자습서: 시계열 분석 및 ML.NET를 사용하여 자전거 대여 서비스 수요 예측
ML.NET를 통해 SQL Server 데이터베이스에 저장된 데이터에 대한 단일 시계열 분석을 사용하여 자전거 대여 서비스 수요를 예측하는 방법을 알아봅니다.
이 자습서에서는 다음과 같은 작업을 수행하는 방법을 살펴봅니다.
- 문제 이해
- 데이터베이스에서 데이터 로드
- 예측 모델 만들기
- 예측 모델 평가
- 예측 모델 저장
- 예측 모델 사용
사전 요구 사항
- “.NET 데스크톱 개발” 워크로드가 설치된 Visual Studio 2022.
시계열 예측 샘플 개요
이 샘플은 Singular Spectrum Analysis라고 하는 일변량 시계열 분석 알고리즘을 사용하여 자전거 대여 수요를 예측하는 C# .NET Core 콘솔 애플리케이션입니다. 이 샘플의 코드는 GitHub의 dotnet/machinelearning-samples repository에서 찾을 수 있습니다.
문제 이해
효율적인 작업을 실행하기 위해 재고 관리는 주요 역할을 담당합니다. 재고가 너무 많은 제품이 있다면 제품이 판매되지 않은 채 진열대에 쌓여 아무런 수익을 창출하지 않는 것과 같습니다. 제품 수가 너무 적으면 판매 및 고객 손실이 발생하여 경쟁사에게 고객을 빼앗길 수 있습니다. 따라서 가장 적합한 재고 보유량에 대해 끊임없는 질문을 던져야 합니다. 시계열 분석은 기록 데이터를 보고 패턴을 식별하고 이 정보를 사용하여 나중에 값을 예측하는 방식으로 이러한 질문에 대한 답을 제공합니다.
이 자습서에서 사용되는 데이터를 분석하는 방법은 일변량 시계열 분석입니다. 일변량 시계열 분석은 월별 판매량 같은 특정 간격으로 일정 기간의 단일 수치를 확인합니다.
이 자습서에서 사용되는 알고리즘은 SSA(Singular Spectrum Analysis)입니다. SSA는 시계열을 주요 구성 요소 집합으로 분리하는 방식으로 작동합니다. 이러한 구성 요소는 추세, 노이즈, 계절성 및 기타 여러 요소에 해당하는 신호의 일부분으로 해석될 수 있습니다. 그런 다음 이러한 구성 요소가 재구성되어 나중에 값을 예측하는 데 사용됩니다.
콘솔 애플리케이션 만들기
"BikeDemandForecasting"이라는 새 C# 솔 애플리케이션을 만듭니다. 다음 단추를 클릭합니다.
사용할 프레임워크로 .NET 6을 선택합니다. 만들기 단추를 클릭합니다.
Microsoft.ML 버전 NuGet 패키지 설치
참고
이 샘플에서는 별도로 지정하지 않은 한 언급된 NuGet 패키지의 최신 안정화 버전을 사용합니다.
- 솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭하고 NuGet 패키지 관리를 선택합니다.
- 패키지 소스로 “nuget.org”를 선택하고, 찾아보기 탭을 선택하고, Microsoft.ML을 검색합니다.
- 시험판 포함 확인란을 선택합니다.
- 설치 단추를 선택합니다.
- 변경 내용 미리 보기 대화 상자에서 확인 단추를 선택한 다음, 나열된 패키지의 사용 조건에 동의하는 경우 [라이선스 승인] 대화 상자에서 동의함 단추를 선택합니다.
- System.Data.SqlClient 및 Microsoft.ML.TimeSeries에 이러한 단계를 반복합니다.
데이터 준비 및 이해
- 데이터 디렉터리를 만듭니다.
- DailyDemand.mdf 데이터베이스 파일을 다운로드하여 데이터 디렉터리에 저장합니다.
참고
이 자습서에서 사용되는 데이터는 UCI 자전거 공유 데이터 세트에서 제공됩니다. Fanaee-T, Hadi, Gama, Joao, 'Event labeling combining ensemble detectors and background knowledge', Progress in Artificial Intelligence (2013): pp. 1-15, Springer Berlin Heidelberg, 웹 링크.
원본 데이터 세트에는 계절성 및 날씨에 해당하는 여러 열이 포함되어 있습니다. 간단히 하기 위해 이 자습서에서 사용되는 알고리즘에는 단일 숫자 열의 값만 필요하므로 원본 데이터 세트는 다음 열만 포함하도록 압축되었습니다.
- dteday: 관측 날짜입니다.
- year: 인코딩된 관측 연도입니다(0=2011, 1=2012).
