Azure Synapse Analytics에서 전용 SQL 풀을 사용하여 분산 테이블을 디자인하기 위한 지침
이 문서에는 전용 SQL 풀의 해시 분산 및 라운드 로빈 분산 테이블 디자인에 대한 권장 사항이 포함됩니다.
이 문서에서는 사용자가 전용 SQL 풀의 데이터 배포 및 데이터 이동 개념에 익숙하다고 가정합니다. 자세한 내용은 Azure Synapse Analytics 아키텍처를 참조하세요.
분산 테이블이란?
분산 테이블은 단일 테이블로 나타나지만 실제로는 행이 60개의 배포에 저장됩니다. 행은 해시 또는 라운드 로빈 알고리즘으로 분산됩니다.
이 문서에서는 대규모 팩트 테이블의 쿼리 성능을 향상시키는 해시 분산에 중점을 둡니다. 라운드 로빈 분산은 로드 속도를 향상시키는 데 유용합니다. 이러한 디자인 선택은 쿼리 및 로딩 성능을 개선하는 데 중요한 영향을 미칩니다.
또 다른 Table Storage 옵션은 모든 컴퓨팅 노드에서 작은 테이블을 복제하는 것입니다. 자세한 내용은 복제된 테이블에 대한 디자인 지침을 참조하세요. 세 가지 옵션 중 빨리 선택하려면 테이블 개요의 분산 테이블을 참조하세요.
테이블 디자인의 일환으로 데이터 및 데이터가 쿼리되는 방식에 대해 최대한 많이 이해하는 것이 좋습니다. 예를 들어 다음 질문을 고려합니다.
- 테이블이 얼마나 큰가요?
- 테이블을 얼마나 자주 새로 고치나요?
- 전용 SQL 풀에 팩트 및 차원 테이블이 있나요?
해시 분산
해시 분산 테이블은 결정적 해시 함수를 사용하여 하나의 배포에 각 행을 할당하도록 컴퓨팅 노드에서 테이블 행을 분산합니다.
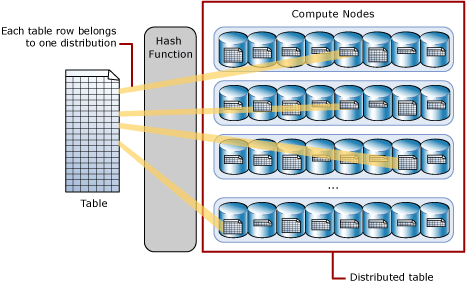
동일한 값은 항상 동일한 배포를 해시하므로 SQL Analytics는 행 위치에 대한 기본 제공 정보를 제공 합니다. 전용 SQL 풀에서 이 정보는 쿼리 중 데이터 이동을 최소화하여 쿼리 성능을 향상시키는 데 사용됩니다.
해시 분산 테이블은 별모양 스키마의 큰 팩트 테이블에 적합합니다. 행 수가 매우 많은 경우에도 여전히 높은 성능을 유지할 수 있습니다. 분산 시스템이 제공하도록 디자인된 성능을 얻는 데 도움이 되는 디자인 고려 사항이 있습니다. 적합한 배포 열을 선택하는 것은 이 문서에서 설명하는 고려 사항 중 하나입니다.
다음 경우 해시 분산 테이블을 사용하는 것이 좋습니다.
- 디스크의 테이블 크기가 2GB보다 큽니다.
- 테이블에 삽입, 업데이트 및 삭제 작업이 빈번합니다.
라운드 로빈 분산
라운드 로빈 분산 테이블은 모든 배포에 테이블 행을 균일하게 배포합니다. 행은 배포에 무작위로 할당됩니다. 해시 분산 테이블과 달리 값이 동일한 행은 동일한 배포에 할당된다는 보장은 없습니다.
결과적으로 경우에 따라 시스템은 쿼리를 해결하기 위해 먼저 데이터 이동 작업을 호출하여 데이터를 좀 더 나은 방식으로 구성해야 합니다. 이 추가 단계로 인해 쿼리 속도가 느려질 수 있습니다. 예를 들어 일반적으로 라운드 로빈 테이블을 조인하려면 행을 다시 섞어야 하므로 성능이 저하됩니다.
다음 시나리오에서는 테이블에 대해 라운드 로빈 배포를 사용하는 것이 좋습니다.
- 기본값이기 때문에 간단한 시작점으로 시작하는 경우
- 명백한 조인 키가 없는 경우
- 테이블의 해시 분산에 적합한 후보 열이 없는 경우
- 테이블이 다른 테이블과 공통 조인 키를 공유하지 않는 경우
- 조인이 쿼리의 다른 조인보다 덜 중요한 경우
- 테이블이 임시 준비 테이블인 경우
뉴욕 택시 데이터 로드 자습서에 라운드 로빈 준비 테이블로 데이터를 로드하는 예제가 제공됩니다.
