자습서: 첫 번째 기계 학습 모델 학습(SDK v1, 2/3)
적용 대상:  Python SDK azureml v1
Python SDK azureml v1
이 자습서에서는 Azure Machine Learning에서 기계 학습 모델을 학습시키는 방법을 보여 줍니다. 이 자습서는 2부로 구성된 자습서 시리즈 중 제2부입니다.
시리즈의 1부: "Hello world!" 실행에서 컨트롤 스크립트를 사용하여 클라우드에서 작업을 실행하는 방법을 알아보았습니다.
이 자습서에서는 기계 학습 모델을 학습시키는 스크립트를 제출하여 다음 단계를 수행합니다. 이 예제는 Azure Machine Learning에서 로컬 디버깅과 원격 실행 간의 일관된 동작을 간소화하는 방법을 이해하는 데 도움이 됩니다.
이 자습서에서는 다음을 수행합니다.
- 학습 스크립트를 만듭니다.
- Conda를 사용하여 Azure Machine Learning 환경 정의
- 제어 스크립트 만들기
- Azure Machine Learning 클래스(
Environment,Run,Metrics) 이해 - 학습 스크립트 제출 및 실행
- 클라우드에서 코드 출력 보기
- Azure Machine Learning에 메트릭 기록
- 클라우드에서 메트릭 보기
필수 조건
- 시리즈의 1부 완료.
학습 스크립트 만들기
먼저 model.py 파일에서 신경망 아키텍처를 정의합니다. model.py를 포함하여 모든 학습 코드는 src 하위 디렉터리로 이동합니다.
학습 코드는 PyTorch의 이 소개 예제에서 가져온 것입니다. Azure Machine Learning 개념은 PyTorch뿐만 아니라 모든 기계 학습 코드에도 적용됩니다.
src 하위 폴더에 model.py 파일을 만듭니다. 이 코드를 파일에 복사합니다.
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x도구 모음에서 저장을 선택하여 파일을 저장합니다. 원하는 경우 탭을 닫습니다.
다음으로, src 하위 폴더에서도 학습 스크립트를 정의합니다. 이 스크립트는 PyTorch
torchvision.datasetAPI를 사용하여 CIFAR10 데이터 세트를 다운로드하고, model.py에 정의된 네트워크를 설정하며, 표준 SGD 및 교차 엔트로피 손실을 사용하여 두 Epoch 동안 학습시킵니다.src 하위 폴더에 train.py 스크립트를 만듭니다.
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")이제 다음과 같은 폴더 구조를 가지게 되었습니다.
로컬에서 테스트
터미널에서 스크립트 저장 및 실행을 선택하여 컴퓨팅 인스턴스에서 직접 train.py 스크립트를 실행합니다.
스크립트가 완료되면 파일 폴더 위에서 새로 고침을 선택합니다. get-started/data라는 새 데이터 폴더가 표시됩니다. 이 폴더를 확장하여 다운로드한 데이터를 봅니다.
Python 환경 만들기
Azure Machine Learning은 실험을 실행하기 위해 재현 가능한 버전의 Python 환경을 나타내는 환경 개념을 제공합니다. 환경은 로컬 Conda 또는 pip 환경에서 쉽게 만들 수 있습니다.
먼저 패키지 종속성이 있는 파일을 만듭니다.
pytorch-env.yml이라는 get-started 폴더에 새 파일을 만듭니다.name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvision도구 모음에서 저장을 선택하여 파일을 저장합니다. 원하는 경우 탭을 닫습니다.
제어 스크립트 만들기
다음 제어 스크립트와 "Hello world!"를 제출하는 데 사용되는 제어 스크립트와의 차이점은 환경을 설정하기 위해 몇 줄을 추가한다는 것입니다.
run-pytorch.py라는 get-started 폴더에 새 Python 파일을 만듭니다.
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
팁
컴퓨팅 클러스터를 만들 때 다른 이름을 사용한 경우 코드 compute_target='cpu-cluster'의 이름도 조정합니다.
코드 변경 내용 이해
env = ...
위에서 만든 종속성 파일을 참조합니다.
config.run_config.environment = env
ScriptRunConfig에 환경을 추가합니다.
Azure Machine Learning에 실행을 제출
터미널에서 스크립트 저장 및 실행을 선택하여 run-pytorch.py 스크립트를 실행합니다.
열리는 터미널 창에 링크가 표시됩니다. 작업을 보려면 링크를 선택합니다.
참고 항목
azureml_run_type_providers... 로드 중 실패로 시작하는 몇 가지 경고가 표시될 수 있습니다. 이러한 경고는 무시해도 됩니다. 이 경고의 맨 아래에 있는 링크를 사용하여 출력을 확인합니다.
출력 보기
- 열리는 페이지에서 작업 상태를 볼 수 있습니다. 이 스크립트를 처음 실행하면 Azure Machine Learning이 PyTorch 환경에서 새 Docker 이미지를 빌드합니다. 전체 작업을 완료하는 데 약 10분이 소요될 수 있습니다. 이 이미지는 향후 작업에서 재사용되어 훨씬 더 빠르게 실행할 수 있습니다.
- Docker 빌드 로그 보기는 Azure Machine Learning 스튜디오에서 확인할 수 있습니다. 빌드 로그를 보려면 다음을 수행합니다.
- 출력 + 로그 탭을 선택하세요.
- azureml-logs 폴더를 선택합니다.
- 20_image_build_log.txt를 선택합니다.
- 작업 상태가 완료됨이면 출력 + 로그를 선택합니다.
