주 지역으로 장애 조치(failover)된 Azure Virtual Machines 다시 보호
Azure Site Recovery를 사용하여 Azure Virtual Machines를 한 지역에서 다른 지역으로 장애 조치(failover)하면 가상 머신이 보조 지역에서 보호되지 않은 상태로 부팅됩니다. 가상 머신을 주 지역으로 장애 복구하려면 다음 작업을 수행합니다.
- 가상 머신이 주 지역으로 복제를 시작하도록 보조 지역의 VM을 다시 보호합니다.
- 다시 보호가 완료되고 가상 머신이 복제되면 보조 지역에서 주 지역으로 장애 조치(failover)할 수 있습니다.
필수 조건
- 기본 지역에서 보조 지역으로의 가상 머신 장애 조치(failover)가 커밋되어야 합니다. 시작하기 전에 가상 머신 상태가 장애 조치(failover)가 커밋됨이어야 합니다.
- 주 대상 사이트가 사용 가능하고 해당 지역에서 리소스를 만들거나 액세스할 수 있어야 합니다.
가상 머신 다시 보호
자격 증명 모음>복제된 항목에서 장애 조치(failover)된 가상 머신을 마우스 오른쪽 단추로 클릭하고 다시 보호를 선택합니다. 다시 보호 방향이 보조에서 주로 표시됩니다.
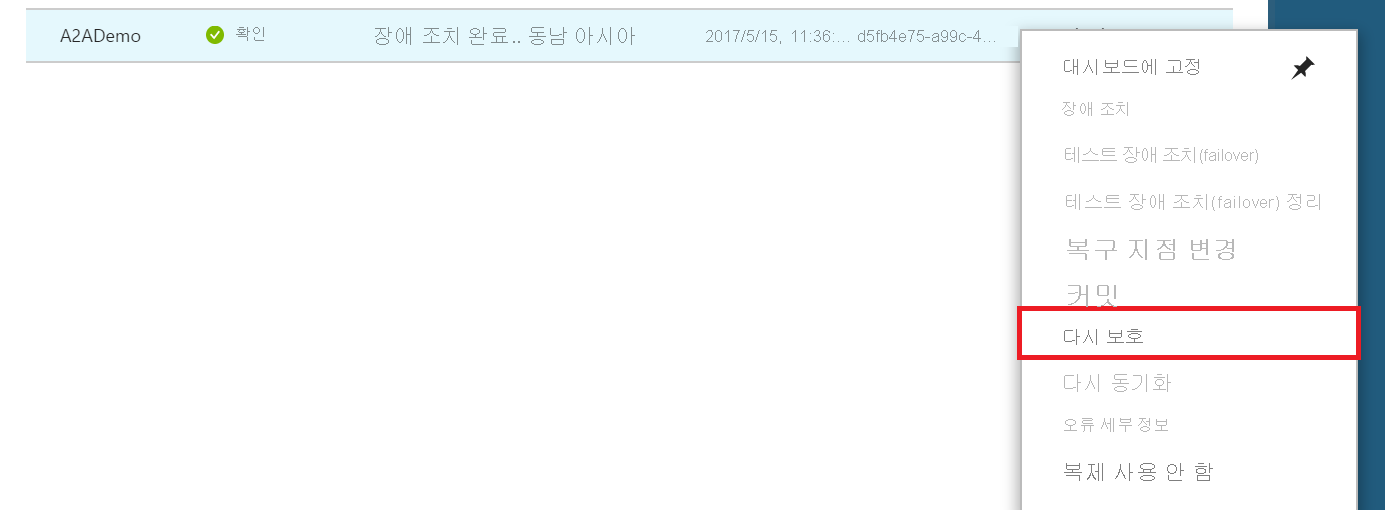
리소스 그룹, 네트워크, 스토리지 및 가용성 집합을 검토합니다. 그런 다음 확인을 선택합니다. 신규로 표시된 리소스가 있는 경우 다시 보호 프로세스의 일부로 생성된 리소스입니다.
다시 보호 작업은 최신 데이터로 대상 사이트를 시드합니다. 작업이 완료되면 델타 복제가 수행됩니다. 그런 다음 주 사이트로 다시 장애 조치(failover)할 수 있습니다. 사용자 지정 옵션을 사용하여 다시 보호 중에 사용할 네트워크나 스토리지 계정을 선택할 수 있습니다.
