연습: 매트릭스 곱
이 단계별 연습에서는 C++ AMP를 사용하여 행렬 곱셈 실행을 가속화하는 방법을 보여 줍니다. 타일링이 없는 알고리즘과 바둑판식 배열이 포함된 알고리즘 두 가지가 표시됩니다.
필수 조건
시작하기 전에:
- C++ AMP 개요를 읽습니다.
- 타일을 사용하여 읽습니다.
- Windows 7 또는 Windows Server 2008 R2 이상을 실행하고 있는지 확인합니다.
참고 항목
C++ AMP 헤더는 Visual Studio 2022 버전 17.0부터 더 이상 사용되지 않습니다.
AMP 헤더를 포함하면 빌드 오류가 생성됩니다. 경고를 무음으로 표시하기 위해 AMP 헤더를 포함하기 전에 정의 _SILENCE_AMP_DEPRECATION_WARNINGS 합니다.
프로젝트를 만들려면
새 프로젝트를 만드는 지침은 설치한 Visual Studio 버전에 따라 달라집니다. 기본 설정된 버전의 Visual Studio에 대한 설명서를 보려면 버전 선택기 컨트롤을 사용하세요. 이 페이지의 목차 맨 위에 있습니다.
Visual Studio에서 프로젝트를 만들려면
메뉴 모음에서 파일>새로 만들기>프로젝트를 선택하여 새 프로젝트 만들기 대화 상자를 엽니다.
대화 상자 맨 위에서 언어를 C++로 설정하고, 플랫폼을 Windows로 설정하고, 프로젝트 형식을 콘솔로 설정합니다.
필터링된 프로젝트 형식 목록에서 빈 프로젝트를 선택한 다음, 다음을 선택합니다. 다음 페이지에서 이름 상자에 MatrixMultiply 를 입력하여 프로젝트의 이름을 지정하고 원하는 경우 프로젝트 위치를 지정합니다.
만들기 단추를 선택하여 클라이언트 프로젝트를 만듭니다.
솔루션 탐색기 원본 파일의 바로 가기 메뉴를 열고 새 항목 추가>를 선택합니다.
새 항목 추가 대화 상자에서 C++ 파일(.cpp)을 선택하고 이름 상자에 MatrixMultiply.cpp 입력한 다음 추가 단추를 선택합니다.
Visual Studio 2017 또는 2015에서 프로젝트를 만들려면
Visual Studio의 메뉴 모음에서 파일>새로 만들기>프로젝트를 선택합니다.
템플릿 창에 설치됨 아래에서 Visual C++를 선택합니다.
빈 프로젝트를 선택하고 이름 상자에 MatrixMultiply를 입력한 다음 확인 단추를 선택합니다.
다음 단추를 선택합니다.
솔루션 탐색기 원본 파일의 바로 가기 메뉴를 열고 새 항목 추가>를 선택합니다.
새 항목 추가 대화 상자에서 C++ 파일(.cpp)을 선택하고 이름 상자에 MatrixMultiply.cpp 입력한 다음 추가 단추를 선택합니다.
바둑판식 배열 없이 곱하기
이 섹션에서는 다음과 같이 정의된 두 행렬 A와 B의 곱셈을 고려합니다.
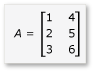

A는 3-by-2 행렬이고 B는 2-by-3 행렬입니다. A를 B로 곱하는 곱은 다음 3-by-3 행렬입니다. 제품은 A의 행과 B 요소의 열을 요소별로 곱하여 계산됩니다.

C++ AMP를 사용하지 않고 곱하려면
MatrixMultiply.cpp 열고 다음 코드를 사용하여 기존 코드를 대체합니다.
#include <iostream> void MultiplyWithOutAMP() { int aMatrix[3][2] = {{1, 4}, {2, 5}, {3, 6}}; int bMatrix[2][3] = {{7, 8, 9}, {10, 11, 12}}; int product[3][3] = {{0, 0, 0}, {0, 0, 0}, {0, 0, 0}}; for (int row = 0; row < 3; row++) { for (int col = 0; col < 3; col++) { // Multiply the row of A by the column of B to get the row, column of product. for (int inner = 0; inner < 2; inner++) { product[row][col] += aMatrix[row][inner] * bMatrix[inner][col]; } std::cout << product[row][col] << " "; } std::cout << "\n"; } } int main() { MultiplyWithOutAMP(); getchar(); }알고리즘은 행렬 곱셈 정의의 간단한 구현입니다. 계산 시간을 줄이기 위해 병렬 또는 스레드 알고리즘을 사용하지 않습니다.
메뉴 모음에서 파일>모두 저장을 차례로 선택합니다.
F5 바로 가기 키를 선택하여 디버깅을 시작하고 출력이 올바른지 확인합니다.
Enter 키를 선택하여 애플리케이션을 종료합니다.
