파이프라인에서 병렬 작업 사용
적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
이 문서에서는 CLI v2 및 Python SDK v2를 사용하여 Azure Machine Learning 파이프라인에서 병렬 작업을 실행하는 방법을 설명합니다. 병렬 작업은 강력한 다중 노드 컴퓨팅 클러스터에 반복 작업을 배포하여 작업 실행을 가속화합니다.
기계 학습 엔지니어에게는 항상 학습 또는 추론 작업에 대한 스케일링 요구 사항이 있습니다. 예를 들어 데이터 과학자가 판매 예측 모델을 학습하는 단일 스크립트를 제공하는 경우 기계 학습 엔지니어는 이 학습 작업을 각 개별 데이터 저장소에 적용해야 합니다. 이 스케일 아웃 프로세스의 과제에는 지연을 유발하는 긴 실행 시간과 작업을 계속 실행하기 위해 수동 개입이 필요한 예기치 않은 문제가 포함됩니다.
Azure Machine Learning 병렬 처리의 핵심 작업은 단일 직렬 작업을 미니 일괄 처리로 분할하고 이러한 미니 일괄 처리를 여러 컴퓨팅에 디스패치하여 병렬로 실행하는 것입니다. 병렬 작업은 엔드 투 엔드 실행 시간을 크게 줄이고 오류를 자동으로 처리합니다. Azure Machine Learning 병렬 작업을 사용하여 분할된 데이터를 기반으로 많은 모델을 학습하거나 대규모 일괄 처리 추론 작업을 가속화하는 것이 좋습니다.
예를 들어 큰 이미지 집합에서 개체 검색 모델을 실행하는 시나리오에서 Azure Machine Learning 병렬 작업을 사용하면 이미지를 쉽게 배포하여 특정 컴퓨팅 클러스터에서 사용자 지정 코드를 병렬로 실행할 수 있습니다. 병렬화를 통해 시간 비용을 대폭 절감할 수 있습니다. 또한 Azure Machine Learning 병렬 작업은 프로세스를 단순화하고 자동화하여 더 효율적으로 만들 수 있습니다.
필수 조건
- Azure Machine Learning 계정 및 작업 영역이 있습니다.
- Azure Machine Learning 파이프라인을 이해합니다.
- Azure CLI 및
ml확장을 설치합니다. 자세한 내용은 CLI(v2) 설치, 설정 및 사용을 참조하세요.az ml명령을 처음 실행하는 경우ml확장이 자동으로 설치됩니다. - CLI v2에서 Azure Machine Learning 파이프라인 및 구성 요소를 만들고 실행하는 방법을 이해합니다.
병렬 작업 단계를 사용하여 파이프라인 만들기 및 실행
Azure Machine Learning 병렬 작업은 파이프라인 작업의 한 단계로만 사용할 수 있습니다.
다음 예제는 Azure Machine Learning 예제 리포지토리의 파이프라인에서 병렬 작업을 사용하여 파이프라인 작업 실행에서 제공됩니다.
병렬 처리 준비
이 병렬 작업 단계에는 준비가 필요합니다. 미리 정의된 함수를 구현하는 항목 스크립트가 필요합니다. 또한 병렬 작업 정의에서 다음과 같은 특성을 설정해야 합니다.
- 입력 데이터를 정의하고 바인딩합니다.
- 데이터 분할 메서드를 설정합니다.
- 컴퓨팅 리소스를 구성합니다.
- 항목 스크립트를 호출합니다.
다음 섹션에서는 병렬 작업을 준비하는 방법을 설명합니다.
입력 및 데이터 분할 설정 선언
병렬 작업을 수행하려면 하나의 주요 입력을 분할하고 병렬로 처리해야 합니다. 주요 입력 데이터 형식은 테이블 형식 데이터 또는 파일 목록일 수 있습니다.
데이터 형식에 따라 입력 형식, 입력 모드, 데이터 분할 메서드가 다릅니다. 다음 표에서는 옵션에 대해 설명합니다.
| 데이터 형식 | Input type | 입력 모드 | 데이터 분할 방법 |
|---|---|---|---|
| 파일 목록 | mltable 또는 uri_folder |
ro_mount 또는 download |
크기(파일 수) 또는 파티션별 |
| 표 형식 데이터 | mltable |
direct |
크기(예상 물리적 크기) 또는 파티션별 |
참고 항목
테이블 형식 mltable을 주요 입력 데이터로 사용하는 경우 다음을 수행해야 합니다.
