Azure AI 기능을 Azure Database for PostgreSQL - 유연한 서버에 통합
적용 대상:  Azure Database for PostgreSQL - 유연한 서버
Azure Database for PostgreSQL - 유연한 서버
azure_ai 확장은 Azure AI 서비스의 기능을 통합하여 LLM(대규모 언어 모델)을 사용하고 Azure Database for PostgreSQL 유연한 서버 데이터베이스 내에서 생성형 AI 애플리케이션을 빌드하는 기능을 추가합니다. 생성형 AI는 자연어 입력을 기반으로 하여 독창적인 콘텐츠를 생성하도록 LLM이 학습되는 인공 지능의 한 형태입니다. azure_ai 확장을 사용하면 데이터베이스에서 생성형 AI의 자연어 쿼리 처리 기능을 직접 사용할 수 있습니다.
이 자습서에서는 azure_ai 확장을 사용하여 풍부한 AI 기능을 Azure Database for PostgreSQL 유연한 서버 인스턴스에 추가하는 방법을 보여줍니다. 확장을 사용하여 Azure OpenAI와 Azure AI 언어 서비스를 데이터베이스에 통합하는 방법을 설명합니다.
필수 조건
Azure 구독 – 체험 구독을 만듭니다.
원하는 Azure 구독의 Azure OpenAI에 대한 액세스 권한. 현재 이 서비스에 대한 액세스 권한은 애플리케이션에서 부여합니다. https://aka.ms/oai/access에서 양식을 작성하여 Azure OpenAI에 대한 액세스를 신청할 수 있습니다.
text-embedding-ada-002(버전 2) 모델이 배포된 Azure OpenAI 리소스. 이 모델은 현재 특정 지역에서만 사용할 수 있습니다. 이 리소스가 없는 경우 리소스 만들기 프로세스는 Azure OpenAI 리소스 배포 가이드에서 설명하고 있습니다.Azure AI 언어 서비스. 이 리소스가 없는 경우 요약 빠른 시작 문서의 지침에 따라 Azure Portal에서 언어 리소스를 만들 수 있습니다. 무료 가격 책정 계층(
Free F0)을 사용하여 서비스를 사용해 보고 나중에 프로덕션에 대한 유료 계층으로 업그레이드할 수 있습니다.Azure 구독의 Azure Database for PostgreSQL 유연한 서버 인스턴스. 이 리소스가 없는 경우 Azure Portal 또는 Azure CLI 가이드를 사용하여 새로 만듭니다.
Azure Cloud Shell에서 psql을 사용하여 데이터베이스에 연결
웹 브라우저에서 Azure Cloud Shell을 엽니다. 환경으로 Bash를 선택하고, 메시지가 표시되면 Azure Database for PostgreSQL 유연한 서버 데이터베이스에 사용한 구독을 선택한 다음, 스토리지 만들기를 선택합니다.
데이터베이스 연결 세부 정보를 검색하려면 다음을 수행합니다.
Azure Portal에서 Azure Database for PostgreSQL 유연한 서버 리소스로 이동합니다.
왼쪽 탐색 메뉴의 설정 아래에서 연결을 선택하고, 연결 세부 정보 블록을 복사합니다.
복사한 환경 변수 선언 줄을 위에서 연 Azure Cloud Shell 터미널에 붙여넣고,
{your-password}토큰을 데이터베이스를 만들 때 설정한 암호로 바꿉니다.export PGHOST={your-server-name}.postgresql.database.azure.com export PGUSER={your-user-name} export PGPORT=5432 export PGDATABASE={your-database-name} export PGPASSWORD="{your-password}"프롬프트에서 다음을 입력하여 psql 명령줄 유틸리티를 통해 데이터베이스에 연결합니다.
psql
azure_ai 확장 설치
azure_ai 확장을 사용하면 Azure OpenAI 및 Azure Cognitive Services를 데이터베이스에 통합할 수 있습니다. 데이터베이스에서 확장을 사용하도록 설정하려면 다음 단계를 수행합니다.
