프로덕션에 배포된 모델의 성능 모니터링
적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure Machine Learning의 모델 모니터링을 사용하여 프로덕션에서 Machine Learning 모델의 성능을 지속적으로 추적하는 방법을 알아봅니다. 모델 모니터링은 모니터링 신호에 대한 광범위한 보기를 제공하고 잠재적인 문제에 대해 경고합니다. 프로덕션 중인 모델의 신호 및 성능 메트릭을 모니터링하면 이와 관련된 내재적 위험을 비판적으로 평가하고 비즈니스에 부정적인 영향을 미칠 수 있는 사각지대를 식별할 수 있습니다.
이 문서에서는 다음 작업을 수행하는 방법을 알아봅니다.
- Azure Machine Learning 온라인 엔드포인트에 배포되는 모델에 대한 기본 및 고급 모니터링 설정
- 프로덕션 중인 모델의 성능 메트릭 모니터링
- Azure Machine Learning 외부에 배포되거나 Azure Machine Learning 일괄 처리 엔드포인트에 배포되는 모니터 모델
- 사용자 지정 신호 및 메트릭을 사용하여 모델 모니터링 설정
- 모니터링 결과 해석
- Azure Event Grid와 Azure Machine Learning 모델 모니터링 통합
필수 조건
이 문서의 단계를 수행하기 전에 다음과 같은 필수 구성 요소가 있는지 확인합니다.
Azure CLI 및 Azure CLI에 대한
ml확장. 자세한 내용은 CLI(v2) 설치, 설정 및 사용을 참조하세요.Important
이 문서의 CLI 예제에서는 Bash(또는 호환) 셸을 사용한다고 가정합니다. 예를 들어 Linux 시스템 또는 Linux용 Windows 하위 시스템에서 이러한 예제를 사용합니다.
Azure Machine Learning 작업 영역 없는 경우 CLI(v2) 설치, 설정 및 사용의 단계를 사용하여 새로 만듭니다.
Azure RBAC(Azure 역할 기반 액세스 제어)는 Azure Machine Learning의 작업에 대한 액세스 권한을 부여하는 데 사용됩니다. 이 문서의 단계를 수행하려면 사용자 계정에 Azure Machine Learning 작업 영역에 대한 소유자 또는 기여자 역할이 할당되거나
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*를 허용하는 사용자 지정 역할이 할당되어야 합니다. 자세한 내용은 Azure Machine Learning 작업 영역 액세스 관리를 참조하세요.Azure Machine Learning 온라인 엔드포인트(관리형 온라인 엔드포인트 또는 Kubernetes 온라인 엔드포인트)에 배포된 모델을 모니터링하는 경우 다음을 확인합니다.
Azure Machine Learning 온라인 엔드포인트에 모델이 이미 배포되어 있습니다. 관리형 온라인 엔드포인트와 Kubernetes 온라인 엔드포인트가 모두 지원됩니다. Azure Machine Learning 온라인 엔드포인트에 배포된 모델이 없는 경우 온라인 엔드포인트를 사용하여 기계 학습 모델 배포 및 점수 매기기를 참조하세요.
모델 배포에 대한 데이터 수집을 사용하도록 설정합니다. Azure Machine Learning 온라인 엔드포인트에 대한 배포 단계 중에 데이터 수집을 사용하도록 설정할 수 있습니다. 자세한 내용은 실시간 엔드포인트에 배포된 모델에서 프로덕션 데이터 수집을 참조하세요.
Azure Machine Learning 일괄 처리 엔드포인트에 배포되거나 Azure Machine Learning 외부에서 배포되는 모델을 모니터링하는 경우 다음을 확인합니다.
- 프로덕션 데이터를 수집하고 Azure Machine Learning 데이터 자산으로 등록할 수 있는 방법이 있습니다.
- 모델 모니터링을 위해 등록된 데이터 자산을 지속적으로 업데이트합니다.
- (권장) 계보 추적을 위해 모델을 Azure Machine Learning 작업 영역에 등록합니다.
Important
모델 모니터링 작업은 Standard_E4s_v3, Standard_E8s_v3, Standard_E16s_v3, Standard_E32s_v3 및 Standard_E64s_v3의 VM 인스턴스 유형에 대한 지원이 있는 서버리스 Spark 컴퓨팅 풀에서 실행되도록 예약됩니다. YAML 구성의 create_monitor.compute.instance_type 속성을 사용하거나 Azure Machine Learning 스튜디오의 드롭다운에서 VM 인스턴스 유형을 선택할 수 있습니다.
