평가 흐름 및 메트릭
평가 흐름은 메트릭을 계산하여 실행 출력이 특정 조건 및 목표를 얼마나 잘 충족하는지 평가하는 특수한 유형의 프롬프트 흐름입니다. 작업 및 목표에 맞게 조정된 평가 흐름 및 메트릭을 만들거나 사용자 지정하고 이를 사용하여 다른 프롬프트 흐름을 평가할 수 있습니다. 이 문서에서는 평가 흐름, 개발 및 사용자 지정 방법, 프롬프트 흐름 일괄 처리 실행에서 이를 사용하여 흐름 성능을 평가하는 방법을 설명합니다.
평가 흐름 이해
프롬프트 흐름은 입력을 처리하고 출력을 생성하는 노드 시퀀스입니다. 또한 평가 흐름은 필요한 입력을 사용하고 일반적으로 점수 또는 메트릭인 해당 출력을 생성합니다. 평가 흐름은 제작 환경 및 사용량의 표준 흐름과 다릅니다.
평가 흐름은 일반적으로 출력을 수신하고 출력을 사용하여 점수 및 메트릭을 계산하여 테스트하는 실행 후에 실행됩니다. 평가 흐름은 프롬프트 흐름 SDK log_metric() 함수를 사용하여 메트릭을 기록합니다.
평가 흐름의 출력은 테스트 중인 흐름의 성능을 측정하는 결과입니다. 평가 흐름에는 테스트 데이터 세트를 통해 테스트되는 흐름의 전체 성능을 계산하는 집계 노드가 있을 수 있습니다.
다음 섹션에서는 평가 흐름에서 입력 및 출력을 정의하는 방법을 설명합니다.
입력
평가 흐름은 테스트 중인 실행의 출력을 가져와 일괄 처리 실행에 대한 메트릭 또는 점수를 계산합니다. 예를 들어 테스트 중인 흐름이 질문에 따라 답변을 생성하는 QnA 흐름인 경우 평가 입력의 이름을 로 지정할 answer수 있습니다. 테스트 중인 흐름이 텍스트를 범주로 분류하는 분류 흐름인 경우 평가 입력의 이름을 로 지정할 category수 있습니다.
다른 입력이 근거로 필요할 수 있습니다. 예를 들어 분류 흐름의 정확도를 계산하려면 데이터 세트의 열을 기본 진리로 제공해야 category 합니다. QnA 흐름의 정확도를 계산하려면 데이터 세트의 열을 기본 진리로 제공해야 answer 합니다. QnA 또는 RAG(검색 보강 생성) 시나리오와 같은 question context 메트릭을 계산하려면 몇 가지 다른 입력이 필요할 수 있습니다.
표준 흐름의 입력을 정의하는 것과 동일한 방식으로 평가 흐름의 입력을 정의합니다. 기본적으로 평가는 테스트 중인 실행과 동일한 데이터 세트를 사용합니다. 그러나 해당 레이블 또는 대상 접지 진리 값이 다른 데이터 세트에 있는 경우 해당 데이터 세트로 쉽게 전환할 수 있습니다.
입력 설명
메트릭을 계산하는 데 필요한 입력을 설명하기 위해 설명을 추가할 수 있습니다. 설명은 일괄 실행 제출에서 입력 원본을 매핑할 때 표시됩니다.
각 입력에 대한 설명을 추가하려면 평가 방법을 개발할 때 입력 섹션에서 설명 표시를 선택한 다음 설명을 입력합니다.

입력 양식에서 설명을 숨기려면 설명 숨기기를 선택합니다.

출력 및 메트릭
평가의 출력은 테스트 중인 흐름의 성능을 보여 주는 결과입니다. 출력은 일반적으로 점수와 같은 메트릭을 포함하며 추론 및 제안에 대한 텍스트를 포함할 수도 있습니다.
