자습서: 서버리스 SQL 풀로 데이터 레이크 탐색 및 분석
이 자습서에서는 스토리지 설정 없이 기존 열린 데이터 세트를 사용하여 예비 데이터 분석을 수행하는 방법을 알아봅니다. 서버리스 SQL 풀을 사용하여 여러 Azure Open Datasets를 결합합니다. 그런 다음, Azure Synapse Analytics용 Synapse Studio에서 결과를 시각화합니다.
이 자습서에서는 다음을 수행합니다.
- 기본 제공 서버리스 SQL 풀에 액세스
- Azure Open Datasets에 액세스하여 자습서 데이터 사용
- SQL을 사용하여 기본 데이터 분석 수행
서버리스 SQL 풀 액세스
모든 작업 영역에는 기본 제공이라는 것을 사용할 수 있도록 미리 구성된 서버리스 SQL 풀이 함께 제공됩니다. 액세스하려면 다음을 수행합니다.
- 작업 영역을 열고 개발 허브를 선택합니다.
- + 새 리소스 추가 단추를 선택합니다.'
- SQL 스크립트를 선택합니다.
이 스크립트를 사용하여 SQL 용량을 예약하지 않고도 데이터를 탐색할 수 있습니다.
Azure 구독이 없는 경우 시작하기 전에 체험 계정을 만듭니다.
자습서 데이터 액세스
이 자습서에서 사용하는 모든 데이터는 스토리지 계정 azureopendatastorage에 저장되며, Azure Open Datasets는 이와 같은 자습서에서 공개적으로 사용할 수 있습니다. 작업 영역이 공용 네트워크에 액세스할 수 있는 한 작업 영역에서 모든 스크립트를 있는 그대로 직접 실행할 수 있습니다.
이 자습서에서는 NYC(뉴욕시) Taxi에 대한 데이터 세트를 사용합니다.
- 승하차 날짜와 시간
- 승하차 위치
- 이동 거리
- 항목별 요금
- 요율 유형
- 결제 유형
- 운전사가 보고한 승객 수
OPENROWSET(BULK...) 함수를 사용하여 Azure Storage의 파일에 액세스할 수 있습니다. [OPENROWSET](develop-openrowset.md)는 파일과 같은 원격 데이터 원본의 콘텐츠를 읽고 콘텐츠를 행 집합으로 반환합니다.
NYC Taxi 데이터에 익숙해지려면 다음 쿼리를 실행합니다.
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
기타 액세스 가능한 데이터 세트
마찬가지로, 다음 쿼리를 사용하여 공휴일 데이터 세트를 쿼리할 수 있습니다.
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
다음 쿼리를 사용하여 날씨 데이터 세트를 쿼리할 수도 있습니다.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
데이터 세트에 대한 설명에서 개별 열의 의미에 대해 자세히 알아볼 수 있습니다.
자동 스키마 유추
데이터가 Parquet 파일 형식으로 저장되므로 자동 스키마 유추를 사용할 수 있습니다. 파일에 있는 모든 열의 데이터 형식을 나열하지 않고 데이터를 쿼리할 수 있습니다. 가상 열 메커니즘과 filepath 함수를 사용하여 파일의 특정 하위 집합을 필터링할 수도 있습니다.
참고 항목
기본 데이터 정렬은 SQL_Latin1_General_CP1_CI_ASIf입니다. 기본 데이터 정렬이 아닌 경우 대/소문자 구분을 고려합니다.
대/소문자를 구분하는 데이터 정렬을 사용하여 데이터베이스를 만든 경우 열을 지정할 때 올바른 열 이름을 사용해야 합니다.
열 이름 tpepPickupDateTime은 정확하지만 tpeppickupdatetime은 기본 데이터 정렬에 있지 않은 경우에는 작동하지 않습니다.
시계열, 계절성 및 이상값 분석
다음 쿼리를 사용하여 연간 택시 이용 횟수를 요약할 수 있습니다.
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
다음은 연간 택시 승차 횟수에 대한 결과 조각을 보여 줍니다.
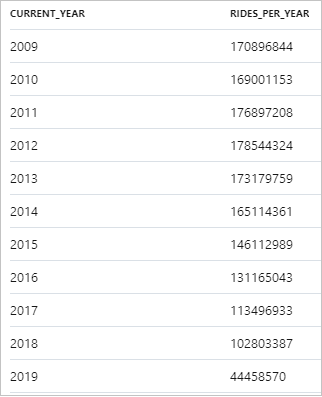
Synapse Studio에서 테이블 보기를 차트 보기로 전환하면 데이터를 시각화할 수 있습니다. 여러 차트 유형(예: 영역, 막대형, 세로 막대형, 꺾은선형, 원형 및 분산형) 중에 선택할 수 있습니다. 이 경우 Category 열을 current_year로 설정하여 세로 막대형 차트를 그리겠습니다.