기본 모델 모니터링 설정
Azure Machine Learning 온라인 엔드포인트에서 프로덕션에 모델을 배포하고 배포 시 데이터 수집을 사용하도록 설정한다고 가정합니다. 이 시나리오에서 Azure Machine Learning은 프로덕션 유추 데이터를 수집하고 Microsoft Azure Blob Storage에 자동으로 저장합니다. 그런 다음, Azure Machine Learning 모델 모니터링을 사용하여 이 프로덕션 유추 데이터를 지속적으로 모니터링할 수 있습니다.
모델 모니터링의 기본 설정에 Azure CLI, Python SDK 또는 스튜디오를 사용할 수 있습니다. 기본 모델 모니터링 구성은 다음과 같은 모니터링 기능을 제공합니다.
- Azure Machine Learning은 Azure Machine Learning 온라인 배포와 연결된 프로덕션 유추 데이터 세트를 자동으로 검색하고 모델 모니터링에 데이터 세트를 사용합니다.
- 비교 참조 데이터 세트는 최근 과거 프로덕션 유추 데이터 세트로 설정됩니다.
- 모니터링 설정에는 데이터 드리프트, 예측 드리프트 및 데이터 품질과 같은 기본 제공 모니터링 신호가 자동으로 포함되고 추적됩니다. 각 모니터링 신호에 대해 Azure Machine Learning은 다음을 사용합니다.
- 최근 프로덕션 유추 데이터 세트를 비교 참조 데이터 세트로 사용합니다.
- 메트릭 및 임계값에 대한 스마트 기본값입니다.
- 모니터링 작업은 모니터링 신호를 획득하고 해당 임계값에 대해 각 메트릭 결과를 평가하기 위해 매일 오전 3시 15분(이 예제의 경우)에 실행되도록 예약됩니다. 기본적으로 임계값을 초과하는 경우 Azure Machine Learning은 모니터를 설정한 사용자에게 경고 이메일을 보냅니다.
Azure Machine Learning 모델 모니터링은 az ml schedule을 사용하여 모니터링 작업을 예약합니다. 다음 CLI 명령 및 YAML 정의를 사용하여 기본 모델 모니터를 만들 수 있습니다.
az ml schedule create -f ./out-of-box-monitoring.yaml
다음 YAML에는 기본 제공 모델 모니터링에 대한 정의가 포함되어 있습니다.
# out-of-box-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: credit_default_model_monitoring
display_name: Credit default model monitoring
description: Credit default model monitoring setup with minimal configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute: # specify a spark compute for monitoring job
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification # model task type: [classification, regression, question_answering]
endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id
alert_notification: # emails to get alerts
emails:
- abc@example.com
- def@example.com


고급 모델 모니터링 설정
Azure Machine Learning은 지속적인 모델 모니터링을 위해 많은 기능을 제공합니다. 이러한 기능의 포괄적인 목록은 모델 모니터링의 기능을 참조하세요. 대부분의 경우 고급 모니터링 기능을 사용하여 모델 모니터링을 설정해야 합니다. 다음 섹션에서는 이러한 기능을 사용하여 모델 모니터링을 설정합니다.
- 광범위한 보기를 위해 여러 모니터링 신호를 사용합니다.
- 기록 모델 학습 데이터 또는 유효성 검사 데이터를 비교 참조 데이터 세트로 사용합니다.
- 상위 N개의 가장 중요한 기능 및 개별 기능 모니터링
기능 중요도 구성
기능 중요도는 모델의 출력에 대한 각 입력 기능의 상대적 중요도를 나타냅니다. 예를 들어 temperature는 elevation에 비해 모델의 예측에 더 중요할 수 있습니다. 기능 중요도를 사용하도록 설정하면 프로덕션 환경에서 드리프트하거나 데이터 품질 문제를 겪지 않으려는 기능을 파악할 수 있습니다.
신호(예: 데이터 드리프트 또는 데이터 품질)에서 기능 중요도를 사용하도록 설정하려면 다음을 제공해야 합니다.
-
reference_data데이터 세트로 학습 데이터 세트 - 모델의 출력/예측 열의 이름인
reference_data.data_column_names.target_column속성
기능 중요도를 사용하도록 설정하면 Azure Machine Learning 모델 모니터링 스튜디오 UI에서 모니터링하는 각 기능에 대한 기능 중요도가 표시됩니다.
SDK 또는 CLI를 사용하는 동안 속성을 설정 alert_enabled 하여 각 신호에 대한 경고를 사용하거나 사용하지 않도록 설정할 수 있습니다.
모델 모니터링의 고급 설정에 Azure CLI, Python SDK 또는 스튜디오를 사용할 수 있습니다.
다음 CLI 명령 및 YAML 정의를 사용하여 고급 모델 모니터링 설정을 만듭니다.
az ml schedule create -f ./advanced-model-monitoring.yaml
다음 YAML에는 고급 모델 모니터링에 대한 정의가 포함되어 있습니다.
