자습서: Jupyter Notebook 예제를 통해 이미지 분류 모델 학습 및 배포
적용 대상:  Python SDK azureml v1
Python SDK azureml v1
이 자습서에서는 원격 컴퓨팅 리소스에 대해 기계 학습 모델을 학습합니다. Python Jupyter Notebook에서 Azure Machine Learning에 대한 학습 및 배포 워크플로를 사용합니다. 그런 다음, 이 노트를 템플릿으로 사용하여 자신의 데이터로 고유한 Machine Learning 모델을 학습할 수 있습니다.
이 자습서에서는 Azure Machine Learning과 함께 MNIST 데이터 세트 및 scikit-learn을 사용하여 간단한 로지스틱 회귀 분석을 학습합니다. MNIST는 70,000개의 회색조 이미지로 구성된 인기 있는 데이터 세트입니다. 각 이미지는 0-9의 숫자를 나타내는 28x28 픽셀의 필기체 숫자입니다. 목표는 지정된 이미지가 나타내는 숫자를 식별하기 위한 다중 클래스 분류자를 만드는 것입니다.
다음 작업을 수행하는 방법에 대해 알아봅니다.
- 데이터 세트를 다운로드하고 데이터를 살펴봅니다.
- MLflow를 사용하여 이미지 분류 모델 및 로그 메트릭을 학습시킵니다.
- 실시간 유추를 수행하도록 모델을 배포합니다.
필수 조건
- 빠른 시작: Azure Machine Learning 시작을 완료하여 다음을 수행합니다.
- 작업 영역을 만듭니다.
- 개발 환경에 사용할 클라우드 기반 컴퓨팅 인스턴스를 만듭니다.
작업 영역에서 Notebook 실행
Azure Machine Learning은 설치할 필요가 없는 미리 구성된 환경을 위해 클라우드 Notebook 서버를 작업 영역에 포함시킵니다. 환경, 패키지 및 종속성을 제어하려면 사용자 고유의 환경을 사용합니다.
Notebook 폴더 복제
Azure Machine Learning 스튜디오에서 다음 실험 설정 및 실행 단계를 완료합니다. 이 통합 인터페이스에는 모든 기술 수준의 데이터 과학 전문가를 위한 데이터 과학 시나리오를 수행하는 기계 학습 도구가 포함되어 있습니다.
Azure Machine Learning Studio에 로그인합니다.
해당 구독과 직접 만든 작업 영역을 선택합니다.
왼쪽에서 Notebook을 선택합니다.
위쪽에서 샘플 탭을 선택합니다.
SDK v1 폴더를 엽니다.
tutorials 폴더의 오른쪽에 있는 ... 단추를 선택한 다음, 복제를 선택합니다.
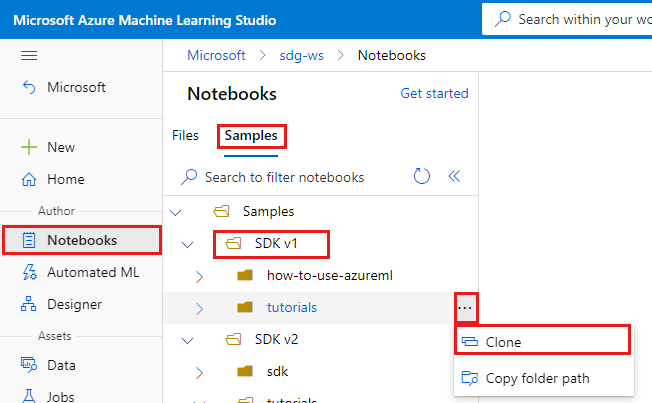
작업 영역에 액세스하는 각 사용자가 폴더 목록에 표시됩니다. tutorials 폴더를 복제할 폴더를 선택합니다.
복제된 Notebook 열기
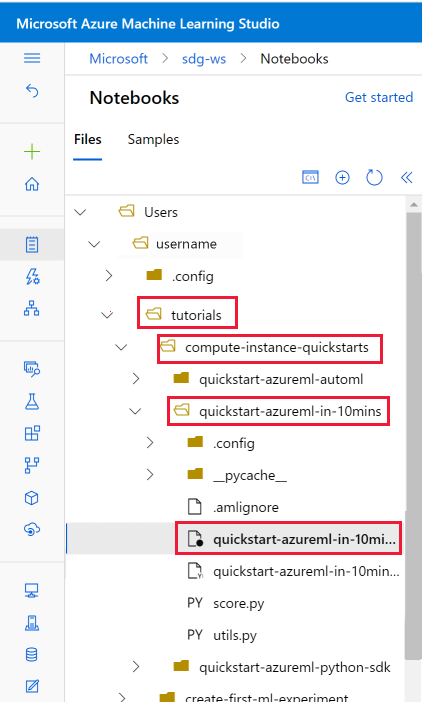
사용자 파일 섹션에서 복제된 tutorials 폴더를 엽니다.
tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins 폴더에서 quickstart-azureml-in-10mins.ipynb 파일을 선택합니다.
