회로 차단기 패턴 구현
팁
이 콘텐츠는 eBook, 컨테이너화된 .NET 애플리케이션을 위한 .NET 마이크로 서비스 아키텍처에서 발췌한 것이며, .NET 문서에서 제공되거나 오프라인 상태에서도 읽을 수 있는 PDF(무료 다운로드 가능)로 제공됩니다.

앞에서 설명한 것처럼 원격 서비스나 리소스에 연결할 때 발생할 수 있는 복구에 소요되는 시간이 유동적인 오류를 처리해야 합니다. 이러한 종류의 오류를 처리하면 애플리케이션의 안정성과 탄력성을 높일 수 있습니다.
분산된 환경에서는 느린 네트워크 연결 및 시간 초과 등과 같은 일시적 오류 때문에, 또는 리소스가 느리게 응답하거나 일시적으로 사용할 수 없어 원격 리소스 및 서비스에 대한 호출이 실패할 수 있습니다. 이러한 오류는 일반적으로 짧은 시간 안에 자체적으로 해결되며, "다시 시도 패턴"과 같은 전략을 사용하여 이러한 오류를 처리할 수 있는 강력한 클라우드 애플리케이션을 준비해야 합니다.
그러나 해결에 더 오랜 시간이 필요한 예기치 않은 이벤트로 인한 오류 상황도 있을 수 있습니다. 이러한 오류는 심각도의 범위가 연결의 부분적인 손실에서 서비스의 전체 오류까지 퍼질 수 있습니다. 이러한 상황에서 애플리케이션이 성공할 가능성이 없는 작업을 계속 다시 시도하는 것은 무의미할 수 있습니다.
이보다는 작업에 실패했음을 받아들이고 그에 따라 오류를 처리하도록 애플리케이션을 코딩해야 합니다.
Http 다시 시도를 부주의하게 사용하면 자신의 소프트웨어 내에서 DoS(서비스 거부) 공격이 발생할 수 있습니다. 마이크로 서비스가 실패하거나 느리게 수행되면 여러 클라이언트에서 실패한 요청을 반복적으로 다시 시도할 수 있습니다. 이로 인해 실패한 서비스를 대상으로 하는 트래픽이 기하 급수적으로 증가할 위험이 있습니다.
따라서 계속 시도할 필요가 없는 경우 과도한 요청을 중지할 수 있도록 일종의 방어막이 필요합니다. 이러한 방어막은 정확히 회로 차단기입니다.
회로 차단기 패턴은 "다시 시도 패턴"과 다른 용도로 사용됩니다. "다시 시도 패턴"을 사용하면 애플리케이션에서 작업이 결국 성공한다고 예상하여 작업을 다시 시도할 수 있습니다. 회로 차단기 패턴은 애플리케이션이 실패할 가능성이 있는 작업을 수행하지 않도록 합니다. 애플리케이션에서 이 두 패턴을 결합할 수 있습니다. 그러나 다시 시도 논리는 회로 차단기에서 반환하는 모든 예외에 민감해야 하며, 회로 차단기에서 일시적 오류가 아니라고 나타내는 경우 다시 시도를 중단해야 합니다.
IHttpClientFactory 및 Polly를 통한 회로 차단기 패턴 구현
다시 시도를 구현할 때 회로 차단기에 권장되는 방법은 Polly와 같이 입증된 .NET 라이브러리와 IHttpClientFactory와의 네이티브 통합을 활용하는 것입니다.
IHttpClientFactory 나가는 미들웨어 파이프라인에 회로 차단기 정책을 추가하는 것은 IHttpClientFactory를 사용할 때 이미 사용하고 있는 코드에 하나의 증분 코드 부분을 추가하는 것만큼 매우 간단합니다.
여기서 HTTP 호출 다시 시도에 사용된 코드에 추가되는 유일한 부분은 다음 증분 코드와 같이 사용하려는 정책 목록에 회로 차단기 정책을 추가하는 코드입니다.