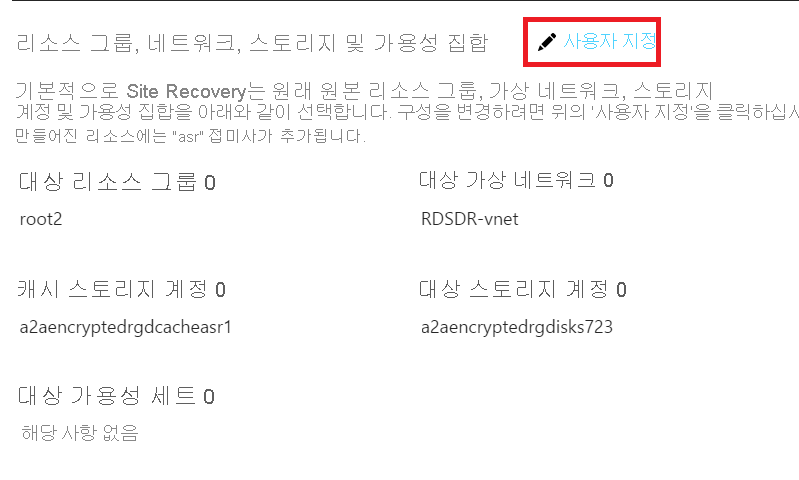


다시 보호 설정 사용자 지정
다시 보호하는 동안 대상 가상 머신의 다음 속성을 사용자 지정할 수 있습니다.

| 속성 | 주의 |
|---|---|
| 대상 리소스 그룹 | 가상 머신이 만들어지는 대상 리소스 그룹을 수정합니다. 다시 보호의 일부로 대상 가상 머신이 삭제됩니다. 장애 조치(failover)된 가상 머신을 원본 가상 머신으로 다시 보호하는 경우 대상 리소스 그룹을 변경할 수 없습니다. |
| 대상 가상 네트워크 | 다시 보호 작업 동안 대상 네트워크를 변경할 수 없습니다. 네트워크를 변경하려면 네트워크 매핑을 다시 실행합니다. |
| 용량 예약 | 가상 머신에 대한 용량 예약을 구성합니다. 새 예약 용량 그룹을 만들어 용량을 예약하거나 기존 용량 예약 그룹을 선택할 수 있습니다. 용량 예약에 대한 자세한 정보 |
| 대상 스토리지(보조 가상 머신은 관리 디스크를 사용하지 않음) | 장애 조치(failover) 후 가상 머신이 사용하는 스토리지 계정을 변경할 수 있습니다. |
| 복제 관리 디스크(보조 가상 머신은 관리 디스크를 사용함) | Site Recovery는 보조 가상 머신의 관리 디스크를 미러링하는 주 지역에서 관리 디스크의 복제본을 만듭니다. |
| 캐시 스토리지 | 복제하는 동안 사용할 캐시 스토리지 계정을 지정할 수 있습니다. 기본적으로 캐시 스토리지 계정이 없는 경우에는 새로 생성됩니다.
기본적으로 원래 기본 위치에서 원본 가상 머신에 대해 선택한 스토리지 계정 유형(표준 스토리지 계정 또는 프리미엄 블록 Blob Storage 계정)이 사용됩니다. 예를 들어 원래 원본에서 대상으로 복제할 때 높은 변동을 선택한 경우 대상에서 원래 원본으로 다시 보호하는 동안에는 프리미엄 블록 Blob이 기본적으로 사용됩니다. 다시 보호를 위해 구성하고 변경할 수 있습니다. 자세한 내용은 Azure Virtual Machines 재해 복구 - 높은 변동 지원을 참조하세요. |
| 가용성 집합 | 보조 지역의 가상 머신이 가용성 집합의 일부인 경우 주 지역의 대상 가상 머신에 대한 가용성 집합을 선택할 수 있습니다. 기본적으로 Site Recovery는 주 지역에서 기존 가용성 집합을 찾고 사용합니다. 사용자 지정하는 동안 새 가용성 집합을 지정할 수 있습니다. |
다시 보호하는 동안 어떻게 되나요?
기본적으로 다음 작업이 수행됩니다.
- 장애 조치된 가상 머신이 실행 중인 지역에 캐시 스토리지 계정이 만들어집니다.