배포 열 선택
해시 분산 테이블에는 해시 키인 배포 열 또는 열 집합이 있습니다. 예를 들어 다음 코드에서는 ProductKey를 배포 열로 사용하여 해시 분산 테이블을 만듭니다.
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
기본 테이블의 더 균등한 분포를 위해 해시 분포를 여러 열에 적용할 수 있습니다. 다중 열 배포를 사용하면 배포할 열을 최대 8개까지 선택할 수 있습니다. 이렇게 하면 시간이 지남에 따라 데이터 기울이기가 감소할 뿐만 아니라 쿼리 성능도 향상됩니다. 예시:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
참고 항목
이 명령으로 데이터베이스의 호환성 수준을 50으로 변경하여 Azure Synapse Analytics의 다중 열 배포를 사용하도록 설정할 수 있습니다.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; 데이터베이스 호환성 수준을 설정하는 방법에 대한 자세한 내용은 ALTER DATABASE SCOPED CONFIGURATION을 참조하세요. 다중 열 배포에 대한 자세한 내용은 CREATE MATERIALIZED VIEW, CREATE TABLE 또는 CREATE TABLE AS SELECT를 참조하세요.
배포 열에 저장된 데이터를 업데이트할 수 있습니다. 배포 열의 데이터를 업데이트하면 데이터 순서 섞기 작업이 발생할 수 있습니다.
해시 열의 값에 따라 행이 배포되는 방법이 결정되므로 배포 열을 선택하는 것은 중요한 디자인 결정입니다. 최상의 선택은 여러 가지 요인에 따라 달라지며 일반적으로 장단점이 있습니다. 배포 열 또는 열 집합을 선택한 후에는 변경할 수 없습니다. 처음에 가장 적합한 열을 선택하지 않은 경우 CREATE TABLE AS SELECT(CTAS)를 사용하여 원하는 배포 해시 키가 있는 테이블을 다시 만들 수 있습니다.
균일하게 분산되는 데이터가 포함된 배포 열 선택
최상의 성능을 위해서는 모든 배포의 행 수가 거의 같아야 합니다. 하나 이상의 배포에서 행 수의 균형이 맞지 않는 경우 일부 배포의 병렬 쿼리 부분이 다른 배포보다 먼저 완료됩니다. 쿼리는 모든 배포에서 처리가 끝날 때까지 완료할 수 없으므로 각 쿼리는 가장 느린 배포의 속도로 처리됩니다.
- 데이터 기울이기는 배포에서 데이터가 균등하게 분산되지 않았음을 의미합니다.
- 처리 기울이기는 병렬 쿼리 실행 시 일부 배포가 다른 배포보다 시간이 오래 걸리는 것을 의미합니다. 이는 데이터가 기울어진 경우에 발생할 수 있습니다.
병렬 처리의 균형을 맞추려면 다음과 같은 배포 열 또는 열 집합을 선택합니다.
- 고유 값이 많음. 하나 이상의 배포 열에 중복된 값이 있을 수 있습니다. 값이 동일한 모든 행은 동일한 배포에 할당됩니다. 60개 배포가 있기 때문에 일부 배포에는 고유한 값이 1개를 초과(> 1)할 수 있지만 다른 배포는 0값으로 끝날 수 있습니다.
- NULL이 없거나 소수의 NULL만 있음. 극단적인 예로, 배포 열의 모든 값이 NULL이면 모든 행이 동일한 배포에 할당됩니다. 결과적으로 쿼리 처리가 하나의 배포에 기울어져 병렬 처리의 이점이 없습니다.
- 날짜 열이 아님. 동일한 날짜의 모든 데이터가 동일한 배포에 있거나 날짜별로 레코드를 클러스터링합니다. 여러 사용자가 모두 같은 날짜(예: 오늘 날짜)로 필터링하는 경우 60개 배포 중 하나만 모든 처리 작업을 수행합니다.
데이터 이동을 최소화하는 배포 열 선택
올바른 쿼리 결과를 얻기 위해 쿼리에서 데이터를 하나의 컴퓨팅 노드에서 다른 컴퓨팅 노드로 이동할 수 있습니다. 일반적으로 데이터 이동은 분산 테이블에서 쿼리 조인 및 집계 시에 발생합니다. 데이터 이동을 최소화하는 데 도움이 되는 배포 열 또는 열 집합을 선택하는 것은 전용 SQL 풀의 성능을 최적화하기 위한 가장 중요한 전략 중 하나입니다.
데이터 이동을 최소화하려면 다음과 같은 배포 열 또는 열 집합을 선택합니다.
