Azure Open Datasets에서 Azure Machine Learning 데이터 세트 만들기
이 문서에서는 Azure Machine Learning 데이터 세트 및 Azure Open Datasets를 사용하여 큐레이팅된 보강 데이터를 로컬 또는 원격 기계 학습 실험으로 가져오는 방법에 관해 알아봅니다.
Azure Machine Learning 데이터 세트를 사용하면 데이터 원본 위치에 대한 참조와 해당 메타데이터의 복사본을 만들 수 있습니다. 데이터 세트는 느리게 평가되고 데이터는 기존 위치에 남아 있으므로
- 원래 데이터 원본이 의도치 않게 변경될 위험을 감수하지 마세요.
- 추가 스토리지 비용이 발생하지 않습니다.
- ML 워크플로 성능 속도를 향상하세요.
데이터 세트가 Azure Machine Learning 데이터 액세스 워크플로 전반에서 어떤 역할을 하는지에 대한 자세한 내용은 안전하게 데이터에 액세스 문서를 참조하세요.
Azure Open Datasets는 예측 솔루션을 보강하고 솔루션의 정확도를 개선하기 위해 시나리오별 기능을 추가한 큐레이션된 공용 데이터 세트입니다. 기계 학습 모델을 학습하는 데 도움이 되는 공용 도메인 데이터에 대한 Open Datasets 카탈로그 리소스를 참조하세요. 예:
Open Datasets는 Microsoft Azure의 클라우드에 호스트됩니다. Azure Machine Learning Python SDK와 Azure Machine Learning 스튜디오에 모두 포함되어 있습니다.
필수 조건
다음 작업을 수행해야 합니다.
Azure 구독 구독이 없으면 시작하기 전에 계정을 만드세요. Azure Machine Learning 평가판 또는 유료 버전을 사용해 보세요.
azureml-datasets패키지가 포함된 Python용 Azure Machine Learning SDK가 설치됩니다.- 통합 Notebook이 포함되어 있고 SDK가 이미 설치된 완전히 구성되어 관리되는 개발 환경인 Azure Machine Learning 컴퓨팅 인스턴스 만들기
OR
- 고유의 Python 환경에서 작업하고 이 지침을 사용하여 직접 SDK를 설치합니다.
참고 항목
일부 데이터 세트 클래스는 azureml-dataprep 패키지에 종속되어 있습니다. 이 패키지는 64비트 Python에만 호환됩니다. Linux 사용자의 경우 이러한 클래스는 다음 Linux 배포판에서만 지원됩니다.
- Debian(8, 9)
- Fedora(27, 28)
- Red Hat Enterprise Linux(7, 8)
- Ubuntu(14.04, 16.04, 18.04)
SDK로 데이터 세트 만들기
Python SDK에서 Azure Open Datasets 클래스를 통해 Azure Machine Learning 데이터 세트를 만들려면 pip install azureml-opendatasets를 사용하여 패키지를 설치했는지 확인합니다. SDK에서 각 개별 데이터 세트의 클래스는 해당 클래스를 나타내며, 특정 클래스는 Azure Machine Learning FileDataset 데이터 형식, Azure Machine Learning TabularDataset 데이터 형식 또는 둘 다로 사용할 수 있습니다. opendatasets 클래스의 전체 목록은 참조 설명서를 참조하세요.
특정 opendatasets 클래스를 TabularDataset 또는 FileDataset 리소스로 검색할 수 있습니다. 그런 다음 파일을 직접 조작 및/또는 다운로드할 수 있습니다. 다른 클래스는 Python SDK의 Dataset클래스에서 get_tabular_dataset() 또는 get_file_dataset() 함수를 사용하는 경우에만 데이터 세트를 검색할 수 있습니다.
이 코드는 MNIST opendatasets 클래스가 TabularDataset 또는 FileDataset를 반환할 수 있음을 보여 줍니다.
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
이 예에서 Diabetes opendatasets 클래스는 TabularDataset로만 사용할 수 있습니다. get_tabular_dataset()를 사용해야 합니다.
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
데이터 세트 등록
작업 영역에 Azure Machine Learning 데이터 세트를 등록하면 다른 사람과 데이터 세트를 공유하고 작업 영역의 여러 실험에서 다시 사용할 수 있습니다. Open Datasets에서 만든 Azure Machine Learning 데이터 세트를 등록하는 경우, 데이터는 즉시 다운로드되지 않지만 나중에(예: 학습 중) 중앙 스토리지 위치에서 요청하면 데이터에 액세스할 수 있습니다.
작업 영역을 사용하여 데이터 세트를 등록하려면 register() 메서드를 사용합니다.
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
스튜디오로 데이터 세트 만들기
Azure Machine Learning 스튜디오를 사용하여 Azure Open Datasets에서 Azure Machine Learning 데이터 세트를 만들 수도 있습니다. 이 통합 웹 인터페이스에는 모든 기술 수준의 데이터 과학 전문가를 위한 데이터 과학 시나리오를 수행하는 기계 학습 도구가 포함되어 있습니다.
참고 항목
Azure Machine Learning 스튜디오를 통해 만든 데이터 세트는 작업 영역에 자동으로 등록됩니다.
작업 영역의 왼쪽 탐색 창에서 데이터를 선택합니다. 데이터 자산 탭에서 이 스크린샷에 표시된 대로 만들기를 선택합니다.
다음 화면에서 새 데이터 자산의 이름과 설명(선택 사항)을 추가합니다. 그런 다음 이 스크린샷에 표시된 대로 형식 드롭다운에서 테이블 형식을 선택합니다.

