Kubernetes 컴퓨팅 문제 해결
이 문서에서는 Kubernetes 컴퓨팅에서 일반적인 워크로드 오류를 해결하는 방법을 알아봅니다. 일반적인 오류에는 학습 작업 및 엔드포인트 오류가 포함됩니다.
유추 가이드
Kubernetes 컴퓨팅에서 흔히 발생하는 Kubernetes 엔드포인트 오류는 컴퓨팅 범위와 클러스터 범위라는 두 가지 범위로 분류됩니다. 컴퓨팅 범위 오류는 컴퓨팅 대상을 찾을 수 없거나 컴퓨팅 대상에 액세스할 수 없는 등 컴퓨팅 대상과 관련되어 있습니다. 클러스터 범위 오류는 클러스터 자체에 연결할 수 없거나 클러스터를 찾을 수 없는 등 기본 Kubernetes 클러스터와 관련되어 있습니다.
Kubernetes 컴퓨팅 오류
다음은 Kubernetes 컴퓨팅을 사용하여 실시간 모델 유추를 위한 온라인 엔드포인트 및 온라인 배포를 만들 때 발생할 수 있는 컴퓨팅 범위의 공통 오류 유형의 목록입니다. 다음 링크된 섹션에서 지침에 따라 문제를 해결할 수 있습니다.
- 오류: GenericComputeError
- 오류: ComputeNotFound
- 오류: ComputeNotAccessible
- 오류: InvalidComputeInformation
- 오류: InvalidComputeNoKubernetesConfiguration
오류: GenericComputeError
오류 메시지는 다음과 같습니다.
Failed to get compute information.
이 오류는 시스템이 Kubernetes 클러스터에서 컴퓨팅 정보를 얻지 못했을 때 발생합니다. 다음 항목을 확인하여 문제를 해결할 수 있습니다.
- Kubernetes 클러스터 상태를 확인합니다. 클러스터가 실행되고 있지 않은 경우 먼저 클러스터를 시작해야 합니다.
- Kubernetes 클러스터 성능 상태를 확인합니다.
- 클러스터에 연결할 수 없는 경우와 같은 문제 발생 시 클러스터 상태 검사 보고서를 볼 수 있습니다.
- 작업 영역 포털로 이동하여 컴퓨팅 상태를 확인할 수 있습니다.
- 인스턴스 유형 정보가 올바른지 확인합니다. Kubernetes 컴퓨팅 설명서에서 지원되는 인스턴스 유형을 확인할 수 있습니다.
- 해당하는 경우 컴퓨팅을 분리했다가 작업 영역에 다시 연결해 보세요.
참고 항목
다시 연결하여 오류를 해결하려면 동일한 컴퓨팅 이름과 네임스페이스 등 이전에 분리된 컴퓨팅과 정확히 동일한 구성으로 다시 연결해야 합니다. 그렇지 않으면 다른 오류가 발생할 수 있습니다.
오류: ComputeNotFound
오류 메시지는 다음과 같습니다.
Cannot find Kubernetes compute.
이 오류는 다음과 같은 경우에 발생합니다.
- 새 온라인 엔드포인트/배포를 만들거나 업데이트할 때 시스템에서 컴퓨팅을 찾을 수 없습니다.
- 기존 온라인 엔드포인트/배포의 컴퓨팅이 제거되었습니다.
다음 항목을 확인하여 문제를 해결할 수 있습니다.
- 엔드포인트 및 배포를 다시 만들어 보세요.
- 컴퓨팅을 분리했다가 작업 영역에 다시 연결해 보세요. 다시 연결 시 추가 참고 사항에 주의하세요.
오류: ComputeNotAccessible
오류 메시지는 다음과 같습니다.
The Kubernetes compute is not accessible.
이 오류는 작업 영역 MSI(관리 ID)가 AKS 클러스터에 액세스할 수 없는 경우 발생합니다. 작업 영역 MSI가 AKS에 대한 액세스 권한을 보유하고 있는지 확인할 수 있으며, 그렇지 않은 경우 이 설명서에 따라 액세스 권한과 ID를 관리할 수 있습니다.
오류: InvalidComputeInformation
오류 메시지는 다음과 같습니다.
The compute information is invalid.