# advanced-model-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with advanced configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:credit-default:main
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1 # use training data as comparison reference dataset
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
features:
top_n_feature_importance: 10 # monitor drift for top 10 features
alert_enabled: true
metric_thresholds:
numerical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_data_quality:
type: data_quality
# reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
features: # monitor data quality for 3 individual features only
- SEX
- EDUCATION
alert_enabled: true
metric_thresholds:
numerical:
null_value_rate: 0.05
categorical:
out_of_bounds_rate: 0.03
feature_attribution_drift_signal:
type: feature_attribution_drift
# production_data: is not required input here
# Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data
# Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
alert_enabled: true
metric_thresholds:
normalized_discounted_cumulative_gain: 0.9
alert_notification:
emails:
- abc@example.com
- def@example.com






모델 성능 모니터링 설정
Azure Machine Learning 모델 모니터링을 사용하면 성능 메트릭을 계산하여 프로덕션에서 모델의 성능을 추적할 수 있습니다. 현재 다음 모델 성능 메트릭이 지원됩니다.
분류 모델의 경우:
- 정밀도
- 정확도
- 재현율
회귀 모델의 경우:
- MAE(평균 절대 오차)
- MSE(평균 제곱 오차)
- RMSE(제곱 평균 오차)
모델 성능 모니터링을 위한 추가 필수 조건
모델 성능 신호를 구성하려면 다음 요구 사항을 충족해야 합니다.
각 행에 대한 고유 ID를 사용하여 프로덕션 모델(모델의 예측)에 대한 출력 데이터를 갖습니다. Azure Machine Learning 데이터 수집기를 사용하여 프로덕션 데이터를 수집하는 경우 각 유추 요청에 대해
correlation_id가 제공됩니다. 데이터 수집기를 사용하면 애플리케이션에서 고유한 ID를 기록할 수도 있습니다.참고 항목
Azure Machine Learning 모델 성능 모니터링의 경우 Azure Machine Learning 데이터 수집기를 사용하여 자체 열에 고유 ID를 기록하는 것이 좋습니다.
각 행마다 고유한 ID가 있는 참조 자료 데이터(참조 자료)가 있습니다. 특정 행의 고유 ID는 해당 특정 유추 요청에 대한 모델 출력의 고유 ID와 일치해야 합니다. 이 고유 ID는 참조 자료 데이터 세트를 모델 출력과 조인하는 데 사용됩니다.
참조 자료 데이터가 없으면 모델 성능 모니터링을 수행할 수 없습니다. 참조 자료 데이터는 애플리케이션 수준에서 발견되므로, 사용 가능해지면 이를 수집하는 것은 사용자의 책임입니다. 또한 이 참조 자료 데이터가 포함된 Azure Machine Learning의 데이터 자산을 유지 관리해야 합니다.
(선택 사항) 모델 출력과 참조 자료 데이터가 사전 조인된 표 형식 데이터 세트가 있습니다.
데이터 수집기를 사용할 때 모델 성능 요구 사항 모니터링
각 행에 대한 고유 ID를 별도의 열로 제공하지 않고 Azure Machine Learning 데이터 수집기를 사용하여 프로덕션 유추 데이터를 수집하는 경우 correlationid가 자동으로 생성되어 로깅된 JSON 개체에 포함됩니다. 그러나 데이터 수집기는 서로 짧은 시간 간격으로 전송되는 행을 일괄 처리합니다. 일괄 처리된 행은 동일한 JSON 개체에 속하므로 동일한 correlationid를 갖게 됩니다.
동일한 JSON 개체의 행을 구별하기 위해 Azure Machine Learning 모델 성능 모니터링은 인덱싱을 사용하여 JSON 개체의 행 순서를 결정합니다. 예를 들어, 세 개의 행이 함께 일괄 처리되고 correlationid가 test인 경우 행 1의 ID는 test_0, 행 2의 ID는 test_1, 행 3의 ID는 test_2입니다. 참조 자료 데이터 세트에 수집된 프로덕션 유추 모델 출력과 일치하는 고유 ID가 포함되도록 하려면 각 correlationid의 인덱스를 적절하게 생성해야 합니다. 기록된 JSON 개체에 행이 하나만 있는 경우 correlationid는 correlationid_0입니다.
이 인덱싱을 사용하지 않으려면 Azure Machine Learning 데이터 수집기로 로깅하는 Pandas DataFrame 내의 자체 열에 고유 ID를 기록하는 것이 좋습니다. 그런 다음 모델 모니터링 구성에서 이 열의 이름을 지정하여 모델 출력 데이터를 참조 자료 데이터와 조인합니다. 두 데이터 세트의 각 행에 대한 ID가 동일하다면 Azure Machine Learning 모델 모니터링은 모델 성능 모니터링을 수행할 수 있습니다.
