자습서: ML.NET 이미지 분류 API와 함께 전송 학습을 사용하여 자동화된 시각적 검사
전송 학습, 미리 학습된 TensorFlow 모델 및 ML.NET 이미지 분류 API를 사용하여 사용자 지정 딥 러닝 모델을 학습시켜 콘크리트 표면의 이미지를 금이 가거나 크래킹되지 않은 이미지로 분류하는 방법을 알아봅니다.
이 자습서에서는 다음 방법을 알아봅니다.
- 문제 이해
- ML.NET 이미지 분류 API에 대해 알아보기
- 미리 학습된 모델을 이해하세요
- 전송 학습을 사용하여 사용자 지정 TensorFlow 이미지 분류 모델 학습
- 사용자 지정 모델을 사용하여 이미지 분류
필수 구성 요소
문제 이해
이미지 분류는 컴퓨터 비전 문제입니다. 이미지 분류는 이미지를 입력으로 사용하고 지정된 클래스로 분류합니다. 이미지 분류 모델은 일반적으로 딥 러닝 및 신경망을 사용하여 학습됩니다. 자세한 내용은 딥 러닝과 기계 학습참조하세요.
이미지 분류가 유용한 몇 가지 시나리오는 다음과 같습니다.
- 얼굴 인식
- 감정 감지
- 의료 진단
- 랜드마크 감지
이 자습서에서는 균열로 인해 손상된 구조를 식별하기 위해 브리지 데크의 자동화된 시각적 검사를 수행하는 사용자 지정 이미지 분류 모델을 학습합니다.
이미지 분류 API ML.NET
ML.NET 이미지 분류를 수행하는 다양한 방법을 제공합니다. 이 자습서에서는 이미지 분류 API를 사용하여 전송 학습을 적용합니다. 이미지 분류 API는 TensorFlow C++ API에 대한 C# 바인딩을 제공하는 하위 수준 라이브러리인 TensorFlow.NET사용합니다.
전이 학습이란?
전이 학습은 한 가지 문제를 해결하여 얻은 지식을 다른 관련 문제에 적용합니다.
딥 러닝 모델을 처음부터 학습하려면 여러 매개 변수, 많은 양의 레이블이 지정된 학습 데이터 및 방대한 양의 컴퓨팅 리소스(수백 시간)를 설정해야 합니다. 전이 학습과 함께 사전 학습된 모델을 사용하면 학습 프로세스를 단축할 수 있습니다.