- 이 conda 파일의 9번 줄과 같이 사용자 환경에
mltable라이브러리를 설치합니다. transformations: - read_delimited:섹션이 채워진 지정된 경로 아래에 MLTable 사양 파일이 있어야 합니다. 예제는 데이터 자산 만들기 및 관리를 참조하세요.
병렬 작업 YAML 또는 Python의 input_data 특성으로 주 입력 데이터를 선언하고, ${{inputs.<input name>}}을 사용하여 병렬 작업의 정의된 input을 사용하여 데이터를 바인딩할 수 있습니다. 그런 다음, 데이터 분할 메서드에 따라 주 입력에 대한 데이터 분할 특성을 정의합니다.
| 데이터 분할 방법 | Attribute name | 특성 유형 | 작업 예 |
|---|---|---|---|
| 크기별 | mini_batch_size |
string | 홍채 일괄 처리 예측 |
| 파티션별 | partition_keys |
문자열 목록 | 오렌지 주스 판매 예측 |
병렬 처리를 위한 컴퓨팅 리소스 구성
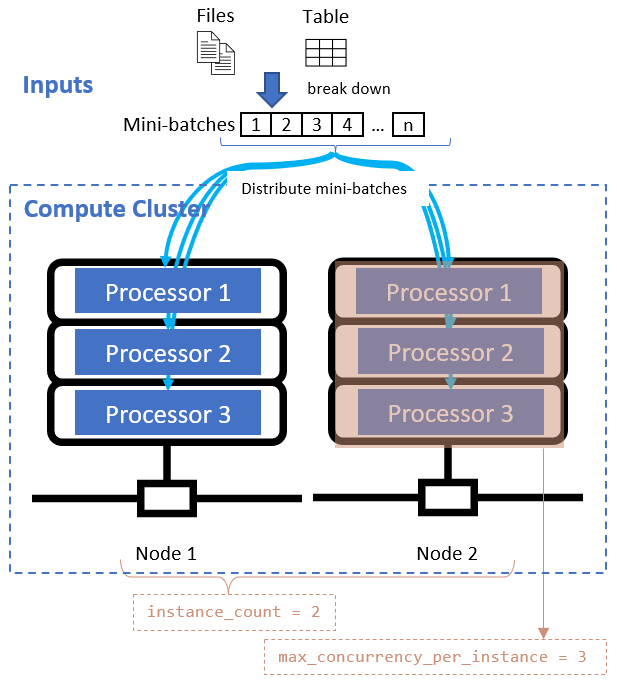
데이터 분할 특성을 정의한 후에는 instance_count 및 max_concurrency_per_instance 특성을 설정하여 병렬화에 대한 컴퓨팅 리소스를 구성합니다.
| 특성 이름 | Type | 설명 | 기본값 |
|---|---|---|---|
instance_count |
정수 | 작업에 사용할 노드 수입니다. | 1 |
max_concurrency_per_instance |
정수 | 각 노드의 프로세서 수입니다. | GPU 컴퓨팅의 경우: 1. CPU 컴퓨팅의 경우: 코어 수. |
이러한 특성은 다음 다이어그램과 같이 지정된 컴퓨팅 클러스터와 함께 작동합니다.
항목 스크립트 호출
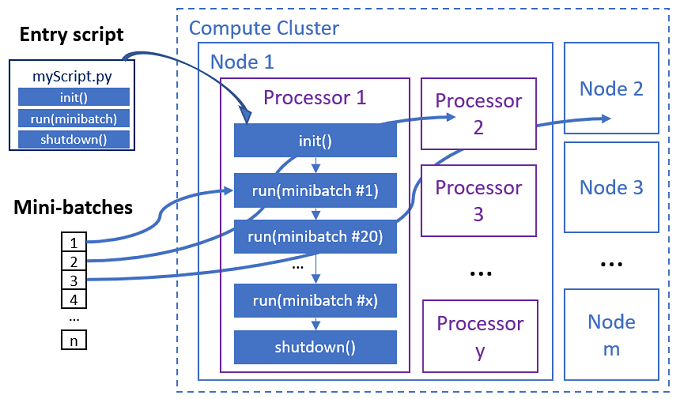
항목 스크립트는 사용자 지정 코드를 사용하여 다음과 같은 세 가지 미리 정의된 함수를 구현하는 단일 Python 파일입니다.