확장 - Azure Database for PostgreSQL - 유연한 서버에서 설명한 대로 확장을 허용 목록에 추가합니다.
psql명령 프롬프트에서 다음을 실행하여 확장이 허용 목록에 성공적으로 추가되었는지 확인합니다.SHOW azure.extensions;azure_ai확장을 사용하려는 데이터베이스에서 CREATE EXTENSION 명령을 사용하여 해당 확장을 설치합니다.CREATE EXTENSION azure_ai;
azure_ai 확장 내에 포함된 개체 검사
azure_ai 확장에 포함된 개체를 검토하면 확장에서 제공하는 기능을 더 잘 이해할 수 있습니다. psql 명령 프롬프트에서 \dx 메타 명령을 사용하여 확장에 포함된 개체를 나열할 수 있습니다.
\dx+ azure_ai
메타 명령 출력에서는 azure_ai 확장에서 세 개의 스키마, 여러 UDF(사용자 정의 함수) 및 여러 복합 형식을 데이터베이스에 만든다는 것을 보여줍니다. 아래 표에서는 확장에서 추가된 스키마를 나열하고 각각에 대해 설명합니다.
| 스키마 | 설명 |
|---|---|
azure_ai |
구성 테이블과 상호 작용을 위한 UDF가 있는 주 스키마입니다. |
azure_openai |
Azure OpenAI 엔드포인트를 호출할 수 있는 UDF가 포함됩니다. |
azure_cognitive |
데이터베이스를 Azure Cognitive Services와 통합하는 데 관련된 UDF 및 복합 형식을 제공합니다. |
함수와 형식은 모두 스키마 중 하나와 연결됩니다. azure_ai 스키마에 정의된 함수를 검토하려면 \df 메타 명령을 사용하여 함수를 표시해야 하는 스키마를 지정합니다. \df 명령 앞의 \x auto 명령은 확장된 디스플레이를 자동으로 설정/해제하여 Azure Cloud Shell에서 명령 출력을 더 쉽게 볼 수 있도록 합니다.
\x auto
\df+ azure_ai.*
azure_ai.set_setting() 함수를 사용하면 Azure AI 서비스에 대한 엔드포인트와 중요한 값을 설정할 수 있습니다. 키와 값을 사용하여 할당합니다. azure_ai.get_setting() 함수는 set_setting() 함수로 설정한 값을 검색하는 방법을 제공합니다. 보려는 설정의 키를 허용합니다. 두 방법 모두에서 키는 다음 중 하나여야 합니다.
| 키 | 설명 |
|---|---|
azure_openai.endpoint |
지원되는 OpenAI 엔드포인트(예: https://example.openai.azure.com) |
azure_openai.subscription_key |
OpenAI 리소스에 대한 구독 키 |
azure_cognitive.endpoint |
지원되는 Cognitive Services 엔드포인트(예: https://example.cognitiveservices.azure.com) |
azure_cognitive.subscription_key |
Cognitive Services 리소스에 대한 구독 키 |
Important
API 키를 포함한 Azure AI 서비스에 대한 연결 정보는 데이터베이스의 구성 테이블에 저장되므로 이 정보가 보호되고 해당 역할이 할당된 사용자만 액세스할 수 있도록 azure_ai 확장은 azure_ai_settings_manager라는 역할을 정의합니다. 이 역할을 통해 확장과 관련된 설정을 읽고 쓸 수 있습니다. azure_ai_settings_manager 역할의 슈퍼 사용자와 멤버만 azure_ai.get_setting() 및 azure_ai.set_setting() 함수를 호출할 수 있습니다. Azure Database for PostgreSQL 유연한 서버에서는 모든 관리 사용자에게 azure_ai_settings_manager 역할이 할당됩니다.
Azure OpenAI를 사용하여 벡터 포함 생성
azure_ai 확장의 azure_openai 스키마를 사용하면 Azure OpenAI를 사용하여 텍스트 값에 대한 벡터 포함을 만들 수 있습니다. 이 스키마를 사용하면 데이터베이스에서 직접 Azure OpenAI를 통해 포함을 생성하여 입력 텍스트의 벡터 표현을 만들 수 있습니다. 그런 다음, 벡터 유사성 검색에 사용하고 기계 학습 모델에서 사용할 수 있습니다.
