RHEL에서 Azure NetApp Files를 사용한 SAP HANA 스케일 업의 고가용성
이 문서에서는 Azure NetApp Files를 사용하여 HANA 파일 시스템이 NFS를 통해 탑재된 경우 스케일 업 배포에서 SAP HANA 시스템 복제를 구성하는 방법을 설명합니다. 구성 및 설치 명령 예에서 인스턴스 번호 03 및 HANA 시스템 ID HN1이 사용됩니다. SAP HANA 시스템 복제는 하나의 기본 노드와 하나 이상의 보조 노드로 구성됩니다.
이 문서의 단계가 다음 접두사로 표시되면 의미는 다음과 같습니다.
- [A]: 단계가 모든 노드에 적용됩니다.
- [1]: 단계가 노드 1에만 적용됩니다.
- [2]: 단계가 노드 2에만 적용됩니다.
필수 조건
다음 SAP Note 및 문서를 먼저 읽어 보세요.
- SAP Note 1928533, 다음 항목을 포함합니다.
- SAP 소프트웨어 배포에 지원되는 Azure VM(Virtual Machine) 크기 목록.
- Azure VM 크기에 대한 중요한 용량 정보.
- 지원되는 SAP 소프트웨어 및 OS(운영 체제)와 데이터베이스 조합.
- Microsoft Azure에서 Windows 및 Linux에 필요한 SAP 커널 버전.
- SAP Note 2015553는 Azure에서 SAP을 지원하는 SAP 소프트웨어 배포에 대한 필수 구성 요소를 나열합니다.
- SAP Note 405827에는 HANA 환경에 권장되는 파일 시스템이 나열되어 있습니다.
- SAP Note 2002167에는 Red Hat Enterprise Linux에 권장되는 OS 설정이 있습니다.
- SAP Note 2009879에는 Red Hat Enterprise Linux용 SAP HANA 지침이 있습니다.
- SAP Note 3108302에는 Red Hat Enterprise Linux 9.x용 SAP HANA 지침이 있습니다.
- SAP Note 2178632는 Azure에서 SAP에 대해 보고된 모든 모니터링 메트릭에 대한 자세한 정보를 포함하고 있습니다.
- SAP Note 2191498는 Azure에서 Linux에 필요한 SAP Host Agent 버전을 포함하고 있습니다.
- SAP Note 2243692는 Azure에서 Linux의 SAP 라이선스에 대한 정보를 포함하고 있습니다.
- SAP Note 1999351에는 SAP용 Azure 고급 모니터링 확장에 대한 추가 문제 해결 정보가 있습니다.
- SAP Community Wiki에는 Linux에 필요한 모든 SAP Note가 포함되어 있습니다.
- Linux에서 SAP용 Azure Virtual Machines 계획 및 구현
- Linux에서 SAP용 Azure Virtual Machines 배포
- Linux에서 SAP용 Azure Virtual Machines DBMS 배포
- Pacemaker 클러스터의 SAP HANA 시스템 복제
- 일반적인 RHEL(Red Hat Enterprise Linux) 설명서:
- High Availability Add-On Overview(고가용성 추가 기능 개요)
- High Availability Add-On Administration(고가용성 추가 기능 관리)
- High Availability Add-On Reference(고가용성 추가 기능 참조)
- HANA 파일 시스템이 NFS 공유에 있을 때 Pacemaker 클러스터의 스케일 업에서 SAP HANA 시스템 복제 구성
- Azure 특정 RHEL 설명서:
- Support Policies for RHEL High Availability Clusters - Microsoft Azure Virtual Machines as Cluster Members(RHEL 고가용성 클러스터용 지원 정책 - Microsoft Azure Virtual Machines(클러스터 멤버))
- Installing and Configuring a Red Hat Enterprise Linux 7.4 (and later) High-Availability Cluster on Microsoft Azure(Microsoft Azure에서 Red Hat Enterprise Linux 7.4 이상 고가용성 클러스터 설치 및 구성)
- HANA 파일 시스템이 NFS 공유에 있을 때 Pacemaker 클러스터에서 SAP HANA 스케일 업 시스템 복제 구성
- SAP HANA용 Azure NetApp Files 기반 NFS v4.1 볼륨
개요
일반적으로 스케일 업 환경에서는 SAP HANA의 모든 파일 시스템이 로컬 스토리지에서 탑재됩니다. Red Hat Enterprise Linux에서 SAP HANA 시스템 복제의 HA(고가용성) 설정은 RHEL에서 SAP HANA 시스템 복제 설정에 게시되어 있습니다.
Azure NetApp Files NFS 공유에서 스케일 업 시스템의 SAP HANA HA를 달성하려면 한 노드에서 Azure NetApp Files의 NFS 공유에 대한 액세스 권한을 잃을 때 HANA 리소스를 복구할 수 있도록 클러스터에 몇 가지 추가 리소스 구성이 필요합니다. 클러스터는 NFS 탑재를 관리하여 리소스의 상태를 모니터링할 수 있도록 합니다. 파일 시스템 탑재와 SAP HANA 리소스 간의 종속성이 적용됩니다.
