Azure Machine Learning을 사용하여 데이터 분석
이 자습서는 Azure Machine Learning 디자이너를 사용하여 예측 기계 학습 모델을 구축합니다. 이 모델은 Azure Synapse에 저장된 데이터를 기반으로 합니다. 이 자습서의 시나리오는 고객이 자전거를 구매할 가능성이 있는지 여부를 예측하여 자전거 매장 Adventure Works에서 타겟팅된 마케팅 캠페인을 계획할 수 있도록 하기 위한 것입니다.
필수 조건
이 자습서를 단계별로 실행하려면 다음이 필요합니다.
- AdventureWorksDW 샘플 데이터로 미리 로드된 SQL 풀. SQL 풀을 프로비저닝하려면 SQL 풀 만들기를 참조하고 샘플 데이터 로드를 선택합니다. 데이터 웨어하우스는 있지만 샘플 데이터가 없는 경우 샘플 데이터를 수동으로 로드할 수 있습니다.
- Azure Machine Learning 작업 영역. 이 자습서의 안내에 따라 새로운 작업 영역을 만듭니다.
데이터 가져오기
사용되는 데이터는 AdventureWorksDW의 dbo.vTargetMail 보기에 있습니다. Azure Synapse에서 현재 데이터 세트를 지원하지 않으므로, 이 자습서에서 데이터 저장소를 사용하려면 데이터를 먼저 Azure Data Lake Storage 계정으로 내보냅니다. Azure Data Factory는 복사 작업을 사용하여 데이터 웨어하우스에서 Azure Data Lake Storage로 데이터를 내보내는 데 사용할 수 있습니다. 다음 쿼리를 사용하여 데이터를 가져옵니다.
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Azure Data Lake Storage에서 데이터를 사용할 수 있게 되면 Azure Machine Learning의 데이터 저장소를 사용하여 Azure 스토리지 서비스에 연결합니다. 다음 단계를 수행하여 데이터 저장소 및 해당 데이터 세트를 만듭니다.
Azure Portal에서 또는 Azure Machine Learning 스튜디오에서 로그인하여 Azure Machine Learning 스튜디오를 시작합니다.
관리 섹션의 왼쪽 창에서 데이터 저장소를 클릭한 다음, 새 데이터 저장소를 클릭합니다.
데이터 저장소의 이름을 입력하고 형식을 ‘Azure Blob Storage’로 선택한 다음, 위치와 자격 증명을 입력합니다. 그런 다음 만들기를 클릭합니다.
그런 다음, 자산 섹션의 왼쪽 창에서 데이터 세트를 클릭합니다. 데이터 저장소에서 옵션을 사용하여 데이터 세트 만들기를 선택합니다.
데이터 세트의 이름을 지정하고 형식에 테이블 형식을 선택합니다. 그러고 나서 다음을 클릭하여 다음 단계로 이동합니다.
데이터 저장소 선택 또는 만들기 섹션에서 이전에 만든 데이터 저장소 옵션을 선택합니다. 이전에 만든 데이터 저장소를 선택합니다. 다음을 클릭하고 경로 및 파일 설정을 지정합니다. 파일에 열 헤더가 포함된 경우 열 헤더를 지정해야 합니다.
마지막으로 만들기를 클릭하여 데이터 세트를 만듭니다.
디자이너 실험 구성
다음으로 디자이너 구성에 대해 아래 단계를 수행합니다.
작성자 섹션의 왼쪽 창에서 디자이너 탭을 클릭합니다.
사용하기 쉬운 사전 제작 구성 요소를 선택하여 새 파이프라인을 구축합니다.
오른쪽의 설정 창에서 파이프라인의 이름을 지정합니다.
또한 이전에 프로비저닝된 클러스터에 대한 설정 단추에서 전체 실험에 대한 대상 컴퓨팅 클러스터를 선택합니다. 설정 창을 닫습니다.