포함은 기계 학습 모델을 사용하여 관련 정보에 대한 밀접한 관련성을 평가하는 기술입니다. 이 기술을 사용하면 데이터 간의 관계와 유사성을 효율적으로 식별할 수 있으므로 알고리즘에서 패턴을 식별하고 정확하게 예측할 수 있습니다.
Azure OpenAI 엔드포인트 및 키 설정
azure_openai 함수를 사용하기 전에 다음을 수행합니다.
Azure OpenAI Service 엔드포인트 및 키를 사용하여 확장을 구성합니다.
Azure Portal에서 Azure OpenAI 리소스로 이동하고, 왼쪽 메뉴의 리소스 관리 아래에서 키 및 엔드포인트 항목을 선택합니다.
엔드포인트와 액세스 키를 복사합니다.
KEY1또는KEY2를 사용할 수 있습니다. 항상 두 개의 키를 사용하면 서비스 중단 없이 키를 안전하게 회전하고 다시 생성할 수 있습니다.
아래 명령에서 {endpoint} 및 {api-key} 토큰을 Azure Portal에서 검색한 값으로 바꾼 다음, psql 명령 프롬프트에서 명령을 실행하여 값을 구성 테이블에 추가합니다.
SELECT azure_ai.set_setting('azure_openai.endpoint','{endpoint}');
SELECT azure_ai.set_setting('azure_openai.subscription_key', '{api-key}');
구성 테이블에 기록된 설정을 확인합니다.
SELECT azure_ai.get_setting('azure_openai.endpoint');
SELECT azure_ai.get_setting('azure_openai.subscription_key');
이제 azure_ai 확장이 Azure OpenAI 계정에 연결되고 벡터 포함을 생성할 준비가 되었습니다.
샘플 데이터를 이용해 데이터베이스 작성
이 자습서에서는 미국 의회 및 캘리포니아 주 법안 목록을 제공하는 BillSum 데이터 세트의 작은 하위 집합을 사용하여 벡터 생성을 위한 샘플 텍스트 데이터를 제공합니다. 이러한 데이터가 포함된 bill_sum_data.csv 파일은 Azure 샘플 GitHub 리포지토리에서 다운로드할 수 있습니다.
데이터베이스에서 샘플 데이터를 호스트하려면 bill_summaries라는 테이블을 만듭니다.
CREATE TABLE bill_summaries
(
id bigint PRIMARY KEY,
bill_id text,
bill_text text,
summary text,
title text,
text_len bigint,
sum_len bigint
);
psql 명령 프롬프트에서 PostgreSQL COPY 명령을 사용하여 CSV의 샘플 데이터를 bill_summaries 테이블에 로드하고 CSV 파일의 첫 번째 행을 머리글 행으로 지정합니다.
\COPY bill_summaries (id, bill_id, bill_text, summary, title, text_len, sum_len) FROM PROGRAM 'curl "https://raw.githubusercontent.com/Azure-Samples/Azure-OpenAI-Docs-Samples/main/Samples/Tutorials/Embeddings/data/bill_sum_data.csv"' WITH CSV HEADER ENCODING 'UTF8'
벡터 지원 사용
azure_ai 확장을 사용하면 입력 텍스트에 대한 포함을 생성할 수 있습니다. 생성된 벡터를 데이터베이스의 나머지 데이터와 함께 저장할 수 있도록 하려면 데이터베이스에서 벡터 지원 사용 설명서의 지침에 따라 pgvector 확장을 설치해야 합니다.
지원되는 벡터가 데이터베이스에 추가되면 vector 데이터 형식을 사용하여 새 열을 bill_summaries 테이블에 추가하여 포함을 테이블 내에 저장합니다. text-embedding-ada-002 모델은 1,536개 차원의 벡터를 생성하므로 1536을 벡터 크기로 지정해야 합니다.
ALTER TABLE bill_summaries
ADD COLUMN bill_vector vector(1536);
벡터 생성 및 저장
이제 bill_summaries 테이블이 포함을 저장할 준비가 되었습니다. azure_openai.create_embeddings() 함수를 사용하여 bill_text 필드에 대한 벡터를 만들고 이러한 벡터를 bill_summaries 테이블의 새로 만든 bill_vector 열에 삽입합니다.
create_embeddings() 함수를 사용하기 전에 다음 명령을 실행하여 해당 함수를 검사하고 필요한 인수를 검토합니다.