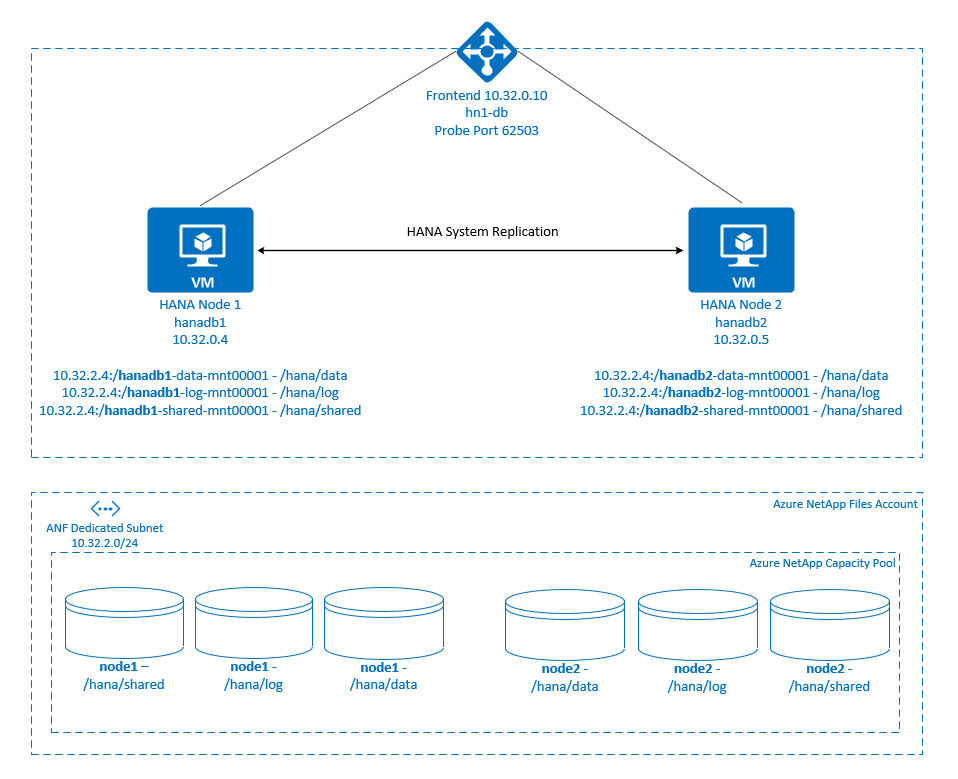 .
.
SAP HANA 파일 시스템은 각 노드에서 Azure NetApp Files를 사용하여 NFS 공유에 탑재됩니다. 파일 시스템 /hana/data, /hana/log, /hana/shared는 각 노드에 고유합니다.
Node1에 탑재됨(hanadb1):
- /hana/data에 10.32.2.4:/hanadb1-data-mnt00001
- /hana/log에 10.32.2.4:/hanadb1-log-mnt00001
- /hana/shared에 10.32.2.4:/hanadb1-shared-mnt00001
Node2에 탑재됨(hanadb2):
- /hana/data에 10.32.2.4:/hanadb2-data-mnt00001
- /hana/log에 10.32.2.4:/hanadb2-log-mnt00001
- /hana/shared에 10.32.2.4:/hanadb2-shared-mnt00001
참고 항목
파일 시스템 /hana/shared, /hana/data, /hana/log는 두 노드 간에 공유되지 않습니다. 각 클러스터 노드에는 별도의 파일 시스템이 있습니다.
SAP HANA 시스템 복제 구성은 전용 가상 호스트 이름과 가상 IP 주소를 사용합니다. Azure에서는 가상 IP 주소를 사용하려면 부하 분산 장치가 필요합니다. 여기에 표시된 구성에는 다음과 같은 부하 분산 장치가 있습니다.
- 프런트 엔드 IP 주소: hn1-db의 경우 10.32.0.10
- 프로브 포트: 62503
Azure NetApp Files 인프라 설정
Azure NetApp Files 인프라 설정을 진행하기 전에 Azure NetApp Files 설명서를 숙지하세요.
Azure NetApp Files는 여러 Azure 지역에서 사용할 수 있습니다. 선택한 Azure 지역에서 Azure NetApp Files를 제공하는지 확인하세요.
Azure 지역별 Azure NetApp Files 가용성에 대한 자세한 내용은 Azure 지역별 Azure NetApp Files 가용성을 참조하세요.
중요 사항
SAP HANA용 Azure NetApp Files 스케일업 시스템을 생성할 때 SAP HANA용 Azure NetApp Files 기반 NFS v4.1 볼륨에 설명된 중요한 고려 사항에 유의하세요.
Azure NetApp Files에서 HANA 데이터베이스 크기 조정
Azure NetApp Files 볼륨의 처리량은 Azure NetApp Files에 대한 서비스 수준에 설명된 대로 볼륨 크기와 서비스 수준의 함수입니다.