C++ AMP를 사용하여 곱하려면
MatrixMultiply.cpp 메서드 앞에 다음 코드를 추가합니다
main.void MultiplyWithAMP() { int aMatrix[] = { 1, 4, 2, 5, 3, 6 }; int bMatrix[] = { 7, 8, 9, 10, 11, 12 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 }; array_view<int, 2> a(3, 2, aMatrix); array_view<int, 2> b(2, 3, bMatrix); array_view<int, 2> product(3, 3, productMatrix); parallel_for_each(product.extent, [=] (index<2> idx) restrict(amp) { int row = idx[0]; int col = idx[1]; for (int inner = 0; inner <2; inner++) { product[idx] += a(row, inner)* b(inner, col); } }); product.synchronize(); for (int row = 0; row <3; row++) { for (int col = 0; col <3; col++) { //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }AMP 코드는 비 AMP 코드와 유사합니다. 호출
parallel_for_each은 각 요소에product.extent대해 하나의 스레드를 시작하고 행 및 열에for대한 루프를 대체합니다. 행과 열의 셀 값은 .에서idx사용할 수 있습니다. 연산자와 인덱스 변수 또는()연산자와 행 및 열 변수를 사용하여[]개체의 요소array_view에 액세스할 수 있습니다. 이 예제에서는 두 메서드를 모두 보여 줍니다. 메서드는array_view::synchronize변수의 값을 변수에product다시 복사합니다productMatrix.MatrixMultiply.cpp 맨 위에 다음
include및using문을 추가합니다.#include <amp.h> using namespace concurrency;메서드를
main호출하도록 메서드를 수정합니다MultiplyWithAMP.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); getchar(); }Ctrl+F5 바로 가기 키를 눌러 디버깅을 시작하고 출력이 올바른지 확인합니다.
스페이스바를 눌러 애플리케이션을 종료합니다.
바둑판식 배열을 사용하여 곱하기
Tiling은 타일이라고 하는 동일한 크기의 하위 집합으로 데이터를 분할하는 기술입니다. 타일링을 사용할 때 세 가지가 변경되었습니다.
변수를 만들
tile_static수 있습니다. 공간의tile_static데이터에 대한 액세스는 전역 공간의 데이터에 액세스하는 것보다 여러 배 더 빠를 수 있습니다. 변수의tile_static인스턴스는 각 타일에 대해 만들어지고 타일의 모든 스레드는 변수에 액세스할 수 있습니다. 타일링의 주요 이점은 액세스로tile_static인한 성능 향상입니다.tile_barrier::wait 메서드를 호출하여 지정된 코드 줄에서 한 타일의 모든 스레드를 중지할 수 있습니다. 스레드가 실행되는 순서는 보장할 수 없으며, 한 타일의 모든 스레드가 실행을 계속하기 전에 호출
tile_barrier::wait시 중지됩니다.전체
array_view개체를 기준으로 하는 스레드의 인덱스와 타일을 기준으로 하는 인덱스로 액세스할 수 있습니다. 로컬 인덱스로 코드를 더 쉽게 읽고 디버그할 수 있습니다.
행렬 곱셈에서 타일링을 활용하려면 알고리즘이 행렬을 타일로 분할한 다음, 더 빠른 액세스를 위해 타일 데이터를 변수에 tile_static 복사해야 합니다. 이 예제에서 행렬은 같은 크기의 하위 매트릭스로 분할됩니다. 제품은 하위 매트릭스를 곱하여 찾을 수 있습니다. 이 예제의 두 행렬과 해당 제품은 다음과 같습니다.
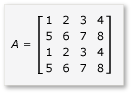
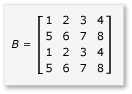
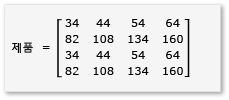
행렬은 다음과 같이 정의된 4개의 2x2 행렬로 분할됩니다.


이제 A와 B의 곱을 다음과 같이 작성하고 계산할 수 있습니다.
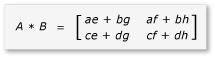
행렬은 a h 2x2 행렬이므로 모든 제품과 합계도 2x2 행렬입니다. 또한 A와 B의 제품이 예상대로 4x4 행렬임을 따릅니다. 알고리즘을 빠르게 확인하려면 제품의 첫 번째 행, 첫 번째 열에 있는 요소의 값을 계산합니다. 이 예제에서는 첫 번째 행과 첫 번째 열에 있는 요소의 ae + bg값입니다. 첫 번째 열, 첫 번째 행 및 bg 각 용어에 ae 대해서만 계산해야 합니다. 해당 값은 ae .입니다 (1 * 1) + (2 * 5) = 11. 값 bg 은 .입니다 (3 * 1) + (4 * 5) = 23. 최종 값은 11 + 23 = 34올바른 값입니다.
이 알고리즘을 구현하기 위해 코드는 다음과 같습니다.
호출에서
tiled_extent개체 대신extent개체를parallel_for_each사용합니다.호출에서
tiled_index개체 대신index개체를parallel_for_each사용합니다.하위 매트릭스를 저장할 변수를 만듭니다
tile_static.메서드를
tile_barrier::wait사용하여 하위 매트릭스의 곱 계산에 대한 스레드를 중지합니다.
