자동화된 Machine Learning 실험 결과 평가
이 문서에서는 자동화된 ML(자동화된 Machine Learning) 실험으로 학습한 모델을 평가하고 비교하는 방법에 대해 알아봅니다. 자동화된 ML 실험을 수행하는 과정에서 많은 작업이 만들어지고 각 작업은 모델을 만듭니다. 자동화된 ML은 각 모델에 대해 모델의 성능을 측정하는 데 도움이 되는 평가 메트릭과 차트를 생성합니다. 책임 있는 AI 대시보드를 추가로 생성하여 기본적으로 권장되는 최상의 모델에 대한 전체적인 평가 및 디버깅을 수행할 수 있습니다. 여기에는 모델 설명, 공정성 및 성능 탐색기, 데이터 탐색기, 모델 오류 분석과 같은 인사이트가 포함됩니다. 책임 있는 AI 대시보드를 생성하는 방법에 대해 자세히 알아봅니다.
예를 들어 자동화된 ML은 실험 유형에 따라 다음과 같은 차트를 생성합니다.
| 분류 | 회귀/예측 |
|---|---|
| 혼동 행렬 | 잔차 히스토그램 |
| ROC(수신자 조작 특성) 곡선 | 예측 대 실제 |
| PR(정밀도-재현율) 곡선 | 예측 기간 |
| 리프트 곡선 | |
| 누적 이득 곡선 | |
| 보정 곡선 |
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 미리 보기 버전은 서비스 수준 계약 없이 제공되며 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
필수 구성 요소
- Azure 구독 (Azure를 구독하고 있지 않은 경우 시작하기 전에 체험 계정을 만듭니다.)
- Azure Machine Learning 실험은 다음 중 하나를 사용하여 만듭니다.
작업 결과 보기
자동화된 ML 실험을 완료한 후 다음을 통해 작업 기록을 찾을 수 있습니다.
- Azure Machine Learning 스튜디오를 사용하는 브라우저
- JobDetails Jupyter 위젯을 사용하는 Jupyter Notebook
다음 단계와 비디오에서는 스튜디오에서 실행 기록과 모델 평가 메트릭 및 차트를 보는 방법을 알려줍니다.
- 스튜디오에 로그인하고 작업 영역으로 이동합니다.
- 왼쪽 메뉴에서 작업을 선택합니다.
- 실험 목록에서 해당 실험을 선택합니다.
- 페이지 아래쪽의 테이블에서 자동 ML 작업을 선택합니다.
- 모델 탭에서 평가하려는 모델의 알고리즘 이름을 선택합니다.
- 메트릭 탭에서 왼쪽의 확인란을 사용하여 메트릭 및 차트를 봅니다.
분류 메트릭
자동화된 ML은 실험에 대해 생성된 각 분류 모델의 성능 메트릭을 계산합니다. 이러한 메트릭은 Scikit-learn 구현을 기반으로 합니다.
많은 분류 메트릭이 두 클래스에서 이진 분류로 정의되고 클래스 전체에 대한 평균을 계산하여 다중 클래스 분류에 대한 하나의 점수를 구해야 합니다. Scikit-learn은 여러 가지 평균 계산 방법을 제공하며 여기에는 자동화된 ML에서 제공하는 macro, micro 및 weighted의 세 가지가 포함됩니다.
- Macro - 각 클래스의 메트릭을 계산하여 가중치가 적용되지 않은 평균을 가져옵니다.
- Micro - 진양성, 가음성, 가양성의 총 개수를 세어 전역으로 메트릭을 계산합니다(클래스와 무관).
- Weighted - 각 클래스의 메트릭을 계산하여 클래스별 샘플 수에 기준한 가중 평균을 가져옵니다.
각 평균 계산 방법은 나름의 이점이 있지만 적절한 방법을 선택함에 있어 한 가지 공통 고려 사항은 클래스 불균형입니다. 클래스의 샘플 수가 각기 다른 경우 비중이 적은 클래스에 비중이 큰 클래스와 동일한 가중치를 부여하는 매크로 평균을 사용하는 것이 더 유용할 수가 있습니다. 자동화된 ML에서 이진 메트릭과 다중 클래스 메트릭 비교를 참조하여 자세히 알아봅니다.
다음 표는 실험에 대해 생성된 각 분류 모델에 대해서 자동화된 ML이 계산하는 모델 성능 메트릭을 요약하여 보여 줍니다. 자세한 내용은 각 메트릭의 계산 필드에 연결된 Scikit-learn 설명서를 참조하세요.
참고 항목
이미지 분류 모델의 메트릭에 대한 자세한 내용은 이미지 메트릭 섹션을 참조하세요.
| 메트릭 | 설명 | 계산 |
|---|---|---|
| AUC | AUC는 수신자 조작 특성 곡선 아래 면적입니다. 목표: 1에 가까울수록 좋음 범위: [0, 1] 지원되는 메트릭 이름에는 다음이 포함됩니다. AUC_macro, 각 클래스에 대한 AUC의 산술 평균입니다.AUC_micro, 진양성, 가음성, 가양성의 총 개수를 세어 계산됩니다. AUC_weighted, 각 클래스의 실제 인스턴스 수를 가중치로 적용하여 계산된 각 클래스에 대한 점수의 산술 평균입니다. AUC_binary, 하나의 특정 클래스를 true 클래스로 처리하고 다른 모든 클래스를 false 클래스로 결합한 AUC 값입니다. |
계산 |
| accuracy | Accuracy(정확도)는 실제 클래스 레이블과 정확히 일치하는 예측 비율입니다. 목표: 1에 가까울수록 좋음 범위: [0, 1] |
계산 |
| average_precision | Average precision(평균 정밀도)은 정밀도-재현율 곡선을 이전 임계값에서의 재현율 증가를 가중치로 사용하여 계산한 각 임계값에서 도달된 정밀도의 가중 평균으로 요약합니다. 목표: 1에 가까울수록 좋음 범위: [0, 1] 지원되는 메트릭 이름에는 다음이 포함됩니다. average_precision_score_macro, 각 클래스의 평균 정밀도 점수의 산술 평균입니다.average_precision_score_micro, 진양성, 가음성, 가양성의 총 개수를 세어 계산됩니다.average_precision_score_weighted, 각 클래스의 실제 인스턴스 수를 가중치로 적용하여 계산된 각 클래스의 평균 정밀도 점수의 산술 평균입니다. average_precision_score_binary, 하나의 특정 클래스를 true 클래스로 처리하고 다른 모든 클래스를 false 클래스로 결합한 평균 정밀도 값입니다. |
계산 |
| balanced_accuracy | Balanced accuracy(균형 정확도)는 각 클래스 재현율의 산술 평균입니다. 목표: 1에 가까울수록 좋음 범위: [0, 1] |
계산 |
| f1_score | F1 score(F1 점수)는 정밀도 및 재현율의 조화 평균입니다. 가양성 및 가음성 모두에 대한 균형 측정값입니다. 그러나 진음성은 고려하지 않습니다. 목표: 1에 가까울수록 좋음 범위: [0, 1] 지원되는 메트릭 이름에는 다음이 포함됩니다. f1_score_macro: 각 클래스에 대한 F1 점수의 산술 평균입니다. f1_score_micro: 진양성, 가음성, 가양성의 총 개수를 세어 계산됩니다. f1_score_weighted: 각 클래스에 대한 F1 점수의 클래스 빈도에 따른 가중 평균입니다. f1_score_binary, 하나의 특정 클래스를 true 클래스로 처리하고 다른 모든 클래스를 false 클래스로 결합한 f1 값입니다. |
계산 |
| log_loss | 이것은 (다항) 로지스틱 회귀와 그 확장(예: 신경망)에 사용되는 손실 함수로, 확률적 분류자의 예측이 주어진 경우 실제 레이블의 음의 로그 유사도로 정의됩니다. 목표: 0에 가까울수록 좋음 범위: [0, inf) |
계산 |
| norm_macro_recall | Normalized macro recall(정규화된 매크로 재현율)은 매크로 평균이면서 정규화되어 있는 재현율이므로, 임의 성능 점수는 0이고 완벽 성능 점수는 1이 됩니다. 목표: 1에 가까울수록 좋음 범위: [0, 1] |
(recall_score_macro - R) / (1 - R) 여기서 R은 임의 예측에 대해 예상되는 recall_score_macro값입니다.이진 분류의 경우 R = 0.5입니다. R = (1 / C) C-클래스 분류 문제의 경우입니다. |
| matthews_correlation | Matthews 상관(Matthews correlation) 계수는 정확도의 균형 측정값으로서, 한 클래스에 다른 클래스보다 훨씬 더 많은 샘플이 포함된 경우에도 사용할 수 있습니다. 계수 1은 완벽 예측, 0은 임의 예측, -1은 역예측을 나타냅니다. 목표: 1에 가까울수록 좋음 범위: [-1, 1] |
계산 |
| 자릿수 | Precision(정밀도)은 음성 샘플을 양성으로 레이블을 지정하지 않도록 하는 모델의 기능입니다. 목표: 1에 가까울수록 좋음 범위: [0, 1] 지원되는 메트릭 이름에는 다음이 포함됩니다. precision_score_macro, 각 클래스에 대한 정밀도의 산술 평균입니다. precision_score_micro, 진양성과 가양성의 총 개수를 세어 전역적으로 계산됩니다. precision_score_weighted, 각 클래스의 실제 인스턴스 수를 가중치로 적용하여 계산된 각 클래스에 대한 정밀도의 산술 평균입니다. precision_score_binary, 하나의 특정 클래스를 true 클래스로 처리하고 다른 모든 클래스를 false 클래스로 결합한 정밀도 값입니다. |
계산 |
| 재현율 | Recall(재현율)은 양성 샘플 모두를 검색하는 모델의 기능입니다. 목표: 1에 가까울수록 좋음 범위: [0, 1] 지원되는 메트릭 이름에는 다음이 포함됩니다. recall_score_macro: 각 클래스에 대한 재현율의 산술 평균입니다. recall_score_micro: 진양성, 가음성, 가양성의 총 개수를 세어 전역적으로 계산됩니다.recall_score_weighted: 각 클래스의 실제 인스턴스 수를 가중치로 적용하여 계산된 각 클래스에 대한 재현율의 산술 평균입니다. recall_score_binary, 하나의 특정 클래스를 true 클래스로 처리하고 다른 모든 클래스를 false 클래스로 결합한 재현율 값입니다. |
계산 |
| weighted_accuracy | Weighted accuracy(가중치가 적용된 정확도)는 각 샘플에 동일한 클래스에 속하는 샘플의 총 수로 가중치가 적용된 정확도입니다. 목표: 1에 가까울수록 좋음 범위: [0, 1] |
계산 |
이진 및 다중 클래스 분류 메트릭
자동화된 ML은 데이터가 이진인지 자동으로 검색하고, true 클래스를 지정하여 데이터를 다중 클래스인 경우에도 사용자가 이진 분류 메트릭을 활성화할 수 있도록 합니다. 데이터 세트에 두 개 이상의 클래스가 있는 경우 다중 클래스 분류 메트릭이 보고됩니다. 이진 분류 메트릭은 데이터가 이진인 경우에만 보고됩니다.