학습 프로세스
이미지 분류 API는 미리 학습된 TensorFlow 모델을 로드하여 학습 프로세스를 시작합니다. 학습 프로세스는 다음 두 단계로 구성됩니다.
- 병목 상태 단계.
- 학습 단계.
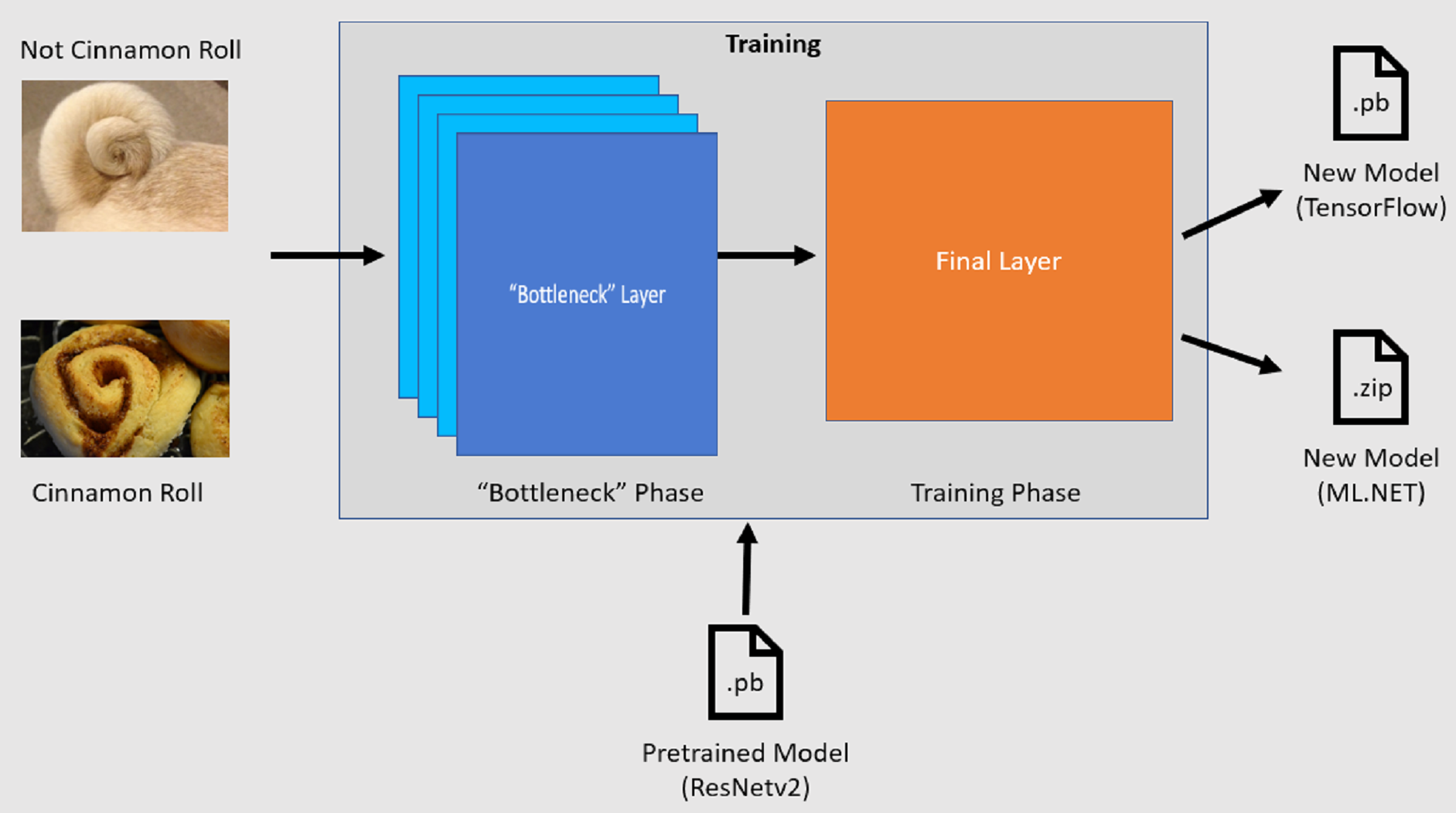
병목 단계
병목 단계에서 학습 이미지 집합이 로드되고, 픽셀 값이 미리 학습된 모델의 고정 계층에 대한 입력 또는 특징으로 사용됩니다. 고정 계층은 신경망의 모든 계층을 끝에서 두 번째 계층까지 포함하며 비공식적으로 병목 현상 계층이라고 합니다. 이러한 계층은 학습이 일어나지 않으며 작업이 단순히 통과되기 때문에 고정된 계층이라고 합니다. 이러한 고정 계층에서는 모델이 서로 다른 클래스를 구분하는 데 도움이 되는 하위 수준 패턴이 계산됩니다. 레이어 수가 많을수록 이 단계는 계산 집약적입니다. 다행히 일회성 계산이므로 다른 매개 변수를 실험할 때 나중에 실행에서 결과를 캐시하고 사용할 수 있습니다.
학습 단계
병목 상태 단계의 출력 값이 계산되면 모델의 최종 계층을 다시 학습하기 위한 입력으로 사용됩니다. 이 프로세스는 반복적이며 모델 매개 변수로 지정된 횟수에 대해 실행됩니다. 각 실행 중에 손실 및 정확도가 평가됩니다. 그런 다음 손실을 최소화하고 정확도를 극대화하는 것을 목표로 모델을 개선하기 위해 적절한 조정이 이루어집니다. 학습이 완료되면 두 개의 모델 형식이 출력됩니다. 그 중 하나는 모델의 .pb 버전이고, 다른 하나는 모델의 .zip ML.NET 직렬화된 버전입니다. ML.NET 지원하는 환경에서 작업하는 경우 모델의 .zip 버전을 사용하는 것이 좋습니다. 그러나 ML.NET 지원되지 않는 환경에서는 .pb 버전을 사용할 수 있습니다.