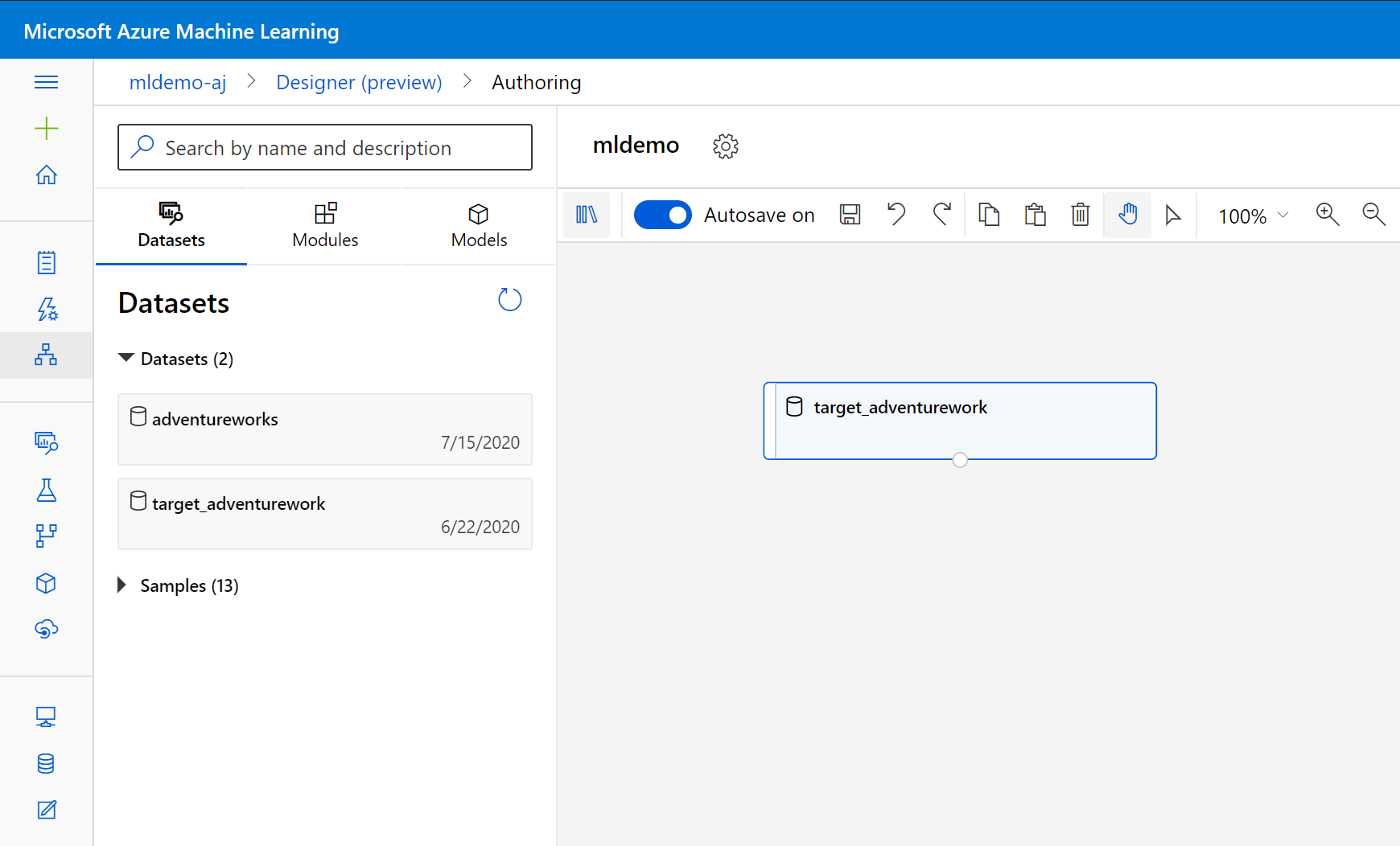
데이터 가져오기
검색 상자 아래의 왼쪽 창에서 데이터 세트 하위 탭을 선택합니다.
이전에 만든 데이터 세트를 캔버스로 끌어다 놓습니다.
데이터 정리
데이터를 정리하려면 모델에 관련되지 않은 열을 삭제합니다. 다음 단계를 수행합니다.
왼쪽 창에서 구성 요소 하위 탭을 선택합니다.
데이터 변환 < 조작 아래의 데이터 세트의 열 선택 구성 요소를 캔버스로 드래그합니다. 이 구성 요소를 데이터 세트 구성 요소에 연결합니다.