Azure NetApp Files를 사용하여 Azure의 SAP HANA에 대한 인프라를 설계하는 동안 SAP HANA용 Azure NetApp Files의 NFS v4.1 볼륨에 대한 권장 사항을 알고 있어야 합니다.
이 문서의 구성에는 간단한 Azure NetApp Files 볼륨이 제공됩니다.
Important
성능이 핵심인 프로덕션 시스템의 경우 SAP HANA용 Azure NetApp Files 애플리케이션 볼륨 그룹을 평가하고 사용하는 것이 좋습니다.
Azure NetApp Files 리소스 배포
다음 지침에서는 Azure 가상 네트워크를 이미 배포했다고 가정합니다. Azure NetApp Files 리소스가 탑재될 Azure NetApp Files 리소스와 VM을 동일한 Azure 가상 네트워크 또는 피어링된 Azure 가상 네트워크에 배포해야 합니다.
NetApp 계정 만들기의 지침에 따라 선택한 Azure 지역에서 NetApp 계정을 만듭니다.
Azure NetApp Files 용량 풀 설정의 지침에 따라 Azure NetApp Files 용량 풀을 설정합니다.
이 문서에 표시된 HANA 아키텍처는 Ultra 서비스 수준에서 단일 Azure NetApp Files 용량 풀을 사용합니다. Azure의 HANA 워크로드의 경우 Azure NetApp Files Ultra 또는 Premium 서비스 수준을 사용하는 것이 좋습니다.
Azure NetApp Files에 서브넷 위임의 지침에 따라 Azure NetApp Files에 서브넷을 위임합니다.
Azure NetApp Files에 대한 NFS 볼륨 만들기의 지침에 따라 Azure NetApp Files 볼륨을 배포합니다.
볼륨을 배포할 때 NFSv4.1 버전을 선택해야 합니다. 지정된 Azure NetApp Files 서브넷에 볼륨을 배포합니다. Azure NetApp 볼륨의 IP 주소는 자동으로 할당됩니다.
Azure NetApp Files 리소스와 Azure VM은 동일하거나 피어링된 Azure 가상 네트워크에 있어야 합니다. 예를 들어
hanadb1-data-mnt00001및hanadb1-log-mnt00001는 볼륨 이름이며nfs://10.32.2.4/hanadb1-data-mnt00001및nfs://10.32.2.4/hanadb1-log-mnt00001는 Azure NetApp Files 볼륨의 파일 경로입니다.hanadb1에서
- 볼륨 hanadb1-data-mnt00001(nfs://10.32.2.4:/hanadb1-data-mnt00001)
- 볼륨 hanadb1-log-mnt00001(nfs://10.32.2.4:/hanadb1-log-mnt00001)
- 볼륨 hanadb1-shared-mnt00001(nfs://10.32.2.4:/hanadb1-shared-mnt00001)
hanadb2에서
- 볼륨 hanadb2-data-mnt00001(nfs://10.32.2.4:/hanadb2-data-mnt00001)
- 볼륨 hanadb2-log-mnt00001(nfs://10.32.2.4:/hanadb2-log-mnt00001)
- 볼륨 hanadb2-shared-mnt00001(nfs://10.32.2.4:/hanadb2-shared-mnt00001)
참고 항목
이 문서에서 /hana/shared을 탑재하는 모든 명령은 NFSv4.1 /hana/shared 볼륨에 대해 제공됩니다.
/hana/shared 볼륨을 NFSv3 볼륨으로 배포한 경우 NFSv3에 대한 /hana/shared의 탑재 명령을 조정하는 것을 잊지 마세요.
인프라 준비
Azure Marketplace에는 다양한 버전의 Red Hat을 사용하여 새 VM을 배포하는 데 사용할 수 있는 고가용성 추가 기능이 포함된 SAP HANA에 적합한 이미지가 포함되어 있습니다.
Azure Portal을 통해 수동으로 Linux VM 배포
이 문서에서는 리소스 그룹, Azure 가상 네트워크 및 서브넷을 이미 배포했다고 가정합니다.
SAP HANA용 VM을 배포합니다. HANA 시스템에 지원되는 적합한 RHEL 이미지를 선택합니다. 가상 머신 확장 집합, 가용성 영역 또는 가용성 집합 같은 옵션 중 하나에서 VM을 배포할 수 있습니다.
Important
선택한 운영 체제가 배포에 사용하려는 특정 VM 유형에서 SAP HANA용으로 인증된 SAP인지 확인해야 합니다. SAP HANA 인증 IaaS 플랫폼에서 SAP HANA 인증 VM 유형 및 해당 OS 릴리스 를 조회할 수 있습니다. 특정 VM 형식에 대한 SAP HANA 지원 OS 릴리스의 전체 목록을 보려면 VM 유형의 세부 정보를 확인하세요.
Azure Load Balancer 구성
VM 구성 중에 네트워킹 섹션에서 기존 부하 분산 장치를 만들거나 선택할 수 있는 옵션이 있습니다. HANA 데이터베이스의 고가용성 설정을 위해 표준 부하 분산 장치를 설정하려면 아래 단계를 따릅니다.
