고객 관리(계획됨) 장애 조치(failover)(미리 보기) 작동 방식
고객 관리 계획적 장애 조치(failover)는 재해 및 복구 계획과 테스트, 예상되는 대규모 재해에 대한 사전적 수정, 스토리지와 관련되지 않은 중단과 같은 시나리오에서 유용할 수 있습니다.
계획된 장애 조치(failover) 프로세스 중에 스토리지 계정의 기본 및 보조 지역이 전환됩니다. 원래 주 지역이 강등되어 새로운 보조 지역이 되고, 원래 보조 지역이 승격되어 새로운 주 지역이 됩니다. 계획된 장애 조치(failover)를 시작하려면 주 및 보조 지역 모두에서 스토리지 계정을 사용할 수 있어야 합니다.
이 문서에서는 고객이 관리하는 계획된 장애 조치(failover) 및 장애 복구(failback)가 프로세스의 각 단계에서 발생하는 일을 설명합니다. 예기치 못한 스토리지 엔드포인트 중단으로 인한 장애 조치(failover)가 작동하는 방식을 알아보려면 고객 관리(계획되지 않음) 장애 조치(failover) 방식을 참조하세요.
Important
고객 관리 계획 장애 조치(failover)는 현재 미리 보기 상태이며 다음 지역으로 제한됩니다.
- 프랑스 중부
- 프랑스 남부
- 인도 중부
- 인도 서부
- 동아시아
- 동남아시아
베타, 미리 보기로 제공되거나 아직 일반 공급으로 릴리스되지 않은 Azure 기능에 적용되는 약관은 Microsoft Azure 미리 보기에 대한 추가 사용 약관을 참조하세요.
Important
계획된 장애 조치(failover) 후 Azure Files 데이터가 있으면 스토리지 계정의 LST(마지막 동기화 시간) 값이 오래되었거나 NULL로 보고될 수 있습니다.
일관된 복구 지점을 유지하기 위해 장애 조치(failover) 및 장애 복구(failback) 중에 사용되는 스토리지 계정의 보조 지역에 시스템 스냅샷이 주기적으로 만들어집니다. 고객 관리 계획 장애 조치(failover)를 시작하면 원래 주 지역이 새로운 보조 지역이 됩니다. 계획된 장애 조치(failover)가 완료된 후 새 보조 데이터베이스에 사용 가능한 시스템 스냅샷이 없는 경우가 있어 계정의 전체 LST 값이 오래되었거나 Null로 표시되는 경우가 있습니다.
개체 만들기, 수정 또는 삭제와 같은 사용자 작업으로 인해 스냅샷 만들기가 트리거될 수 있으므로 계획된 장애 조치(failover) 이후 이러한 작업이 발생하는 계정에는 추가적인 주의가 필요하지 않습니다. 그러나 스냅샷이나 사용자 작업이 없는 계정은 시스템 스냅샷 만들기가 트리거될 때까지 Null LST 값을 계속 표시할 수 있습니다.
필요한 경우 스토리지 계정 내의 각 공유에 대해 다음 작업 중 하나를 수행하여 스냅샷 만들기를 트리거합니다. 완료되면 30분 이내에 사용자의 계정에 유효한 LST 값이 표시됩니다.
- 공유를 탑재한 다음, 모든 파일을 읽기용으로 엽니다.
- 테스트 또는 샘플 파일을 공유에 업로드합니다.
계획된 장애 조치(failover) 및 장애 복구(failback) 중 중복성 관리
팁
고객 관리 장애 조치(failover) 및 장애 복구(failback) 프로세스 중 다양한 중복성 상태를 자세히 이해하려면 각각에 대한 정의에 대해 Azure Storage 중복성을 참조하세요.
계획된 장애 조치(failover) 프로세스 동안 주 지역의 스토리지 서비스 엔드포인트는 읽기 전용이 되고 나머지 업데이트는 보조 지역으로 복제가 완료됩니다. 다음으로, 모든 스토리지 서비스 엔드포인트의 DNS(도메인 이름 서비스) 항목이 전환됩니다. 스토리지 계정의 보조 엔드포인트는 새 기본 엔드포인트가 되고 원래 기본 엔드포인트는 새 보조 엔드포인트가 됩니다. 주 지역과 보조 지역이 전환되더라도 각 지역 내의 데이터 복제는 변경되지 않은 상태로 유지됩니다.
계획된 장애 복구(failback) 프로세스는 기본적으로 계획된 장애 조치(failover) 프로세스와 동일하지만, 한 가지 예외가 있습니다. 계획된 장애 복원 중에 Azure는 스토리지 계정의 원래 중복성 구성을 저장하고 장애 복원 시 원래 상태로 복원합니다. 예를 들어, 스토리지 계정이 원래 GZRS로 구성된 경우 스토리지 계정은 장애 복구(failback) 후 GZRS가 됩니다.
참고 항목
고객 관리(계획되지 않음) 장애 조치(failover)와 달리 계획된 장애 조치(failover) 중에는 엔드포인트의 DNS 항목이 새 보조 지역으로 변경되기 전에 기본 지역에서 보조 지역으로의 복제가 완료되어야 합니다. 이 때문에 프로세스 전체에서 주 지역과 보조 지역을 모두 사용할 수 있는 한 계획된 장애 조치(failover) 또는 장애 복구 중에는 데이터 손실이 예상되지 않습니다.
장애 조치(failover)를 시작하는 방법
장애 조치(failover)를 시작하는 방법을 알아보려면 계정 장애 조치(failover) 시작을 참조하세요.
계획된 장애 조치(failover) 및 장애 복구(failback) 프로세스
다음 다이어그램은 스토리지 계정의 고객 관리 계획된 장애조치 및 장애 복구 중에 발생하는 일을 보여 줍니다.
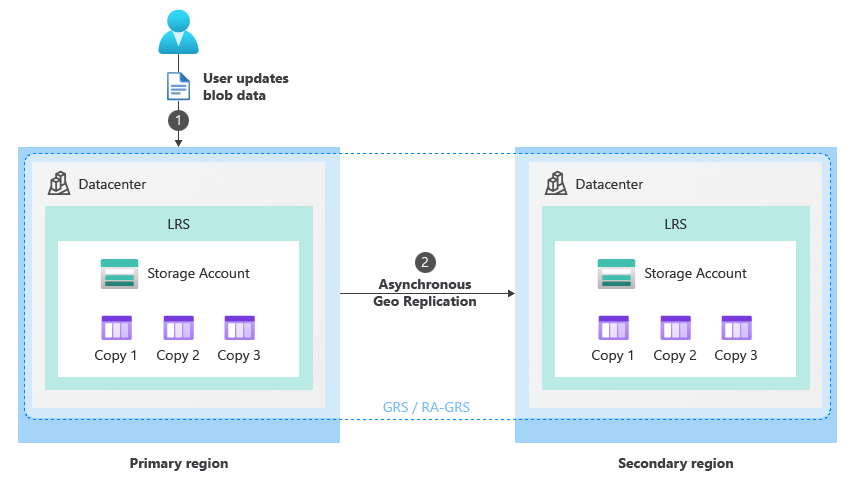
정상적인 상황에서 클라이언트는 스토리지 서비스 엔드포인트를 통해 주 지역의 스토리지 계정에 데이터를 씁니다(1). 그런 다음 데이터는 주 지역에서 보조 지역으로 비동기적으로 복사됩니다(2). 다음 이미지는 GRS로 구성된 스토리지 계정의 정상 상태를 보여 줍니다.