출력 점수
프롬프트 흐름은 한 번에 한 행의 데이터를 처리하고 출력 레코드를 생성합니다. 마찬가지로 평가 흐름은 각 데이터 행에 대한 점수를 계산할 수 있으므로 각 개별 데이터 요소에서 흐름이 어떻게 수행되는지 확인할 수 있습니다.
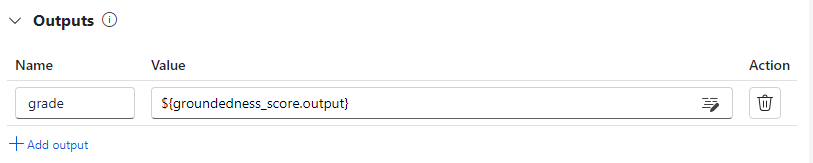
각 데이터 인스턴스의 점수를 평가 흐름의 출력 섹션에서 지정하여 계산 흐름 출력으로 기록할 수 있습니다. 제작 환경은 표준 흐름 출력을 정의하는 것과 동일합니다.
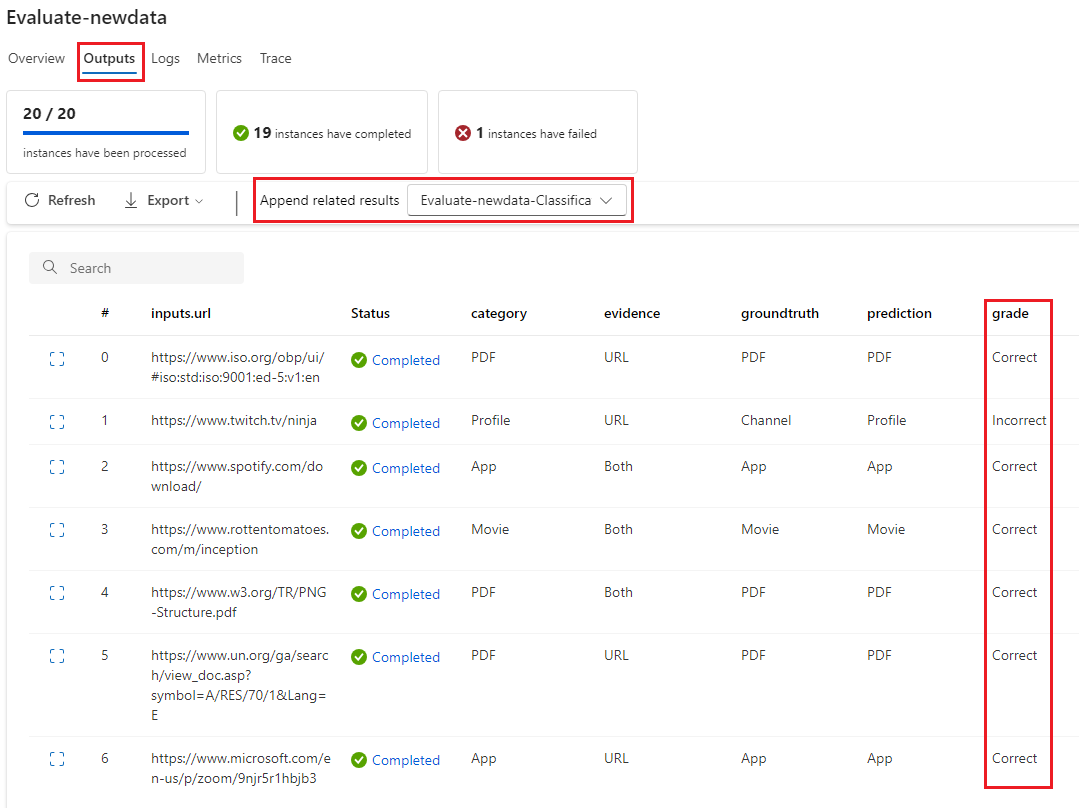
출력 보기(표준 흐름 일괄 처리 실행의 출력 확인)를 선택할 때 출력 탭에서 개별 점수를 볼 수 있습니다. 이러한 인스턴스 수준 점수를 테스트한 흐름의 출력에 추가할 수 있습니다.
