기계 학습 파이프라인에서 Apache Spark(Azure Synapse Analytics에서 제공)를 사용하는 방법(사용되지 않음)
적용 대상:  Python SDK azureml v1
Python SDK azureml v1
Warning
Python SDK v1에서 사용할 수 있는 Azure Machine Learning과의 Azure Synapse Analytics 통합은 더 이상 사용되지 않습니다. 사용자는 Azure Machine Learning에 등록된 Synapse 작업 영역을 연결된 서비스로 계속 사용할 수 있습니다. 그러나 새 Synapse 작업 영역은 더 이상 연결된 서비스로 Azure Machine Learning에 등록할 수 없습니다. CLI v2 및 Python SDK v2에서 사용할 수 있는 서버리스 Spark 컴퓨팅 및 연결된 Synapse Spark 풀을 사용하는 것이 좋습니다. 자세한 내용은 https://aka.ms/aml-spark을 참조하세요.
이 문서에서는 Azure Synapse Analytics에서 제공하는 Apache Spark 풀을 Azure Machine Learning 파이프라인의 데이터 준비 단계에 대한 컴퓨팅 대상으로 사용하는 방법에 대해 알아봅니다. 단일 파이프라인이 특정 단계에 적합한 계산 리소스(예: 데이터 준비 또는 학습)를 사용할 수 있는 방법을 알아봅니다. Spark 단계를 위해 데이터를 준비하는 방법과 다음 단계로 전달하는 방법도 알아봅니다.
필수 조건
모든 파이프라인 리소스를 수용할 Azure Machine Learning 작업 영역을 만듭니다.
Azure Machine Learning SDK를 설치하거나 SDK가 이미 설치된 Azure Machine Learning 컴퓨팅 인스턴스를 사용하도록 개발 환경을 구성합니다.
Azure Synapse Analytics 작업 영역 및 Apache Spark 풀을 만듭니다. 자세한 내용은 빠른 시작: Synapse Studio를 사용하여 서버리스 Apache Spark 풀 만들기를 참조하세요.
Azure Machine Learning 작업 영역과 Azure Synapse Analytics 작업 영역 연결
Azure Synapse Analytics 작업 영역에서 Apache Spark 풀을 만들고 관리합니다. Apache Spark 풀을 Azure Machine Learning 작업 영역과 통합하려면 Azure Synapse Analytics 작업 영역에 연결해야 합니다. Azure Machine Learning 작업 영역과 Azure Synapse Analytics 작업 영역을 연결하면 다음을 통해 Apache Spark 풀을 연결할 수 있습니다.
나중에 설명한 대로 Python SDK
ARM(Azure Resource Manager) 템플릿 자세한 내용은 ARM 템플릿 예제를 참조하세요.
- 명령줄을 사용하여 ARM 템플릿을 따르고, 연결된 서비스를 추가하고, 이 코드 샘플을 사용하여 Apache Spark 풀을 연결할 수 있습니다.
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
Important
Synapse 작업 영역에 성공적으로 연결하려면 Synapse 작업 영역의 소유자 역할을 부여해야 합니다. Azure Portal에서 액세스를 확인합니다.
연결된 서비스는 생성 시 시스템 할당 SAI(관리 ID)를 가져옵니다. Spark 작업을 제출할 수 있도록 이 연결 서비스 SAI를 Synapse Studio의 "Synapse Apache Spark 관리자" 역할에 할당해야 합니다(Synapse Studio에서 Synapse RBAC 역할 할당을 관리하는 방법 참조).
또한 Azure Machine Learning 작업 영역의 사용자에게 리소스 관리의 Azure Portal에서 "기여자" 역할을 부여해야 합니다.
Azure Synapse Analytics 작업 영역과 Azure Machine Learning 작업 영역 간의 링크를 검색합니다.
이 코드는 작업 영역에서 연결된 서비스를 검색하는 방법을 보여 줍니다.
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
먼저 Workspace.from_config()은(는) config.json 파일의 구성을 사용하여 Azure Machine Learning 작업 영역에 액세스합니다. (자세한 내용은 작업 영역 구성 파일 만들기를 참조하세요.) 그런 다음, 코드는 작업 영역에서 사용할 수 있는 모든 연결된 서비스를 인쇄합니다. 마지막으로 LinkedService.get()이 'synapselink1'이라는 연결된 서비스를 검색합니다.