AMP 및 바둑판식 배열을 사용하여 곱하려면
MatrixMultiply.cpp 메서드 앞에 다음 코드를 추가합니다
main.void MultiplyWithTiling() { // The tile size is 2. static const int TS = 2; // The raw data. int aMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int bMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 }; // Create the array_view objects. array_view<int, 2> a(4, 4, aMatrix); array_view<int, 2> b(4, 4, bMatrix); array_view<int, 2> product(4, 4, productMatrix); // Call parallel_for_each by using 2x2 tiles. parallel_for_each(product.extent.tile<TS, TS>(), [=] (tiled_index<TS, TS> t_idx) restrict(amp) { // Get the location of the thread relative to the tile (row, col) // and the entire array_view (rowGlobal, colGlobal). int row = t_idx.local[0]; int col = t_idx.local[1]; int rowGlobal = t_idx.global[0]; int colGlobal = t_idx.global[1]; int sum = 0; // Given a 4x4 matrix and a 2x2 tile size, this loop executes twice for each thread. // For the first tile and the first loop, it copies a into locA and e into locB. // For the first tile and the second loop, it copies b into locA and g into locB. for (int i = 0; i < 4; i += TS) { tile_static int locA[TS][TS]; tile_static int locB[TS][TS]; locA[row][col] = a(rowGlobal, col + i); locB[row][col] = b(row + i, colGlobal); // The threads in the tile all wait here until locA and locB are filled. t_idx.barrier.wait(); // Return the product for the thread. The sum is retained across // both iterations of the loop, in effect adding the two products // together, for example, a*e. for (int k = 0; k < TS; k++) { sum += locA[row][k] * locB[k][col]; } // All threads must wait until the sums are calculated. If any threads // moved ahead, the values in locA and locB would change. t_idx.barrier.wait(); // Now go on to the next iteration of the loop. } // After both iterations of the loop, copy the sum to the product variable by using the global location. product[t_idx.global] = sum; }); // Copy the contents of product back to the productMatrix variable. product.synchronize(); for (int row = 0; row <4; row++) { for (int col = 0; col <4; col++) { // The results are available from both the product and productMatrix variables. //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }이 예제는 바둑판식 배열 없이 예제와 크게 다릅니다. 이 코드는 다음과 같은 개념적 단계를 사용합니다.
타일[0,0]의
a요소를 .에locA복사합니다. 타일[0,0]의b요소를 .에locB복사합니다. 타일이 아니라a타일로 된 것을product확인합니다b. 따라서 전역 인덱스를 사용하여 액세스a, b하고product. 호출tile_barrier::wait은 필수적입니다. 둘 다locAlocB채워지게 될 때까지 타일의 모든 스레드를 중지합니다.결과를 곱
locA하고locB에 넣습니다product.타일[0,1]의 요소를 .에
alocA복사합니다. 타일 [1,0]의 요소를 .에blocB복사합니다.이미
product있는 결과에 곱locBlocA하고 추가합니다.타일[0,0]의 곱하기가 완료되었습니다.
나머지 4개의 타일에 대해 반복합니다. 타일에 대해 특별히 인덱싱이 없으며 스레드는 임의의 순서로 실행할 수 있습니다. 각 스레드가
tile_static실행되면 각 타일에 대해 변수가 적절하게 만들어지고 프로그램 흐름을 제어하는tile_barrier::wait호출이 생성됩니다.알고리즘을 자세히 살펴보면 각 하위 매크로가 메모리에
tile_static두 번 로드됩니다. 해당 데이터 전송에는 시간이 소요되었습니다. 그러나 데이터가 메모리에tile_static있으면 데이터에 대한 액세스 속도가 훨씬 빠릅니다. 제품을 계산하려면 하위 매트릭스의 값에 반복적으로 액세스해야 하므로 전반적인 성능이 향상됩니다. 각 알고리즘에 대해 최적의 알고리즘과 타일 크기를 찾으려면 실험이 필요합니다.
비 AMP 및 비 타일 예제에서 A와 B의 각 요소는 전역 메모리에서 4번 액세스하여 제품을 계산합니다. 타일 예제에서 각 요소는 전역 메모리에서 두 번, 메모리에서
tile_static4번 액세스됩니다. 이는 중요한 성능 향상이 아닙니다. 그러나 A와 B가 1024x1024 매트릭스이고 타일 크기가 16인 경우 상당한 성능 향상이 있을 것입니다. 이 경우 각 요소는 메모리에tile_static16번만 복사되고 메모리에서tile_static1024번 액세스됩니다.표시된 것처럼 메서드를 호출하도록 main 메서드를
MultiplyWithTiling수정합니다.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); MultiplyWithTiling(); getchar(); }Ctrl+F5 바로 가기 키를 눌러 디버깅을 시작하고 출력이 올바른지 확인합니다.
스페이스바를 눌러 애플리케이션을 종료합니다.
참고 항목
C++ AMP(C++ Accelerated Massive Parallelism)
연습: C++ AMP 애플리케이션 디버깅