패키지 설치
컴퓨팅 인스턴스가 실행되고 커널이 나타나면 이 자습서에 필요한 패키지를 설치하는 새 코드 셀을 추가합니다.
Notebook 맨 위에 코드 셀을 추가합니다.
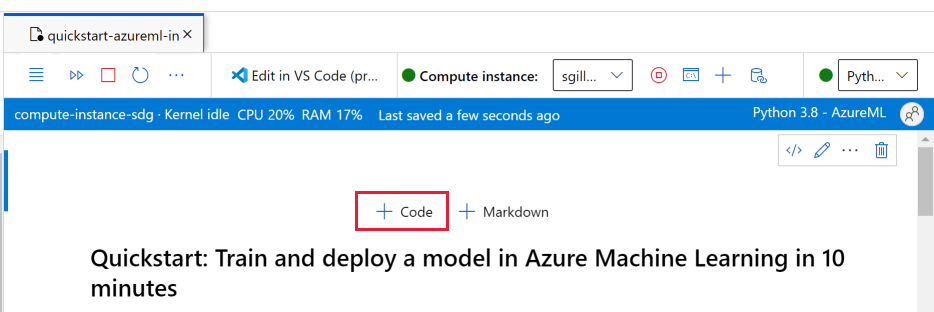
다음을 셀에 추가한 다음, 실행 도구를 사용하거나 Shift+Enter를 사용하여 셀을 실행합니다.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
몇 가지 설치 경고가 표시될 수 있습니다. 이 오류는 무시해도 됩니다.
노트북 실행
이 자습서 및 함께 제공되는 utils.py 파일은 자체 로컬 환경에서 사용하려는 경우 GitHub에서도 사용할 수 있습니다. 컴퓨팅 인스턴스를 사용하지 않는 경우 위의 설치에 %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib를 추가합니다.
Important
이 문서의 나머지 부분에는 Notebook에 표시되는 것과 동일한 콘텐츠가 포함되어 있습니다.
코드를 읽는 동안 코드를 실행하려면 지금 Jupyter Notebook으로 전환합니다. Notebook에서 단일 코드 셀을 실행하려면 코드 셀을 클릭하고 Shift+Enter 키를 누릅니다. 또는 상단 도구 모음에서 모두 실행을 선택하여 전체 Notebook을 실행합니다.
데이터 가져오기
모델을 학습시키기 전에 이 모델을 학습시키는 데 사용할 데이터를 이해해야 합니다. 이 섹션에서는 다음 방법에 대해 알아봅니다.
- MNIST 데이터 세트 다운로드
- 일부 샘플 이미지 표시
Azure Open Datasets를 사용하여 원시 MNIST 데이터 파일을 가져옵니다. Azure Open Datasets는 기계 학습 솔루션에 시나리오별 기능을 추가하여 더 나은 모델을 만들 수 있는 큐레이팅된 공개 데이터 세트입니다. 각 데이터 세트에는 여러 다른 방식으로 데이터를 검색하기 위한 해당 클래스(이 경우에는 MNIST)가 있습니다.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
데이터 살펴보기
압축된 파일을 numpy 배열로 로드합니다. 그런 다음, matplotlib를 사용하여 데이터 세트에 있는 30개의 무작위 이미지를 그리고, 위에 레이블을 표시합니다.
이 단계를 수행하려면 utils.py 파일에 포함된 load_data 함수가 필요합니다. 이 파일은 이 Notebook과 동일한 폴더에 있습니다. load_data 함수는 압축 파일을 numpy 배열로 간단히 구문 분석합니다.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
코드는 레이블이 있는 임의의 이미지 집합을 다음과 같이 표시합니다.

MLflow를 사용하여 모델 및 로그 메트릭 학습
다음 코드를 사용하여 모델을 학습합니다. 이 코드는 MLflow 자동 로깅을 사용하여 메트릭 및 로그 모델 아티팩트를 추적합니다.
SciKit Learn 프레임워크의 LogisticRegression 분류자를 사용하여 데이터를 분류합니다.
참고 항목
모델 학습을 완료하는 데 약 2분이 걸립니다.
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
실험 보기
Azure Machine Learning 스튜디오의 왼쪽 메뉴에서 작업을 선택한 다음 작업(azure-ml-in10-mins-tutorial)을 선택합니다. 작업은 지정된 스크립트 또는 코드 조각에서 많은 실행을 그룹화한 것입니다. 여러 작업을 실험으로 함께 그룹화할 수 있습니다.
실행에 대한 정보는 해당 작업 아래에 저장됩니다. 작업을 제출할 때 이름이 존재하지 않는 경우 실행을 선택하면 메트릭, 로그, 설명 등이 포함된 다양한 탭이 표시됩니다.