다중 클래스 분류 메트릭은 다중 클래스 분류를 위한 것입니다. 예상대로 이러한 메트릭은 이진 데이터 세트에 적용될 때 클래스를 true 클래스로 처리하지 않습니다. 명확하게 다중 클래스용인 메트릭은 micro, macro 또는 weighted가 접미사로 붙습니다. 이러한 예로 average_precision_score, f1_score, precision_score, recall_score 및 AUC가 있습니다. 예를 들어, tp / (tp + fn)으로 재현율을 계산하는 대신 다중 클래스 평균 재현율(micro, macro 또는 weighted)은 이진 분류 데이터 세트의 두 클래스에 대한 평균입니다. 이는 true 클래스와 false 클래스에 대해 개별적으로 재현율을 계산하고 나서 둘의 평균을 구하는 것과 같습니다.
뿐만 아니라 이진 분류의 자동 검색이 지원되기는 하지만 항상 true 클래스를 수동으로 지정하여 이진 분류 메트릭이 올바른 클래스에 대해 계산되도록 하는 것이 좋습니다.
데이터 세트 자체가 다중 클래스일 때 이진 분류 데이터 세트에 대한 메트릭을 활성화하려는 경우 사용자가 true 클래스로 처리할 클래스를 지정하기만 하면 이러한 메트릭이 계산됩니다.
혼동 행렬
혼동 행렬은 기계 학습 모델이 분류 모델에 대한 예측에서 체계적인 오차를 만드는 방법에 대한 시각적 정보를 제공합니다. 이름에서 "혼동"이라는 단어는 모델이 "혼동되거나" 잘못된 레이블이 붙은 샘플에서 유래합니다. 혼동 행렬의 행 i 및 열 j의 셀에는 C_i 클래스에 속하고 모델에 의해 C_j 클래스로 분류된 평가 데이터 세트의 샘플 수가 포함됩니다.
스튜디오에서 색이 더 진한 셀은 샘플 개수가 더 많음을 나타냅니다. 드롭다운에서 정규화됨 보기를 선택하면 각 행렬 행을 정규화하여 C_j 클래스로 예측되는 C_i 클래스의 백분율을 보여 줍니다. 기본 행 보기의 이점은 불균형 데이터 세트에서의 일반적인 문제인 실제 클래스 분포의 불균형으로 인해 모델이 비중이 적은 클래스의 샘플을 잘못 분류하였는지의 여부를 확인할 수 있다는 것입니다.
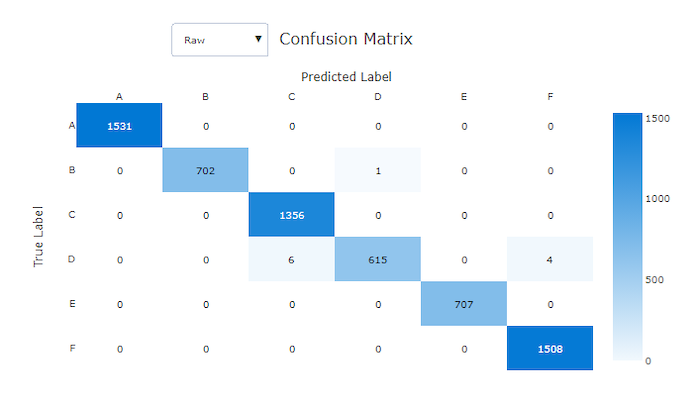
좋은 모델의 혼동 행렬은 대부분의 샘플이 대각선에 있습니다.
좋은 모델의 혼동 행렬
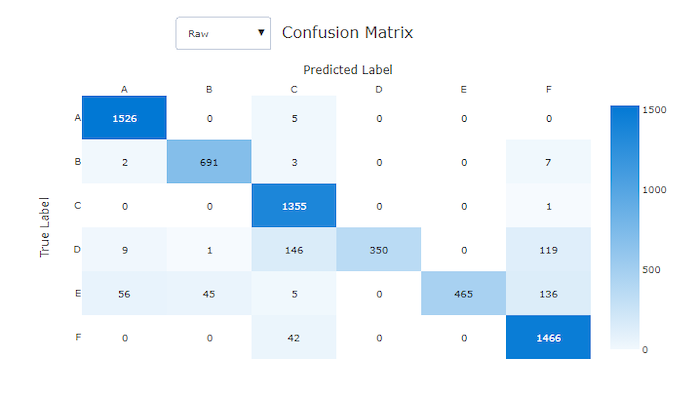
나쁜 모델의 혼동 행렬
ROC 곡선
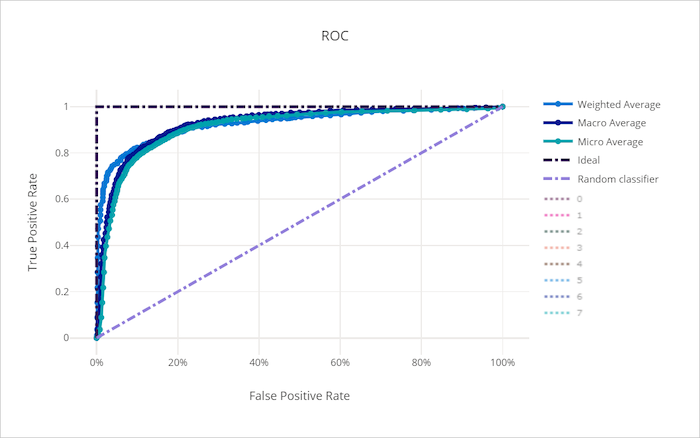
ROC(수신자 조작 특성) 곡선은 의사 결정 임계값의 변화에 따른 TPR(진양성 비율)과 FPR(가양성 비율) 간의 관계를 표시합니다. 클래스 불균형이 심한 데이터 세트에 대해 모델을 학습시키는 경우에는 ROC 곡선이 덜 유용할 수 있는데 이는 비중이 큰 클래스가 비중이 적은 클래스의 기여를 무산시킬 수 있기 때문입니다.
AUC(곡선 아래 면적)는 올바르게 분류된 샘플의 비율로 해석할 수 있습니다. 좀 더 정확하게 말하자면, AUC는 분류자가 임의로 선택된 음성 샘플보다 임의로 선택된 양성 샘플을 더 높은 우선순위로 지정할 가능성입니다. 곡선의 모양은 분류 임계값 또는 의사 결정 경계의 함수로서 TPR와 FPR 간의 관계에 대한 직관적 해석을 제공합니다.