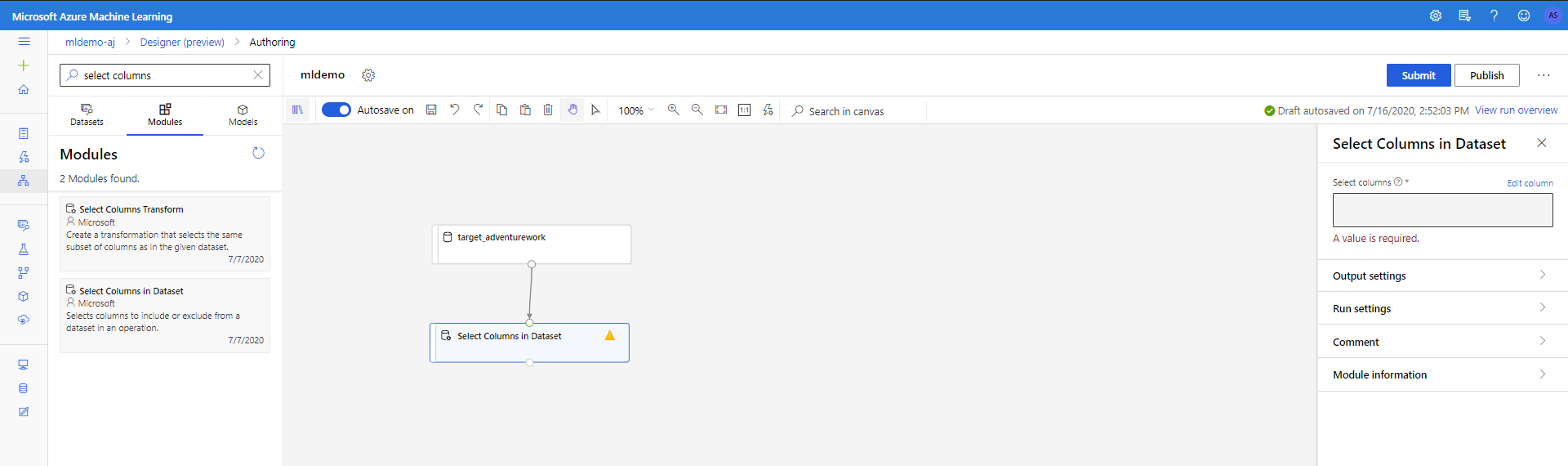
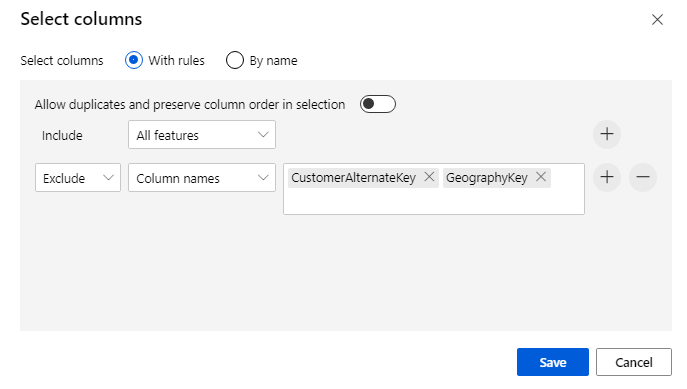
구성 요소를 클릭하여 속성 창을 엽니다. 편집 열을 클릭하여 삭제할 열을 지정합니다.
다음 두 열을 제외합니다. 페이지 맨 아래에 있는 저장

모델 빌드
데이터가 80-20으로 분할되어 80%는 기계 학습 모델을 학습하고 20%는 모델을 테스트합니다. 이 이진 분류 문제에는 “2클래스” 알고리즘이 사용됩니다.
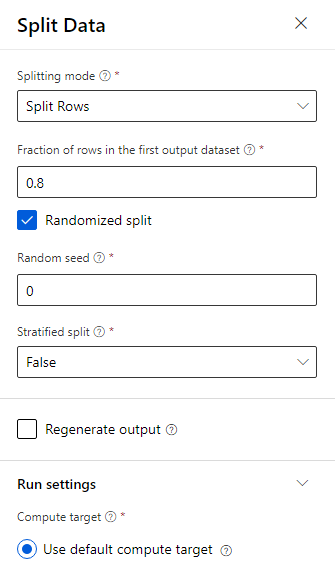
데이터 분할 구성 요소를 캔버스로 드래그합니다.