- 대상 스토리지 계정(주 지역의 원래 스토리지 계정)이 없는 경우 새로 만들어집니다. 할당된 스토리지 계정 이름은 보조 가상 머신에서 사용하는 스토리지 계정의 이름에 접미사로
asr이 추가된 것입니다. - 가상 머신에서 관리 디스크를 사용하는 경우 복제본 관리 디스크는 보조 가상 머신의 디스크에서 복제된 데이터를 저장하기 위해 주 지역에 생성됩니다.
- 원본 디스크(보조 지역의 가상 머신에 연결된 디스크)의 임시 복제본은
ms-asr-<GUID>라는 이름으로 만들어지며, 데이터를 전송하고 읽는 데 사용됩니다. 임시 디스크를 사용하면 가상 머신에 연결된 원래 디스크의 16% 대역폭 대신 디스크의 전체 대역폭을 활용할 수 있습니다. 임시 디스크는 다시 보호가 완료되면 삭제됩니다. - 대상 가용성 집합이 없는 경우에는 필요에 따라 다시 보호 작업의 일부로 새로 생성됩니다. 다시 보호 설정을 사용자 지정한 경우 선택한 집합이 사용됩니다.
다시 보호 작업을 트리거하고 대상 가상 머신이 존재하면 다음이 발생합니다.
- 대상 쪽 가상 머신이 실행 중인 경우 꺼집니다.
- 가상 머신이 관리 디스크를 사용하는 경우
-ASRReplica접미사를 추가하여 원래 디스크의 사본이 만들어집니다. 원래 디스크가 삭제됩니다.-ASRReplica사본은 복제에 사용됩니다. - 가상 머신이 관리되지 않는 디스크를 사용할 경우 대상 가상 머신의 데이터 디스크가 분리되어 복제에 사용됩니다. OS 디스크의 복사본이 만들어지고 가상 머신에서 연결됩니다. 원래의 OS 디스크가 분리되며 복제에 사용됩니다.
- 원본 디스크와 대상 디스크 간의 변경 내용만 동기화됩니다. 차등 백업은 디스크를 모두 비교하여 계산된 다음, 전달됩니다. 다시 보호를 완료하는 데 걸리는 예상 시간을 찾으려면 아래를 확인합니다.
- 동기화가 완료되면 델타 복제가 시작되고, 복제 정책에 따라 복구 지점이 생성됩니다.
다시 보호 작업을 트리거할 때 대상 가상 머신과 디스크가 없으면 다음이 발생합니다.
- 가상 머신이 관리 디스크를 사용하는 경우
-ASRReplica접미사를 추가하여 복제본 디스크가 생성됩니다.-ASRReplica사본은 복제에 사용됩니다. - 가상 머신이 관리되지 않는 디스크를 사용하는 경우 복제 디스크는 대상 스토리지 계정에 만들어집니다.
- 전체 디스크가 장애 조치된 지역에서 새 대상 지역에 복사됩니다.
- 동기화가 완료되면 델타 복제가 시작되고, 복제 정책에 따라 복구 지점이 생성됩니다.
참고 항목
ms-asr 디스크는 다시 보호 작업이 완료된 후 삭제되는 임시 디스크입니다. 이러한 디스크가 활성화된 시간 동안 Azure 관리 디스크 가격을 기준으로 최소 요금이 청구됩니다.
다시 보호를 수행하는 데 걸리는 예상 시간
대부분의 경우 Azure Site Recovery는 전체 데이터를 원본 지역에 복제하지 않습니다. 복제되는 데이터의 양은 다음 조건에 따라 달라집니다.
- Azure Site Recovery는 원본 가상 머신의 데이터가 삭제, 손상되거나 어떤 이유로든 액세스할 수 없는 경우 다시 보호를 지원하지 않습니다. 예를 들어, 리소스 그룹 변경 또는 삭제가 있습니다. 또는 이전 재해 복구 보호를 사용하지 않도록 설정하고 현재 셀이 있는 영역에서 새 보호를 사용하도록 설정할 수 있습니다.
- 원본 가상 머신 데이터에 액세스할 수 있는 경우 두 디스크를 비교하여 차등이 계산되고 차이점만 전송됩니다.
이 경우 다시 보호 시간은
checksum calculation time + checksum differentials transfer time + time taken to process the recovery points from Azure Site Recovery agent + auto scale time보다 크거나 같습니다.