\df+ azure_openai.*
\df+ azure_openai.* 명령 출력의 Argument data types 속성은 함수에 필요한 인수 목록을 표시합니다.
| 인수 | Type | 기본값 | 설명 |
|---|---|---|---|
| deployment_name | text |
text-embeddings-ada-002 모델이 포함된 Azure OpenAI Studio의 배포 이름입니다. |
|
| input | text |
포함을 만드는 데 사용되는 입력 텍스트입니다. | |
| timeout_ms | integer |
3600000 | 작업이 중지된 후의 시간 제한(밀리초)입니다. |
| throw_on_error | boolean |
true | 오류 발생 시 함수에서 예외를 throw하여 래핑 트랜잭션을 롤백해야 하는지 여부를 나타내는 플래그입니다. |
첫 번째 인수는 포함 모델이 Azure OpenAI 계정에 배포될 때 할당된 deployment_name입니다. 이 값을 검색하려면 Azure Portal에서 Azure OpenAI 리소스로 이동합니다. 이 리소스에 있는 왼쪽 탐색 메뉴의 리소스 관리 아래에서 모델 배포 항목을 선택하여 Azure OpenAI Studio를 엽니다. Azure OpenAI Studio의 배포 탭에서 text-embedding-ada-002 모델 배포와 연결된 배포 이름 값을 복사합니다.
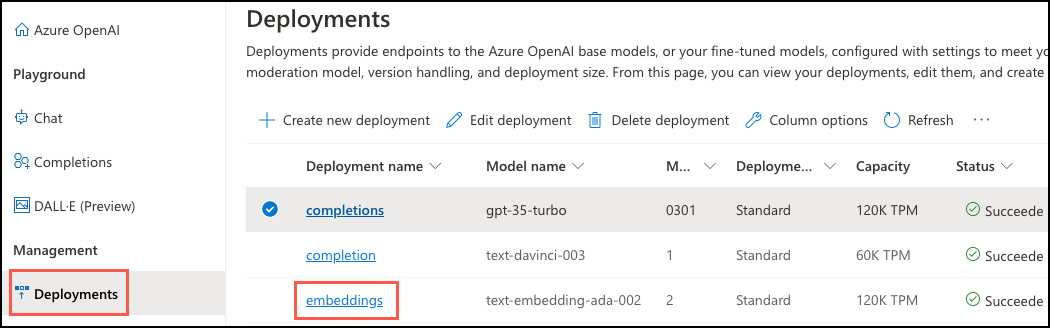
이 정보를 사용하여 bill_summaries 테이블의 각 레코드를 업데이트하는 쿼리를 실행하고, azure_openai.create_embeddings() 함수를 사용하여 bill_text 필드에 대해 생성된 벡터 포함을 bill_vector 열에 삽입합니다. {your-deployment-name}을 Azure OpenAI Studio 배포 탭에서 복사한 배포 이름 값으로 바꾸고, 다음 명령을 실행합니다.
UPDATE bill_summaries b
SET bill_vector = azure_openai.create_embeddings('{your-deployment-name}', b.bill_text);
다음 쿼리를 실행하여 테이블의 첫 번째 레코드에 대해 생성된 포함을 봅니다. 출력을 쉽게 읽을 수 없는 경우 먼저 \x를 실행할 수 있습니다.
SELECT bill_vector FROM bill_summaries LIMIT 1;
각 포함은 부동 소수점 숫자의 벡터입니다. 따라서 벡터 공간의 두 포함 사이의 거리는 원래 형식의 두 입력 간의 의미 체계 유사성과 상관 관계가 있습니다.
벡터 유사성 검색 수행
벡터 유사성은 일련의 숫자인 벡터로 표시하여 두 항목이 얼마나 비슷한지 측정하는 데 사용되는 메서드입니다. 벡터는 LLM을 사용하여 검색을 수행하는 데 사용되는 경우가 많습니다. 벡터 유사성은 일반적으로 유클리드 거리 또는 코사인 유사성과 같은 거리 메트릭을 사용하여 계산됩니다. 유클리드 거리는 n차원 공간에서 두 벡터 간의 직선 거리를 측정하는 반면, 코사인 유사성은 두 벡터 사이의 각도의 코사인을 측정합니다.