// Program.cs
var retryPolicy = GetRetryPolicy();
var circuitBreakerPolicy = GetCircuitBreakerPolicy();
builder.Services.AddHttpClient<IBasketService, BasketService>()
.SetHandlerLifetime(TimeSpan.FromMinutes(5)) // Sample: default lifetime is 2 minutes
.AddHttpMessageHandler<HttpClientAuthorizationDelegatingHandler>()
.AddPolicyHandler(retryPolicy)
.AddPolicyHandler(circuitBreakerPolicy);
AddPolicyHandler()는 사용할 HttpClient 개체에 정책을 추가하는 메서드입니다. 이 경우 회로 차단기에 대한 Polly 정책이 추가됩니다.
좀 더 모듈화된 방법을 사용하기 위해 회로 차단기 정책은 다음 코드와 같이 GetCircuitBreakerPolicy()라는 별도의 메서드로 정의됩니다.
// also in Program.cs
static IAsyncPolicy<HttpResponseMessage> GetCircuitBreakerPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.CircuitBreakerAsync(5, TimeSpan.FromSeconds(30));
}
위의 코드 예제에서 Http 요청을 다시 시도할 때 5개의 연속된 오류가 발생하면 회로를 차단하거나 열리도록 회로 차단기 정책이 구성되었습니다. 이 경우 회로가 30초 동안 끊깁니다. 이 기간에는 호출이 실제로 배치되는 것이 아니라 회로 차단기에 의해 즉시 실패하게 됩니다. 정책은 관련 예외 및 HTTP 상태 코드를 자동으로 오류로 해석합니다.
또한 HTTP 호출을 수행하는 클라이언트 애플리케이션 또는 서비스와 다른 환경에 배포된 특정 리소스에 문제가 있는 경우 회로 차단기를 사용하여 요청을 대체 인프라로 리디렉션해야 합니다. 이런 식으로 클라이언트 애플리케이션이 아닌 백 엔드 마이크로 서비스에만 영향을 미치는 데이터 센터에서 중단이 발생한 경우, 클라이언트 애플리케이션이 대체(fallback) 서비스로 리디렉션할 수 있습니다. Polly는 이 장애 조치(failover) 정책 시나리오를 자동화하기 위해 새 정책을 계획하고 있습니다.
이러한 모든 기능은 사용자를 위해 Azure에서 위치 투명성을 사용하여 자동으로 관리하는 대신, .NET 코드 내에서 장애 조치를 관리하는 경우를 위한 것입니다.
사용 관점에서 HttpClient를 사용하는 경우 이전 섹션과 같이 코드가 IHttpClientFactory를 통해 HttpClient를 사용할 때와 동일하므로 여기서는 추가할 새로운 내용이 없습니다.
eShopOnContainers에서 HTTP 다시 시도 및 회로 차단기 테스트
Docker 호스트에서 eShopOnContainers 솔루션을 시작할 때마다 여러 컨테이너를 시작해야 합니다. SQL Server 컨테이너처럼 일부 컨테이너는 시작과 초기화가 더 느립니다. 특히 처음 Docker에 eShopOnContainers 애플리케이션을 배포하는 경우 이미지와 데이터베이스를 설정해야 하기 때문에 이 문제가 더욱 두드러집니다. 일부 컨테이너가 다른 컨테이너보다 늦게 시작되기 때문에 이전 섹션에서 설명한 대로 도커-작성 수준에서 컨테이너 간의 종속성을 설정했다 하더라도 나머지 서비스에서 최초에 HTTP 예외가 발생할 수 있습니다. 이러한 컨테이너 간 도커-작성 종속성은 프로세스 수준에 국한됩니다. 컨테이너의 진입점 프로세스는 시작될 수 있지만 SQL Server는 쿼리 준비가 되지 않았을 수 있습니다. 그 결과 오류가 연쇄 발생하고 특정 컨테이너를 사용하려 할 때 애플리케이션에 예외가 발생할 수 있습니다.