속성 창에서 첫 번째 출력 데이터 세트의 행 분수에 대해 0.8을 입력합니다.
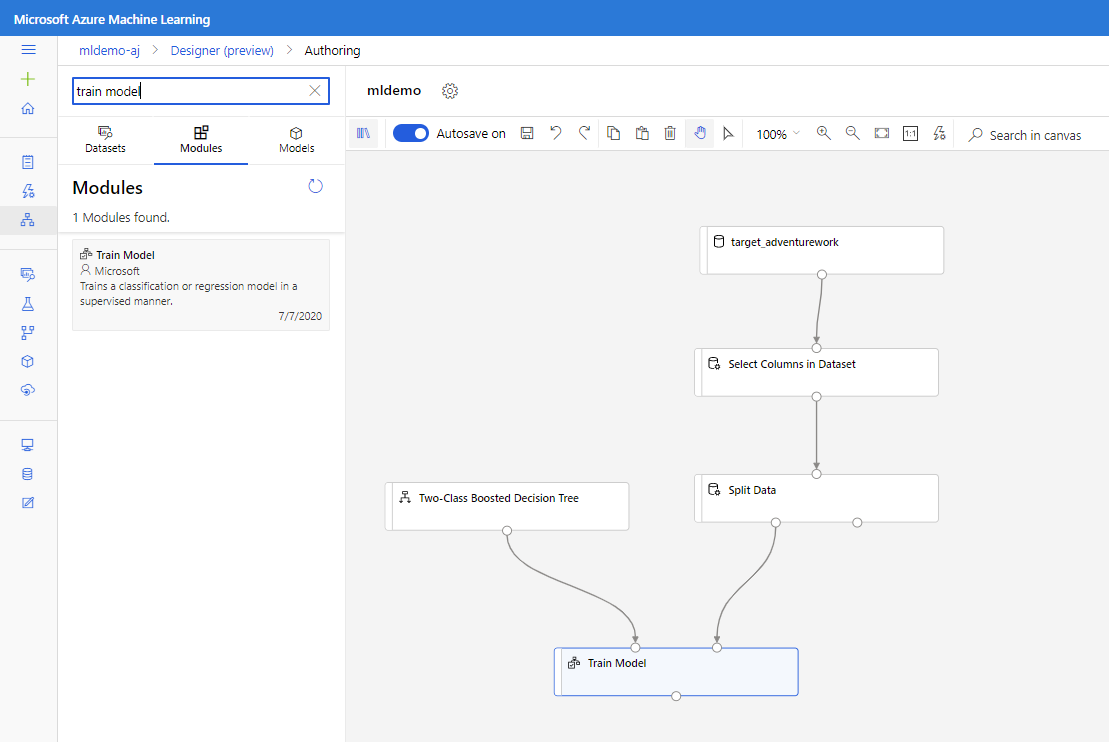
2클래스 향상된 의사 결정 트리 구성 요소를 캔버스로 드래그합니다.
모델 학습 구성 요소를 캔버스로 드래그합니다. 2클래스 향상된 의사 결정 트리(ML 알고리즘) 및 데이터 분할(알고리즘을 학습할 데이터) 구성 요소에 연결하여 입력을 지정합니다.
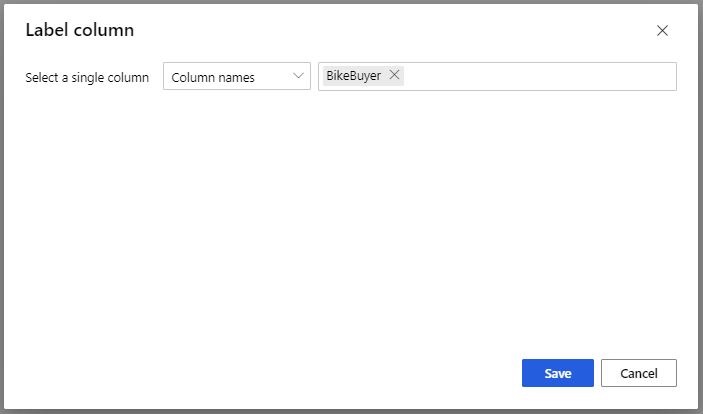
모델 학습 모델의 경우 속성 창의 레이블 열 옵션에서 열 편집을 선택합니다. BikeBuyer 열을 예측할 열로 선택하고 저장을 선택합니다.