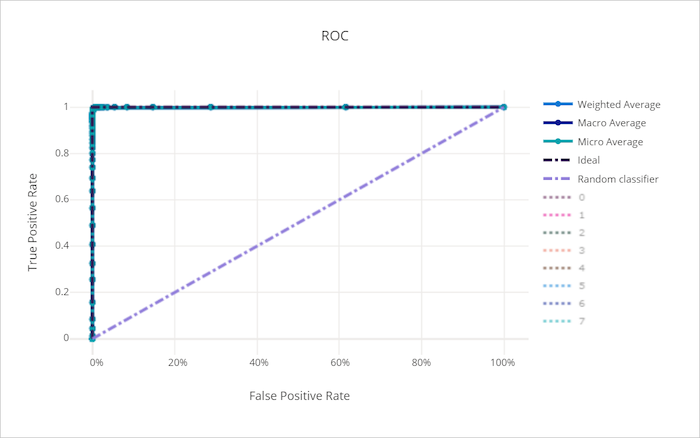
차트의 왼쪽 상단 모서리에 근접하는 곡선은 최상의 가능 모델인 100% TPR 및 0% FPR에 근접하고 있는 것입니다. 임의 모델은 왼쪽 아래 모서리에서 오른쪽 상단으로 y = x 선을 따라 ROC 곡선을 생성합니다. 임의 모델보다 나쁜 모델은 y = x 선 아래로 떨어지는 ROC 곡선을 갖습니다.
팁
분류 실험의 경우 자동화된 ML 모델에 대해 생성된 각각의 꺾은선형 차트를 이용하여 클래스별로 모델을 평가하거나 모든 클래스에 대해 평균화할 수 있습니다. 차트의 오른쪽에 있는 범례에서 클래스 레이블을 클릭하여 이러한 여러 보기 간에 전환이 가능합니다.
좋은 모델의 ROC 곡선
나쁜 모델의 ROC 곡선
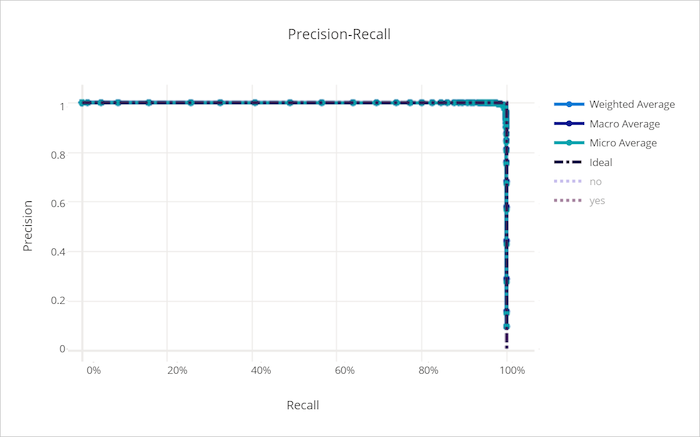
정밀도-재현율 곡선
정밀도-재현율 곡선은 의사 결정 임계값의 변화에 따른 정확도와 재현율 간의 관계를 표시합니다. 재현율은 양성 샘플 모두를 검색하는 모델의 기능이고 정밀도는 음성 샘플에 대해 양성으로 레이블을 지정하지 않도록 하는 모델의 기능입니다. 가음성 방지 또는 가양성 방지에 대한 상대적 중요도에 따라 재현율과 정밀도의 비중이 달라야 하므로 일부 비즈니스 문제가 발생할 수 있습니다.
팁
분류 실험의 경우 자동화된 ML 모델에 대해 생성된 각각의 꺾은선형 차트를 이용하여 클래스별로 모델을 평가하거나 모든 클래스에 대해 평균화할 수 있습니다. 차트의 오른쪽에 있는 범례에서 클래스 레이블을 클릭하여 이러한 여러 보기 간에 전환이 가능합니다.
좋은 모델의 정밀도-재현율 곡선
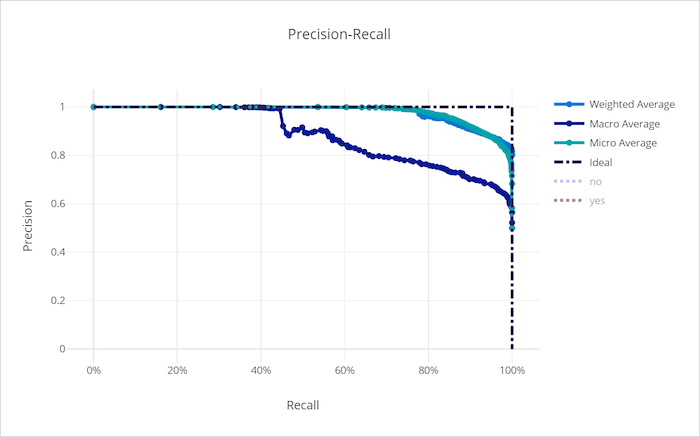
나쁜 모델의 정밀도-재현율 곡선
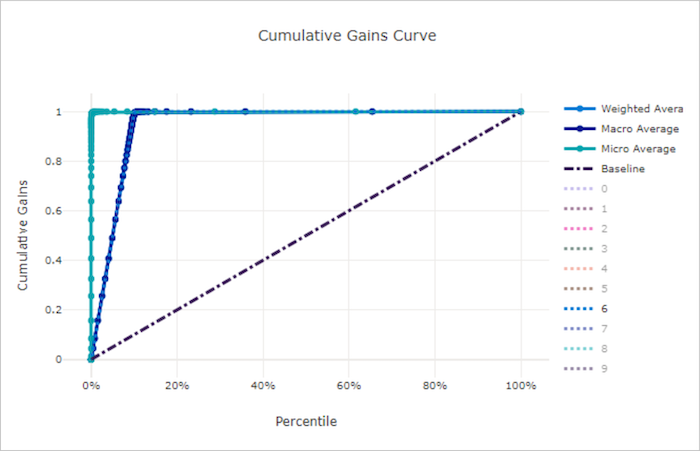
누적 이득 곡선
누적 이득 곡선은 예측된 확률 순으로 샘플을 고려하는 경우 고려되는 샘플 백분율의 함수로 올바르게 분류된 양성 샘플의 백분율을 표시합니다.
이득을 계산하려면 먼저 모든 샘플을 모델이 예측한 최고 확률부터 최저 확률까지 정렬합니다. 그런 다음 최고 신뢰도 예측의 x%를 구합니다. 해당 x%로 검색된 양성 샘플 수를 양성 샘플의 총 수로 나누어 이득을 계산합니다. 누적 이득은 양성 클래스에 속할 가능성이 가장 높은 일부 데이터를 고려할 때 검색하게 되는 양성 샘플의 백분율입니다.
완벽 모델은 모든 양성 샘플을 모든 음성 샘플 위에 순위를 두어 두 개의 직선 세그먼트로 구성된 누적 이득 곡선을 제공합니다. 첫 번째는 기울기가 1 / x인 (0, 0)에서 (x, 1)을 잇는 선으로, 여기에서 x는 양성 클래스에 속하는 샘플의 비율입니다(클래스가 분산된 경우 1 / num_classes). 두 번째는 (x, 1)에서 (1, 1)을 잇는 가로선입니다. 첫 번째 세그먼트에서 모든 양성 샘플이 올바르게 분류되고 누적 이득은 고려되는 샘플의 첫 x% 내에서 100%로 이동합니다.
기준 임의 모델은 y = x을 따르는 누적 이득 곡선을 가지며, 고려된 샘플 중 x%의 경우 총 양성 샘플 중 약 x%만 검색되었습니다. 균형 잡힌 데이터 세트에 대한 완벽 모델은 마이크로 평균 곡선과 누적 이득이 100%가 될 때까지 기울기가 num_classes이고 이후에는 데이터 백분율이 100이 될 때까지 수평인 매크로 평균선을 갖습니다.
팁
분류 실험의 경우 자동화된 ML 모델에 대해 생성된 각각의 꺾은선형 차트를 이용하여 클래스별로 모델을 평가하거나 모든 클래스에 대해 평균화할 수 있습니다. 차트의 오른쪽에 있는 범례에서 클래스 레이블을 클릭하여 이러한 여러 보기 간에 전환이 가능합니다.