Azure Portal을 사용하여 고가용성 SAP 시스템용 표준 Load Balancer를 설정하려면 부하 분산 장치 만들기의 단계를 따릅니다. 부하 분산 장치를 설정하는 동안 다음 사항을 고려합니다.
- 프런트 엔드 IP 구성: 프런트 엔드 IP를 만듭니다. 데이터베이스 가상 머신과 동일한 가상 네트워크 및 서브넷 이름을 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 만들고 데이터베이스 VM을 추가합니다.
- 인바운드 규칙: 부하 분산 규칙을 만듭니다. 두 부하 분산 규칙 모두에 대해 동일한 단계를 수행합니다.
- 프런트 엔드 IP 주소: 프런트 엔드 IP를 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 선택합니다.
- 고가용성 포트: 이 옵션을 선택합니다.
- 프로토콜: TCP를 선택합니다.
- 상태 프로브: 다음 세부 정보를 사용하여 상태 프로브를 만듭니다.
- 프로토콜: TCP를 선택합니다.
- 포트: 예, 625<instance-no.>.
- 간격: 5를 입력합니다.
- 프로브 임계값: 2를 입력합니다.
- 유휴 시간 제한(분): 30을 입력합니다.
- 부동 IP 사용: 이 옵션을 선택합니다.
참고 항목
포털에서 비정상 임계값이라고도 알려진 상태 프로브 구성 속성 numberOfProbes는 준수되지 않습니다. 성공하거나 실패한 연속 프로브 수를 제어하려면 probeThreshold 속성을 2로 설정합니다. 현재 Azure Portal을 사용하여 이 속성을 설정할 수 없으므로 Azure CLI 또는 PowerShell 명령을 사용합니다.
SAP HANA에 필요한 포트에 대한 자세한 내용은 SAP HANA 테넌트 데이터베이스 가이드의 테넌트 데이터베이스에 연결 챕터 또는 SAP Note 2388694를 참조하세요.
참고 항목
공용 IP 주소가 없는 VM이 표준 Azure Load Balancer의 내부(공용 IP 주소 없음) 인스턴스의 백 엔드 풀에 배치되면 공용 엔드포인트로의 라우팅을 허용하도록 추가 구성이 수행되지 않는 한 아웃바운드 인터넷 연결이 이루어지지 않습니다. 아웃바운드 연결을 설정하는 방법에 대한 자세한 정보는 SAP 고가용성 시나리오에서 표준 Azure Load Balancer를 사용하는 가상 머신에 대한 공용 엔드포인트 연결을 참조하세요.
Important
Azure Load Balancer 뒤에 배치되는 Azure VM에서 TCP 타임스탬프를 사용하도록 설정하면 안 됩니다. TCP 타임스탬프를 사용하도록 설정하면 상태 프로브가 실패할 수 있습니다. 매개 변수 net.ipv4.tcp_timestamps를 0으로 설정합니다. 자세한 내용은 부하 분산 장치 상태 프로브 및 AP Note 2382421을 참조하세요.
Azure NetApp Files 볼륨 탑재
[A] HANA 데이터베이스 볼륨에 대한 탑재 지점을 만듭니다.
sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/shared[A] NFS 도메인 설정을 확인합니다. 도메인이 기본 Azure NetApp Files 도메인(예: defaultv4iddomain.com)으로 구성되어 있고 매핑이 nobody로 설정되어 있는지 확인합니다.
sudo cat /etc/idmapd.conf예제 출력:
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyImportant
VM의
/etc/idmapd.conf에서 NFS 도메인을 Azure NetApp Files의 기본 도메인 구성(defaultv4iddomain.com)과 일치하도록 설정합니다. NFS 클라이언트(즉, VM)의 도메인 구성과 NFS 서버(즉, Azure NetApp Files 구성)가 일치하지 않는 경우 VM에 탑재된 Azure NetApp Files 볼륨의 파일에 대한 사용 권한이nobody로 표시됩니다.[1] node1(hanadb1)에 노드별 볼륨 탑재
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-data-mnt00001 /hana/data[2] node2(hanadb2)에 노드별 볼륨 탑재
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-data-mnt00001 /hana/data[A] 모든 HANA 볼륨이 NFS 프로토콜 버전 NFSv4로 탑재되었는지 확인합니다.
sudo nfsstat -mvers플래그가 4.1로 설정되었는지 확인합니다. hanadb1의 예:/hana/log from 10.32.2.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/data from 10.32.2.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/shared from 10.32.2.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4[A] nfs4_disable_idmapping을 확인합니다. Y로 설정되어야 합니다. nfs4_disable_idmapping이 있는 디렉터리 구조를 만들려면 mount 명령을 실행합니다. 커널 및 드라이버에 대한 액세스가 예약되어 있으므로
/sys/modules아래에 디렉터리를 수동으로 만들 수 없습니다.nfs4_disable_idmapping를 확인합니다.sudo cat /sys/module/nfs/parameters/nfs4_disable_idmappingnfs4_disable_idmapping을 다음으로 설정해야 하는 경우:sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping구성을 영구적으로 만듭니다.
sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.conf매개 변수를 변경하는
nfs_disable_idmapping방법에 대한 자세한 내용은 Red Hat 기술 자료를 참조 하세요.