시나리오 2에서 다시 보호 시간을 관리하는 요소
다음 요소는 시나리오 2에서 원본 가상 머신에 액세스할 수 있는 다시 보호 시간에 영향을 미칩니다.
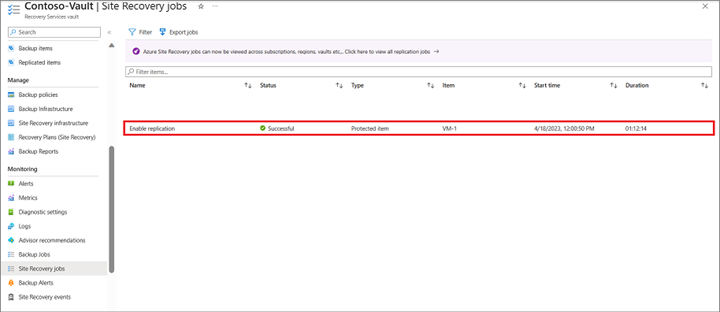
체크섬 계산 시간 - 주 위치에서 재해 복구 위치까지 복제 사용 프로세스를 완료하는 데 걸리는 시간은 체크섬 차등 계산의 벤치마크로 사용됩니다. Recovery Services 자격 증명 모음>모니터링>Site Recovery 작업으로 이동하여 복제를 사용하도록 설정하는 프로세스를 완료하는 데 걸린 시간을 확인합니다. 체크섬 계산을 완료하는 데 필요한 최소 시간입니다.
체크섬 차등 데이터 전송은 디스크 처리량의 약 23%에서 발생합니다.
Azure Site Recovery 에이전트에서 보낸 복구 지점을 처리하는 데 걸리는 시간 – Azure Site Recovery 에이전트는 체크섬 계산 및 전송 단계 중에도 복구 지점을 계속 보냅니다. 그러나 Azure Site Recovery는 체크섬 차등 전송이 완료된 후에만 복구 지점을 처리합니다. 복구 지점을 처리하는 데 걸리는 시간은 체크섬 차등 계산 및 체크섬 차등 전송 시간(체크섬 차등 계산 시간 + 체크섬 차등 전송 시간)의 약 5분의 1(1/5)입니다. 예를 들어 체크섬 차등 계산 및 체크섬 차등 전송에 걸리는 시간이 15시간인 경우 에이전트에서 복구 지점을 처리하는 데 걸리는 시간은 3시간입니다.
자동 스케일링 시간은 약 20~30분입니다.
시나리오 예:
다음 스크린샷에서 예제를 살펴보겠습니다. 주 위치에서 재해 복구 위치로 복제를 사용하도록 설정하는 데 1시간 12분이 걸렸습니다. 체크섬 계산 시간은 최소 1시간 12분입니다. 장애 조치(failover) 후 데이터 변경의 양이 45GB이고 디스크의 처리량이 60Mbps라고 가정하면 차등 전송은 14Mbps에서 발생하며 차등 전송에 걸리는 시간은 45GB/14Mbps, 즉 약 55분입니다. 복구 지점을 처리하는 데 걸리는 시간은 체크섬 계산에 소요된 총 시간(72분)과 데이터 전송에 소요된 시간(55분)의 약 5분의 1이며 약 25분 정도입니다. 또한 자동 스케일링에는 20~30분이 걸립니다. 따라서 다시 보호에 걸리는 총 시간은 최소 3시간 이상이어야 합니다.

위의 내용은 다시 보호 시간을 예측하는 방법에 대한 간단한 그림입니다. 고객이 대상 지역으로 장애 조치(failover)하고 다시 보호하면 원본 가상 머신 및 관련 리소스가 삭제되지 않습니다. 고객이 주 지역으로 장애 복구(failback )하고 다시 보호하면 VM(대상/재해 복구 지역의) 및 관련 리소스가 삭제됩니다.
다음 단계
가상 머신을 보호한 후 장애 조치(failover)를 시작할 수 있습니다. 장애 조치를 수행하면 보조 지역의 가상 머신이 종료되고 주 지역에서 가상 머신이 생성되어 부팅됩니다. 이 프로세스 도중 짧은 가동 중지 시간이 발생합니다. 이 프로세스에 적절한 시간을 선택하고, 주 사이트로 전체 장애 조치를 시작하기 전에 테스트 장애 조치를 실행하는 것이 좋습니다.
Azure Site Recovery 장애 조치에 대해 자세히 알아봅니다.