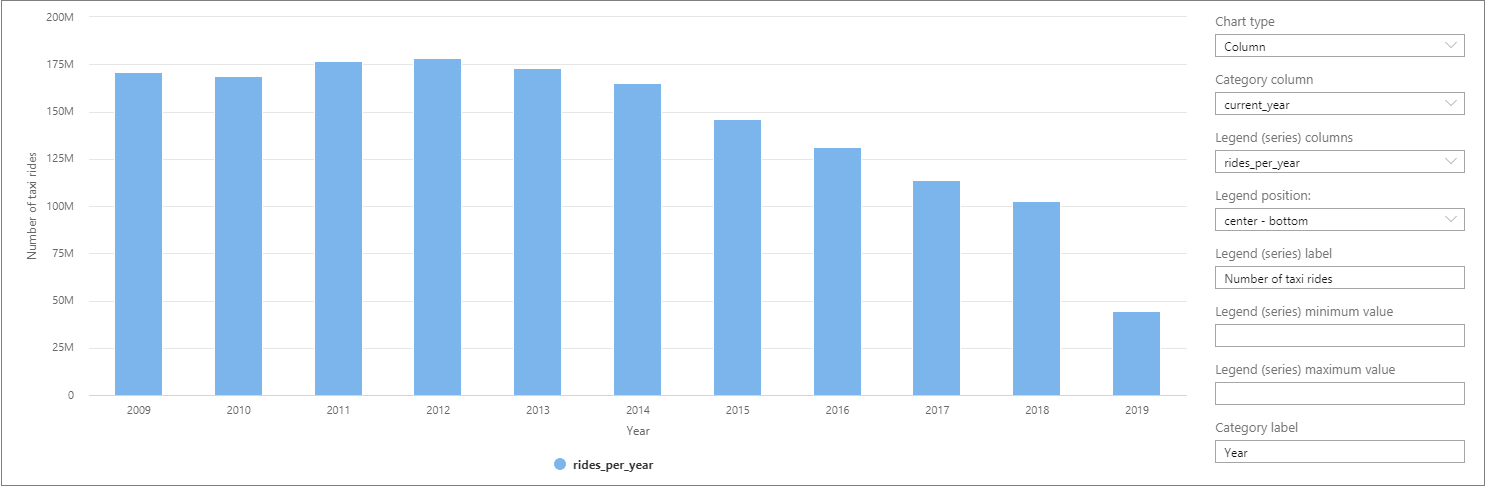
이 시각화를 통해 수년 동안 승차 횟수가 감소하는 추세를 확인할 수 있습니다. 아마도 최근 승차 공유 회사의 인기가 상승하면서 승차 인원이 감소했기 때문일 수 있습니다.
참고 항목
이 자습서를 작성할 당시에는 2019년도 데이터가 완전하지 않습니다. 따라서 해당 연도의 탑승 횟수는 크게 감소한 것처럼 보입니다.
한 해(예: 2016)에 대한 분석에 집중할 수 있습니다. 다음 쿼리는 해당 연도 중 일일 승차 횟수를 반환합니다.
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
다음은 이 쿼리에 대한 결과 조각을 보여줍니다.
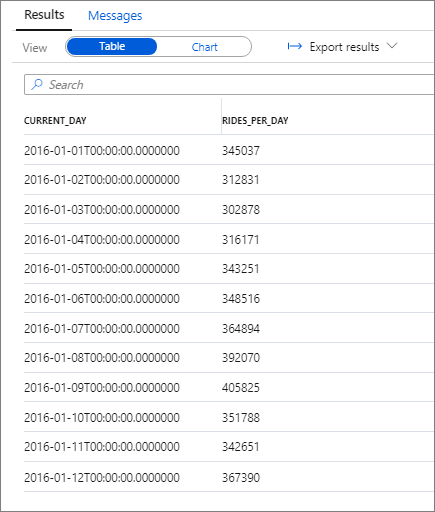
다시, Category 열을 current_day로 설정하고 Legend(series) 열을 rides_per_day로 설정하여 세로 막대형 차트를 그려서 데이터를 시각화할 수 있습니다.