SAP HANA 설치
[A] 모든 호스트의 호스트 이름 확인을 설정합니다.
DNS 서버를 사용하거나 모든 노드의
/etc/hosts파일을 수정할 수 있습니다. 이 예제에서는/etc/hosts파일을 사용하는 방법을 보여줍니다. 다음 명령에서 IP 주소와 호스트 이름을 바꿉니다.sudo vi /etc/hosts다음 줄을
/etc/hosts파일에 삽입합니다. 사용자 환경에 맞게 IP 주소와 호스트 이름을 변경합니다.10.32.0.4 hanadb1 10.32.0.5 hanadb2[A] SAP Note 3024346 - NetApp NFS용 Linux 커널 설정에 설명된 대로 NFS를 사용하여 Azure NetApp에서 SAP HANA를 실행하기 위한 OS를 준비합니다. NetApp 구성 설정에 대한 구성 파일
/etc/sysctl.d/91-NetApp-HANA.conf를 만듭니다.sudo vi /etc/sysctl.d/91-NetApp-HANA.conf구성 파일에 다음 항목을 추가합니다.
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] 더 많은 최적화 설정을 사용하여 구성 파일
/etc/sysctl.d/ms-az.conf를 만듭니다.sudo vi /etc/sysctl.d/ms-az.conf구성 파일에 다음 항목을 추가합니다.
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10팁
SAP 호스트 에이전트가 포트 범위를 관리할 수 있도록
sysctl구성 파일에서net.ipv4.ip_local_port_range및net.ipv4.ip_local_reserved_ports를 명시적으로 설정하지 마세요. 자세한 내용은 SAP Note 2382421을 참조하세요.[A] SAP Note 3024346 - NetApp NFS용 Linux 커널 설정에 권장된 대로
sunrpc설정을 조정합니다.sudo vi /etc/modprobe.d/sunrpc.conf다음 줄을 삽입합니다.
options sunrpc tcp_max_slot_table_entries=128[A] HANA에 대한 RHEL OS 구성을 수행합니다.
RHEL 버전에 따라 다음 SAP Note에 설명된 대로 OS를 구성합니다.
[A] SAP HANA를 설치합니다.
HANA 2.0 SPS 01부터 MDC는 기본 옵션입니다. HANA 시스템을 설치하는 경우 SYSTEMDB와 동일한 SID를 가진 테넌트를 함께 만듭니다. 경우에 따라 기본 테넌트가 필요하지 않습니다. 설치와 함께 초기 테넌트를 만들고 싶지 않은 경우 SAP Note 2629711을 따를 수 있습니다.
HANA DVD에서 hdblcm 프로그램을 실행합니다. 프롬프트에서 다음 값을 입력합니다.
- 설치 선택: 1을 입력합니다(설치용).
- 설치를 위해 더 많은 구성 요소 선택: 1을 입력합니다.
- 설치 경로 입력 [/hana/shared]: 기본값을 적용하려면 Enter 키를 선택합니다.
- 로컬 호스트 이름 입력 [..]: 기본값을 적용하려면 Enter 키를 선택합니다. 시스템에 호스트를 추가할까요? (y/n) [n]: n.
- SAP HANA 시스템 ID 입력: HN1을 입력합니다.
- 인스턴스 번호 입력 [00]: 03을 입력합니다.
- 데이터베이스 모드/인덱스 입력 선택 [1]: 기본값을 적용하려면 Enter 키를 선택합니다.
- 시스템 사용량/인덱스 입력 선택 [4]: 4(사용자 지정)를 입력합니다.
- 데이터 볼륨의 위치 입력 [/hana/data]: 기본값을 적용하려면 Enter 키를 선택합니다.
- 로그 볼륨의 위치 입력 [/hana/log]: 기본값을 적용하려면 Enter 키를 선택합니다.
- 최대 메모리 할당 제한? [n]: 기본값을 적용하려면 Enter 키를 선택합니다.
- 호스트 '...'에 대한 인증서 호스트 이름 입력 [...]: 기본값을 적용하려면 Enter 키를 선택합니다.
- SAP 호스트 에이전트 사용자(sapadm) 암호 입력: 호스트 에이전트 사용자 암호를 입력합니다.
- SAP 호스트 에이전트 사용자(sapadm) 암호 확인: 호스트 에이전트 사용자 암호를 다시 입력하여 확인합니다.
- 시스템 관리자(hn1adm) 암호 입력: 시스템 관리자 암호를 입력합니다.
- 시스템 관리자(hn1adm) 암호 확인: 시스템 관리자 암호를 다시 입력하여 확인합니다.
- 시스템 관리자 홈 디렉터리 입력 [/usr/sap/HN1/home]: 기본값을 적용하려면 Enter 키를 선택합니다.