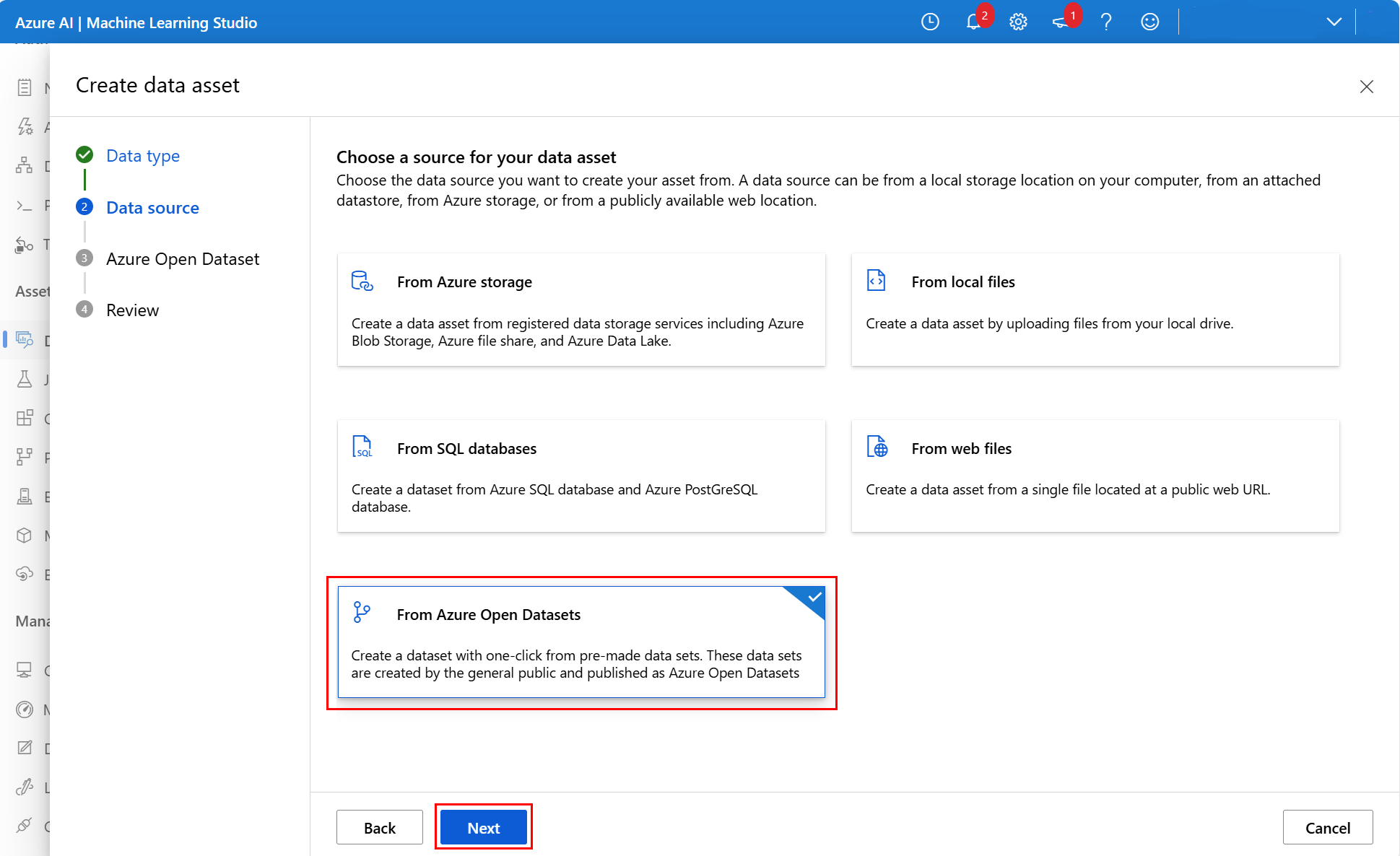
다음 화면에서 Azure Open Datasets에서를 선택한 후 이 스크린샷에 표시된 대로 다음을 선택합니다.
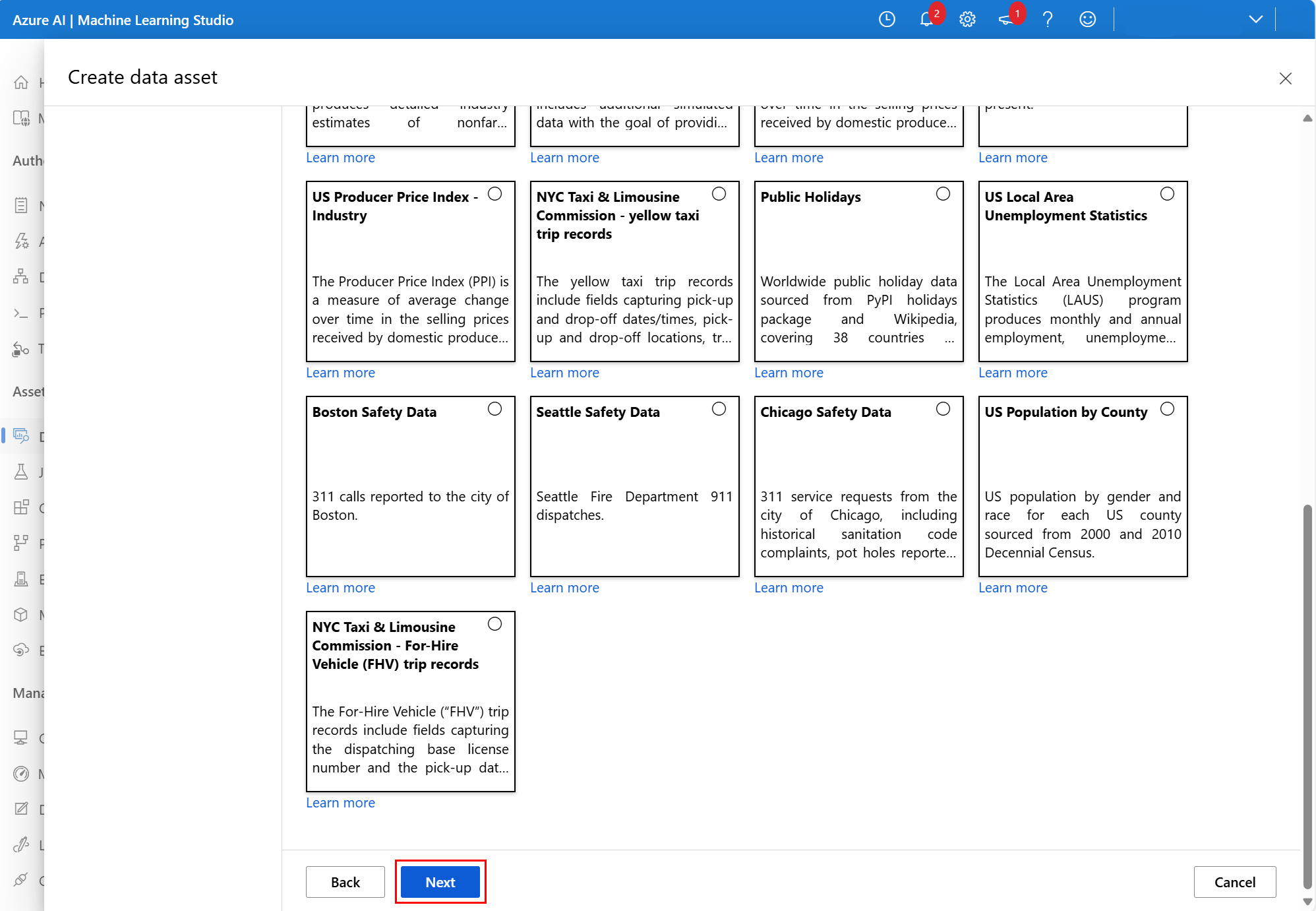
다음 화면에서 사용 가능한 Azure Open Dataset를 선택합니다. 이 스크린샷에서 우리는 샌프란시스코 안전 데이터 데이터 세트를 선택했습니다.