JOIN,GROUP BY,DISTINCT,OVER및HAVING절에 사용됨. 두 개의 큰 팩트 테이블에서 조인이 잦은 경우 조인 열 중 하나에 두 테이블을 분산하면 쿼리 성능이 향상됩니다. 테이블이 조인에 사용되지 않는 경우 테이블을GROUP BY절에 자주 사용되는 열 또는 열 집합에 배포하는 것이 좋습니다.WHERE절에 사용되지 않음. 쿼리의WHERE절과 테이블의 배포 열이 동일한 열에 있는 경우 쿼리에서 높은 데이터 기울이기가 발생하여 일부 배포에서만 처리 부하가 떨어질 수 있습니다. 이는 쿼리 성능에 영향을 미치며 이상적으로는 많은 배포가 처리 부하를 공유합니다.- 날짜 열이 아님.
WHERE절은 날짜별로 필터링하는 경우가 많습니다. 이 경우 쿼리 성능에 영향을 미치는 일부 배포에서만 모든 처리가 실행될 수 있습니다. 이상적으로는 많은 배포판이 처리 부하를 공유합니다.
해시 분산 테이블을 디자인한 후 다음 단계는 데이터를 테이블로 로드하는 것입니다. 로드 지침은 로드 개요를 참조하세요.
배포가 적합한 선택인지 확인하는 방법
해시 분산 테이블에 데이터를 로드한 다음 60개의 배포에 균등하게 행이 배포되었는지 확인합니다. 배포당 행 수는 성능에 별다른 영향을 주지 않으면서 최대 10%까지 다를 수 있습니다.
배포 열을 평가하려면 다음 방법을 고려합니다.
테이블에 데이터 기울이기가 있는지 확인
데이터 기울이기를 확인하는 빠른 방법은 DBCC PDW_SHOWSPACEUSED를 사용하는 것입니다. 다음 SQL 코드는 60개의 각 배포에 저장된 테이블 행의 수를 반환합니다. 균형 잡힌 성능을 위해서는 분산 테이블의 행을 모든 배포에 균등하게 배포되어야 합니다.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
데이터 기울이기가 10%가 넘는 테이블을 식별하려면:
- 테이블 개요 문서에 나온
dbo.vTableSizes뷰를 만듭니다. - 다음 쿼리를 실행합니다.
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
데이터 이동에 대한 쿼리 계획 확인
적합한 배포 열을 사용하면 조인 및 집계에서 데이터 이동을 최소화할 수 있습니다. 이는 조인을 작성하는 방법에 영향을 줍니다. 두 개의 해시 분산 테이블 조인에서 데이터 이동을 최소화하려면 조인 열 중 하나가 배포 열에 있어야 합니다. 두 해시 분산 테이블이 동일한 데이터 형식의 배포 열에 조인되는 경우 조인에 데이터 이동이 필요하지 않습니다. 조인은 데이터 이동 없이 추가 열을 사용할 수 있습니다.
조인하는 동안 데이터 이동을 방지하려면:
- 조인에 관련된 테이블은 조인에 포함되는 열 중 하나 에서 해시 분산해야 합니다.
- 조인 열의 데이터 형식은 두 테이블 간에 일치해야 합니다.
- 같음 연산자로 열을 조인해야 합니다.
- 조인 형식은
CROSS JOIN일 수 없습니다.
쿼리 시 데이터 이동이 발생하는지 확인하기 위해 쿼리 계획을 살펴볼 수 있습니다.
배포 열 문제 해결
모든 경우의 데이터 기울이기를 해결할 필요는 없습니다. 데이터 분산은 데이터 기울이기 최소화와 데이터 이동 최소화 간의 적절한 균형을 찾는 문제입니다. 데이터 기울이기 및 데이터 이동 둘 다를 항상 최소화할 수 있는 것은 아닙니다. 데이터 이동을 최소화할 경우의 이점이 데이터 기울이기의 영향을 능가하는 경우도 있습니다.
테이블의 데이터 오차를 해결해야 하는지 결정하려면 워크로드의 데이터 볼륨 및 쿼리를 최대한 이해해야 합니다. 쿼리 모니터링 문서의 단계를 사용하여 쿼리 성능에 대한 기울이기 영향을 모니터링할 수 있습니다. 특히 개별 배포에서 큰 쿼리가 완료되는 데 소요되는 시간을 확인합니다.
기존 테이블에서 배포 열을 변경할 수 없으므로 데이터 기울이기를 해결하는 일반적인 방법은 다른 배포 열로 테이블을 다시 만드는 것입니다.
새 배포 열 집합이 있는 테이블 다시 만들기
이 예제에서는 CREATE TABLE AS SELECT를 사용하여 다른 해시 배포 열로 테이블을 다시 만듭니다.
먼저 새 키가 있는 새 CREATE TABLE AS SELECT(CTAS) 테이블을 사용합니다. 그런 다음, 통계를 다시 만들고, 마지막으로 이름을 바꿔 테이블을 바꿉니다.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
관련 콘텐츠
분산 테이블을 만들려면 다음 문 중 하나를 사용합니다.