또한 애플리케이션을 클라우드에 배포할 때도 시작 중에 이런 종류의 오류가 발생할 수 있습니다. 이 경우 클러스터의 노드 전체에서 컨테이너 수의 균형을 유지할 때 오케스트레이터가 한 노드나 VM의 컨테이너를 다른 곳으로 옮길 수 있습니다(즉 새 인스턴스 시작).
모든 컨테이너를 시작할 때 이러한 문제를 해결하는 'eShopOnContainers' 방법은 앞에서 설명한 다시 시도 패턴을 사용하는 것입니다.
eShopOnContainers에서 회로 차단기 테스트
eShopOnContainers를 사용하여 회로를 차단하거나 열고, 테스트할 수 있는 몇 가지 방법이 있습니다.
한 옵션은 회로 차단기 정책에서 재시도 허용 횟수를 1로 낮추고 전체 솔루션을 Docker에 다시 배포하는 것입니다. 단일 재시도 상황에서 배포 중에 HTTP 요청이 실패하면 회로 차단기가 열리고 오류가 발생하게 됩니다.
또 다른 옵션은 Basket 마이크로 서비스에서 구현된 사용자 지정 미들웨어를 사용하는 것입니다. 이 미들웨어를 사용할 때는 모든 HTTP 요청이 캐시되고 상태 코드 500을 반환합니다. 다음과 같이 실패 URI에 대한 GET 요청을 수행하여 마들웨어를 사용할 수 있습니다.
GET http://localhost:5103/failing
이 요청은 미들웨어의 현재 상태를 반환합니다. 미들웨어를 사용할 경우 이 요청은 상태 코드 500을 반환합니다. 미들웨어를 사용하지 않으면 응답이 없습니다.GET http://localhost:5103/failing?enable
이 요청은 미들웨어를 사용합니다.GET http://localhost:5103/failing?disable
이 요청은 미들웨어를 사용하지 않습니다.
예를 들어, 애플리케이션이 실행되면 아무 브라우저에서나 다음 URI를 통해 요청을 수행하여 미들웨어를 사용합니다. 순서 지정 마이크로 서비스는 포트 5103을 사용합니다.
http://localhost:5103/failing?enable
그런 다음, 그림 8-5와 같이 URI http://localhost:5103/failing을 사용하여 상태를 확인할 수 있습니다.
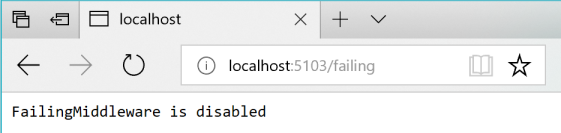
그림 8-5. “실패” ASP.NET 미들웨어의 상태 확인 - 이 경우 사용하지 않습니다.
이 시점에서 Basket 마이크로 서비스는 호출될 때마다 상태 코드 500으로 응답합니다.
미들웨어가 실행되면 MVC 웹 애플리케이션으로부터 주문을 시도해 볼 수 있습니다. 요청이 실패하기 때문에 회로가 열립니다.
다음 예제에서는 MVC 웹 애플리케이션의 논리에 주문 수행을 위한 수집 블록이 있습니다. 이 코드가 열림-회로 예외를 수집하면 사용자에게 기다리라고 알리는 친숙한 메시지를 표시합니다.
public class CartController : Controller
{
//…
public async Task<IActionResult> Index()
{
try
{
var user = _appUserParser.Parse(HttpContext.User);
//Http requests using the Typed Client (Service Agent)
var vm = await _basketSvc.GetBasket(user);
return View(vm);
}
catch (BrokenCircuitException)
{
// Catches error when Basket.api is in circuit-opened mode
HandleBrokenCircuitException();
}
return View();
}
private void HandleBrokenCircuitException()
{
TempData["BasketInoperativeMsg"] = "Basket Service is inoperative, please try later on. (Business message due to Circuit-Breaker)";
}
}
다음은 요약 정보입니다. 재시도 정책이 HTTP 요청을 수행하기 위해 몇 차례 시도했고 HTTP 오류를 받았습니다. 회로 차단기 정책에 설정된 최대 다시 시도 횟수(이 경우 5)에 도달하면 애플리케이션에서 BrokenCircuitException을 throw합니다. 그 결과 그림 8-6처럼 사용자에게 친숙한 메시지가 표시됩니다.