집계 및 메트릭 로깅
평가 흐름은 실행에 대한 전반적인 평가도 제공합니다. 전체 결과를 개별 출력 점수와 구분하기 위해 이러한 전체 실행 성능 값을 메트릭이라고 합니다.
개별 점수를 기준으로 전체 평가 값을 계산하려면 평가 흐름의 Python 노드에서 집계 확인란을 선택하여 축소 노드로 전환합니다. 그런 다음 노드는 입력을 목록으로 가져와 일괄 처리로 처리합니다.

집계를 사용하면 각 흐름 출력의 모든 점수를 계산 및 처리하고 각 점수를 사용하여 전체 결과를 계산할 수 있습니다. 예를 들어 분류 흐름의 정확도를 계산하려면 각 점수 출력의 정확도를 계산한 다음 모든 점수 출력의 평균 정확도를 계산할 수 있습니다. 그런 다음 , 를 사용하여 promptflow_sdk.log_metric()평균 정확도를 메트릭으로 기록할 수 있습니다. 메트릭은 숫자(예: float 또는 int.)여야 합니다. 문자열 형식 메트릭 로깅은 지원되지 않습니다.
다음 코드 조각은 모든 데이터 요소의 정확도 점수를 grades 평균하여 전체 정확도를 계산하는 예제입니다. 전체 정확도는 .를 사용하여 promptflow_sdk.log_metric()메트릭으로 기록됩니다.
from typing import List
from promptflow import tool, log_metric
@tool
def calculate_accuracy(grades: List[str]): # Receive a list of grades from a previous node
# calculate accuracy
accuracy = round((grades.count("Correct") / len(grades)), 2)
log_metric("accuracy", accuracy)
return accuracy
Python 노드에서 이 함수를 호출하므로 다른 곳에 할당할 필요가 없으며 나중에 메트릭을 볼 수 있습니다. 일괄 실행에서 이 평가 방법을 사용한 후에는 출력을 볼 때 메트릭 탭을 선택하여 전반적인 성능을 보여 주는 메트릭 을 볼 수 있습니다.

평가 흐름 개발
고유한 평가 흐름을 개발하려면 Azure Machine Learning 스튜디오 프롬프트 흐름 페이지에서 만들기를 선택합니다. 새 흐름 만들기 페이지에서 다음 중 하나를 수행할 수 있습니다.
만들기 유형 아래의 평가 흐름 카드에서 만들기를 선택합니다. 이 선택은 새 평가 방법을 개발하기 위한 템플릿을 제공합니다.
탐색 갤러리에서 평가 흐름을 선택하고 사용 가능한 기본 제공 흐름 중 하나를 선택합니다. 보기 세부 정보를 선택하여 각 흐름에 대한 요약을 얻고 복제를 선택하여 흐름을 열고 사용자 지정합니다. 흐름 만들기 마법사를 사용하면 사용자 고유의 시나리오에 맞게 흐름을 수정할 수 있습니다.

각 데이터 요소에 대한 점수 계산
평가 흐름은 데이터 세트에 실행되는 흐름의 점수와 메트릭을 계산합니다. 평가 흐름의 첫 번째 단계는 각 개별 데이터 출력에 대한 점수를 계산하는 것입니다.
예를 들어 기본 제공 분류 정확도 평가 흐름 grade 에서 해당 접지 진리에 대한 각 흐름 생성 출력의 정확도를 측정하는 값은 등급 Python 노드에서 계산됩니다.
평가 흐름 템플릿을 사용하는 경우 line_process Python 노드에서 이 점수를 계산합니다. line_process Python 노드를 LLM(큰 언어 모델) 노드로 바꿔서 LLM을 사용하여 점수를 계산하거나 여러 노드를 사용하여 계산을 수행할 수도 있습니다.

이 노드의 출력을 계산 흐름의 출력으로 지정합니다. 이는 출력이 각 데이터 샘플에 대해 계산된 점수임을 나타냅니다. 또한 추가 정보에 대한 추론을 출력할 수 있으며 표준 흐름에서 출력을 정의하는 것과 동일한 환경입니다.