좋은 모델의 누적 이득 곡선
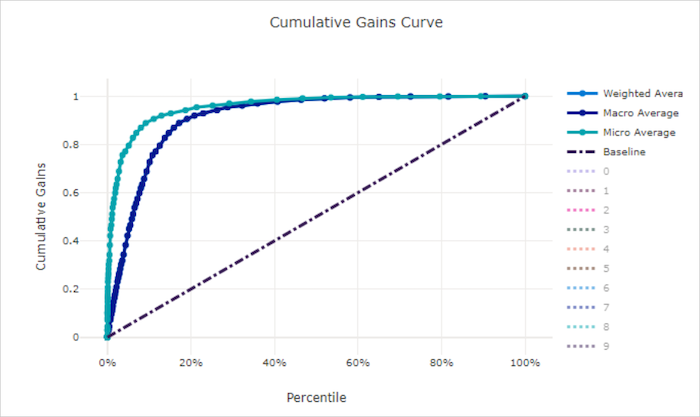
나쁜 모델의 누적 이득 곡선
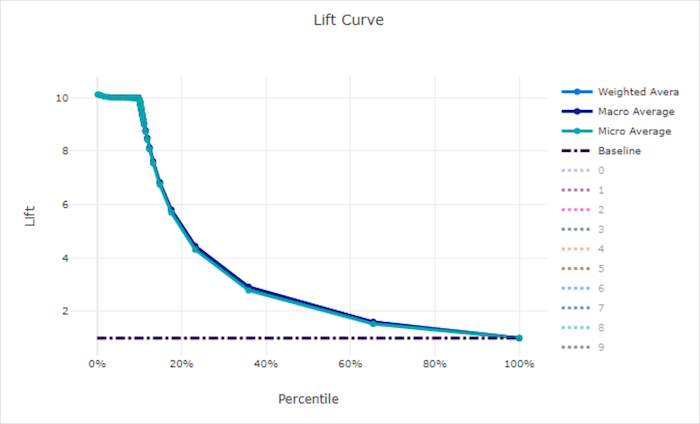
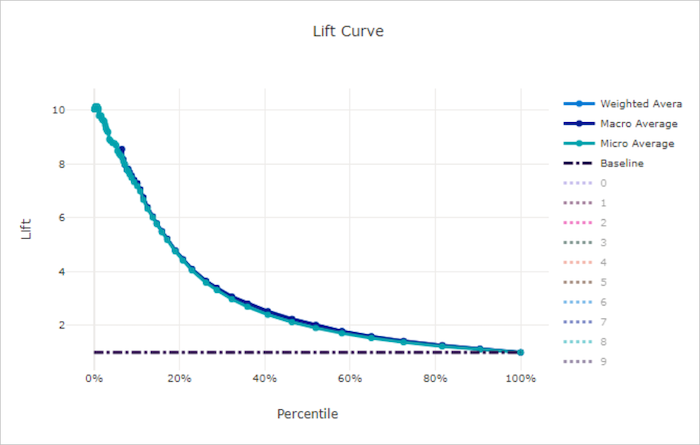
리프트 곡선
리프트 곡선은 임의 모델에 비하여 모델의 성능이 몇 배나 더 우수한지를 보여 줍니다. 리프트는 임의 모델의 누적 이득에 대한 누적 이득의 비율(항상 1)로 정의됩니다.
이러한 상대적 성능은 클래스의 수를 늘릴 때 분류가 더 어려워지는 점을 반영합니다. (임의 모델은 두 클래스를 사용하는 데이터 세트에 비해 10개 클래스를 사용하는 데이터 세트에서 더 높은 비율의 샘플을 잘못 예측)
기준 리프트 곡선은 y = 1인 선으로, 모델 성능이 임의 모델의 성능과 일치합니다. 일반적으로 좋은 모델의 리프트 곡선은 해당 차트에서 더 높고 x-축으로부터 더 멀어서 모델이 예측을 가장 신뢰할 수 있을 때 임의 예측보다 몇 배 더 성능이 좋다는 것을 보여 줍니다.
팁
분류 실험의 경우 자동화된 ML 모델에 대해 생성된 각각의 꺾은선형 차트를 이용하여 클래스별로 모델을 평가하거나 모든 클래스에 대해 평균화할 수 있습니다. 차트의 오른쪽에 있는 범례에서 클래스 레이블을 클릭하여 이러한 여러 보기 간에 전환이 가능합니다.
좋은 모델의 리프트 곡선
나쁜 모델의 리프트 곡선
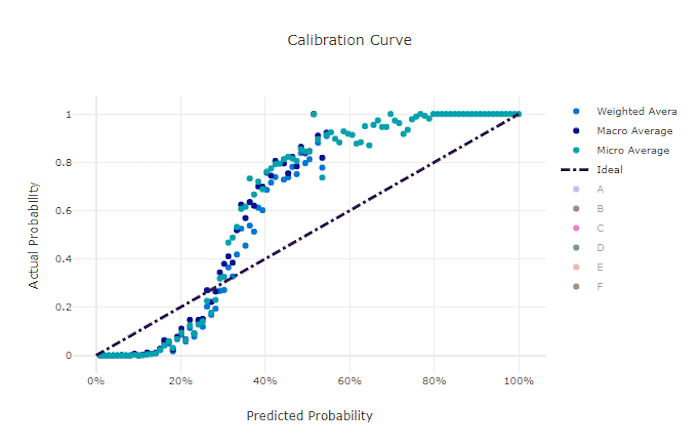
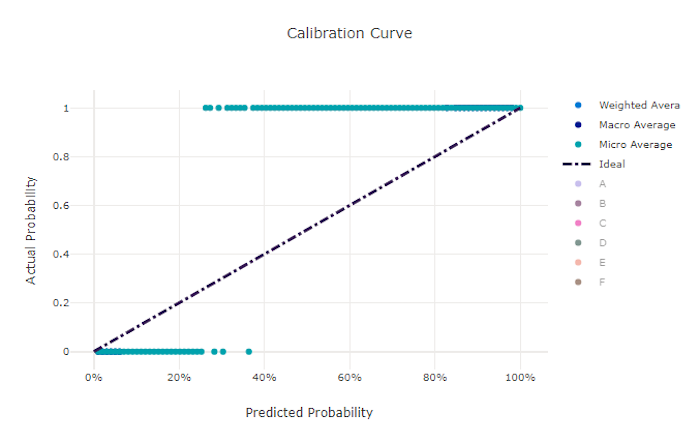
보정 곡선
보정 곡선은 각 신뢰도 수준에서 양성 샘플의 비율에 대한 모델의 예측 신뢰도를 표시합니다. 잘 보정된 모델은 100% 신뢰도를 할당하는 예측의 100%, 50% 신뢰도를 할당하는 예측의 50%, 20% 신뢰도를 할당하는 예측의 20% 등을 올바르게 분류합니다. 완벽하게 보정된 모델은 y = x 선을 따르는 보정 곡선을 가지며, 모델이 각 클래스에 속하는 확률을 완벽하게 예측합니다.
확신이 과도한 모델은 각 샘플의 클래스에 대해서는 불확실한 경우가 거의 없이 0과 1에 가깝게 확률을 과도하게 예측하고 보정 곡선은 뒤집어진 "S"와 유사하게 보입니다. 확신이 부족한 모델은 예측하는 클래스에 평균적으로 낮은 확률을 할당하고 관련된 보정 곡선은 "S"와 유사하게 보입니다. 보정 곡선은 올바르게 분류하는 모델의 기능이 아니라 예측에 대한 신뢰도를 올바르게 할당하는 기능을 나타냅니다. 모델이 낮은 신뢰도와 높은 불확실성을 올바르게 할당하면 나쁜 모델도 좋은 보정 곡선을 가질 수 있습니다.
참고 항목
보정 곡선은 샘플 수에 민감하므로 작은 유효성 검사 집합은 해석하기 어려울 수 있는 노이즈가 있는 결과를 생성할 수 있습니다. 이것은 반드시 모델이 잘 보정되지 않았다는 의미는 아닙니다.
좋은 모델의 보정 곡선
나쁜 모델의 보정 곡선
회귀/예측 메트릭
자동화된 ML은 회귀인지 예측 실험인지에 관계없이 생성된 각 모델에 대해 동일한 성능 메트릭을 계산합니다. 이러한 메트릭은 또한 정규화를 거쳐 다른 범위의 데이터에 대해 학습된 모델 간의 비교를 가능하게 합니다. 자세히 알아보려면 메트릭 정규화를 참조하세요.