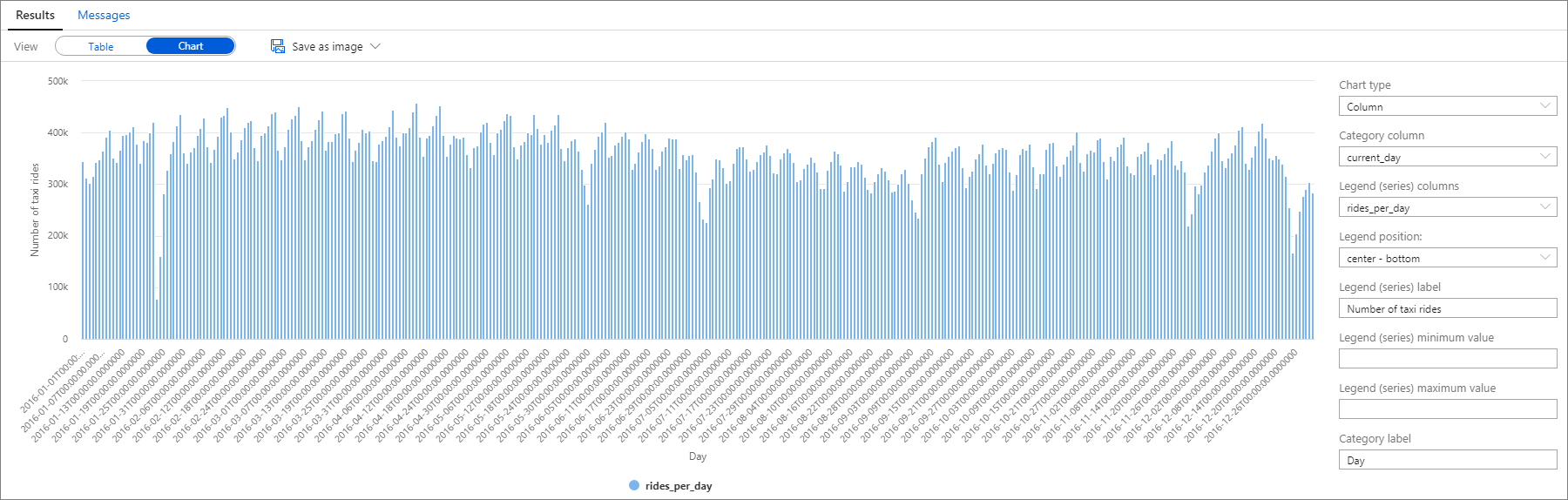
이 플롯 차트에서 주 단위 패턴을 볼 수 있으며, 토요일이 가장 탑승 횟수가 많은 요일임을 알 수 있습니다. 여름 몇 개월 동안은 휴가로 인해 택시 승차 인원이 줄어듭니다. 또한 택시 승차 횟수가 언제 그리고 왜 발생하는지에 대한 명확한 패턴이 없이 크게 감소한 경우도 있습니다.
다음으로, 승차 감소가 공휴일과 관련이 있는지 확인합니다. NYC Taxi 탑승 데이터 세트를 공휴일 데이터 세트와 결합하여 상관관계가 있는지 확인합니다.
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC
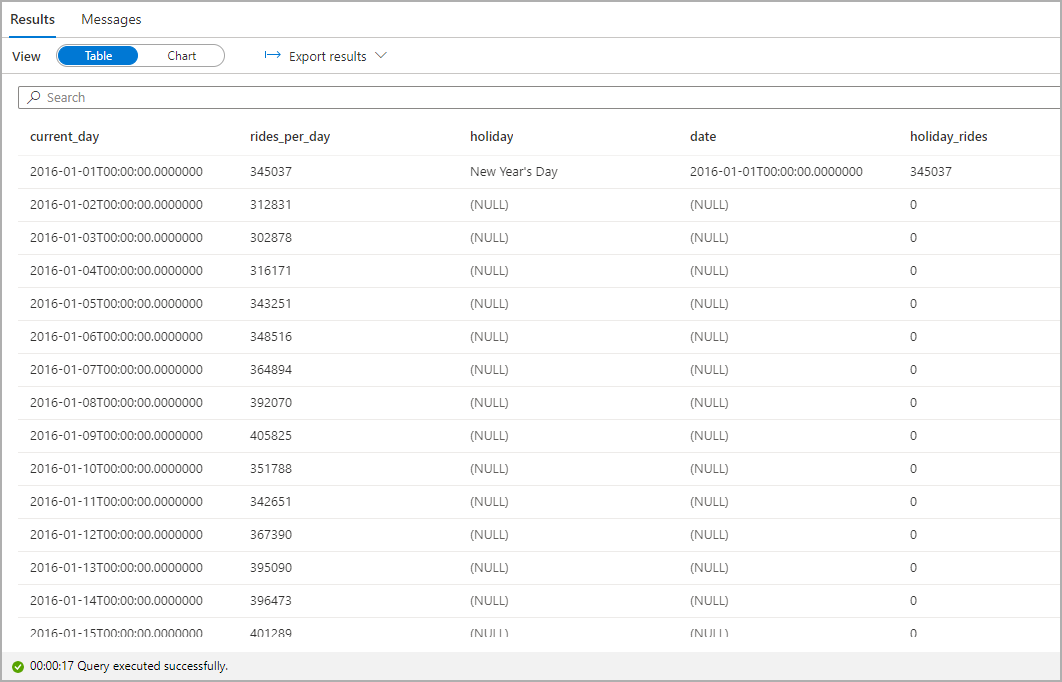
공휴일에 택시를 탑승한 횟수를 강조 표시합니다. 이를 위해 Category 열에는 current_day를 선택하고 Legend(series) 열에는 rides_per_day와 holiday_rides를 선택합니다.