모델 점수 매기기
이제 테스트 데이터에서 모델이 수행하는 방식을 테스트합니다. 두 가지 알고리즘을 비교하여 어떤 알고리즘이 더 나은지 확인합니다. 다음 단계를 수행합니다.
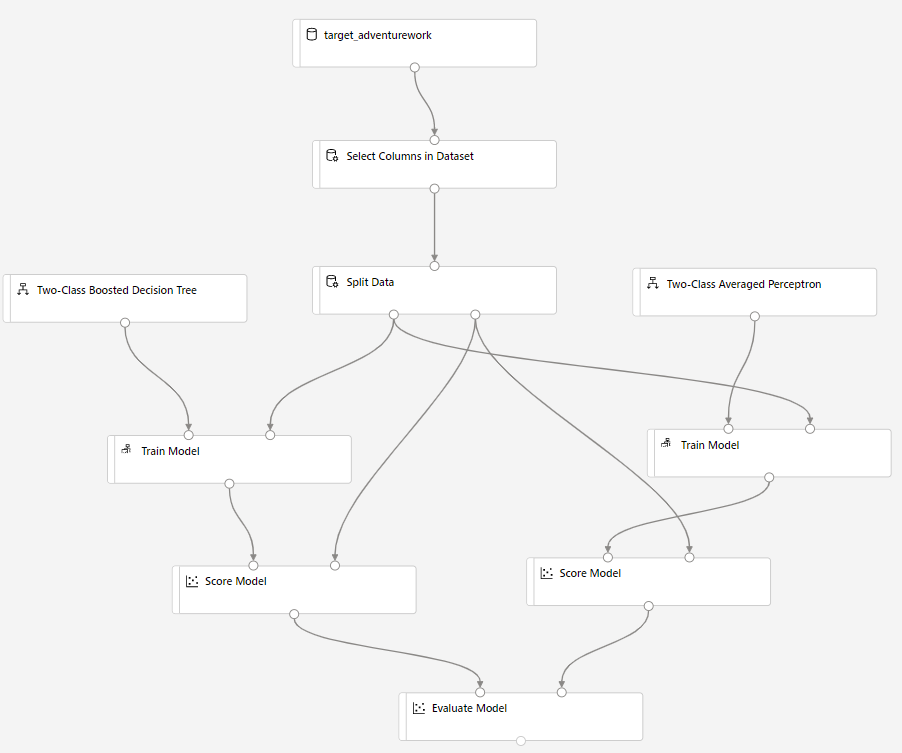
모델 점수 매기기 구성 요소를 캔버스로 끌어 놓고 모델 학습 및 데이터 분할 구성 요소에 연결합니다.
2클래스 Bayes 평균 퍼셉트론을 실험 캔버스로 끌어서 놓습니다. 2클래스 향상된 의사 결정 트리와 비교하여 이 알고리즘이 수행하는 방법을 비교합니다.
캔버스에서 모델 학습 및 모델 채점 구성 요소를 복사하고 붙여넣습니다.
모델 평가 구성 요소를 캔버스로 드래그하여 두 알고리즘을 비교합니다.
제출을 클릭하여 파이프라인 실행을 설정합니다.
실행이 완료되면 모델 평가 구성 요소를 마우스 오른쪽 단추로 클릭하고 평가 결과 시각화를 클릭합니다.