다음 표에는 회귀 및 예측 실험에 대해 생성된 모델 성능 메트릭이 요약되어 있습니다. 분류 메트릭과 마찬가지로 이러한 메트릭도 Scikit-learn 구현을 기반으로 합니다. 적절한 Scikit-learn 설명서가 계산 필드에 적절하게 링크되어 있습니다.
| 메트릭 | 설명 | 계산 |
|---|---|---|
| explained_variance | Explained variance(설명된 분산)는 모델이 대상 변수의 변동을 설명하는 정도를 측정합니다. 오차 분산에 대한 원래 데이터의 분산 감소율입니다. 오차의 평균이 0인 경우 결정 계수와 같습니다(아래 차트의 r2_score 참조). 목표: 1에 가까울수록 좋음 범위: (-inf, 1] |
계산 |
| mean_absolute_error | 평균 절대 오차는 대상과 예측 간 차이의 절대값에 대한 예상값입니다. 목표: 0에 가까울수록 좋음 범위: [0, inf) 유형: mean_absolute_error normalized_mean_absolute_error, mean_absolute_error를 데이터의 범위로 나눈 값입니다. |
계산 |
| mean_absolute_percentage_error | MAPE(평균 절대 백분율 오차)는 예측 값과 실제 값 간의 평균 차이를 측정한 값입니다. 목표: 0에 가까울수록 좋음 범위: [0, inf) |
|
| median_absolute_error | Median absolute error(중앙값 절대 오차)는 목표와 예측 간 모든 절대 차이의 중앙값입니다. 이 손실은 이상값보다 강력합니다. 목표: 0에 가까울수록 좋음 범위: [0, inf) 유형: median_absolute_errornormalized_median_absolute_error: mean_absolute_error를 데이터의 범위로 나눈 값입니다. |
계산 |
| r2_score | R2(결정 계수)는 관찰된 데이터의 총 분산에 대한 MSE(평균 제곱 오차)의 비율 감소를 측정합니다. 목표: 1에 가까울수록 좋음 범위: [-1, 1] 참고: R2는 종종 (-inf, 1]의 범위를 가집니다. MSE는 관찰된 분산보다 클 수 있으므로 R2는 데이터 및 모델 예측에 따라 임의로 큰 음수 값을 가질 수 있습니다. 자동화된 ML은 -1에서 R2 점수를 보고했으므로 R2의 값이 -1이면 실제 R2 점수가 -1보다 작음을 의미할 수 있습니다. 음의 R2 점수를 해석할 때 다른 메트릭 값과 데이터의 속성을 고려합니다. |
계산 |
| root_mean_squared_error | RMSE(제곱 평균 오차)는 대상과 예측 간의 예상 제곱 차이의 제곱근입니다. 비편향 추정기의 경우 RMSE는 표준 편차와 같습니다. 목표: 0에 가까울수록 좋음 범위: [0, inf) 유형: root_mean_squared_error normalized_root_mean_squared_error: root_mean_squared_error를 데이터의 범위로 나눈 값입니다. |
계산 |
| root_mean_squared_log_error | 제곱 평균 로그 오차는 예상 로그 제곱 오차의 제곱근입니다. 목표: 0에 가까울수록 좋음 범위: [0, inf) 유형: root_mean_squared_log_error normalized_root_mean_squared_log_error: root_mean_squared_log_error를 데이터의 범위로 나눈 값입니다. |
계산 |
| spearman_correlation | Spearman correlation(Spearman 상관 관계)은 두 데이터 세트 간 관계의 비모수 단조성 측정입니다. Pearson 상관 관계와 달리 Spearman 상관 관계는 두 데이터 세트가 모두 정규적으로 분포된다고 가정하지 않습니다. 다른 상관 계수처럼 Spearman은 -1과 1 사이에서 변화하며 0은 상관 관계가 없음을 의미합니다. - 1 또는 1의 상관 관계는 정확한 단조 관계를 의미합니다. Spearman은 예측 값 또는 실제 값을 변경해도 예측 값 또는 실제 값의 우선순위 순서가 변경되지 않는 경우 Spearman 결과가 변경되지 않음을 의미하는 우선 순위 순서 상관 관계 메트릭입니다. 목표: 1에 가까울수록 좋음 범위: [-1, 1] |
계산 |
메트릭 정규화
자동화된 ML은 회귀 및 예측 메트릭을 정규화하여 다른 범위의 데이터에 대해 학습된 모델 간의 비교를 가능하게 합니다. 범위가 더 큰 데이터에 대해 학습된 모델은 해당 오차를 정규화하지 않으면 더 작은 범위의 데이터로 학습된 동일한 모델보다 높은 오차를 갖습니다.
오차 메트릭을 정규화하는 표준 방법은 없지만 자동화된 ML은 오차를 데이터 범위로 나누는 일반적인 접근 방식을 사용합니다. normalized_error = error / (y_max - y_min)
참고 항목
데이터 범위는 모델과 함께 저장되지 않습니다. 홀드아웃 테스트 세트에서 동일한 모델을 사용하여 추론하는 경우 y_min 및 y_max는 테스트 데이터에 따라 변경될 수 있으며, 정규화된 메트릭은 학습 및 테스트 세트에 대한 모델의 성능을 비교하는 데 직접 사용되지 않을 수 있습니다. 학습 집합에서 y_min 및 y_max 값을 전달하여 공평하게 비교가 진행되도록 할 수 있습니다.
예측 메트릭: 정규화 및 집계
예측 모델 평가를 위한 메트릭을 계산하려면 데이터에 여러 시계열이 포함된 경우 몇 가지 특별한 고려 사항이 필요합니다. 여러 계열에서 메트릭을 집계하기 위한 두 가지 기본 선택 항목이 있습니다.
- 각 시리즈의 평가 메트릭에 동일한 가중치가 부여되는 매크로 평균,
- 각 예측에 대한 평가 메트릭의 가중치가 동일한 마이크로 평균.
이러한 사례는 다중 클래스 분류의 매크로 및 마이크로 평균화와 직접적인 유사성을 갖습니다.
모델 선택을 위한 기본 메트릭을 선택할 때 매크로 평균과 마이크로 평균의 차이가 중요할 수 있습니다. 예를 들어, 특정 소비자 제품에 대한 수요를 예측하려는 소매 시나리오를 생각해 보세요. 일부 제품은 다른 제품보다 더 많은 양으로 판매됩니다. 마이크로 평균 RMSE를 기본 메트릭으로 선택하면 대용량 항목이 모델링 오류의 대부분을 차지하고 결과적으로 메트릭을 지배하게 될 가능성이 있습니다. 모델 선택 알고리즘은 볼륨이 작은 항목보다 볼륨이 높은 항목에서 정확도가 더 높은 모델을 선호할 수 있습니다. 이와 대조적으로 매크로 평균, 정규화된 RMSE는 소량 항목에 대량 항목과 대략 동일한 가중치를 부여합니다.
다음 표는 매크로 평균과 마이크로 평균을 사용하는 AutoML의 예측 메트릭이 나와 있습니다.
| 매크로 평균 | 마이크로 평균 |
|---|---|
매크로 평균 메트릭은 각 계열을 개별적으로 정규화합니다. 그런 다음 각 계열의 정규화된 메트릭을 평균하여 최종 결과를 제공합니다. 매크로와 마이크로의 올바른 선택은 비즈니스 시나리오에 따라 다르지만 일반적으로 normalized_root_mean_squared_error를 사용하는 것이 좋습니다.
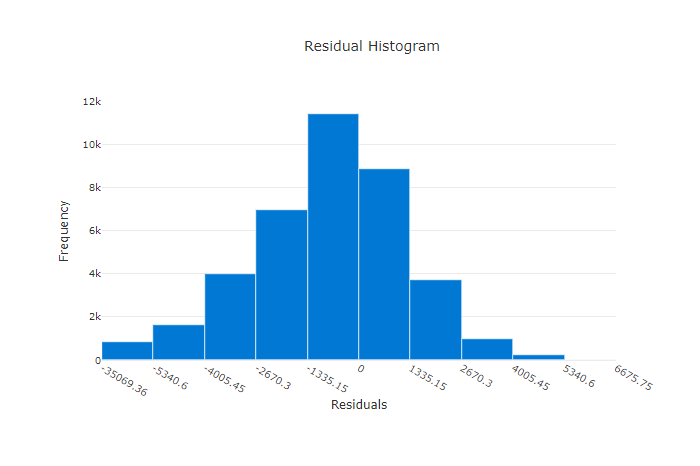
잔차
잔차 차트는 회귀 및 예측 실험에 대해 생성된 예측 오류(잔차)의 히스토그램입니다. 잔차는 모든 샘플에 대해 y_predicted - y_true로 계산된 다음 모델 바이어스를 보여 주는 히스토그램으로 표시됩니다.
이 예제에서는 두 모델 모두 실제 값보다 낮게 예측하도록 약간 바이어스되어 있습니다. 이는 실제 대상의 분포가 치우쳐 있는 데이터 세트에 대해서는 드문 일이 아니지만 모델 성능이 더 나쁘다는 것을 나타냅니다. 좋은 모델은 극단에서는 잔차가 거의 없이 0에서 정점을 이루는 잔차 분포를 갖습니다. 더 나쁜 모델은 0 근처에 더 적은 수의 샘플이 있는 분산된 잔차 분포를 갖습니다.