모델 레지스트리를 사용하여 모델 버전 제어
모델 등록을 사용하여 모델을 작업 영역에 저장하고 버전을 지정할 수 있습니다. 등록된 모델은 이름 및 버전으로 식별됩니다. 모델을 기존 이름과 동일한 이름으로 등록할 때마다 레지스트리에서 버전을 증가시킵니다. 아래 코드는 위에서 학습시킨 모델을 등록하고 버전을 지정합니다. 아래 코드 셀을 실행하면 Azure Machine Learning 스튜디오의 왼쪽 메뉴에서 모델을 선택하여 레지스트리에서 모델을 표시합니다.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
실시간 유추를 위해 모델 배포
이 섹션에서는 애플리케이션이 REST를 통해 모델을 사용(유추)할 수 있도록 모델을 배포하는 방법을 알아봅니다.
배포 구성 만들기
코드 셀은 모델을 호스트하는 데 필요한 모든 종속성(예: scikit-learn과 같은 패키지)을 지정하는 큐레이팅된 환경을 가져옵니다. 또한 모델을 호스트하는 데 필요한 컴퓨팅 양을 지정하는 배포 구성을 만듭니다. 이 경우 컴퓨팅에는 1개의 CPU와 1GB 메모리가 있습니다.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
모델 배포
다음 코드 셀은 Azure Container Instance에 모델을 배포합니다.
참고 항목
배포를 완료하는 데 약 3분이 걸립니다. 그러나 사용할 수 있을 때까지는 15분까지 더 길어질 수 있습니다.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
이전 코드에서 참조된 채점 스크립트 파일은 이 Notebook과 동일한 폴더에서 찾을 수 있으며 다음 두 가지 함수가 있습니다.
- 서비스가 시작될 때 한 번 실행되는
init함수 - 이 함수에서는 일반적으로 레지스트리에서 모델을 가져오고 전역 변수를 설정합니다. - 서비스에 대한 호출이 이루어질 때마다 실행되는
run(data)함수. 이 함수에서는 일반적으로 입력 데이터의 형식을 지정하고, 예측을 실행하고, 예측 결과를 출력합니다.
엔드포인트 보기
모델이 성공적으로 배포되면 Azure Machine Learning 스튜디오의 왼쪽 메뉴에서 엔드포인트로 이동하여 엔드포인트를 볼 수 있습니다. 엔드포인트의 상태(정상/비정상), 로그 및 사용(애플리케이션에서 모델을 사용하는 방법)이 표시됩니다.
모델 서비스 테스트
웹 서비스를 테스트하기 위해 원시 HTTP 요청을 전송하여 모델을 테스트할 수 있습니다.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
리소스 정리
이 모델을 계속 사용하지 않으려면 다음을 사용하여 모델 서비스를 삭제합니다.
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
비용을 추가로 제어하려면 컴퓨팅 드롭다운 옆에 있는 "컴퓨팅 중지" 단추를 선택하여 컴퓨팅 인스턴스를 중지합니다. 그런 다음, 다음에 필요할 때 컴퓨팅 인스턴스를 다시 시작합니다.
모든 항목 삭제
다음 단계를 사용하여 Azure Machine Learning 작업 영역 및 모든 컴퓨팅 리소스를 삭제합니다.
Important
사용자가 만든 리소스는 다른 Azure Machine Learning 자습서 및 방법 문서의 필수 구성 요소로 사용할 수 있습니다.
사용자가 만든 리소스를 사용하지 않으려면 요금이 발생하지 않도록 해당 리소스를 삭제합니다.
Azure Portal의 검색 상자에 리소스 그룹을 입력하고 결과에서 선택합니다.
목록에서 만든 리소스 그룹을 선택합니다.
개요 페이지에서 리소스 그룹 삭제를 선택합니다.
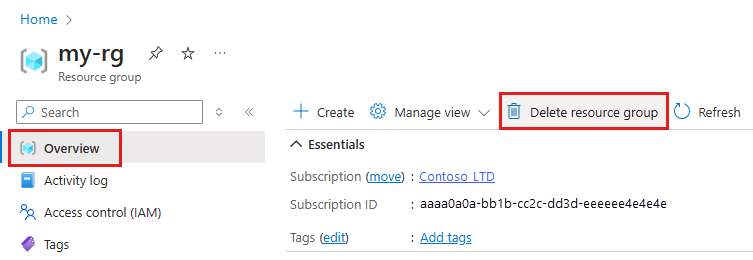
리소스 그룹 이름을 입력합니다. 그런 다음 삭제를 선택합니다.
관련 참고 자료
- Azure Machine Learning에 대한 배포 옵션을 모두 알아봅니다.
- 배포된 모델에 대해 인증하는 방법을 알아봅니다.
- 많은 양의 데이터에 대해 비동기적으로 예측합니다.
- Application Insights를 사용하여 Azure Machine Learning 모델을 모니터링합니다.