- cnt: 해당 일에 대한 총 자전거 대여 수입니다.
원본 데이터 세트는 SQL Server 데이터베이스에서 다음 스키마를 포함하는 데이터베이스 테이블에 매핑됩니다.
CREATE TABLE [Rentals] (
[RentalDate] DATE NOT NULL,
[Year] INT NOT NULL,
[TotalRentals] INT NOT NULL
);
다음은 데이터 샘플입니다.
| RentalDate | Year | TotalRentals |
|---|---|---|
| 1/1/2011 | 0 | 985 |
| 1/2/2011 | 0 | 801 |
| 1/3/2011 | 0 | 1349 |
입력 및 출력 클래스 만들기
Program.cs 파일을 열고 기존
using문을 다음으로 바꿉니다.using Microsoft.ML; using Microsoft.ML.Data; using Microsoft.ML.Transforms.TimeSeries; using System.Data.SqlClient;ModelInput클래스를 만듭니다.Program클래스 아래에 다음 코드를 추가합니다.public class ModelInput { public DateTime RentalDate { get; set; } public float Year { get; set; } public float TotalRentals { get; set; } }ModelInput클래스에는 다음 열이 포함됩니다.- RentalDate: 관측 날짜입니다.
- Year: 인코딩된 관측 연도입니다(0=2011, 1=2012).
- TotalRentals: 해당 일에 대한 총 자전거 대여 수입니다.
새로 만든
ModelInput클래스 아래에ModelOutput클래스를 만듭니다.public class ModelOutput { public float[] ForecastedRentals { get; set; } public float[] LowerBoundRentals { get; set; } public float[] UpperBoundRentals { get; set; } }ModelOutput클래스에는 다음 열이 포함됩니다.- ForecastedRentals: 예측 기간의 예측 값입니다.
- LowerBoundRentals: 예측 기간의 예측 최소값입니다.
- UpperBoundRentals: 예측 기간의 예측 최대값입니다.
경로 정의 및 변수 초기화
using 문 아래에서 데이터의 위치, 연결 문자열 및 학습된 모델을 저장할 위치를 저장하는 변수를 정의합니다.
string rootDir = Path.GetFullPath(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "../../../")); string dbFilePath = Path.Combine(rootDir, "Data", "DailyDemand.mdf"); string modelPath = Path.Combine(rootDir, "MLModel.zip"); var connectionString = $"Data Source=(LocalDB)\\MSSQLLocalDB;AttachDbFilename={dbFilePath};Integrated Security=True;Connect Timeout=30;";경로를 정의한 후 다음 줄을 추가하여 새로운
MLContext인스턴스로mlContext변수를 초기화합니다.MLContext mlContext = new MLContext();MLContext클래스는 모든 ML.NET 작업의 시작점이며, mlContext를 초기화하면 모델 생성 워크플로 개체 간에 공유할 수 있는 새 ML.NET 환경이 생성됩니다. 개념적으로 Entity Framework의DBContext와 유사합니다.
데이터 로드
ModelInput형식의 레코드를 로드하는DatabaseLoader를 만듭니다.DatabaseLoader loader = mlContext.Data.CreateDatabaseLoader<ModelInput>();데이터베이스에서 데이터를 로드하는 쿼리를 정의합니다.
string query = "SELECT RentalDate, CAST(Year as REAL) as Year, CAST(TotalRentals as REAL) as TotalRentals FROM Rentals";ML.NET 알고리즘은 데이터를
Single형식으로 간주합니다. 따라서Real형식이 아닌 데이터베이스에서 가져온 숫자 값(단정밀도 부동 소수점 값)은Real로 변환해야 합니다.Year및TotalRental열은 모두 데이터베이스의 정수 형식입니다.CAST기본 제공 함수를 사용하여Real로 캐스팅됩니다.데이터베이스에 연결하고 쿼리를 실행하는
DatabaseSource를 만듭니다.DatabaseSource dbSource = new DatabaseSource(SqlClientFactory.Instance, connectionString, query);데이터를
IDataView에 로드합니다.IDataView dataView = loader.Load(dbSource);데이터 세트에는 두 개 연도 분량의 데이터가 포함됩니다. 첫 번째 연도의 데이터만 학습에 사용되고, 두 번째 연도는 모델에서 생성된 예측과 실제 값을 비교하는 데 사용됩니다.
FilterRowsByColumn변환을 사용하여 데이터를 필터링합니다.IDataView firstYearData = mlContext.Data.FilterRowsByColumn(dataView, "Year", upperBound: 1); IDataView secondYearData = mlContext.Data.FilterRowsByColumn(dataView, "Year", lowerBound: 1);첫 번째 연도의 경우
upperBound매개 변수를 1로 설정하여Year열의 값만 선택합니다. 반면 두 번째 연도의 경우lowerBound매개 변수를 1로 설정하여 1 이상의 값을 선택합니다.