필요한 경우 아래로 스크롤하여 이 스크린샷에 표시된 대로 다음을 선택합니다.
선택적으로, 선택한 데이터 세트에 적절한 사용 가능한 필터를 사용하여 데이터를 필터링합니다. 샌프란시스코 안전 데이터 데이터 세트의 경우 필터링된 날짜 범위를 시작 날짜인 2024년 7월 1일과 2024년 7월 17일 사이로 설정했습니다. 이 스크린샷에 표시된 대로 다음을 선택합니다.

다음 화면에서 새 데이터 자산에 대한 설정을 검토하고 필요한 변경을 수행합니다. 문제가 해결되면 이 스크린샷에 표시된 대로 만들기를 선택합니다.

샌프란시스코 안전 데이터 데이터 세트의 필드 설명 및 날짜 범위에 대한 자세한 내용은 샌프란시스코 안전 데이터 리소스를 참조하세요. 다른 데이터 세트에 대한 자세한 내용은 Azure Open Datasets Catalog 리소스를 참조하세요.







이제 데이터 세트 아래의 작업 영역에서 데이터 세트를 사용할 수 있습니다. 다른 데이터 세트를 만든 것과 같은 방식으로 사용할 수 있습니다.
실험을 위한 데이터 세트 액세스
기계 학습 실험에서 ML 모델 학습을 위해 데이터 세트를 사용합니다. 자세한 내용은 데이터 세트를 사용하여 학습하는 방법에 대해 자세히 알아보기를 참조하세요.
예제 Notebook
Open Datasets 기능의 예와 데모를 보려면 샘플 Notebook을 검토합니다.