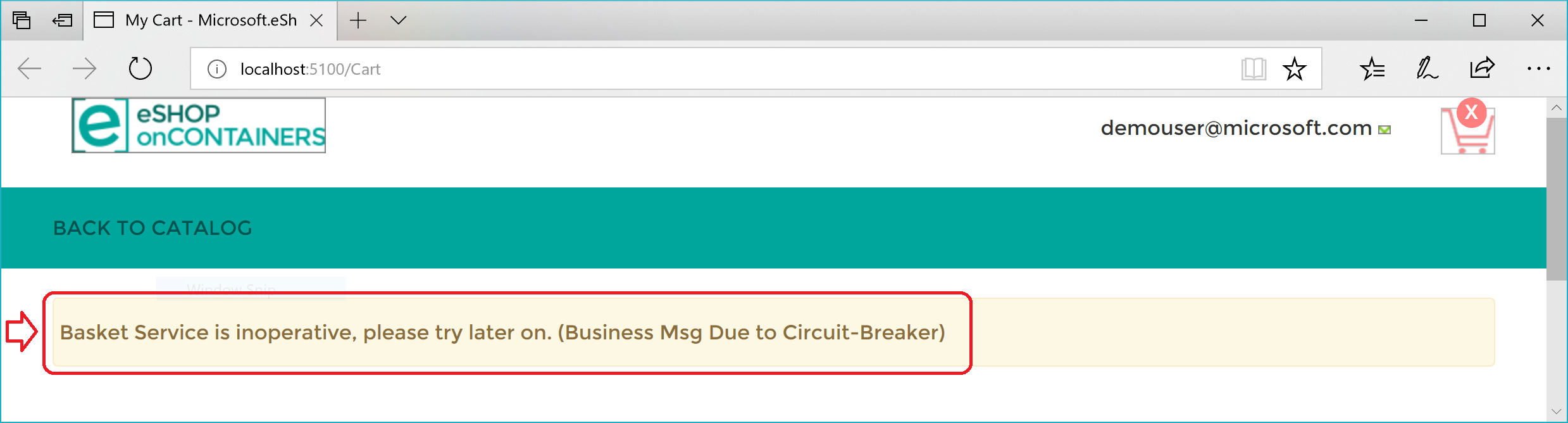
그림 8-6. UI에 오류를 반환한 회로 차단기
회로를 열거나 차단하는 경우에 대해 다른 논리를 구현할 수 있습니다. 또는 대체 데이터 센터나 중복 백 엔드 시스템이 있는 경우 다른 백 엔드 마이크로 서비스에 대해 HTTP 요청을 시도할 수 있습니다.
마지막으로, CircuitBreakerPolicy에 대한 또 다른 가능성은 Isolate(회로를 강제로 열고 열려 있는 상태로 유지) 및 Reset(회로를 다시 닫음)을 사용하는 것입니다. 이를 사용하여 정책에서 직접 분리 및 재설정을 호출하는 유틸리티 HTTP 엔드포인트를 구성할 수 있습니다. 이러한 HTTP 엔드포인트는 업그레이드 등의 상황에서 다운스트림을 임시 분리하기 위해 프로덕션에서 적절히 안전하게 사용할 수도 있습니다. 또는 오류가 있다고 의심되는 다운스트림 시스템을 보호하기 위해 회로를 수동으로 이동할 수 있습니다.
추가 리소스
.NET