Kubernetes 클러스터에 모델을 배포할 때 컴퓨팅 대상 유효성 검사 프로세스가 있습니다. 이 오류는 컴퓨팅 정보가 유효하지 않은 경우에 발생합니다. 예를 들어, 계산 대상을 찾을 수 없거나 Kubernetes 클러스터에서 Azure Machine Learning 확장의 구성이 업데이트된 경우입니다.
다음 항목을 확인하여 문제를 해결할 수 있습니다.
- 사용한 컴퓨팅 대상이 올바른지, 작업 영역에 존재하는지 확인합니다.
- 컴퓨팅을 분리했다가 작업 영역에 다시 연결해 보세요. 다시 연결 시 추가 참고 사항에 주의하세요.
오류: InvalidComputeNoKubernetesConfiguration
오류 메시지는 다음과 같습니다.
The compute kubeconfig is invalid.
이 오류는 시스템에서 클러스터에 연결할 구성을 찾지 못했을 때 발생합니다. 예를 들면 다음과 같습니다.
- Arc-Kubernetes 클러스터에서 Azure Relay 구성을 찾을 수 없는 경우
- AKS 클러스터에서 AKS 구성을 찾을 수 없는 경우
클러스터에서 컴퓨팅 연결의 구성을 다시 빌드하려면 컴퓨팅을 분리했다가 작업 영역에 다시 연결하면 됩니다. 다시 연결 시 추가 참고 사항에 주의하세요.
Kubernetes 클러스터 오류
다음은 Kubernetes 컴퓨팅을 사용하여 실시간 모델 유추를 위한 온라인 엔드포인트 및 온라인 배포를 만들 때 발생할 수 있는 클러스터 범위 오류 유형의 목록으로, 지침에 따라 문제를 해결할 수 있습니다.
- 오류: GenericClusterError
- 오류: ClusterNotReachable
- 오류: ClusterNotFound
- 오류: ClusterServiceNotFound
- 오류: ClusterUnauthorized
오류: GenericClusterError
오류 메시지는 다음과 같습니다.
Failed to connect to Kubernetes cluster: <message>
이 오류는 알 수 없는 이유로 시스템이 Kubernetes 클러스터에 연결하지 못한 경우 발생합니다. 다음 항목을 확인하여 문제를 해결할 수 있습니다.
AKS 클러스터:
- AKS 클러스터가 종료되었는지 확인합니다.
- 클러스터가 실행되고 있지 않은 경우 먼저 클러스터를 시작해야 합니다.
- AKS 클러스터가 권한 있는 IP 범위를 사용해 선택한 네트워크를 사용하도록 설정했는지 확인합니다.
- AKS 클러스터에서 권한 있는 IP 범위를 사용하도록 설정한 경우, AKS 클러스터에 대한 Azure Machine Learning 컨트롤 플레인 IP 범위를 모두 사용하도록 설정했는지 확인합니다. 자세한 내용은 이 설명서를 참조하세요.
AKS 클러스터 또는 Azure Arc 지원 Kubernetes 클러스터:
- 클러스터에서
kubectl명령을 실행하여 Kubernetes API 서버에 액세스할 수 있는지 확인합니다.
오류: ClusterNotReachable
오류 메시지는 다음과 같습니다.
The Kubernetes cluster is not reachable.
이 오류는 시스템이 클러스터에 연결할 수 없는 경우 발생합니다. 다음 항목을 확인하여 문제를 해결할 수 있습니다.
AKS 클러스터:
- AKS 클러스터가 종료되었는지 확인합니다.
- 클러스터가 실행되고 있지 않은 경우 먼저 클러스터를 시작해야 합니다.
AKS 클러스터 또는 Azure Arc 지원 Kubernetes 클러스터:
- 클러스터에서
kubectl명령을 실행하여 Kubernetes API 서버에 액세스할 수 있는지 확인합니다.
오류: ClusterNotFound
오류 메시지는 다음과 같습니다.
Cannot found Kubernetes cluster.
이 오류는 시스템이 AKS/Arc-Kubernetes 클러스터를 찾을 수 없는 경우 발생합니다.
다음 항목을 확인하여 문제를 해결할 수 있습니다.
- 먼저, Azure Portal의 클러스터 리소스 ID를 검사하여 Kubernetes 클러스터 리소스가 여전히 존재하고 정상적으로 실행되고 있는지 여부를 확인합니다.