- 작업의 출력을 보려면 user_logs를 선택한 다음, std_log.txt를 선택합니다.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
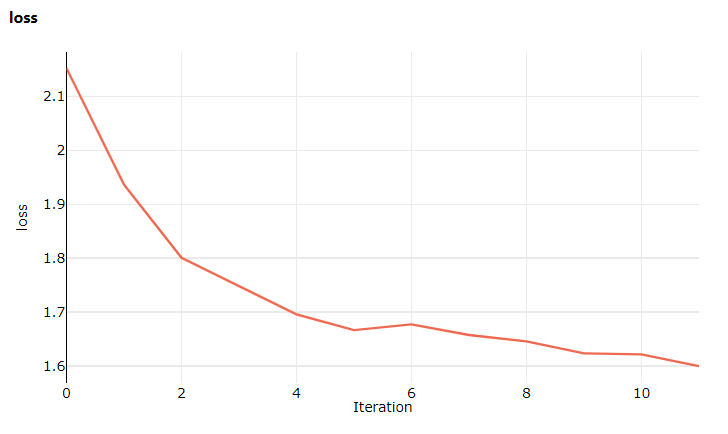
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
오류 Your total snapshot size exceeds the limit가 표시되면 데이터 폴더가 ScriptRunConfig에서 사용되는 source_directory 값에 있음을 나타냅니다.
폴더 끝에 있는 ...를 선택한 다음, 이동을 선택하여 데이터를 get-started 폴더로 이동합니다.
학습 메트릭 기록
이제 Azure Machine Learning에서 학습된 모델이 있으므로 몇 가지 성능 메트릭의 추적을 시작합니다.
현재 학습 스크립트는 메트릭을 터미널에 출력합니다. Azure Machine Learning은 더 많은 기능을 통해 메트릭을 기록하는 메커니즘을 제공합니다. 몇 줄의 코드를 추가하면 Studio에서 메트릭을 시각화하고 여러 작업 간에 메트릭을 비교할 수 있습니다.
로깅을 포함하도록 train.py 수정
train.py 스크립트를 수정하여 코드의 두 줄을 더 포함시킵니다.
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')이 파일을 저장한 다음, 원하는 경우 탭을 닫습니다.
두 줄의 추가 코드 이해
train.py에서 Run.get_context() 메서드를 사용하여 학습 스크립트 자체 내에서 실행 개체에 액세스하고, 이 개체를 사용하여 메트릭을 기록합니다.
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Azure Machine Learning의 메트릭은 다음과 같습니다.
- 실험 및 실행별로 구성되므로 메트릭을 쉽게 추적하고 비교할 수 있습니다.
- Studio에서 UI를 사용하여 학습 성과를 시각화할 수 있습니다.
- 크기를 조정할 수 있도록 설계되었으므로 수백 개의 실험을 실행하는 경우에도 이러한 이점을 유지할 수 있습니다.
Conda 환경 파일 업데이트
train.py 스크립트는 azureml.core에 대한 새로운 종속성을 가져왔습니다. 이 변경 내용을 반영하도록 pytorch-env.yml을 업데이트합니다.
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
실행을 제출하기 전에 이 파일을 저장해야 합니다.
Azure Machine Learning에 실행을 제출
run-pytorch.py 스크립트의 탭을 선택한 다음, 터미널에서 스크립트 저장 및 실행을 선택하여 run-pytorch.py 스크립트를 다시 실행합니다. 먼저 pytorch-env.yml에 변경 내용을 저장해야 합니다.
이번에는 Studio를 방문할 때 모델 학습 손실에 대한 라이브 업데이트를 볼 수 있는 메트릭 탭으로 이동합니다. 학습이 시작되기까지 1~2분 정도 걸릴 수 있습니다.
리소스 정리
지금 다른 자습서로 계속 진행하거나 자체 학습 작업을 시작하려면 관련 리소스로 건너뜁니다.
컴퓨팅 인스턴스 중지
지금 사용하지 않으려면 컴퓨팅 인스턴스를 중지합니다.
- 스튜디오 왼쪽의 컴퓨팅을 선택합니다.
- 맨 위 탭에서 컴퓨팅 인스턴스를 선택합니다.
- 목록에서 컴퓨팅 인스턴스를 선택합니다.
- 맨 위의 도구 모음에서 중지를 선택합니다.
모든 리소스 삭제
Important
사용자가 만든 리소스는 다른 Azure Machine Learning 자습서 및 방법 문서의 필수 구성 요소로 사용할 수 있습니다.
사용자가 만든 리소스를 사용하지 않으려면 요금이 발생하지 않도록 해당 리소스를 삭제합니다.
Azure Portal의 검색 상자에 리소스 그룹을 입력하고 결과에서 선택합니다.
목록에서 만든 리소스 그룹을 선택합니다.
개요 페이지에서 리소스 그룹 삭제를 선택합니다.
리소스 그룹 이름을 입력합니다. 그런 다음 삭제를 선택합니다.
또한 리소스 그룹을 유지하면서 단일 작업 영역을 삭제할 수도 있습니다. 작업 영역 속성을 표시하고 삭제를 선택합니다.
관련 참고 자료
이 세션에서는 기본 "Hello world!" 스크립트에서 특정 Python 환경을 실행하는 데 필요한 더 사실적인 학습 스크립트로 업그레이드했습니다. 큐레이팅된 Azure Machine Learning 환경을 사용하는 방법을 살펴보았습니다. 마지막으로 몇 줄의 코드에서 메트릭을 Azure Machine Learning에 기록할 수 있는 방법을 살펴보았습니다.
pip requirements.txt 또는 기존 로컬 Conda 환경을 포함하여 Azure Machine Learning 환경을 만드는 다른 방법이 있습니다.