시계열 분석 파이프라인 정의
SsaForecastingEstimator를 사용하여 시계열 데이터 세트의 값을 예측하는 파이프라인을 정의합니다.
var forecastingPipeline = mlContext.Forecasting.ForecastBySsa( outputColumnName: "ForecastedRentals", inputColumnName: "TotalRentals", windowSize: 7, seriesLength: 30, trainSize: 365, horizon: 7, confidenceLevel: 0.95f, confidenceLowerBoundColumn: "LowerBoundRentals", confidenceUpperBoundColumn: "UpperBoundRentals");forecastingPipeline은 첫 번째 연도와 샘플에 대해 365개의 데이터 요소를 사용하거나 시계열 데이터 세트를seriesLength매개 변수에 지정된 대로 30일(월별) 간격으로 분할합니다. 이러한 각 샘플은 주별 또는 7일 기간을 통해 분석됩니다. 다음 기간에 대한 예측 값을 결정할 때 이전 7일의 값을 사용하여 예측을 수행합니다. 모델은horizon매개 변수로 정의된 대로 향후 7일의 기간을 예측하도록 설정됩니다. 예측은 추측이므로 항상 100% 정확하지는 않습니다. 따라서 상한 및 하한으로 정의된 최선 및 최악의 시나리오 값 범위를 파악하고 있는 것이 좋습니다. 이 경우 하한 및 상한에 대한 신뢰 수준은 95%로 설정됩니다. 신뢰 수준을 적절하게 높이거나 줄일 수 있습니다. 값이 높을수록 원하는 수준의 신뢰도를 얻기 위해 상한 및 하한 간 범위가 넓어집니다.Fit메서드를 사용하여 모델을 학습하고 이전에 정의된forecastingPipeline에 데이터를 맞춥니다.SsaForecastingTransformer forecaster = forecastingPipeline.Fit(firstYearData);
모델 평가
다음 연도의 데이터를 예측하고 실제 값과 비교하여 모델이 얼마나 잘 수행하고 있는지 평가합니다.
Program.cs 파일의 맨 아래에
Evaluate라는 새 유틸리티 메서드를 만듭니다.Evaluate(IDataView testData, ITransformer model, MLContext mlContext) { }Evaluate메서드 내에서 학습된 모델과 함께Transform메서드를 사용하여 두 번째 연도의 데이터를 예측합니다.IDataView predictions = model.Transform(testData);CreateEnumerable메서드를 사용하여 데이터에서 실제 값을 가져옵니다.IEnumerable<float> actual = mlContext.Data.CreateEnumerable<ModelInput>(testData, true) .Select(observed => observed.TotalRentals);CreateEnumerable메서드를 사용하여 예측 값을 가져옵니다.IEnumerable<float> forecast = mlContext.Data.CreateEnumerable<ModelOutput>(predictions, true) .Select(prediction => prediction.ForecastedRentals[0]);일반적으로 오류라고 하는 실제 값과 예측 값의 차이를 계산합니다.
var metrics = actual.Zip(forecast, (actualValue, forecastValue) => actualValue - forecastValue);절대 평균 오차 및 제곱 평균 오차 값을 계산하여 성능을 측정합니다.
var MAE = metrics.Average(error => Math.Abs(error)); // Mean Absolute Error var RMSE = Math.Sqrt(metrics.Average(error => Math.Pow(error, 2))); // Root Mean Squared Error성능을 평가하기 위해 다음 메트릭이 사용됩니다.
- 절대 평균 오차: 예측이 실제 값과 얼마나 근접한지 측정합니다. 이 값의 범위는 0과 무한대 사이입니다. 0에 가까울수록 모델의 품질이 좋습니다.
- 제곱 평균 오차: 모델의 오류를 요약합니다. 이 값의 범위는 0과 무한대 사이입니다. 0에 가까울수록 모델의 품질이 좋습니다.
메트릭을 콘솔에 출력합니다.
Console.WriteLine("Evaluation Metrics"); Console.WriteLine("---------------------"); Console.WriteLine($"Mean Absolute Error: {MAE:F3}"); Console.WriteLine($"Root Mean Squared Error: {RMSE:F3}\n");아래의
Evaluate메서드를 호출하여Fit()메서드를 호출합니다.Evaluate(secondYearData, forecaster, mlContext);
모델 저장
모델에 만족하는 경우 나중에 다른 애플리케이션에서 사용할 수 있도록 저장합니다.