- 클러스터가 존재하고 실행 중인 경우 컴퓨팅을 분리했다가 작업 영역에 다시 연결해 보면 됩니다. 다시 연결 시 추가 참고 사항에 주의하세요.
오류: ClusterServiceNotFound
오류 메시지는 다음과 같습니다.
AzureML extension service not found in cluster.
이 오류는 확장 소유 수신 서비스에 백 엔드 Pod가 충분하지 않을 때 발생합니다.
마케팅 목록의 구성원을 관리할 수 있습니다.
- 클러스터에 액세스하고
azureml네임스페이스 아래에 있는 서비스azureml-ingress-nginx-controller및 해당 백엔드 Pod의 상태를 확인합니다. - 클러스터에 실행 중인 백 엔드 Pod가 없는 경우 Pod를 설명하여 이유를 확인합니다. 예를 들어 Pod에 실행할 리소스가 충분하지 않은 경우 일부 Pod를 삭제하여 수신 Pod에 충분한 리소스를 확보할 수 있습니다.
오류: ClusterUnauthorized
오류 메시지는 다음과 같습니다.
Request to Kubernetes cluster unauthorized.
이 오류는 TA 지원 클러스터에서만 발생해야 하며, 이는 배포 중에 액세스 토큰이 만료되었음을 의미합니다.
몇 분 후에 다시 시도할 수 있습니다.
팁
Kubernetes 온라인 엔드포인트 및 배포를 만들거나 업데이트할 때 발생하는 일반적인 오류에 대한 자세한 문제 해결 가이드는 온라인 엔드포인트 문제 해결 방법에서 찾을 수 있습니다.
ID 오류
오류: RefreshExtensionIdentityNotSet
이 오류는 확장이 설치되어 있지만 확장 ID가 올바르게 할당되지 않은 경우에 발생합니다. 확장을 다시 설치하여 해결할 수 있습니다.
이 오류는 관리 클러스터에만 해당됩니다.
sslCertPemFile 및 sslKeyPemFile이 올바른지 확인하는 방법
알려진 오류가 표시되도록 하려면 명령을 사용하여 인증서 및 키에 대한 기준 검사를 실행할 수 있습니다. 두 번째 명령은 암호를 묻는 메시지를 표시하지 않고 'RSA 키 확인'을 반환할 것으로 예상됩니다.
openssl x509 -in cert.pem -noout -text
openssl rsa -in key.pem -noout -check
명령을 실행하여 sslCertPemFile 및 sslKeyPemFile이 일치하는지 여부를 확인합니다.
openssl x509 -in cert.pem -noout -modulus | md5sum
openssl rsa -in key.pem -noout -modulus | md5sum
sslCertPemFile의 경우 공용 인증서입니다. 다음 인증서를 포함하는 인증서 체인을 포함하고 서버 인증서, 중간 CA 인증서 및 루트 CA 인증서의 순서로 있어야 합니다.
- 서버 인증서: TLS 핸드셰이크 중 서버에서 클라이언트에 제시합니다. 여기에는 서버의 공개 키, 도메인 이름 및 기타 정보가 포함됩니다. 서버 인증서는 서버 ID를 보증하는 중간 CA(인증 기관)에 의해 서명됩니다.
- 중간 CA 인증서: 중간 CA는 서버 인증서에 서명할 권한을 증명하기 위해 클라이언트에 제시합니다. 여기에는 중간 CA의 공개 키, 이름 및 기타 정보가 포함됩니다. 중간 CA 인증서는 중간 CA의 ID를 보증하는 루트 CA에 의해 서명됩니다.
- 루트 CA 인증서: 루트 CA는 중간 CA 인증서에 서명할 권한을 증명하기 위해 클라이언트에 제시됩니다. 여기에는 루트 CA의 공개 키, 이름 및 기타 정보가 포함됩니다. 루트 CA 인증서는 자체 서명되며 클라이언트에서 신뢰할 수 있습니다.
학습 가이드
학습 작업이 실행 중일 때 작업 영역 포털에서 작업 상태를 확인할 수 있습니다. 작업이 여러 번 다시 시도되거나 작업이 초기화 상태에서 중단되거나 작업이 결국 실패하는 등 비정상적인 작업 상태가 발생하는 경우 가이드에 따라 문제를 해결할 수 있습니다.