| 함수 이름 | Required | Description | Input | 반환 값 |
|---|---|---|---|---|
Init() |
Y | 미니 일괄 처리 실행을 시작하기 전의 일반적인 준비입니다. 예를 들어 이 함수를 사용하여 모델을 전역 개체로 로드합니다. | -- | -- |
Run(mini_batch) |
Y | 미니 일괄 처리에 대한 기본 실행 논리를 구현합니다. | mini_batch는 입력 데이터가 테이블 형식 데이터인 경우 pandas 데이터 프레임이고, 입력 데이터가 디렉터리인 경우 파일 경로 목록입니다. |
데이터 프레임, 목록 또는 튜플입니다. |
Shutdown() |
N | 풀에 컴퓨팅을 반환하기 전에 사용자 지정 정리를 수행하는 선택적 함수입니다. | -- | -- |
Important
Init() 또는 Run(mini_batch) 함수에서 인수를 구문 분석할 때 예외를 방지하려면 parse_args 대신 parse_known_args를 사용합니다. 인수 파서가 있는 항목 스크립트는 iris_score 예제를 참조하세요.
Important
Run(mini_batch) 함수에는 데이터 프레임, 목록 또는 튜플 항목의 반환이 필요합니다. 병렬 작업은 이 반환 수를 사용하여 해당 미니 일괄 처리에서 성공 항목을 측정합니다. 미니 일괄 처리 수는 모든 항목이 처리된 경우 반환 목록 수와 같아야 합니다.
병렬 작업은 다음 다이어그램과 같이 각 프로세서에서 함수를 실행합니다.
다음 항목 스크립트 예제를 참조하세요.
항목 스크립트를 호출하려면 병렬 작업 정의에서 다음 두 특성을 설정합니다.
| 특성 이름 | Type | 설명 |
|---|---|---|
code |
string | 작업에 업로드하고 사용할 소스 코드 디렉터리의 로컬 경로입니다. |
entry_script |
string | 미리 정의된 병렬 함수의 구현을 포함하는 Python 파일입니다. |
병렬 작업 단계 예제
다음 병렬 작업 단계에서는 입력 형식, 모드, 데이터 분할 메서드를 선언하고, 입력을 바인딩하고, 컴퓨팅을 구성하고, 항목 스크립트를 호출합니다.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
자동화 설정 고려
Azure Machine Learning 병렬 작업은 수동 개입 없이 작업을 자동으로 제어할 수 있는 많은 선택적 설정을 노출합니다. 다음 표에서는 이러한 설정에 대해 설명합니다.
| 키 | 형식 | 설명 | 허용된 값 | Default value | 특성 또는 프로그램 인수에서 설정 |
|---|---|---|---|---|---|
mini_batch_error_threshold |
정수 | 이 병렬 작업에서 무시하지 못한 미니 일괄 처리의 수입니다. 실패한 미니 일괄 처리 수가 이 임계값보다 크면 병렬 작업이 실패한 것으로 표시됩니다. 미니 일괄 처리는 다음과 같은 경우 실패한 것으로 표시됩니다. - run()의 반환 수가 미니 일괄 처리 입력 수보다 적습니다.- 예외가 사용자 지정 run() 코드에서 확인됩니다. |
[-1, int.max] |
-1은 실패한 모든 미니 일괄 처리 무시를 의미합니다. |
특성 mini_batch_error_threshold |
mini_batch_max_retries |
정수 | 미니 일괄 처리가 실패하거나 시간이 초과된 경우 재시도 횟수입니다. 모든 재시도에 실패하면 미니 일괄 처리는 mini_batch_error_threshold 계산에 따라 실패한 것으로 표시됩니다. |
[0, int.max] |
2 |
특성 retry_settings.max_retries |
mini_batch_timeout |
정수 | 사용자 지정 run() 함수를 실행하기 위한 시간 제한(초)입니다. 실행 시간이 이 임계값보다 높은 경우 미니 일괄 처리가 중단되고 다시 시도를 트리거하지 못한 것으로 표시됩니다. |
(0, 259200] |
60 |
특성 retry_settings.timeout |
item_error_threshold |
정수 | 실패한 항목의 임계값입니다. 실패한 항목은 각 미니 일괄 처리의 입력과 반환 간의 숫자 차이로 계산됩니다. 실패한 항목의 합계가 이 임계값보다 높으면 병렬 작업이 실패한 것으로 표시됩니다. | [-1, int.max] |