미리 학습된 모델을 이해하기
이 자습서에서 사용되는 미리 학습된 모델은 잔여 네트워크(ResNet) v2 모델의 101층 변형입니다. 원래 모델은 이미지를 천 개의 범주로 분류하도록 학습됩니다. 모델은 224 x 224 크기의 이미지를 입력으로 사용하고 학습된 각 클래스에 대한 클래스 확률을 출력합니다. 이 모델의 일부는 사용자 지정 이미지를 사용하여 두 클래스 간에 예측을 수행하도록 새 모델을 학습시키는 데 사용됩니다.
콘솔 애플리케이션 만들기
이제 전송 학습 및 이미지 분류 API에 대한 일반적인 이해가 있으므로 애플리케이션을 빌드해야 합니다.
"DeepLearning_ImageClassification_Binary"이라는 C# 콘솔 애플리케이션 만듭니다. 다음 단추를 클릭합니다.
.NET 8을 사용할 프레임워크로 선택한 다음 만들기 선택합니다.
Microsoft.ML NuGet 패키지를 설치합니다.
메모
이 샘플에서는 달리 명시되지 않는 한 언급된 안정적인 최신 버전의 NuGet 패키지를 사용합니다.
- 솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭하고 NuGet 패키지 관리선택합니다.
- 패키지 원본으로 "nuget.org"을 선택합니다.
- 찾아보기 탭을 선택합니다.
- 사전 출시 포함 확인란을 선택합니다.
- Microsoft.ML을 검색합니다.
- 설치 단추를 선택합니다.
- 나열된 패키지의 사용 조건에 동의하면, 라이선스 동의 대화 상자에서 '동의' 버튼을 선택하십시오.
- Microsoft.ML.Vision
, SciSharp.TensorFlow.Redist(버전 2.3.1) 및 Microsoft.ML.ImageAnalytics NuGet 패키지대해 이러한 단계를 반복합니다.
데이터 준비 및 이해
메모
이 자습서의 데이터 세트는 Marc Maguire, Sattar Dorafshan 및 Robert J. Thomas가 제공한 "SDNET2018: 기계 학습 애플리케이션을 위한 콘크리트 균열 이미지 데이터 세트"(2018)에서 가져왔습니다. 모든 데이터 세트를 찾습니다. 문서 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018은 금이 간 및 금이 가지 않은 콘크리트 구조물(교량 상판, 벽 및 포장도로)에 대한 주석이 포함된 이미지 데이터 세트입니다.

데이터는 세 개의 하위 디렉터리로 구성됩니다.
- D에는 브리지 데크 이미지가 포함되어 있습니다.
- P에는 도로 이미지가 포함되어 있습니다.
- W에는 벽 이미지가 포함되어 있습니다.
이러한 각 하위 디렉터리에는 두 개의 추가 접두사 하위 디렉터리가 포함됩니다.
- C는 금이 간 표면에 사용되는 접두사입니다.
- U는 크래킹되지 않은 표면에 사용되는 접두사입니다.
이 자습서에서는 브리지 데크 이미지만 사용됩니다.
- 데이터 세트을 다운로드한 후 압축을 풉니다.
- 프로젝트에 "Assets"라는 디렉터리를 만들어 데이터 세트 파일을 저장합니다.
- CD 및 UD 하위 디렉터리를 최근에 압축 해제된 디렉터리에서 Assets 디렉터리로 복사합니다.
입력 및 출력 클래스 만들기
Program.cs 파일을 열고 기존 콘텐츠를 다음
using지시문으로 바꿉니다.using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;ImageData클래스를 만듭니다. 이 클래스는 처음에 로드된 데이터를 나타내는 데 사용됩니다.class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageData다음 속성을 포함합니다.-
ImagePath이미지가 저장되는 정규화된 경로입니다. -
Label이미지가 속한 범주입니다. 이는 예측할 값입니다.
-
입력 및 출력 데이터에 대한 클래스를 만듭니다.
ImageData클래스 아래에서ModelInput라는 새 클래스에서 입력 데이터의 스키마를 정의합니다.class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInput다음 속성을 포함합니다.-
Image이미지의byte[]표현입니다. 모델은 이미지 데이터가 학습을 위해 이 유형이어야 합니다. -
LabelAsKeyLabel숫자 표현입니다. -
ImagePath이미지가 저장되는 정규화된 경로입니다. -
Label이미지가 속한 범주입니다. 이는 예측할 값입니다.