좋은 모델의 잔차 차트
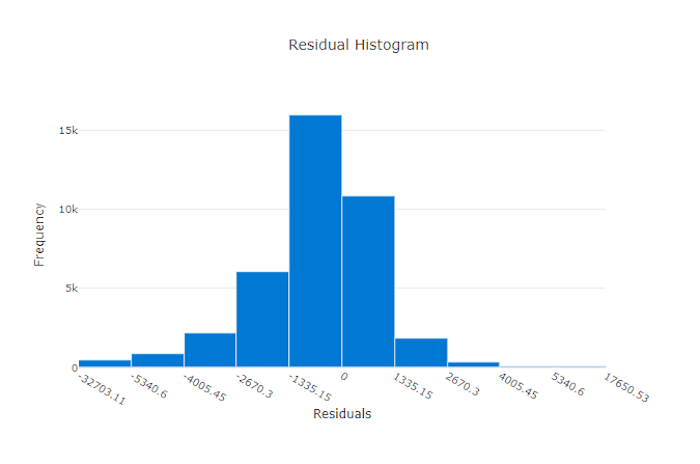
나쁜 모델의 잔차 차트
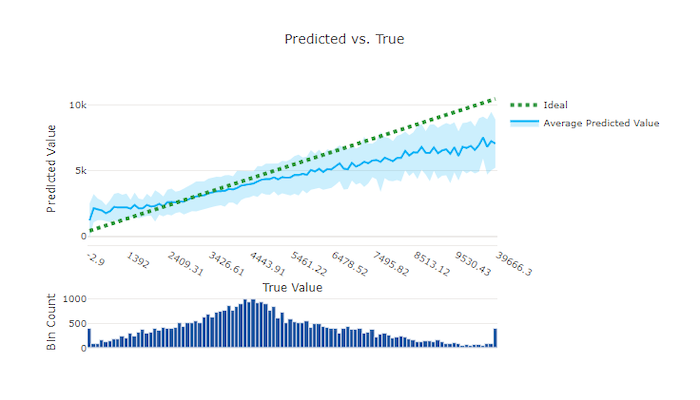
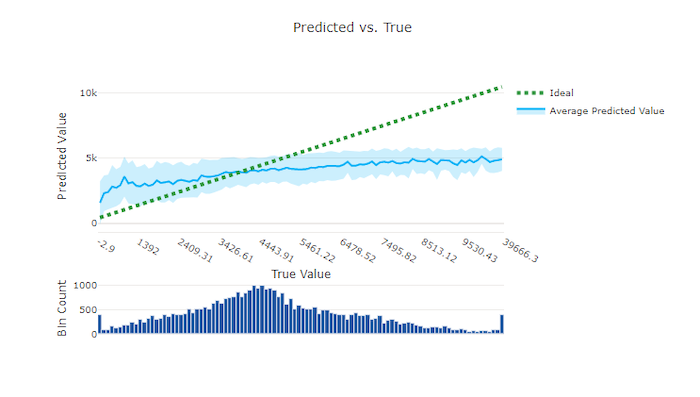
예측 대 실제
회귀 및 예측 실험의 경우 예측 대 실제 차트는 대상 기능(실제/진짜 값)과 모델 예측 간의 관계를 표시합니다. 실제 값은 x축을 따라 계급구간이 나뉘어지고 각 계급구간에 대해 예측 값 평균이 오차 막대로 표시됩니다. 이를 통해 모델이 특정 값을 예측하는 쪽으로 바이어스되어 있는지 확인할 수 있습니다. 선은 평균 예측을 표시하고 음영 처리된 영역은 해당 평균 주변의 예측 분산을 나타냅니다.
종종 가장 일반적인 실제 값이 가장 낮은 분산으로 가장 정확한 예측을 갖습니다. 실제 값이 거의 없는 이상적인 y = x 선에서 추세선까지의 거리는 이상값에 대한 모델 성능을 측정하는 좋은 척도입니다. 차트 아래쪽의 히스토그램을 사용하여 실제 데이터 분포를 추론할 수 있습니다. 분포가 희박한 데이터 샘플을 더 많이 포함하면 보이지 않는 데이터에 대한 모델 성능을 향상시킬 수 있습니다.
이 예에서 더 나은 모델은 이상적인 y = x 선에 더 가까운 예측 대 실제 선을 가집니다.
좋은 모델의 예측 대 실제 차트
나쁜 모델의 예측 대 실제 차트
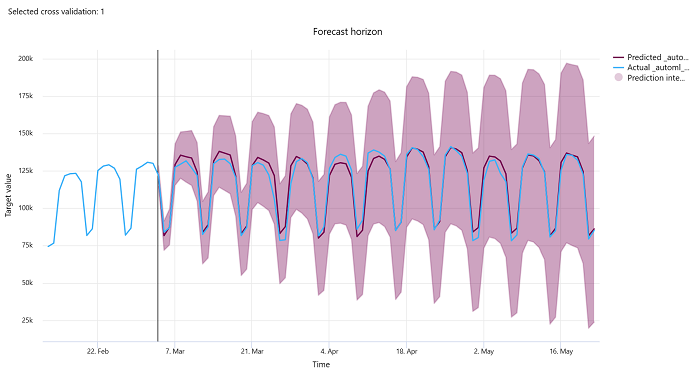
예측 기간
예측 실험의 경우 예측 구간 차트는 모델 예측 값과 교차 유효성 검사 폴드당 시간에 따라 매핑된 실제 값 간의 관계를 최대 5배까지 그립니다. x축은 학습 설정 중에 제공한 빈도에 따라 시간을 매핑합니다. 차트의 수직선은 예측 생성을 시작할 기간인 수평선이라고도 하는 예측 수평 지점을 표시합니다. 예측 수평선의 왼쪽에서 과거 추세를 더 잘 시각화하기 위해 기록 학습 데이터를 볼 수 있습니다. 예측 수평선의 오른쪽에서 다양한 교차 유효성 검사 접기 및 시계열 식별자에 대한 실제(파란색 선)에 대해 예측(자주색 선)을 시각화할 수 있습니다. 음영 처리된 자주색 영역은 해당 평균에 대한 예측의 신뢰 구간 또는 분산을 나타냅니다.
차트의 오른쪽 위 모서리에 있는 연필 편집 아이콘을 클릭하여 표시할 교차 유효성 검사 접기 및 시계열 식별자 조합을 선택할 수 있습니다. 처음 5개의 교차 유효성 검사 접기 및 최대 20개의 시계열 식별자 중에서 선택하여 다양한 시계열에 대한 차트를 시각화합니다.
Important
이 차트는 학습 및 유효성 검사 데이터에서 생성된 모델의 학습 실행과 학습 데이터 및 테스트 데이터를 기반으로 하는 테스트 실행에서 사용할 수 있습니다. 예측 origin 이전까지는 최대 20개의 데이터 요소와 예측 origin 이후부터는 최대 80개의 데이터 요소를 허용합니다. DNN 모델의 경우 학습 실행의 이 차트는 모델이 완전히 학습된 후 마지막 Epoch의 데이터를 표시합니다. 테스트 실행의 이 차트는 학습 실행 중에 유효성 검사 데이터가 명시적으로 제공된 경우 가로선 앞에 간격이 있을 수 있습니다. 이는 테스트 실행에 학습 데이터 및 테스트 데이터가 사용되어 유효성 검사 데이터를 제외하여 간격이 발생하기 때문입니다.
이미지 모델에 대한 메트릭(미리 보기)
자동화된 ML는 유효성 검사 데이터 세트의 이미지를 사용하여 모델의 성능을 평가합니다. 학습의 진행 방식을 파악하기 위해 epoch 수준에서 모델 성능이 측정됩니다. 전체 데이터 세트가 신경망을 정확하게 한 번 앞뒤로 통과하면 epoch가 발생합니다.