-1은 병렬 작업 중 모든 오류를 무시함을 의미합니다. |
프로그램 인수--error_threshold |
allowed_failed_percent |
정수 | mini_batch_error_threshold와 유사하지만, 개수 대신 실패한 미니 일괄 처리의 백분율을 사용합니다. |
[0, 100] |
100 |
프로그램 인수--allowed_failed_percent |
overhead_timeout |
정수 | 각 미니 일괄 처리를 초기화하기 위한 시간 제한(초)입니다. 예를 들면, 미니 일괄 처리 데이터를 로드하여 run() 함수에 전달합니다. |
(0, 259200] |
600 |
프로그램 인수--task_overhead_timeout |
progress_update_timeout |
정수 | 미니 일괄 처리 실행 진행률을 모니터링하기 위한 시간 제한(초)입니다. 진행률 업데이트를 이 시간 제한 설정 내에 받지 못하면 병렬 작업이 실패한 것으로 표시됩니다. | (0, 259200] |
다른 설정으로 동적으로 계산 | 프로그램 인수--progress_update_timeout |
first_task_creation_timeout |
정수 | 작업 시작과 첫 번째 미니 일괄 처리 실행 사이의 시간을 모니터링하기 위한 시간 제한(초)입니다. | (0, 259200] |
600 |
프로그램 인수--first_task_creation_timeout |
logging_level |
string | 사용자 로그 파일에 덤프할 로그 수준입니다. | INFO, WARNING 또는 DEBUG |
INFO |
특성 logging_level |
append_row_to |
string | 각 미니 일괄 처리 실행의 반환을 모두 집계하여 이 파일에 출력합니다. ${{outputs.<output_name>}} 식을 사용하여 병렬 작업의 출력 중 하나를 참조할 수 있습니다. |
특성 task.append_row_to |
||
copy_logs_to_parent |
string | 작업 진행률, 개요, 로그를 부모 파이프라인 작업에 복사할지에 대한 부울 옵션입니다. | True 또는 False |
False |
프로그램 인수--copy_logs_to_parent |
resource_monitor_interval |
정수 | 노드 리소스 사용량(예: cpu 또는 메모리)을 logs/sys/perf 경로 아래의 로그 폴더에 덤프하는 시간 간격(초)입니다. 참고: 리소스 로그를 자주 덤프하면 실행 속도가 약간 느려집니다. 리소스 사용량 덤프를 중지하려면 이 값을 0으로 설정합니다. |
[0, int.max] |
600 |
프로그램 인수--resource_monitor_interval |
다음 샘플 코드는 이러한 설정을 업데이트합니다.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
병렬 작업 단계를 사용하여 파이프라인 만들기
다음 예제에서는 병렬 작업 단계를 인라인으로 사용하여 전체 파이프라인 작업을 보여 줍니다.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
파이프라인 작업 제출
az ml job create CLI 명령을 사용하여 병렬 단계로 파이프라인 작업을 제출합니다.
az ml job create --file pipeline.yml
스튜디오 UI에서 병렬 단계 확인
파이프라인 작업을 제출한 후 SDK 또는 CLI 위젯은 Azure Machine Learning 스튜디오 UI의 파이프라인 그래프에 대한 웹 URL 링크를 제공합니다.
병렬 작업 결과를 보려면 파이프라인 그래프에서 병렬 단계를 두 번 클릭하고, 세부 정보 패널에서 설정 탭을 선택하고, 실행 설정을 확장한 다음, 병렬 섹션을 확장합니다.

병렬 작업 실패를 디버그하려면 출력 + 로그 탭을 선택하고, 로그 폴더를 확장하고, job_result.txt를 확인하여 병렬 작업이 실패한 이유를 이해합니다. 병렬 작업의 로깅 구조에 대한 자세한 내용은 동일한 폴더의 readme.txt를 참조하세요.