Image및LabelAsKey만 모델을 학습하고 예측하는 데 사용됩니다.ImagePath및Label속성은 원래 이미지 파일 이름 및 범주에 액세스하기 위해 편리하게 유지됩니다.-
그런 다음,
ModelInput클래스 아래에서ModelOutput이라는 새 클래스에서 출력 데이터의 스키마를 정의합니다.class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutput다음 속성을 포함합니다.-
ImagePath이미지가 저장되는 정규화된 경로입니다. -
Label이미지가 속한 원래 범주입니다. 이는 예측할 값입니다. -
PredictedLabel모델이 예측하는 값입니다.
ModelInput와 마찬가지로, 모델이 예측한 결과를 포함하고 있는PredictedLabel만 있으면 예측을 수행할 수 있습니다. 원래 이미지 파일 이름 및 범주에 액세스하기 위해ImagePath및Label속성이 유지됩니다.-
경로 정의 및 변수 초기화
using지시문 아래에 다음 코드를 추가합니다.자산의 위치를 정의합니다.
MLContext새 인스턴스를 사용하여
mlContext변수를 초기화합니다.MLContext 클래스는 모든 ML.NET 작업의 시작점이며, mlContext를 초기화하면 모델 생성 워크플로 개체 간에 공유할 수 있는 새 ML.NET 환경이 만들어집니다. 개념적으로 Entity Framework에서
DbContext것과 비슷합니다.
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
데이터 로드
데이터 로드 유틸리티 메서드 만들기
이미지는 두 개의 하위 디렉터리에 저장됩니다. 데이터를 로드하기 전에 ImageData 개체 목록에 서식을 지정해야 합니다. 이렇게 하려면 LoadImagesFromDirectory 메서드를 만듭니다.
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
LoadImagesFromDirectory 메서드:
- 하위 디렉터리에서 모든 파일 경로를 가져옵니다.
-
foreach문을 사용하여 각 파일을 반복하고 파일 확장자가 지원되는지 확인합니다. 이미지 분류 API는 JPEG 및 PNG 형식을 지원합니다. - 파일의 레이블을 가져옵니다.
useFolderNameAsLabel매개 변수가true설정되면 파일이 저장된 부모 디렉터리가 레이블로 사용됩니다. 그렇지 않으면 레이블이 파일 이름 자체 또는 해당 파일 이름의 접두사여야 합니다. -
ModelInput새 인스턴스를 생성합니다.
데이터 준비
MLContext새 인스턴스를 만드는 줄 다음에 다음 코드를 추가합니다.
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
이전 코드:
LoadImagesFromDirectory유틸리티 메서드를 호출하여mlContext변수를 초기화한 후 학습에 사용되는 이미지 목록을 가져옵니다.LoadFromEnumerable메서드를 이용해 이미지를IDataView에 로드합니다.ShuffleRows메서드를 사용하여 데이터를 섞습니다. 데이터는 디렉터리에서 읽은 순서대로 로드됩니다. 순서 섞기는 균형을 맞추기 위해 수행됩니다.학습하기 전에 데이터에 대한 일부 전처리를 수행합니다. 이 작업은 기계 학습 모델에서 입력이 숫자 형식이 될 것으로 예상하기 때문에 수행됩니다. 전처리 코드는
MapValueToKey및LoadRawImageBytes변환으로 구성된EstimatorChain만듭니다.MapValueToKey변환은Label열의 범주 값을 가져와 숫자KeyType값으로 변환하고LabelAsKey이라는 새 열에 저장합니다.LoadImagesImagePath열의 값을imageFolder매개 변수와 함께 사용하여 학습을 위해 이미지를 로드합니다.Fit메서드를 사용하여 데이터를preprocessingPipelineEstimatorChain에 적용한 다음,Transform메서드를 사용하여 전처리된 데이터를 포함하는IDataView를 반환합니다.데이터를 학습, 유효성 검사 및 테스트 집합으로 분할합니다.
모델을 학습하려면 학습 데이터 세트와 유효성 검사 데이터 세트가 있어야 합니다. 모델은 훈련 데이터셋으로 훈련됩니다. 보이지 않는 데이터에 대한 예측을 얼마나 잘 만드는지는 유효성 검사 집합에 대한 성능으로 측정됩니다. 해당 성능의 결과에 따라 모델은 개선을 위해 학습한 내용을 조정합니다. 유효성 검사 집합은 원래 데이터 세트를 분할하거나 이 목적을 위해 이미 따로 설정된 다른 원본에서 가져올 수 있습니다.