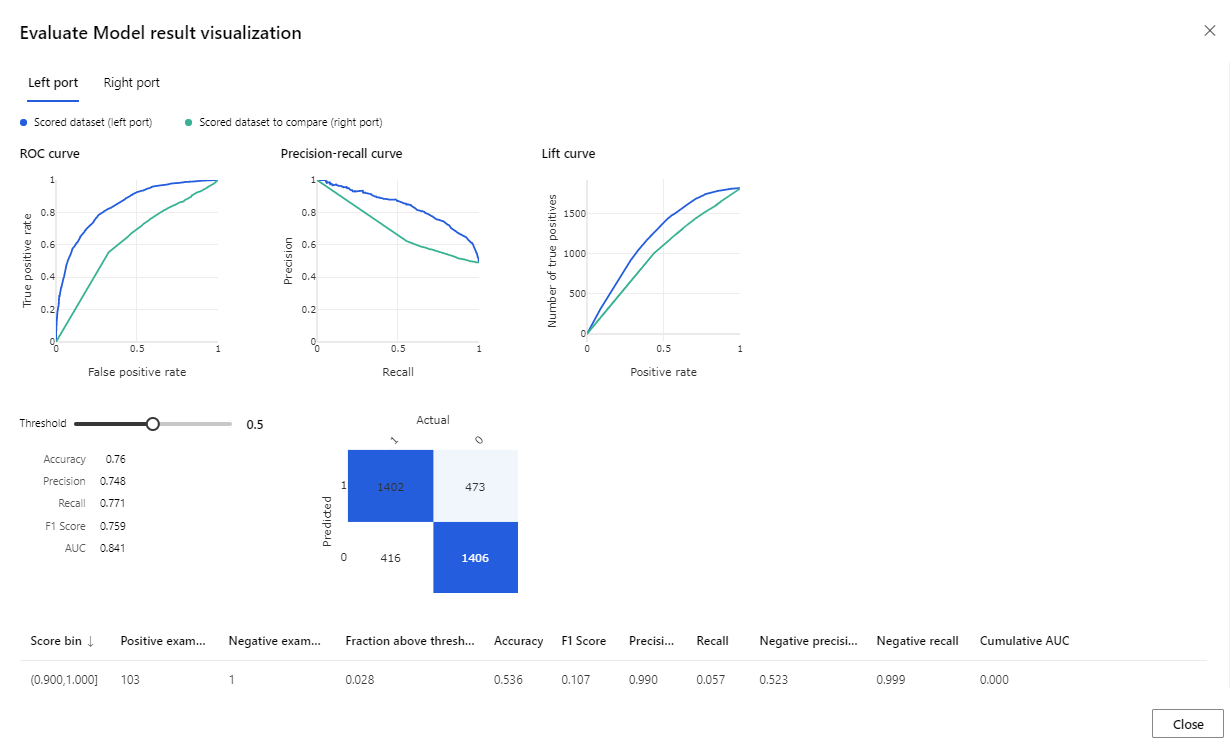

제공된 메트릭은 ROC 곡선, 정밀도-리콜 다이어그램 및 리프트 곡선입니다. 메트릭을 살펴보면 첫 번째 모델이 두 번째 모델보다 효과적으로 실행된 것을 확인할 수 있습니다. 첫 번째 모델이 예측한 것을 보려면 점수 모델 구성 요소를 마우스 오른쪽 단추로 클릭하고 점수가 매겨진 데이터 세트 시각화를 클릭하여 예측 결과를 확인합니다.
테스트 데이터 세트에 두 개의 열이 추가된 것을 확인할 수 있습니다.
- 점수가 매겨진 확률: 고객이 자전거 구매자일 가능성입니다.
- 점수가 매겨진 레이블: 모델에 의해 분류가 실행되었습니다. – 자전거 구매자(1) 혹은 아님(0) 레이블 지정에 대한 확률 임계값은 50%로 설정되고 조정할 수 있습니다.
점수가 매겨진 레이블(예측)로 열 BikeBuyer(실제) 비교를 통해 모델이 얼마나 잘 실행했는지 확인할 수 있습니다. 다음으로 이 모델을 사용하여 신규 고객에 대해 예측할 수 있습니다. 이 모델을 웹 서비스로 게시하거나 Azure Synapse에 결과를 다시 작성할 수 있습니다.
다음 단계
Azure Machine Learning에 대한 자세한 내용은 Azure의 Machine Learning 소개를 참조하세요.
데이터 웨어하우스의 기본 제공 채점에 대한 자세한 내용은 여기를 참조하세요.