- 시스템 관리자 로그인 셸 입력 [/bin/sh]: 기본값을 적용하려면 Enter 키를 선택합니다.
- 시스템 관리자 사용자 ID 입력 [1001]: 기본값을 적용하려면 Enter 키를 선택합니다.
- 사용자 그룹(sapsys)의 ID 입력 [79]: 기본값을 적용하려면 Enter 키를 선택합니다.
- 데이터베이스 사용자(SYSTEM) 암호 입력: 데이터베이스 사용자 암호를 입력합니다.
- 데이터베이스 사용자(SYSTEM) 암호 확인: 데이터베이스 사용자 암호를 다시 입력하여 확인합니다.
- 컴퓨터를 다시 부팅한 다음 시스템 다시 시작? [n]: 기본값을 적용하려면 Enter 키를 선택합니다.
- 계속하시겠습니까? (y/n): 요약의 유효성을 검사합니다. 계속하려면 y를 입력합니다.
[A] SAP 호스트 에이전트를 업그레이드합니다.
SAP Software Center에서 최신 SAP 호스트 에이전트 아카이브를 다운로드하고 다음 명령을 실행하여 에이전트를 업그레이드합니다. 다운로드한 파일을 가리키도록 아카이브의 경로를 바꿉니다.
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>[A] 방화벽을 구성합니다.
Azure 부하 분산 장치 프로브 포트의 방화벽 규칙을 만듭니다.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp –permanent
SAP HANA 시스템 복제 구성
SAP HANA 시스템 복제 설정의 단계에 따라 SAP HANA 시스템 복제를 구성합니다.
클러스터 구성
이 섹션에서는 Azure NetApp Files를 사용하여 NFS 공유에 SAP HANA를 설치할 때 클러스터가 원활하게 작동하는 데 필요한 단계를 설명합니다.
Pacemaker 클러스터 만들기
Azure의 Red Hat Enterprise Linux에서 Pacemaker 설정 단계에 따라 이 HANA 서버용 기본 Pacemaker 클러스터를 만듭니다.
Important
시스템 기반 SAP Startup Framework를 사용하면 이제 systemd에서 SAP HANA 인스턴스를 관리할 수 있습니다. 필요한 최소 RHEL(Red Hat Enterprise Linux) 버전은 SAP용 RHEL 8입니다. SAP Note 3189534에서 설명한 대로 SAP HANA SPS07 수정 버전 70 이상을 새로 설치하거나 HANA 시스템을 HANA 2.0 SPS07 수정 버전 70 이상으로 업데이트하면 SAP 시작 프레임워크가 자동으로 systemd에 등록됩니다.
HA 솔루션을 사용하여 시스템 지원 SAP HANA 인스턴스(SAP Note 3189534참조)와 함께 SAP HANA 시스템 복제를 관리하는 경우 HA 클러스터가 systemd의 간섭 없이 SAP 인스턴스를 관리할 수 있도록 추가 단계가 필요합니다. 따라서 systemd와 통합된 SAP HANA 시스템의 경우 모든 클러스터 노드에서 Red Hat KBA 7029705에 설명된 추가 단계를 따라야 합니다.
Python 시스템 복제 후크 SAPHanaSR 구현
이 단계는 클러스터와의 통합을 최적화하고, 클러스터 장애 조치(failover)가 필요한 경우 검색 기능을 향상시키는 중요한 단계입니다. SAPHanaSR python 후크를 구성하는 것이 좋습니다. Python 시스템 복제 후크 SAPHanaSR 구현의 단계를 따릅니다.
파일 시스템 리소스 만들기
이 예제에서 각 클러스터 노드에는 고유한 HANA NFS 파일 시스템 /hana/shared, /hana/data, /hana/log가 있습니다.
[1] 클러스터를 유지 관리 모드로 설정합니다.
sudo pcs property set maintenance-mode=true[1] hanadb1 탑재를 위한 파일 시스템 리소스를 만듭니다.
sudo pcs resource create hana_data1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_log1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_shared1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs[2] hanadb2 탑재를 위한 파일 시스템 리소스를 만듭니다.
sudo pcs resource create hana_data2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_log2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_shared2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfsOCF_CHECK_LEVEL=20특성이 모니터 작업에 추가되어 각 모니터가 파일 시스템에서 읽기/쓰기 테스트를 수행합니다. 이 특성이 없으면 모니터 작업은 파일 시스템이 탑재되어 있는지만 확인합니다. 이는 연결이 끊어질 때 파일 시스템에 액세스할 수 없는 경우에도 탑재된 상태를 유지할 수 있기 때문에 문제가 될 수 있습니다.on-fail=fence특성도 모니터 작업에 추가됩니다. 이 옵션을 사용하면 노드에서 모니터 작업이 실패하는 경우 해당 노드가 즉시 펜싱됩니다. 이 옵션이 없으면 기본 동작으로 실패한 리소스에 종속된 모든 리소스를 중지하고, 실패한 리소스를 다시 시작한 다음, 실패한 리소스에 종속된 모든 리소스를 시작합니다.이 동작은 SAPHana 리소스가 실패한 리소스에 의존하는 경우 시간이 오래 걸릴 뿐만 아니라 완전히 실패할 수도 있습니다. HANA 실행 파일이 있는 NFS 서버에 액세스할 수 없는 경우 SAPHana 리소스를 중지할 수 없습니다.