코드 샘플은 두 분할을 수행합니다. 먼저 전처리된 데이터가 분할되고 70개의% 학습에 사용되고 나머지 30개% 유효성 검사에 사용됩니다. 그런 다음, 30개의% 유효성 검사 집합이 유효성 검사 및 테스트 집합으로 더 분할됩니다. 여기서 90개의% 유효성 검사에 사용되고 10개의% 테스트에 사용됩니다.
이러한 데이터 파티션의 목적을 생각하는 한 가지 방법은 시험을 치르는 것입니다. 시험을 공부할 때 노트, 책 또는 기타 리소스를 검토하여 시험에 있는 개념을 파악합니다. 이것이 바로 기차 세트의 용도입니다. 그런 다음 모의 시험을 통해 지식의 유효성을 검사할 수 있습니다. 여기서 유효성 검사 집합을 편리하게 사용할 수 있습니다. 실제 시험에 응시하기 전에 개념을 잘 이해하고 있는지 확인하려고 합니다. 이러한 결과에 따라 잘못했거나 잘 이해하지 못한 내용을 기록하고 실제 시험을 검토할 때 변경 내용을 통합합니다. 마지막으로 시험에 응시합니다. 이것이 테스트 집합이 사용되는 용도입니다. 시험에 있는 질문을 본 적이 없으며, 이제 학습 및 유효성 검사에서 배운 내용을 사용하여 현재 작업에 지식을 적용합니다.
파티션에 학습, 검증, 및 테스트 데이터에 각기 다른 값을 할당합니다.
학습 파이프라인 정의
모델 학습은 두 단계로 구성됩니다. 먼저 이미지 분류 API를 사용하여 모델을 학습합니다. 그런 다음 PredictedLabel 열의 인코딩된 레이블은 MapKeyToValue 변환을 사용하여 원래 범주 값으로 다시 변환됩니다.
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
이전 코드:
ImageClassificationTrainer대한 필수 및 선택적 매개 변수 집합을 저장하는 새 변수를 만듭니다. ImageClassificationTrainer 몇 가지 선택적 매개 변수를 사용합니다.
-
FeatureColumnName모델의 입력으로 사용되는 열입니다. - 예측할 값의 열은
LabelColumnName입니다. -
IDataView은 유효성 검사 데이터를 포함하는ValidationSet입니다. -
Arch은 사용할 미리 학습된 모델 아키텍처를 정의합니다. 이 자습서에서는 ResNetv2 모델의 101층 변형을 사용합니다. -
MetricsCallback함수를 바인딩하여 학습 중에 진행률을 추적합니다. -
TestOnTrainSet유효성 검사 집합이 없을 때 학습 집합에 대한 성능을 측정하도록 모델에 지시합니다. -
ReuseTrainSetBottleneckCachedValues이후 실행에서 병목 상태 단계에서 캐시된 값을 사용할지 여부를 모델에 알려줍니다. 병목 현상 단계는 처음 수행될 때 계산 집약적인 일회성 통과 계산입니다. 학습 데이터가 변경되지 않고 다른 수의 Epoch 또는 일괄 처리 크기를 사용하여 실험하려는 경우 캐시된 값을 사용하면 모델 학습에 필요한 시간이 크게 줄어듭니다. -
ReuseValidationSetBottleneckCachedValues는 이 경우 유효성 검증 데이터 세트를 위한 것으로ReuseTrainSetBottleneckCachedValues과 유사합니다.
-
mapLabelEstimatorImageClassificationTrainer모두 구성된EstimatorChain학습 파이프라인을 정의합니다.Fit메서드를 사용하여 모델을 학습합니다.
모델 사용
모델을 학습했으므로 이제 이미지를 분류하는 데 사용할 시간입니다.
OutputPrediction라는 새 유틸리티 메서드를 만들어 콘솔에 예측 정보를 표시합니다.