작업 다시 시도 디버깅
노드 OOM(메모리 부족)으로 실행되는 노드로 인해 클러스터에서 실행 중인 학습 작업 Pod가 종료된 경우, 작업은 사용 가능한 다른 노드로 자동으로 다시 시도됩니다.
작업 시도의 근본 원인을 추가로 디버그하려면 작업 영역 포털로 이동하여 작업 다시 시도 로그를 확인하면 됩니다.
- 각각의 다시 시도 로그는 "retry-<다시 시도 횟수>"(예: retry-001) 형식으로 새 로그 폴더에 기록됩니다.
그런 다음, 다시 시도 작업 노드 매핑 정보를 가져와 다시 시도 작업이 실행 중인 노드를 파악할 수 있습니다.
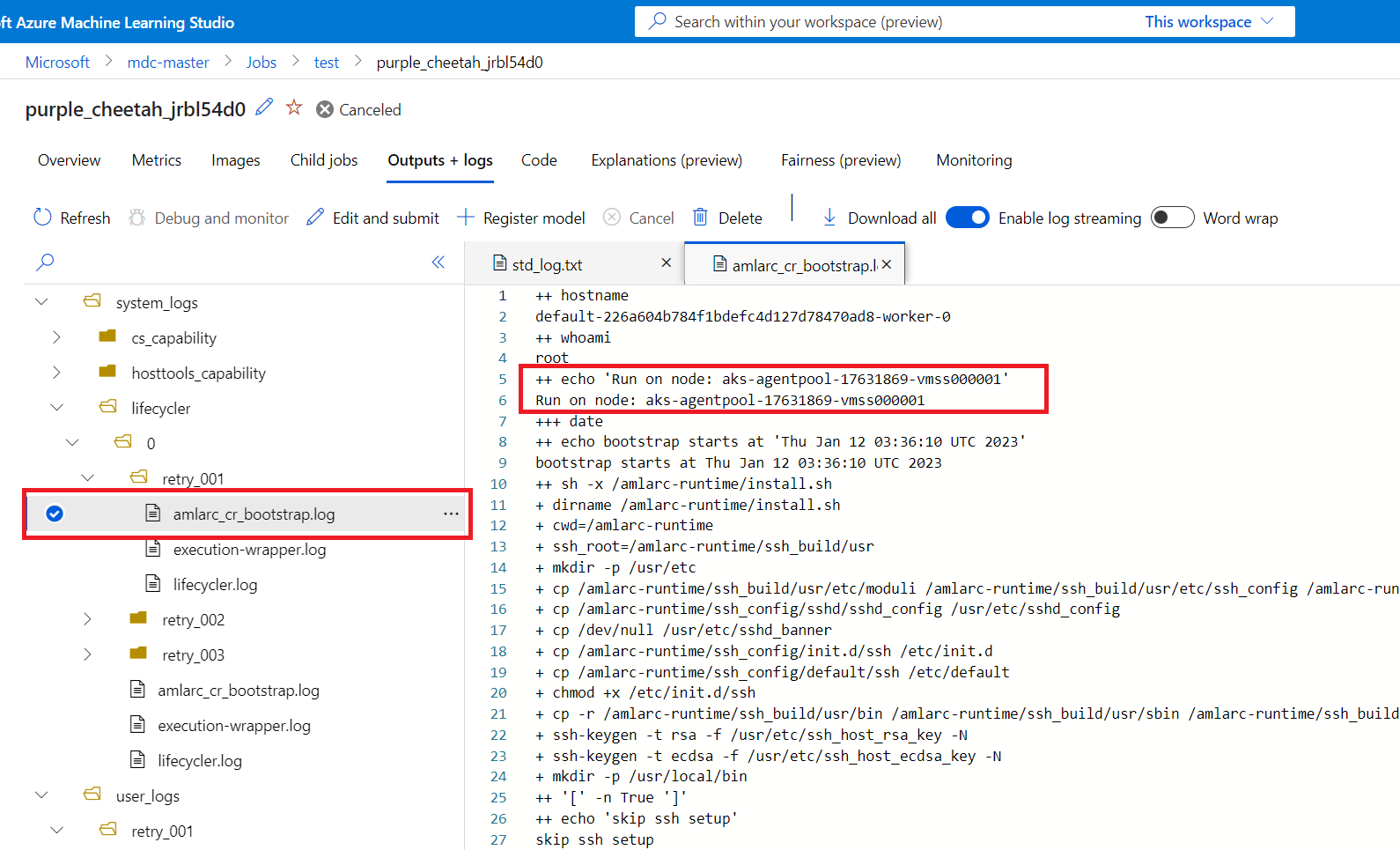
system_logs 폴더의 amlarc_cr_bootstrap.log에서 작업 노드 매핑 정보를 가져올 수 있습니다.