Azure Machine Learning에 대한 컴퓨팅 대상으로 Apache Spark 풀 연결
Apache Spark 풀을 사용하여 기계 학습 파이프라인의 단계를 수행하려면 다음 코드 샘플과 같이 파이프라인 단계에 대한 ComputeTarget으로 연결해야 합니다.
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
코드는 먼저 SynapseCompute를 구성합니다. linked_service 인수는 이전 단계에서 만들었거나 검색한 LinkedService 개체입니다. type 인수는 SynapseSpark여야 합니다. SynapseCompute.attach_configuration()의 pool_name 인수는 Azure Synapse Analytics 작업 영역에 있는 기존 풀의 인수와 일치해야 합니다. Azure Synapse Analytics 작업 영역에서 Apache Spark 풀을 만드는 방법에 대한 자세한 내용은 빠른 시작: Synapse Studio를 사용하여 서버리스 Apache Spark 풀 만들기를 참조하세요. attach_config 형식이 ComputeTargetAttachConfiguration입니다.
구성이 만들어지면 Workspace, ComputeTargetAttachConfiguration 값 및 기계 학습 작업 영역에서 계산을 참조할 이름을 전달하여 기계 학습 ComputeTarget을 생성합니다. ComputeTarget.attach()에 대한 호출은 비동기이므로 호출이 완료될 때까지 샘플이 차단됩니다.
연결된 Apache Spark 풀을 사용하는 SynapseSparkStep 만들기
Apache Spark 풀의 샘플 Notebook Spark 작업은 간단한 기계 학습 파이프라인을 정의합니다. 먼저 노트북은 이전 단계에서 정의된 synapse_compute에서 제공하는 데이터 준비 단계를 정의합니다. 그런 다음 Notebook은 학습에 더 적합한 컴퓨팅 대상에 의해 구동되는 학습 단계를 정의합니다. 샘플 Notebook은 Titanic 서바이벌 데이터베이스를 사용하여 데이터 입력 및 출력을 표시합니다. 실제로 데이터를 정리하거나 예측 모델을 만들지 않습니다. 이 샘플에는 실제로 학습이 포함되지 않으므로 학습 단계에서는 저렴한 CPU 기반 컴퓨팅 리소스를 사용합니다.
데이터는 표 형식의 데이터 또는 파일 집합을 포함할 수 있는 DatasetConsumptionConfig개의 개체를 통해 기계 학습 파이프라인으로 흐릅니다. 데이터는 종종 작업 영역의 데이터 저장소에 있는 Blob Storage의 파일에서 제공됩니다. 이 코드 샘플은 기계 학습 파이프라인에 대한 입력을 만드는 일반적인 코드를 보여 줍니다.
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
코드 샘플은 Titanic.csv 파일이 Blob Storage에 있다고 가정합니다. 이 코드에서는 TabularDataset 및 FileDataset로 파일을 읽는 방법을 보여 줍니다. 이 코드는 입력값을 복제하거나 단일 데이터 원본을 테이블 포함 리소스와 파일 모두로 해석하는 데 혼동을 줄 수 있기 때문에 데모용으로만 사용됩니다.
Important
FileDataset을(를) 입력으로 사용하려면 최소한 1.20.0의 azureml-core 버전이 필요합니다. 나중에 설명하는 것처럼 Environment 클래스를 사용하여 이를 지정할 수 있습니다. 단계가 완료되면 다음 코드 샘플과 같이 출력 데이터를 저장할 수 있습니다.
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
이 코드 샘플에서 datastore은(는) test라는 파일에 데이터를 저장합니다. 데이터는 기계 학습 작업 영역 내에서 registered_dataset라는 이름의 Dataset(으)로 사용할 수 있습니다.