코사인 거리와 HNSW(Hierarchical Navigable Small World의 약어)를 사용하여 인덱스를 bill_summaries에 만들면 vector 필드를 더 효율적으로 검색할 수 있습니다. HNSW를 사용하면 pgvector에서 최신 그래프 기반 알고리즘을 사용하여 가장 인접한 항목 쿼리를 근사화할 수 있습니다.
CREATE INDEX ON bill_summaries USING hnsw (bill_vector vector_cosine_ops);
이제 모든 항목이 준비되었으므로 데이터베이스에 대해 코사인 유사성 검색 쿼리를 실행할 준비가 되었습니다.
아래 쿼리에서는 입력 질문에 대한 포함이 생성된 다음, bill_summaries 테이블에 저장된 벡터와 비교할 수 있는 벡터 배열(::vector)로 캐스팅됩니다.
SELECT bill_id, title FROM bill_summaries
ORDER BY bill_vector <=> azure_openai.create_embeddings('embeddings', 'Show me bills relating to veterans entrepreneurship.')::vector
LIMIT 3;
쿼리는 다차원 공간에서 두 벡터 사이의 거리를 계산하는 데 사용되는 "코사인 거리" 연산자를 나타내는 벡터 연산자를 사용합니다.<=>
Azure Cognitive Services 통합
azure_ai 확장의 azure_cognitive 스키마에 포함된 Azure AI 서비스 통합은 데이터베이스에서 직접 액세스할 수 있는 다양한 AI 언어 기능 세트를 제공합니다. 이러한 기능에는 감정 분석, 언어 감지, 핵심 구 추출, 엔터티 인식 및 텍스트 요약이 포함됩니다. 이러한 기능에 대한 액세스는 Azure AI 언어 서비스를 통해 사용하도록 설정됩니다.
확장을 통해 액세스할 수 있는 전체 Azure AI 기능을 검토하려면 Azure Cognitive Services와 Azure Database for PostgreSQL - 유연한 서버 통합을 참조하세요.
Azure AI 언어 서비스 엔드포인트 및 키 설정
azure_openai 함수와 마찬가지로 azure_ai 확장을 사용하여 Azure AI 서비스에 대한 호출을 성공적으로 수행하려면 Azure AI 언어 서비스에 대한 엔드포인트와 키를 제공해야 합니다. Azure Portal에 있는 왼쪽 메뉴의 리소스 관리 아래에서 언어 서비스 리소스로 이동하여 이러한 값을 검색하고, 키 및 엔드포인트 항목을 선택합니다. 엔드포인트와 액세스 키를 복사합니다. KEY1 또는 KEY2를 사용할 수 있습니다.
아래 명령에서 {endpoint} 및 {api-key} 토큰을 Azure Portal에서 검색한 값으로 바꾼 다음, psql 명령 프롬프트에서 명령을 실행하여 값을 구성 테이블에 추가합니다.
SELECT azure_ai.set_setting('azure_cognitive.endpoint','{endpoint}');
SELECT azure_ai.set_setting('azure_cognitive.subscription_key', '{api-key}');
청구서 요약
azure_ai 확장의 azure_cognitive 기능 중 일부를 보여주려면 각 청구서에 대한 요약을 생성합니다. azure_cognitive 스키마는 텍스트 요약을 수행하는 두 가지 함수인 summarize_abstractive 및 summarize_extractive를 제공합니다. 추상 요약은 입력 텍스트에서 주요 개념을 캡처하지만 동일한 단어를 사용하지 않을 수 있는 요약을 생성합니다. 추출 요약은 입력 텍스트에서 중요한 문장을 추출하여 요약을 어셈블합니다.
Azure AI 언어 서비스의 기능을 사용하여 새 원본 콘텐츠를 생성하려면 summarize_abstractive 함수를 사용하여 텍스트 입력 요약을 만듭니다. 이번에는 psql의 \df 메타 명령을 다시 사용하여 azure_cognitive.summarize_abstractive 함수를 구체적으로 살펴보세요.