작업 Pod가 실행 중인 노드의 호스트 이름이 이 로그에 표시됩니다. 예를 들면 다음과 같습니다.
++ echo 'Run on node: ask-agentpool-17631869-vmss0000"
'ask-agentpool-17631869-vmss0000'은 AKS 클러스터에서 이 작업을 실행하는 노드 호스트 이름을 나타냅니다. 그런 다음, 클러스터에 액세스하여 추가 조사를 위해 노드 상태를 확인할 수 있습니다.
작업 Pod가 Init 상태에서 중단됨
작업이 예상보다 오래 실행되고 이 Unable to attach or mount volumes: *** failed to get plugin from volumeSpec for volume ***-blobfuse-*** err=no volume plugin matched 경고와 함께 작업 Pod가 Init 상태에서 중단되었음이 확인되는 경우, Azure Machine Learning 확장에서 입력 데이터에 대한 다운로드 모드를 지원하지 않기 때문에 문제가 발생할 수 있습니다.
이 문제를 해결하려면 입력 데이터에 대한 탑재 모드로 변경하세요.
일반적인 작업 실패 오류
다음은 Kubernetes 컴퓨팅을 사용하여 학습 작업을 만들고 실행할 때 발생할 수 있는 일반적인 오류 형식 목록입니다. 지침에 따라 문제를 해결할 수 있습니다.
작업이 실패했습니다. 137
오류 메시지가 다음과 같은 경우:
Azure Machine Learning Kubernetes job failed. 137:PodPattern matched: {"containers":[{"name":"training-identity-sidecar","message":"Updating certificates in /etc/ssl/certs...\n1 added, 0 removed; done.\nRunning hooks in /etc/ca-certificates/update.d...\ndone.\n * Serving Flask app 'msi-endpoint-server' (lazy loading)\n * Environment: production\n WARNING: This is a development server. Do not use it in a production deployment.\n Use a production WSGI server instead.\n * Debug mode: off\n * Running on http://127.0.0.1:12342/ (Press CTRL+C to quit)\n","code":137}]}
프록시 설정을 확인하고, 이 네트워크 구성에 따라 az connectedk8s connect를 사용할 때 127.0.0.1이 proxy-skip-range에 추가되었는지 여부를 확인합니다.
작업이 실패했습니다. E45004
오류 메시지가 다음과 같은 경우:
Azure Machine Learning Kubernetes job failed. E45004:"Training feature is not enabled, please enable it when install the extension."
Azure Machine Learning 확장 설치를 수행할 때 enableTraining=True를 설정했는지 여부를 확인하세요. 자세한 내용은 AKS 또는 Arc Kubernetes 클러스터에 Azure Machine Learning 확장 배포에서 찾을 수 있습니다.
작업이 실패했습니다. 400
오류 메시지가 다음과 같은 경우:
Azure Machine Learning Kubernetes job failed. 400:{"Msg":"Encountered an error when attempting to connect to the Azure Machine Learning token service","Code":400}
Private Link 문제 해결 섹션에 따라 네트워크 설정을 확인하면 됩니다.
계정 키 또는 SAS 토큰 제공
Docker 이미지용 ACR(Azure Container Registry)에 액세스하고 학습 데이터용 스토리지 계정에 액세스해야 하는 경우, 이 문제는 컴퓨팅이 관리 ID로 지정되지 않았을 때 발생합니다.
Docker 이미지용 Kubernetes 컴퓨팅 클러스터에서 ACR(Azure Container Registry)에 액세스하거나 학습 데이터용 스토리지 계정에 액세스하려면 시스템 할당 또는 사용자 할당 관리 ID를 사용하도록 설정하여 Kubernetes 컴퓨팅을 연결해야 합니다.