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
단일 이미지 분류
단일 이미지 예측을 만들고 출력하는
ClassifySingleImage메서드를 만듭니다.static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }ClassifySingleImage메서드:-
ClassifySingleImage메서드 내에서PredictionEngine을 만듭니다. 이PredictionEngine은(는) 단일 데이터 인스턴스를 입력하여 예측을 수행할 수 있는 편리한 API입니다. - 단일
ModelInput인스턴스에 액세스하려면CreateEnumerable메서드를 사용하여dataIDataViewIEnumerable변환한 다음 첫 번째 관찰을 가져옵니다. -
Predict메서드를 사용하여 이미지를 분류합니다. -
OutputPrediction메서드를 사용하여 콘솔에 예측을 출력합니다.
-
테스트 이미지 집합을 사용하여
Fit메서드를 호출한 후ClassifySingleImage호출합니다.ClassifySingleImage(mlContext, testSet, trainedModel);
여러 이미지 분류
여러 이미지 예측을 만들고 출력하는
ClassifyImages메서드를 만듭니다.static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }ClassifyImages메서드:-
Transform메서드를 사용하여 예측을 포함하는IDataView을 만듭니다. - 예측을 반복하기 위해
CreateEnumerable메서드를 사용하여predictionDataIDataViewIEnumerable변환한 다음 처음 10개의 관찰을 가져옵니다. - 예측에 대한 원래 및 예측 레이블을 반복하고 출력합니다.
-
테스트 이미지 집합을 사용하여
ClassifySingleImage()메서드를 호출한 후ClassifyImages호출합니다.ClassifyImages(mlContext, testSet, trainedModel);
애플리케이션 실행
콘솔 앱을 실행합니다. 출력은 다음 출력과 유사해야 합니다.
메모
경고 또는 처리 메시지가 표시될 수 있습니다. 이러한 메시지는 명확성을 위해 다음 결과에서 제거되었습니다. 간단히 하기 위해 출력이 압축되었습니다.
병목 상태 단계
이미지가 byte[] 로드되므로 표시할 이미지 이름이 없으므로 이미지 이름에 대한 값이 인쇄되지 않습니다.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
학습 단계
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
이미지 분류 출력
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
7001-220.jpg 이미지를 검사하면, 모델이 예측한 대로 금이 가지 않았음을 확인할 수 있습니다.
 예측에 사용되는
예측에 사용되는
축하합니다! 이제 이미지를 분류하기 위한 딥 러닝 모델을 성공적으로 빌드했습니다.
모델 개선
모델의 결과에 만족하지 않는 경우 다음 방법 중 일부를 시도하여 성능을 향상시키려고 할 수 있습니다.
- 더 많은 데이터
: 모델이 학습하는 예제가 많을수록 성능이 향상됩니다. 전체 SDNET2018 데이터 세트를 다운로드하여 학습에 사용하십시오. - 데이터 증강: 데이터를 다양화하는 일반적인 기술은 이미지를 사용하고 회전, 뒤집기, 이동, 자르기의 변환을 적용하여 데이터를 증강하는 것입니다. 이렇게 하면 모델에서 학습할 수 있는 더 다양한 예제가 추가됩니다.
- 더 긴 시간 동안 학습하세요: 학습 시간이 길수록 모델이 더욱 정교해집니다. Epoch 수를 늘리면 모델의 성능이 향상될 수 있습니다.
- 하이퍼 매개 변수실험: 이 자습서에서 사용되는 매개 변수 외에도 다른 매개 변수를 조정하여 성능을 향상시킬 수 있습니다. 각 Epoch 이후 모델에 대한 업데이트 크기를 결정하는 학습 속도를 변경하면 성능이 향상될 수 있습니다.
- 다른 모델 아키텍처사용: 데이터의 모양에 따라 해당 기능을 가장 잘 학습할 수 있는 모델이 다를 수 있습니다. 모델의 성능에 만족하지 않는 경우 아키텍처를 변경해 보세요.
다음 단계
이 자습서에서는 전송 학습, 미리 학습된 이미지 분류 TensorFlow 모델 및 ML.NET 이미지 분류 API를 사용하여 사용자 지정 딥 러닝 모델을 빌드하여 콘크리트 표면의 이미지를 금이 가거나 크래킹되지 않은 이미지로 분류하는 방법을 알아보았습니다.
자세한 내용을 보려면 다음 자습서로 진행하세요.
참고 사항
- 샘플: ML.NET 및 TensorFlow 사용하여 딥 러닝 이미지 분류 모델 학습
.NET