계획된 장애 조치(failover) 프로세스(GRS/RA-GRS)
보조 지역에 대한 스토리지 계정의 장애 조치(failover)를 시작하여 재해 복구 테스트를 시작합니다. 다음 단계에서는 장애 조치(failover) 프로세스를 설명하고, 후속 이미지는 그림을 제공합니다.
- 원래 주 지역은 읽기 전용이 됩니다.
- 주 지역에서 보조 지역으로의 모든 데이터 복제가 완료됩니다.
- 보조 지역의 스토리지 서비스 엔드포인트에 대한 DNS 항목이 승격되어 스토리지 계정의 새 기본 엔드포인트가 됩니다.
장애 조치(failover)에는 일반적으로 약 1시간이 걸립니다.

장애 조치(failover)가 완료되면 원래 주 지역은 새 보조 지역이 되고(1) 원래 보조 지역은 새 주 지역이 됩니다(2). Blob, 테이블, 큐 및 파일에 대한 스토리지 서비스 엔드포인트에 대한 URI는 동일하게 유지되지만 DNS 항목은 새 주 지역을 가리키도록 변경됩니다(3). 사용자는 새 주 지역의 스토리지 계정에 데이터 쓰기를 다시 시작할 수 있으며, 다음 이미지와 같이 데이터가 새 보조 지역에 비동기적으로 복사됩니다(4).

장애 조치(failover) 상태인 동안 재해 복구 테스트를 수행합니다.
계획된 장애 복구(failback) 프로세스(GRS/RA-GRS)
테스트가 완료되면 다른 장애 조치(failover)를 수행하여 원래 주 지역으로 장애 복구합니다. 다음 이미지와 같이 장애 조치(failover) 프로세스 중에:
- 원래 주 지역은 읽기 전용이 됩니다.
- 모든 데이터는 현재 주 지역에서 현재 보조 지역으로 복제를 완료합니다.
- 스토리지 서비스 엔드포인트에 대한 DNS 항목은 초기 장애 조치(failover)가 수행되기 전에 주 지역이었던 지역을 다시 가리키도록 변경됩니다.
장애 복구에는 일반적으로 약 1시간이 걸립니다.

장애 복구가 완료되면 스토리지 계정이 원래 중복 구성으로 복원됩니다. 사용자는 원래 주 지역의 스토리지 계정에 데이터 쓰기를 다시 시작할 수 있으며(1), 원래 보조 지역에 대한 복제(2)는 장애 조치(failover) 이전과 같이 계속됩니다.