이미지 분류 메트릭
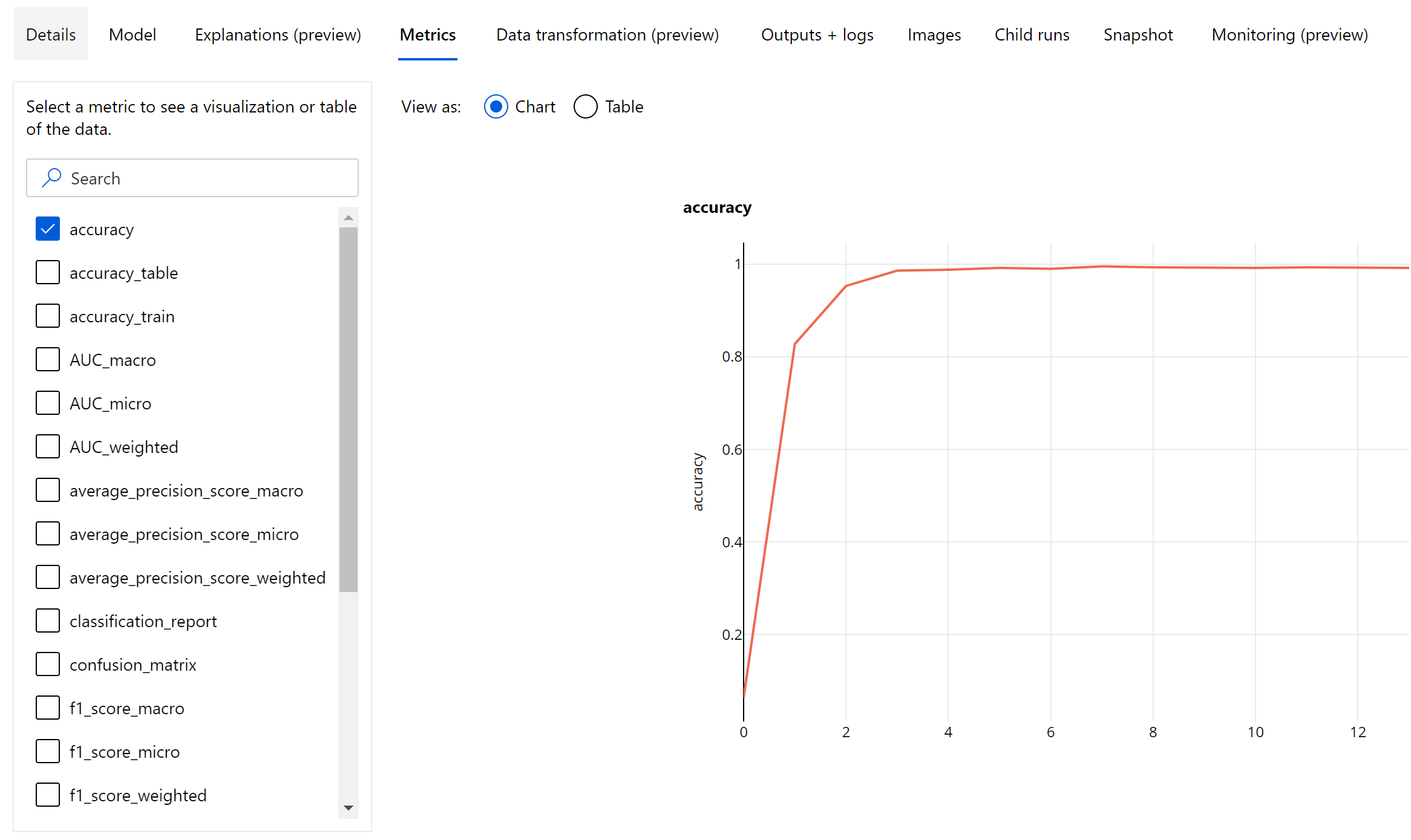
평가에 대한 기본 메트릭은 이진 및 다중 클래스 분류 모델의 경우 정확도이고, 다중 레이블 분류 모델의 경우 IoU(Intersection over Union)입니다. 이미지 분류 모델에 대한 분류 메트릭은 분류 메트릭 섹션에 정의된 것과 동일합니다. 또한 epoch와 연결된 손실 값이 기록되어 학습의 진행 방식을 모니터링하고 모델이 과잉 맞춤되거나 과소 맞춤되는지를 파악하는 데 도움이 될 수 있습니다.
분류 모델의 모든 예측에는 예측에 사용된 신뢰도 수준을 나타내는 신뢰도 점수가 연결됩니다. 다중 레이블 이미지 분류 모델은 기본적으로 0.5의 점수 임계값으로 평가됩니다. 이것은 이 수준 이상의 신뢰도를 가진 예측만 관련 클래스에 대한 긍정 예측으로 간주됨을 의미합니다. 다중 클래스 분류는 점수 임계값을 사용하지 않고 대신 신뢰도 점수가 최대인 클래스를 예측으로 간주합니다.
이미지 분류를 위한 Epoch 수준 메트릭
테이블 형식 데이터 세트의 분류 메트릭과 달리, 이미지 분류 모델은 아래와 같이 epoch 수준에서 모든 분류 메트릭을 기록합니다.
이미지 분류에 대한 요약 메트릭
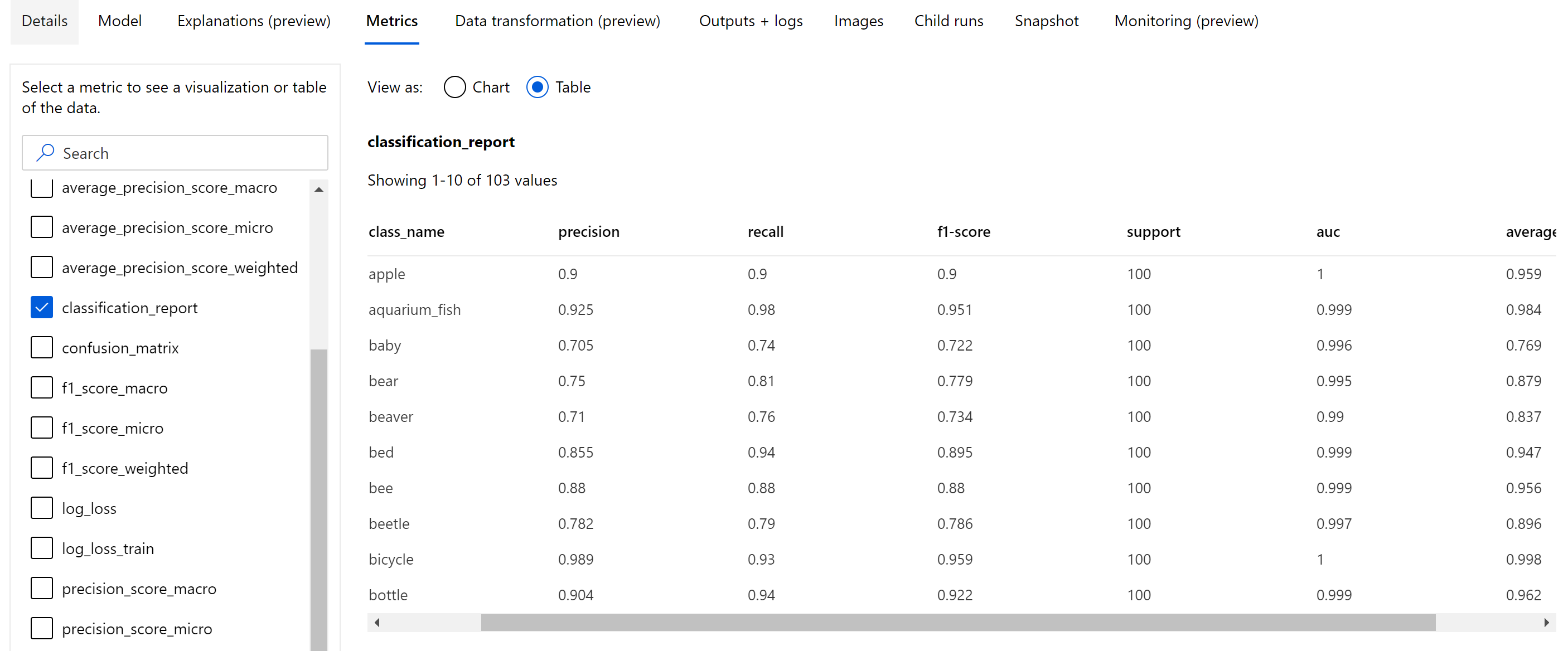
Epoch 수준에서 기록된 스칼라 메트릭과는 별도로, 이미지 분류 모델은 혼동 행렬, 분류 차트(ROC 곡선, 가장 높은 기본 메트릭(정확도) 점수를 얻게 되는 최상의 epoch에 있는 모델에 대한 정밀도-재현율 곡선 및 분류 보고서 포함) 같은 요약 메트릭도 기록합니다.
분류 보고서는 아래 표시된 것과 같이 다양한 평균 수준인 마이크로, 매크로를 가지며 아래와 같이 가중치가 적용되는 정밀도, 재현율, f1-점수, 지원, auc 및 average_precision과 같은 메트릭에 대한 클래스 수준 값을 제공합니다. 분류 메트릭 섹션에서 메트릭 정의를 참조하세요.
개체 감지 및 인스턴스 구분 메트릭
이미지 개체 감지 또는 인스턴스 구분 모델의 모든 예측은 신뢰도 점수와 연결됩니다.
신뢰도 점수가 점수 임계값보다 큰 예측은 예측으로 출력되고 메트릭 계산에 사용됩니다. 이것은 모델마다 고유하며 하이퍼 매개 변수 튜닝 페이지(box_score_threshold 하이퍼 매개 변수)에서 참조될 수 있는 기본값입니다.
이미지 개체 감지 및 인스턴스 구분 모델의 메트릭 계산은 IoU(Intersection over Union)라는 메트릭으로 정의된 중첩 측정을 기준으로 합니다. 이 측정값은 자체 실측과 예측 사이의 교집합 영역을 자체 실측과 예측의 합집합 영역으로 나누어 계산합니다. 모든 예측에서 계산된 IoU가 긍정 예측으로 간주되려면 예측이 IoU 임계값이라는 중복 임계값과 비교되어 사용자가 주석 처리한 자체 실측에 얼마나 많이 겹치는지 확인합니다. 예측에서 계산된 IoU가 중복 임계값보다 작은 경우 예측은 관련 클래스에 대한 긍정 예측으로 간주되지 않습니다.