데이터 외에도 파이프라인 단계는 단계별로 Python 종속성을 가질 수 있습니다. 또한 개별 SynapseSparkStep 개체는 정확한 Azure Synapse Apache Spark 구성을 지정할 수 있습니다. 이를 보여주기 위해 다음 코드 샘플은 azureml-core 패키지 버전이 1.20.0 이상이어야 한다고 지정합니다. 앞서 설명한 대로 FileDataset를 입력으로 사용하려면 azureml-core 패키지에 대한 이 요구 사항이 필요합니다.
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
이 코드는 Azure Machine Learning 파이프라인에서 단일 단계를 지정합니다. 이 코드의 environment 값은 특정 azureml-core 버전을 설정하며 코드는 필요에 따라 다른 conda 또는 pip 종속성을 추가할 수 있습니다.
SynapseSparkStep은(는) 로컬 컴퓨터에서 ./code 하위 디렉터리를 압축하고 업로드합니다. 해당 디렉토리는 컴퓨팅 서버에 다시 생성되고 단계는 해당 디렉토리에서 dataprep.py 스크립트를 실행합니다. 해당 단계의 inputs 및 outputs는 앞에서 설명한 step1_input1, step1_input2, step1_output 개체입니다. dataprep.py 스크립트 내에서 이러한 값에 액세스하는 가장 쉬운 방법은 명명된 arguments와 연결하는 것입니다.
SynapseSparkStep 생성자에 대한 다음 인수 집합은 Apache Spark를 제어합니다. compute_target은 이전에 컴퓨팅 대상으로 연결한 'link1-spark01'입니다. 다른 매개 변수는 사용하고자 하는 메모리 및 코어를 지정합니다.
샘플 노트북은 dataprep.py에 대해 이 코드를 사용합니다.
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
이 "데이터 준비" 스크립트는 실제 데이터 변환을 수행하지는 않지만 데이터를 검색하고, Spark 데이터 프레임으로 변환하고, 몇 가지 기본적인 Apache Spark 조작을 수행하는 방법을 보여 줍니다. Azure Machine Learning 스튜디오에서 출력을 찾으려면 다음 스크린샷과 같이 자식 작업을 열고, 출력 + 로그 탭을 선택하고, logs/azureml/driver/stdout 파일을 엽니다.