위의 학습 시나리오에서 작업 영역에 바인딩된 ARM 리소스와 Kubernetes 컴퓨팅 클러스터 간에 통신하기 위한 자격 증명으로 Kubernetes 컴퓨팅을 사용하려면 이 컴퓨팅 ID가 필요합니다. 따라서 이 ID가 없으면 학습 작업이 실패하고 계정 키 또는 sas 토큰 누락이 보고됩니다. 예를 들어, 스토리지 계정에 액세스하는 경우 Kubernetes 컴퓨팅에 관리 ID를 지정하지 않으면 다음 오류 메시지와 함께 작업이 실패합니다.
Unable to mount data store workspaceblobstore. Give either an account key or SAS token
자격 증명이 없는 기계 학습 작업 영역 기본 스토리지 계정은 Kubernetes 컴퓨팅의 학습 작업에 액세스할 수 없기 때문입니다.
이 문제를 완화하려면 컴퓨팅 연결 단계에서 컴퓨팅에 관리 ID를 할당하거나 연결된 후 컴퓨팅에 관리 ID를 할당하면 됩니다. 자세한 내용은 컴퓨팅 대상에 관리 ID 할당에서 찾을 수 있습니다.
AzureBlob 권한 부여 실패
Kubernetes 컴퓨팅의 학습 작업에서 데이터 업로드 또는 다운로드를 위해 AzureBlob에 액세스해야 하는 경우 다음 오류 메시지와 함께 작업이 실패합니다.
Unable to upload project files to working directory in AzureBlob because the authorization failed.
작업이 프로젝트 파일을 AzureBlob에 업로드하려고 할 때 권한 부여가 실패했기 때문입니다. 다음 항목을 확인하여 문제를 해결할 수 있습니다.
- 스토리지 계정이 '신뢰할 수 있는 서비스 목록의 Azure 서비스가 이 스토리지 계정에 액세스하도록 허용' 예외를 사용하도록 설정했고 작업 영역이 리소스 인스턴스 목록에 있는지 확인합니다.
- 작업 영역에 시스템 할당 관리 ID가 있는지 확인합니다.
프라이빗 링크 문제
이 방법으로 Kubernetes 클러스터의 한 Pod에 로그인한 다음, 관련 네트워크 설정을 확인하여 프라이빗 링크 설정을 확인할 수 있습니다.
Azure Portal에서 작업 영역 ID를 찾거나 명령줄에서
az ml workspace show를 실행하여 이 ID를 가져옵니다.kubectl get po -n azureml -l azuremlappname=azureml-fe에서 실행하는 모든 azureml-fe Pod를 표시합니다.그중 하나로 로그인하여
kubectl exec -it -n azureml {scorin_fe_pod_name} bash을(를) 실행합니다.클러스터에서 프록시를 사용하지 않는 경우
nslookup {workspace_id}.workspace.{region}.api.azureml.ms를 실행합니다. VNet에서 작업 영역으로 프라이빗 링크를 올바르게 설정한 경우 VNet의 내부 IP가 DNSLookup 도구를 통해 응답해야 합니다.클러스터에서 프록시를 사용하는 경우
curl작업 영역을 사용해 볼 수 있습니다.
curl https://{workspace_id}.workspace.westcentralus.api.azureml.ms/metric/v2.0/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/api/2.0/prometheus/post -X POST -x {proxy_address} -d {} -v -k
프록시 및 작업 영역이 프라이빗 링크로 올바르게 설정되면 내부 IP에 연결하려는 시도를 관찰해야 합니다. 토큰이 제공되지 않은 경우 이 시나리오에서는 HTTP 401 상태 코드가 포함된 응답이 필요합니다.
기타 알려진 문제
Kubernetes 컴퓨팅 업데이트가 적용되지 않음
현재 CLI v2 및 SDK v2에서는 기존 Kubernetes 컴퓨팅 구성 업데이트를 허용하지 않습니다. 예를 들어, 네임스페이스를 변경해도 적용되지 않습니다.
작업 영역 또는 리소스 그룹 이름은 '-'로 끝납니다.
Kubernetes 컴퓨팅에서 배포, 엔드포인트 또는 작업과 같은 워크로드를 만들 때 "InternalServerError" 오류가 발생하는 일반적인 원인은 작업 영역 또는 리소스 그룹 이름 끝에 '-'와 같은 특수 문자가 있기 때문입니다.