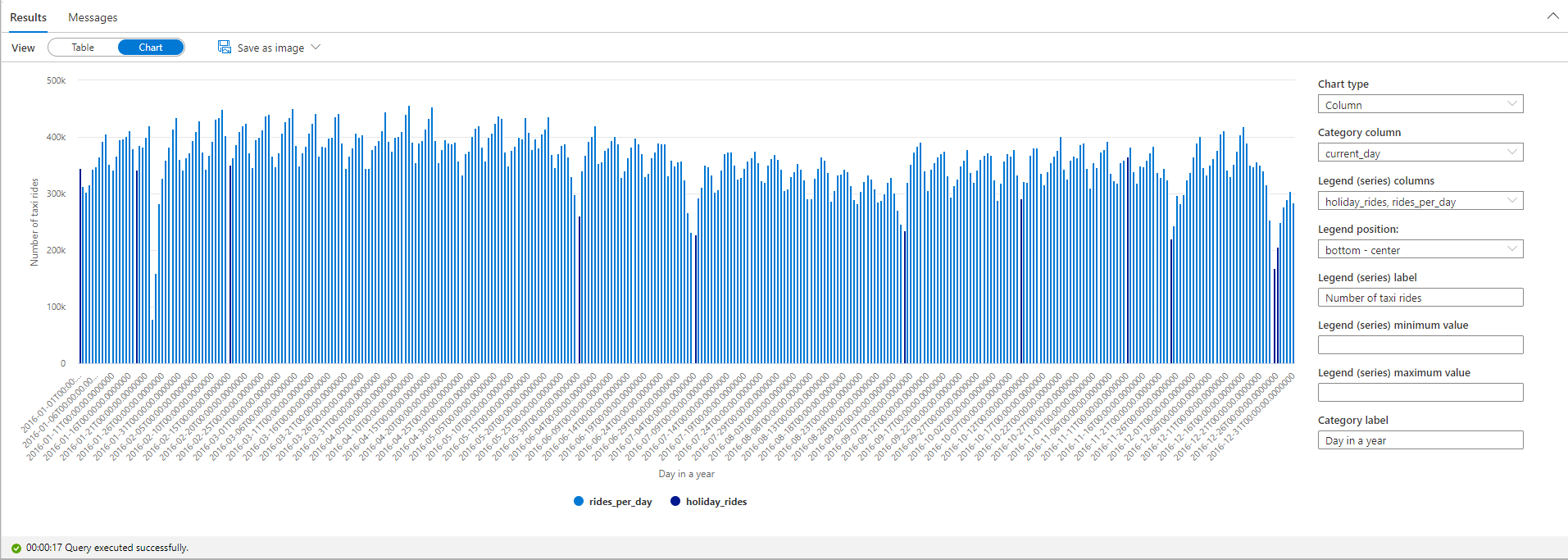
그림 차트를 보면 공휴일 중 택시 승차 횟수가 적은 것을 알 수 있습니다. 1월 23일의 큰 하락은 여전히 설명할 수 없습니다. 날씨 데이터 세트를 쿼리하여 해당일의 NYC 날씨를 확인해보겠습니다.
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

쿼리 결과에 따르면 택시 승차 횟수 하락의 원인은 다음과 같습니다.
- 그날 NYC에 폭설(~30cm)로 인한 눈보라가 있었습니다.
- 추웠습니다(섭씨 영하의 온도).
- 바람이 불었습니다(초속 10m 이하).
이 자습서에서는 데이터 분석가가 탐색적 데이터 분석을 신속하게 수행하는 방법을 보여 주었습니다. 서버리스 SQL 풀을 사용하여 다른 데이터 세트를 결합하고 Azure Synapse Studio를 사용하여 결과를 시각화할 수 있습니다.
관련 콘텐츠
서버리스 SQL 풀을 Power BI Desktop에 연결하고 보고서를 만드는 방법을 알아보려면 서버리스 SQL 풀을 Power BI Desktop에 연결하고 보고서 만들기를 참조하세요.
서버리스 SQL 풀에서 외부 테이블을 사용하는 방법을 알아보려면 Synapse SQL에서 외부 테이블 사용을 참조하세요.