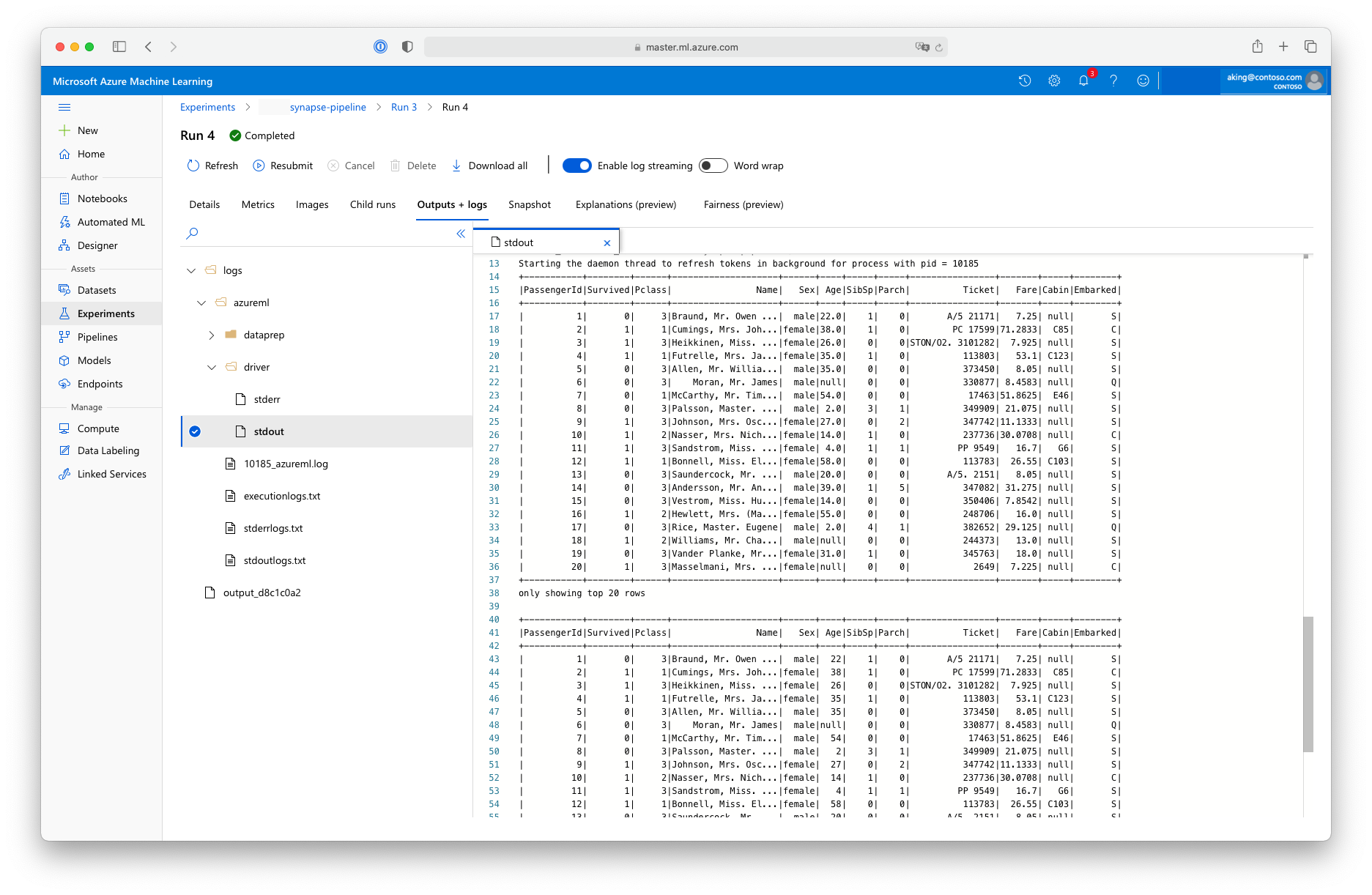
파이프라인에서 SynapseSparkStep 사용
다음 예제에서는 이전 섹션에서 만든 SynapseSparkStep의 출력을 사용합니다. 파이프라인의 다른 단계에는 고유한 환경이 있을 수 있으며 현재 작업에 적합한 다양한 컴퓨팅 리소스에서 실행될 수 있습니다. 샘플 노트북은 작은 CPU 클러스터에서 "학습 단계"를 실행합니다.
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
이 코드는 필요한 경우 새 컴퓨팅 리소스를 만듭니다. 그런 다음 step1_output 결과를 학습 단계에 대한 입력으로 변환합니다. as_download() 옵션은 데이터를 컴퓨팅 리소스로 이동하여 더 빠르게 액세스할 수 있음을 의미합니다. 데이터가 너무 커서 로컬 컴퓨팅 하드 드라이브에 맞지 않는 경우 as_mount() 옵션을 사용하여 FUSE 파일 시스템을 통해 데이터를 스트리밍해야 합니다. 이 두 번째 단계의 compute_target은 데이터 준비 단계에서 사용한 'link1-spark01' 리소스가 아니라 'cpucluster'입니다. 이 단계에서는 이전 단계에서 사용한 dataprep.py 스크립트 대신 간단한 train.py 스크립트를 사용합니다. 샘플 Notebook에는 train.py 스크립트에 대한 세부 정보가 있습니다.
모든 단계를 정의한 후 파이프라인을 만들고 실행할 수 있습니다.
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
이 코드는 Azure Synapse Analytics(step_1) 및 학습 단계(step_2)에 의해 제공되는 Apache Spark 풀의 데이터 준비 단계로 구성된 파이프라인을 만듭니다. Azure는 실행 그래프를 계산하는 단계 간의 데이터 종속성을 검사합니다. 이 경우 하나의 간단한 종속성만 있습니다. 여기서는 step2_input에는 반드시 step1_output이(가) 필요합니다.
pipeline.submit 호출은 필요한 경우 synapse-pipeline라는 Experiment를 만들고 그 안에서 Job을 비동기적으로 시작합니다. 파이프라인 내의 개별 단계는 이 주 작업의 자식 작업으로 실행되며 Studio의 실험 페이지에서 해당 단계를 모니터링하고 검토할 수 있습니다.