제안된 시간 제한 값을 사용하면 클러스터 리소스가 NFSv4.1 임대 갱신과 관련된 프로토콜별 일시 중지를 견딜 수 있습니다. 자세한 내용은 NetApp의 NFS 모범 사례를 참조하세요. 위의 구성에서 시간 제한은 특정 SAP 설정에 맞게 조정해야 할 수 있습니다.
더 높은 처리량이 필요한 워크로드의 경우 SAP HANA용 Azure NetApp Files의 NFS v4.1 볼륨에 설명된 대로
nconnect탑재 옵션을 사용하는 것이 좋습니다.nconnect를 Linux 릴리스에서 Azure NetApp Files가 지원하는지 확인합니다.[1] 위치 제약 조건을 구성합니다.
Hanadb1 고유 탑재를 관리하는 리소스가 hanadb2에서 실행될 수 없도록 위치 제약 조건을 구성하고 그 반대의 경우도 마찬가지입니다.
sudo pcs constraint location hanadb1_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb2 sudo pcs constraint location hanadb2_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb1resource-discovery=never옵션은 각 노드의 고유 탑재가 동일한 탑재 지점을 공유하기 때문에 설정됩니다. 예를 들어,hana_data1은 탑재 지점/hana/data를 사용하고hana_data2도 탑재 지점/hana/data를 사용합니다. 동일한 탑재 지점 공유로 인해 클러스터 시작 시 리소스 상태가 확인될 때 프로브 작업에 대해 가양성이 발생할 수 있으며, 불필요한 복구 동작이 발생할 수 있습니다. 이 시나리오를 방지하려면resource-discovery=never를 설정합니다.[1] 특성 리소스를 구성합니다.
특성 리소스를 구성합니다. 이러한 특성은 노드의 모든 NFS 탑재(
/hana/data,/hana/log,/hana/data)가 탑재된 경우 true로 설정됩니다. 그렇지 않으면 false로 설정됩니다.sudo pcs resource create hana_nfs1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs1_active sudo pcs resource create hana_nfs2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs2_active[1] 위치 제약 조건을 구성합니다.
Hanadb1의 특성 리소스가 hanadb2에서 실행되지 않도록 하는 위치 제약 조건을 구성하고 그 반대의 경우도 마찬가지입니다.
sudo pcs constraint location hana_nfs1_active avoids hanadb2 sudo pcs constraint location hana_nfs2_active avoids hanadb1[1] 주문 제약 조건을 만듭니다.
노드의 모든 NFS 탑재를 탑재한 후에 노드의 특성 리소스가 시작되도록 정렬 제약 조건을 구성합니다.
sudo pcs constraint order hanadb1_nfs then hana_nfs1_active sudo pcs constraint order hanadb2_nfs then hana_nfs2_active팁
구성에
hanadb1_nfs또는hanadb2_nfs그룹 외부의 파일 시스템이 포함된 경우 파일 시스템 간에 순서 종속성이 없도록sequential=false옵션을 포함합니다. 모든 파일 시스템은hana_nfs1_active전에 시작해야 하지만 서로 상대적인 순서로 시작할 필요는 없습니다. 자세한 내용은 HANA 파일 시스템이 NFS 공유에 있을 때 Pacemaker 클러스터의 스케일 업에서 SAP HANA 시스템 복제를 구성하는 방법을 참조하세요.
SAP HANA 클러스터 리소스 구성
SAP HANA 클러스터 리소스 만들기의 단계에 따라 클러스터에 SAP HANA 리소스를 만듭니다. SAP HANA 리소스가 만들어지면 SAP HANA 리소스와 파일 시스템(NFS 탑재) 간에 위치 규칙 제약 조건을 만들어야 합니다.
[1] SAP HANA 리소스와 NFS 탑재 간에 제약 조건을 구성합니다.
모든 노드의 NFS 탑재를 탑재한 경우에만 노드에서 SAP HANA 리소스를 실행할 수 있도록 위치 규칙 제약 조건을 설정합니다.
sudo pcs constraint location SAPHanaTopology_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueRHEL 7.x에서:
sudo pcs constraint location SAPHana_HN1_03-master rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueRHEL 8.x/9.x에서:
sudo pcs constraint location SAPHana_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne true[1] 노드의 SAP 리소스가 NFS 탑재를 중지하기 전에 중지되도록 순서 지정 제약 조건을 구성합니다.
pcs constraint order stop SAPHanaTopology_HN1_03-clone then stop hanadb1_nfs pcs constraint order stop SAPHanaTopology_HN1_03-clone then stop hanadb2_nfsRHEL 7.x에서:
pcs constraint order stop SAPHana_HN1_03-master then stop hanadb1_nfs pcs constraint order stop SAPHana_HN1_03-master then stop hanadb2_nfsRHEL 8.x/9.x에서:
pcs constraint order stop SAPHana_HN1_03-clone then stop hanadb1_nfs pcs constraint order stop SAPHana_HN1_03-clone then stop hanadb2_nfs클러스터의 유지 관리 모드를 해제합니다.
sudo pcs property set maintenance-mode=false클러스터 및 모든 리소스의 상태를 확인합니다.