Evaluate()메서드 아래에서TimeSeriesPredictionEngine을 만듭니다.TimeSeriesPredictionEngine은 단일 예측을 만드는 편리한 메서드입니다.var forecastEngine = forecaster.CreateTimeSeriesEngine<ModelInput, ModelOutput>(mlContext);이전에 정의된
modelPath변수에 지정된 대로MLModel.zip이라는 파일에 모델을 저장합니다.Checkpoint메서드를 사용하여 모델을 저장합니다.forecastEngine.CheckPoint(mlContext, modelPath);
모델을 사용하여 수요 예측
Evaluate메서드 아래Forecast라는 새 유틸리티 메서드를 만듭니다.void Forecast(IDataView testData, int horizon, TimeSeriesPredictionEngine<ModelInput, ModelOutput> forecaster, MLContext mlContext) { }Forecast메서드 내에서Predict메서드를 사용하여 다음 7일 동안의 대여를 예측합니다.ModelOutput forecast = forecaster.Predict();7일간의 실제 값과 예측 값을 맞춥니다.
IEnumerable<string> forecastOutput = mlContext.Data.CreateEnumerable<ModelInput>(testData, reuseRowObject: false) .Take(horizon) .Select((ModelInput rental, int index) => { string rentalDate = rental.RentalDate.ToShortDateString(); float actualRentals = rental.TotalRentals; float lowerEstimate = Math.Max(0, forecast.LowerBoundRentals[index]); float estimate = forecast.ForecastedRentals[index]; float upperEstimate = forecast.UpperBoundRentals[index]; return $"Date: {rentalDate}\n" + $"Actual Rentals: {actualRentals}\n" + $"Lower Estimate: {lowerEstimate}\n" + $"Forecast: {estimate}\n" + $"Upper Estimate: {upperEstimate}\n"; });예측 출력을 반복하여 콘솔에 표시합니다.
Console.WriteLine("Rental Forecast"); Console.WriteLine("---------------------"); foreach (var prediction in forecastOutput) { Console.WriteLine(prediction); }
애플리케이션 실행
아래에서
Checkpoint()메서드를 호출하면Forecast메서드가 호출됩니다.Forecast(secondYearData, 7, forecastEngine, mlContext);애플리케이션을 실행합니다. 아래와 유사한 출력이 콘솔에 표시됩니다. 간단히 표시하기 위해 출력이 압축되었습니다.
Evaluation Metrics --------------------- Mean Absolute Error: 726.416 Root Mean Squared Error: 987.658 Rental Forecast --------------------- Date: 1/1/2012 Actual Rentals: 2294 Lower Estimate: 1197.842 Forecast: 2334.443 Upper Estimate: 3471.044 Date: 1/2/2012 Actual Rentals: 1951 Lower Estimate: 1148.412 Forecast: 2360.861 Upper Estimate: 3573.309
실제 값 및 예측 값을 검사하면 다음과 같은 관계가 표시됩니다.
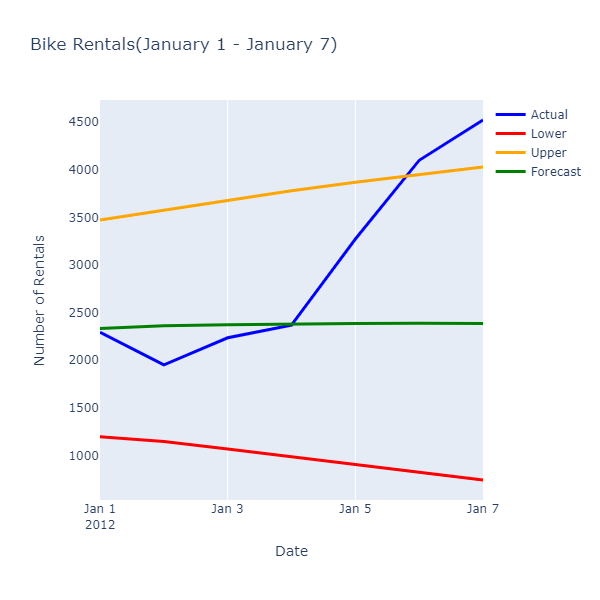
예측 값이 정확한 대여 수를 예측하지는 않지만 더 좁은 범위의 값을 제공하여 작업에서 리소스 사용을 최적화할 수 있습니다.
지금까지 이제 자전거 대여 수요를 예측하는 시계열 기계 학습 모델을 성공적으로 빌드했습니다.
dotnet/samples 리포지토리에서 이 자습서의 소스 코드를 찾을 수 있습니다.
다음 단계
.NET