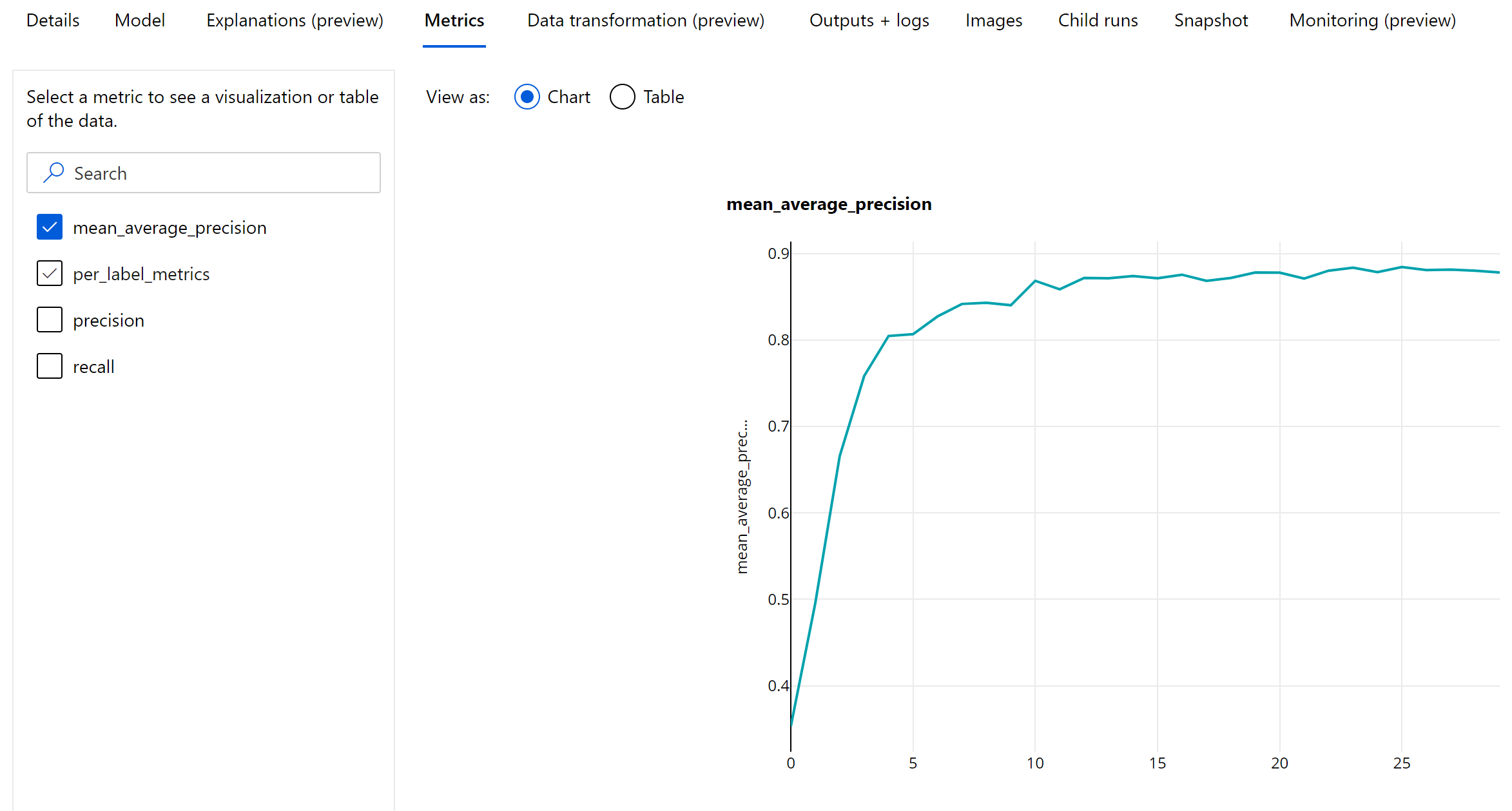
이미지 개체 감지 및 인스턴스 구분 모델의 평가에 대한 기본 메트릭은 mAP(평균 정밀도의 평균)입니다. mAP는 모든 클래스에서 AP(평균 정밀도)의 평균 값입니다. 자동화된 ML 개체 감지 모델은 아래에 나오는 자주 사용되는 두 가지 방법을 사용하여 mAP 계산을 지원합니다.
Pascal VOC 메트릭:
Pascal VOC mAP는 개체 감지/인스턴스 구분 모델에 대한 기본 mAP 계산 방법입니다. Pascal VOC 스타일 mAP 방법은 정밀도-재현율 곡선 형태의 아래 영역을 계산합니다. 재현율 i의 정밀도인 첫 번째 p(rᵢ)는 모든 고유한 재현율 값에 대해 계산됩니다. 그러면 p(rᵢ)가 재현율 r' >= rᵢ에 대해 구한 최대 정밀도로 바뀝니다. 이 버전의 곡선에서는 정밀도 값이 일정하게 감소합니다. Pascal VOC mAP 메트릭은 기본적으로 IoU 임계값 0.5를 사용하여 평가됩니다. 이 개념에 대한 자세한 설명은 이 블로그에서 확인할 수 있습니다.
COCO 메트릭:
COCO 평가 방법에서는 AP 계산에 101점 보간 방법을 사용하고 10개 이상의 IoU 임계값 평균을 구합니다. AP@[.5:.95]는 단계 크기를 0.05로 하여 0.5에서 0.95까지의 IoU에 대한 평균 AP에 해당합니다. 자동화된 ML은 애플리케이션 로그에서 다양한 스케일의 AP 및 AR(평균 재현율)을 포함하여 COCO 방법으로 정의된 12개 메트릭을 모두 기록하는 반면, 메트릭 사용자 인터페이스는 IoU 임계값 0.5의 mAP만 표시합니다.
팁
validation_metric_type 하이퍼 매개 변수가 하이퍼 매개 변수 튜닝 섹션에 설명된 대로 ‘coco’로 설정된 경우 이미지 개체 감지 모델 평가에서 coco 메트릭을 사용할 수 있습니다.
개체 감지 및 인스턴스 구분을 위한 Epoch 수준 메트릭
mAP, 정밀도 및 재현율 값은 이미지 개체 감지/인스턴스 구분 모델에 대해 epoch 수준에서 기록됩니다. mAP, 정밀도 및 재현율 메트릭은 이름이 'per_label_metrics'인 클래스 수준에서도 기록됩니다. ‘per_label_metrics’는 테이블로 표시되어야 합니다.
참고 항목
‘coco’ 메서드를 사용하는 경우 정밀도, 재현율 및 per_label_metrics에 대한 Epoch 수준 메트릭은 사용할 수 없습니다.
가장 권장되는 AutoML 모델을 위한 책임 있는 AI 대시보드(미리 보기)
Azure Machine Learning 책임 있는 AI 대시보드는 실제로 책임 있는 AI를 효과적이고 효율적으로 구현하는 데 도움이 되는 단일 인터페이스를 제공합니다. 책임 있는 AI 대시보드는 표 형식 데이터를 통해서만 지원되며 분류 및 회귀 모델에서만 지원됩니다. 다음과 같은 영역에서 몇 가지 성숙한 책임 있는 AI 도구를 함께 제공합니다.
- 모델 성능 및 공정성 평가
- 데이터 살펴보기
- 기계 학습 해석 가능성
- 오류 분석
모델 평가 메트릭 및 차트는 모델의 일반적인 품질을 측정하는 데 적합하지만, 모델의 공정성 검사, 설명 보기(예측에 사용되는 모델을 기능으로 하는 데이터 세트라고도 함), 오류 및 잠재적 블라인드 검사와 같은 작업 책임 있는 AI를 실천하려면 스폿이 필수적입니다. 이것이 바로 자동화된 ML이 모델에 대한 다양한 인사이트를 관찰하는 데 도움이 되는 책임 있는 AI 대시보드를 제공하는 이유입니다. Azure Machine Learning 스튜디오에서 책임 있는 AI 대시보드를 보는 방법을 알아봅니다.
UI 또는 SDK를 통해 이 대시보드를 생성하는 방법을 알아봅니다.
모델 설명 및 기능 중요도
모델의 일반적인 품질을 측정하는 데에는 모델 평가 메트릭과 차트로도 충분하지만, 책임을 져야 하는 AI를 실습할 때는 모델이 예측에 사용한 데이터 세트 기능을 검사하는 것이 중요 합니다. 이것이 자동화된 ML이 데이터 세트 기능의 상대적 기여도를 측정하고 보고하는 모델 설명 대시보드를 제공하는 이유입니다. Azure Machine Learning 스튜디오에서 설명 대시보드를 보는 방법을 참조하세요.
참고 항목
다음 알고리즘을 최적의 모델 또는 앙상블로 권장하는 자동화된 ML 예측 실험에는 해석력 및 최적의 모델 설명을 사용할 수 없습니다.
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Prophet
- 평균
- Naive
- Seasonal Average
- Seasonal Naive
다음 단계
- 자동화된 Machine Learning 모델 설명 샘플 Notebook을 사용해 봅니다.
- 자동화된 ML 관련 세부 질문은 askautomatedml@microsoft.com으로 문의하세요.