참고 항목
이 문서에는 Microsoft에서 더 이상 사용하지 않는 용어에 대한 참조가 포함되어 있습니다. 소프트웨어에서 용어가 제거되면 이 문서에서 해당 용어가 제거됩니다.
sudo pcs status예제 출력:
Online: [ hanadb1 hanadb2 ] Full list of resources: rsc_hdb_azr_agt(stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem):Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1
Pacemaker 클러스터에서 HANA 활성/읽기 사용 시스템 복제 구성
SAP HANA 2.0 SPS 01부터 SAP는 SAP HANA 시스템 복제를 위한 활성/읽기 사용 설정을 허용합니다. 여기서 SAP HANA 시스템 복제의 보조 시스템은 읽기 집약적인 워크로드에 적극적으로 사용할 수 있습니다. 클러스터에서 이러한 설정을 지원하려면 클라이언트가 보조 읽기 사용 SAP HANA 데이터베이스에 액세스할 수 있도록 두 번째 가상 IP 주소가 필요합니다.
인수가 발생한 후에도 보조 복제 사이트에 액세스할 수 있도록 클러스터에서 가상 IP 주소를 SAPHana 리소스의 보조로 이동해야 합니다.
두 번째 가상 IP를 사용하는 Red Hat HA 클러스터에서 HANA 활성/읽기 사용 시스템 복제를 관리하는 데 필요한 추가 구성은 Pacemaker 클러스터에서 Hana 활성/읽기 사용 시스템 복제 구성에 설명되어 있습니다.
계속 진행하기 전에 설명서의 이전 섹션에 설명된 대로 SAP HANA 데이터베이스를 관리하는 Red Hat 고가용성 클러스터를 완전히 구성했는지 확인합니다.
클러스터 설정 테스트
이 섹션에서는 설정을 테스트하는 방법을 설명합니다.
테스트를 시작하기 전에 Pacemaker에 실패한 작업이 없으며(pcs 상태를 통해), 예기치 않은 위치 제약 조건이 없고(예: 마이그레이션 테스트의 결과),
systemReplicationStatus의 경우처럼 해당 HANA 시스템 복제가 동기화 상태에 있는지 확인합니다.sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"노드가 NFS 공유(
/hana/shared)에 대한 액세스 권한을 상실하면 장애 시나리오에 대한 클러스터 구성을 확인합니다.SAP HANA 리소스 에이전트에서
/hana/shared에 저장된 이진 파일을 사용하여 장애 조치(failover) 동안 작업을 수행합니다. 제공된 시나리오에서는/hana/shared파일 시스템이 NFS를 통해 탑재됩니다.서버 중 하나가 NFS 공유에 대한 액세스 권한을 상실하는 오류를 시뮬레이션하는 것은 어렵습니다. 테스트로 파일 시스템을 읽기 전용으로 다시 탑재할 수 있습니다. 이 접근 방식은 활성 노드에서
/hana/shared에 대한 액세스가 손실된 경우 클러스터가 장애 조치(failover)를 수행할 수 있는지 확인합니다.예상 결과:
/hana/shared를 읽기 전용 파일 시스템으로 만들 때 파일 시스템에서 읽기/쓰기 작업을 수행하는 리소스hana_shared1의OCF_CHECK_LEVEL특성이 실패합니다. 파일 시스템에 아무것도 쓸 수 없으며 HANA 리소스 장애 조치(failover)를 수행합니다. HANA 노드가 NFS 공유에 액세스할 수 없는 경우에도 동일한 결과가 예상됩니다.테스트 시작 전 리소스 상태:
sudo pcs status예제 출력:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem): Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1다음 명령을 사용하여 활성 클러스터 노드에서 읽기 전용 모드에
/hana/shared를 배치할 수 있습니다.sudo mount -o ro 10.32.2.4:/hanadb1-shared-mnt00001 /hana/sharedhanadb가stonith(pcs property show stonith-action) 작업 세트에 따라 다시 부팅되거나 전원이 꺼집니다. 서버(hanadb1)가 다운되면 HANA 리소스가hanadb2로 이동합니다.hanadb2에서 클러스터의 상태를 확인할 수 있습니다.sudo pcs status예제 출력:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb2 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Stopped hana_log1 (ocf::heartbeat:Filesystem): Stopped hana_shared1 (ocf::heartbeat:Filesystem): Stopped Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Stopped hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb2 ] Stopped: [ hanadb1 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb2 ] Stopped: [ hanadb1 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb2 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb2또한 RHEL용 SAP HANA 시스템 복제 설정에 설명된 테스트를 수행하여 SAP HANA 클러스터 구성을 철저히 테스트하는 것이 좋습니다.