메트릭 계산 및 로그
평가의 다음 단계는 실행을 평가하는 전체 메트릭을 계산하는 것입니다. 집계 옵션이 선택된 Python 노드에서 메트릭을 계산합니다. 이 노드는 이전 계산 노드의 점수를 가져와 목록으로 구성한 다음 전체 값을 계산합니다.
평가 템플릿을 사용하는 경우 이 점수는 집계 노드에서 계산됩니다. 다음 코드 조각은 집계 노드에 대한 템플릿을 보여줍니다.
from typing import List
from promptflow import tool
@tool
def aggregate(processed_results: List[str]):
"""
This tool aggregates the processed result of all lines and log metric.
:param processed_results: List of the output of line_process node.
"""
# Add your aggregation logic here
aggregated_results = {}
# Log metric
# from promptflow import log_metric
# log_metric(key="<my-metric-name>", value=aggregated_results["<my-metric-name>"])
return aggregated_results
점수 평균, 중앙값 또는 표준 편차 계산과 같은 고유한 집계 논리를 사용할 수 있습니다.
함수를 사용하여 메트릭을 기록합니다 promptflow.log_metric() . 단일 평가 흐름에서 여러 메트릭을 기록할 수 있습니다. 메트릭은 숫자(float/int)여야 합니다.
평가 흐름 사용
고유한 평가 흐름 및 메트릭을 만든 후 흐름을 사용하여 표준 흐름의 성능을 평가할 수 있습니다. 예를 들어 QnA 흐름을 평가하여 대규모 데이터 세트에서 수행하는 방법을 테스트할 수 있습니다.
Azure Machine Learning 스튜디오 평가할 흐름을 열고 위쪽 메뉴 모음에서 평가(Evaluate)를 선택합니다.

Batch 실행 및 평가 마법사에서 기본 설정 및 Batch 실행 설정을 완료하여 테스트용 데이터 세트를 로드하고 입력 매핑을 구성합니다. 자세한 내용은 일괄 처리 실행 제출 및 흐름 계산을 참조하세요.
평가 선택 단계에서 실행할 사용자 지정된 평가 또는 기본 제공 평가 중 하나 이상을 선택할 수 있습니다. 사용자 지정된 평가 에는 사용자가 만들거나 복제하거나 사용자 지정한 모든 평가 흐름이 나열됩니다. 동일한 프로젝트에서 작업하는 다른 사용자가 만든 평가 흐름은 이 섹션에 표시되지 않습니다.
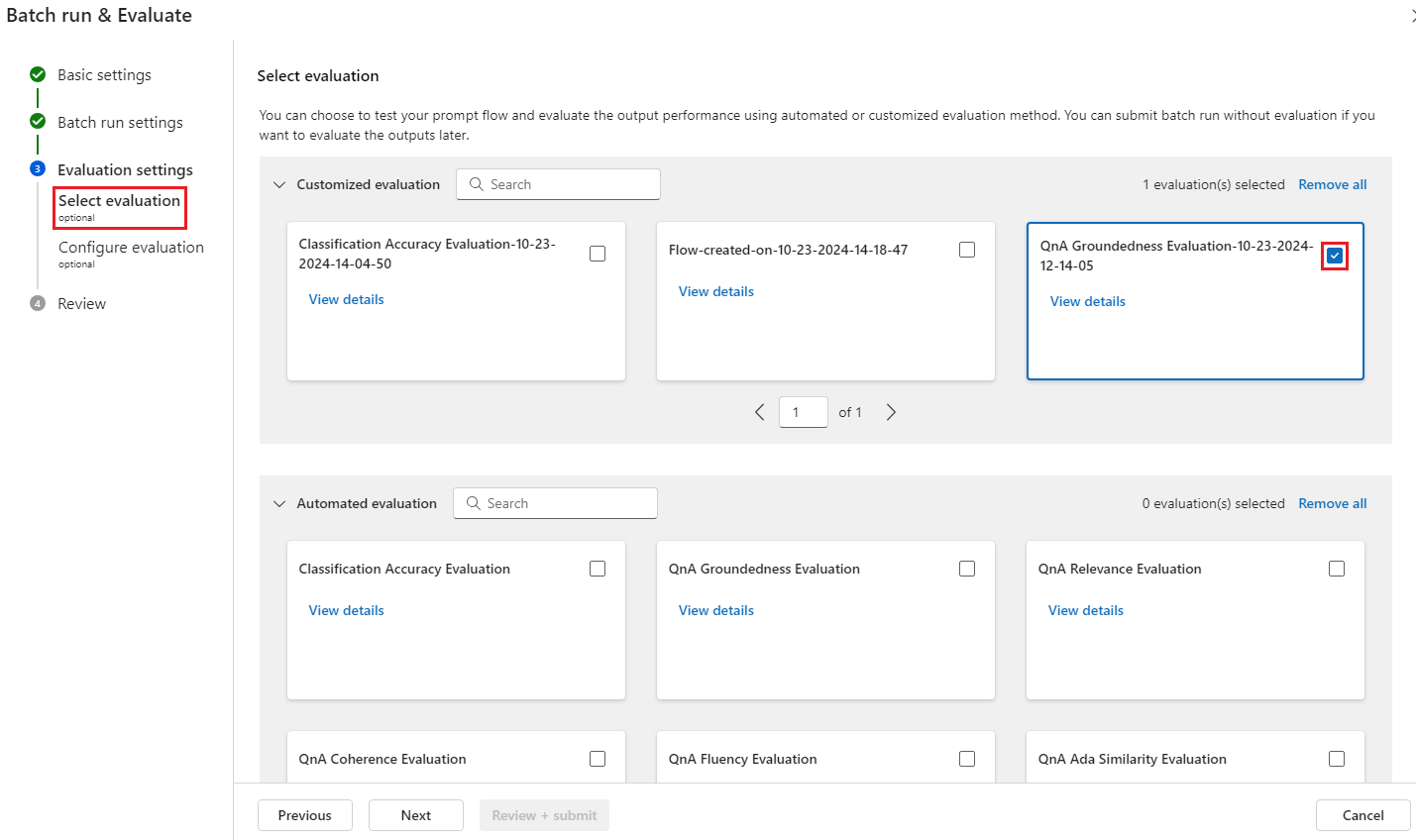
평가 구성 화면에서 평가 방법에 필요한 입력 데이터의 원본을 지정합니다. 예를 들어 기본 진리 열은 데이터 세트에서 나올 수 있습니다. 평가 방법에 데이터 세트의 데이터가 필요하지 않은 경우 데이터 세트를 선택하거나 입력 매핑 섹션에서 데이터 세트 열을 참조할 필요가 없습니다.