\df azure_cognitive.summarize_abstractive
\df azure_cognitive.summarize_abstractive 명령 출력의 Argument data types 속성은 함수에 필요한 인수 목록을 표시합니다.
| 인수 | Type | 기본값 | 설명 |
|---|---|---|---|
| text | text |
요약할 입력 텍스트입니다. | |
| 언어 | text |
입력 텍스트가 작성된 언어에 대한 두 글자 ISO 639-1 표현입니다. 허용되는 값은 언어 지원을 확인하세요. | |
| timeout_ms | integer |
3600000 | 작업이 중지된 후의 시간 제한(밀리초)입니다. |
| throw_on_error | boolean |
true | 오류 발생 시 함수에서 예외를 throw하여 래핑 트랜잭션을 롤백해야 하는지 여부를 나타내는 플래그입니다. |
| sentence_count | integer |
3 | 생성되는 요약에 포함할 최대 문장 수입니다. |
| disable_service_logs | boolean |
false | 언어 서비스는 문제 해결을 위해 입력 텍스트를 48시간 동안 기록합니다. 이 속성을 true로 설정하면 입력 로깅이 사용하지 않도록 설정되고 발생하는 문제를 조사하는 기능이 제한될 수 있습니다. 자세한 내용은 https://aka.ms/cs-compliance의 Cognitive Services 규정 준수 및 개인 정보 보호 참고 사항 및 https://www.microsoft.com/ai/responsible-ai의 Microsoft 책임 있는 AI 원칙을 참조하세요. |
summarize_abstractive 함수에는 azure_cognitive.summarize_abstractive(text TEXT, language TEXT) 인수가 필요합니다.
bill_summaries 테이블에 대한 다음 쿼리는 summarize_abstractive 함수를 사용하여 청구서 텍스트에 대한 새로운 한 문장 요약을 생성하므로 생성형 AI의 기능을 쿼리에 직접 통합할 수 있습니다.
SELECT
bill_id,
azure_cognitive.summarize_abstractive(bill_text, 'en', sentence_count => 1) one_sentence_summary
FROM bill_summaries
WHERE bill_id = '112_hr2873';
이 함수를 사용하여 데이터를 데이터베이스 테이블에 쓸 수도 있습니다. 한 문장 요약을 데이터베이스에 저장하기 위한 새 열을 추가하도록 bill_summaries 테이블을 수정합니다.
ALTER TABLE bill_summaries
ADD COLUMN one_sentence_summary TEXT;
다음으로 테이블을 요약으로 업데이트합니다. summarize_abstractive 함수는 텍스트 배열(text[])을 반환합니다. array_to_string 함수는 반환 값을 문자열 표현으로 변환합니다. 아래 쿼리에서 throw_on_error 인수는 false로 설정되었습니다. 이 설정을 사용하면 오류가 발생하더라도 요약 프로세스를 계속할 수 있습니다.
UPDATE bill_summaries b
SET one_sentence_summary = array_to_string(azure_cognitive.summarize_abstractive(b.bill_text, 'en', throw_on_error => false, sentence_count => 1), ' ', '')
where one_sentence_summary is NULL;
출력에서 적절한 요약을 생성할 수 없는 잘못된 문서에 대한 경고를 확인할 수 있습니다. 이 경고는 위 쿼리에서 throw_on_error를 false로 설정하여 발생합니다. 해당 플래그를 기본값인 true로 두면 쿼리가 실패하고 요약이 데이터베이스에 기록되지 않습니다. 경고를 throwgks 레코드를 보려면 다음을 실행합니다.
SELECT bill_id, one_sentence_summary FROM bill_summaries WHERE one_sentence_summary is NULL;
그러면 bill_summaries 테이블을 쿼리하여 테이블의 다른 레코드에 대해 azure_ai 확장에서 생성된 새로운 한 문장 요약을 볼 수 있습니다.
SELECT bill_id, one_sentence_summary FROM bill_summaries LIMIT 5;
결론
축하합니다. azure_ai 확장을 사용하여 대규모 언어 모델과 생성형 AI 기능을 데이터베이스에 통합하는 방법을 알아보았습니다.