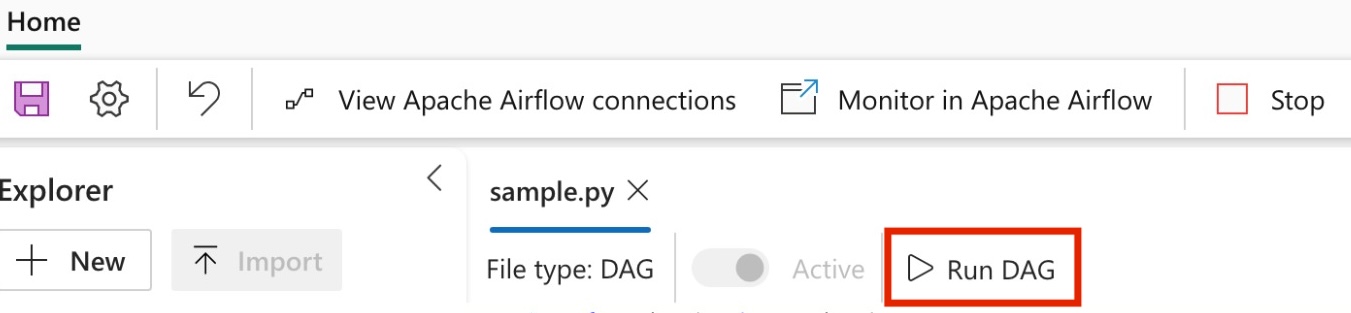
Apache Airflow UI에 로드된 dag를 보려면
Monitor in Apache Airflow.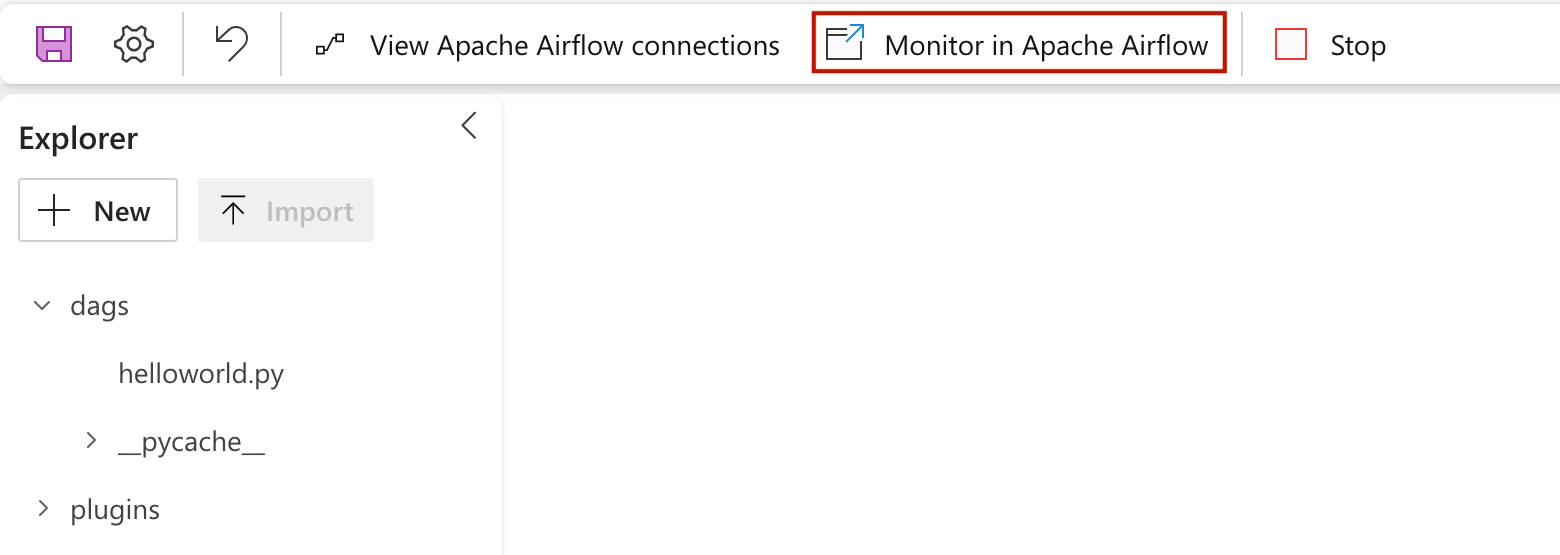
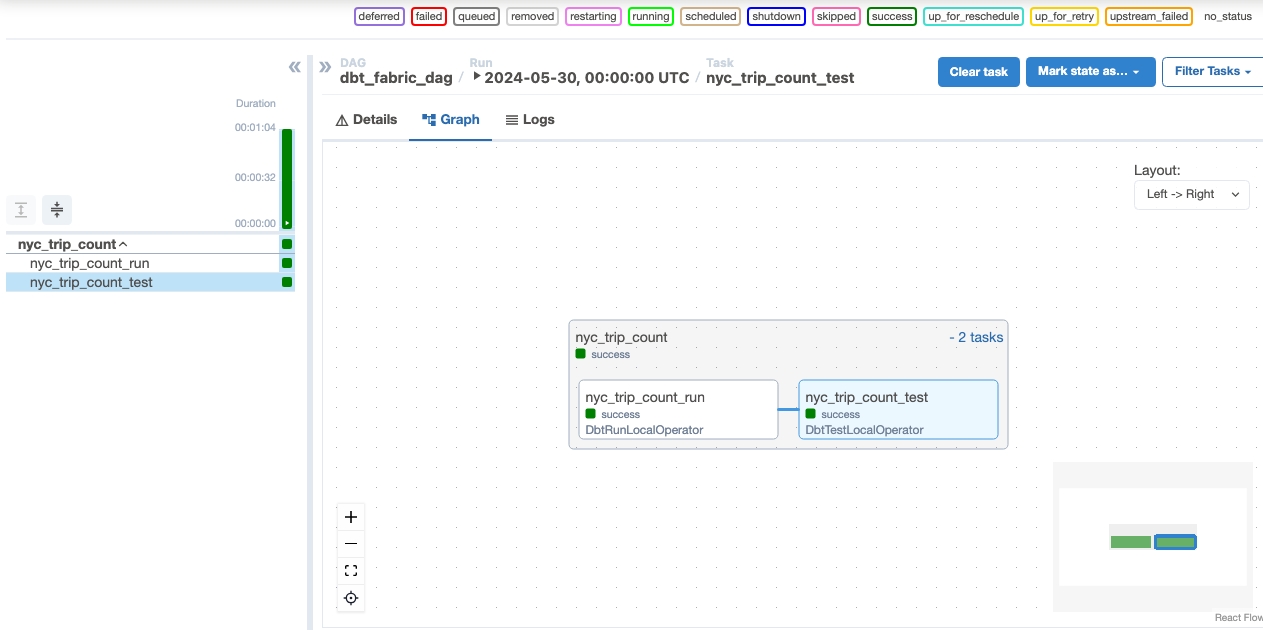



데이터 유효성 검사
- 성공적으로 실행한 후 데이터의 유효성을 검사하기 위해 Fabric 데이터 Warehouse에서 만든 'nyc_trip_count.sql'이라는 새 테이블을 볼 수 있습니다.