평가 입력 매핑 섹션에서 평가에 필요한 입력의 원본을 나타낼 수 있습니다. 데이터 원본이 실행 출력에서 온 경우 원본을 .로
${run.outputs.[OutputName]}설정합니다. 데이터가 테스트 데이터 세트의 데이터인 경우 원본을 .로${data.[ColumnName]}설정합니다. 데이터 입력에 대해 설정한 설명도 여기에 표시됩니다. 자세한 내용은 일괄 처리 실행 제출 및 흐름 계산을 참조하세요.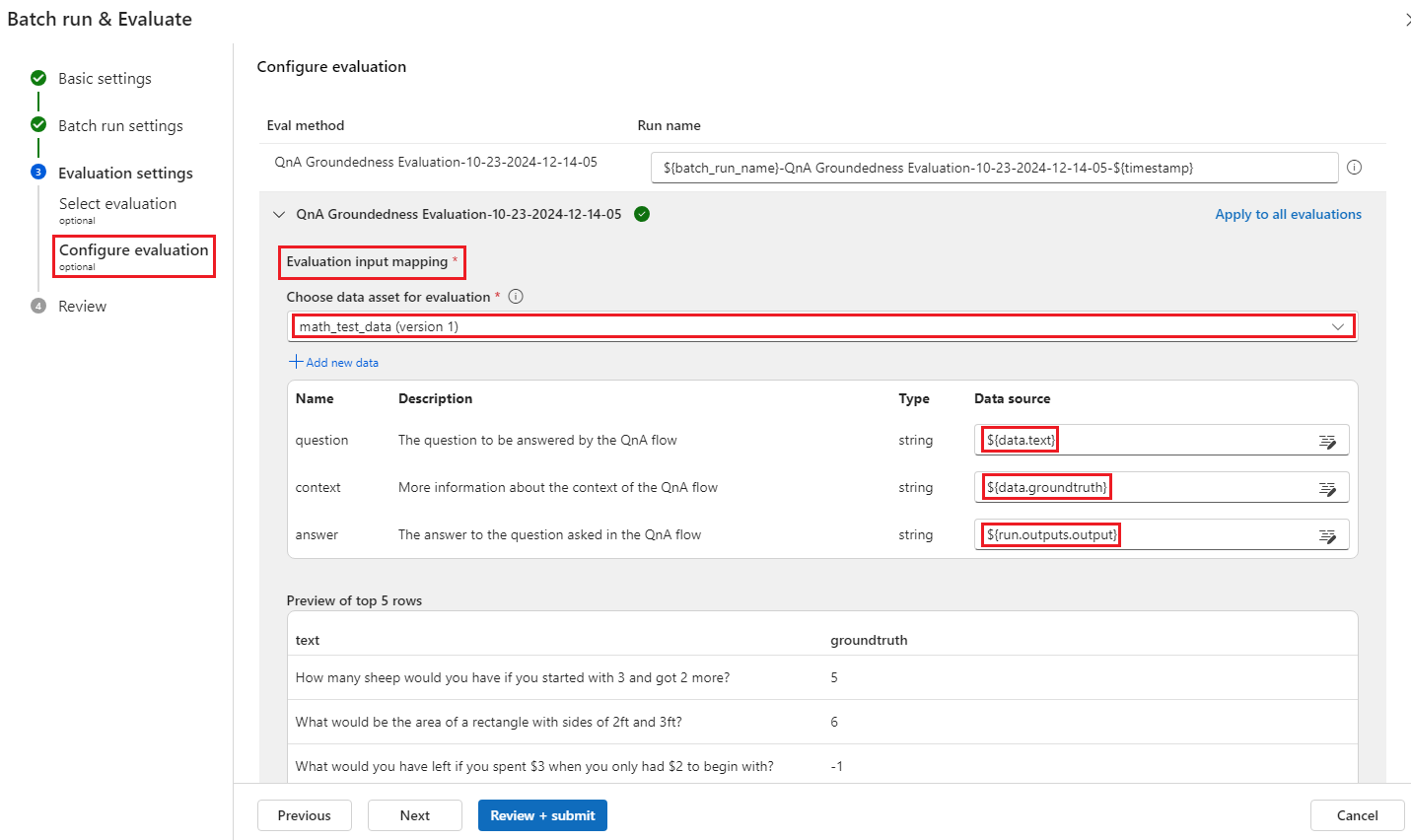
Important
평가 흐름에 LLM 노드가 있거나 자격 증명 또는 기타 키를 사용하기 위해 연결이 필요한 경우 평가 흐름을 사용할 수 있도록 이 화면의 연결 섹션에 연결 데이터를 입력해야 합니다.
검토 + 제출을 선택한 다음 제출을 선택하여 평가 흐름을 실행합니다.
평가 흐름이 완료되면 일괄 처리 보기 실행을>선택하여 평가한 흐름의 맨 위에 있는 최신 일괄 처리 실행 출력 보기를 선택하여 인스턴스 수준 점수를 볼 수 있습니다. 추가 관련 결과 드롭다운 목록에서 평가 실행을 선택하여 각 데이터 행의 성적을 확인합니다.