모델 성능 모니터링을 위한 워크플로 예
모델 성능 모니터링과 관련된 개념을 이해하려면 이 예 워크플로를 고려합니다. 신용 카드 트랜잭션이 사기인지 여부를 예측하기 위해 모델을 배포한다고 가정하면 다음 단계에 따라 모델 성능을 모니터링할 수 있습니다.
- 데이터 수집기를 사용하여 모델의 프로덕션 유추 데이터(입력 및 출력 데이터)를 수집하도록 배포를 구성합니다. 출력 데이터가
is_fraud열에 저장되어 있다고 가정해 보겠습니다. - 수집된 유추 데이터의 각 행에 대해 고유 ID를 기록합니다. 고유 ID는 애플리케이션에서 가져오거나, 기록된 각 JSON 개체에 대해 Azure Machine Learning이 고유하게 생성하는
correlationid를 사용할 수 있습니다. - 나중에 참조 자료(또는 실제)
is_fraud데이터를 사용할 수 있게 되면 이 데이터도 모델의 출력과 함께 기록된 동일한 고유 ID에 기록되고 매핑됩니다. - 이 참조 자료
is_fraud데이터도 Azure Machine Learning에 데이터 자산으로 수집, 유지 관리 및 등록됩니다. - 고유한 ID 열을 사용하여 모델의 프로덕션 유추와 참조 자료 데이터 자산을 조인하는 모델 성능 모니터링 신호를 만듭니다.
- 마지막으로 모델 성능 메트릭을 계산합니다.
모델 성능 모니터링 필수 조건을 충족하면 다음 CLI 명령과 YAML 정의를 사용하여 모델 모니터링을 설정할 수 있습니다.
az ml schedule create -f ./model-performance-monitoring.yaml
다음 YAML에는 수집한 프로덕션 유추 데이터를 사용하여 모델 모니터링에 대한 정의가 포함되어 있습니다.
$schema: http://azureml/sdk-2-0/Schedule.json
name: model_performance_monitoring
display_name: Credit card fraud model performance
description: Credit card fraud model performance
trigger:
type: recurrence
frequency: day
interval: 7
schedule:
hours: 10
minutes: 15
create_monitor:
compute:
instance_type: standard_e8s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment
monitoring_signals:
fraud_detection_model_performance:
type: model_performance
production_data:
data_column_names:
prediction: is_fraud
correlation_id: correlation_id
reference_data:
input_data:
path: azureml:my_model_ground_truth_data:1
type: mltable
data_column_names:
actual: is_fraud
correlation_id: correlation_id
data_context: actuals
alert_enabled: true
metric_thresholds:
tabular_classification:
accuracy: 0.95
precision: 0.8
alert_notification:
emails:
- abc@example.com





Azure Machine Learning에 프로덕션 데이터를 가져와 모델 모니터링 설정
Azure Machine Learning 일괄 처리 엔드포인트에 배포되거나 Azure Machine Learning 외부에 배포된 모델에 대한 모델 모니터링을 설정할 수도 있습니다. 배포가 없지만 프로덕션 데이터가 있는 경우 데이터를 사용하여 지속적인 모델 모니터링을 수행할 수 있습니다. 이러한 모델을 모니터링하려면 다음을 수행할 수 있어야 합니다.
- 프로덕션에 배포된 모델에서 프로덕션 유추 데이터를 수집합니다.
- 프로덕션 유추 데이터를 Azure Machine Learning 데이터 자산으로 등록하고 데이터의 지속적인 업데이트를 보장합니다.
- 사용자 지정 데이터 전처리 구성 요소를 제공하고 Azure Machine Learning 구성 요소로 등록합니다.
데이터 수집기로 데이터를 수집하지 않는 경우 사용자 지정 데이터 전처리 구성 요소를 제공해야 합니다. 이 사용자 지정 데이터 전처리 구성 요소가 없으면 Azure Machine Learning 모델 모니터링 시스템에서 시간 창을 지원하는 테이블 형식으로 데이터를 처리하는 방법을 알 수 없습니다.
사용자 지정 전처리 구성 요소에는 다음과 같은 입력 및 출력 서명이 있어야 합니다.
| 입/출력 | 서명 이름 | Type | 설명 | 예제 값 |
|---|---|---|---|---|
| input | data_window_start |
리터럴, 문자열 | ISO8601 형식의 데이터 창 시작 시간 | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
리터럴, 문자열 | ISO8601 형식의 데이터 창 종료 시간 | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | Azure Machine Learning 데이터 자산으로 등록된 수집된 프로덕션 유추 데이터 | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | 참조 데이터 스키마의 하위 집합과 일치하는 테이블 형식 데이터 세트 |
사용자 지정 데이터 전처리 구성 요소의 예제는 azuremml-examples GitHub 리포지토리의 custom_preprocessing을 참조하세요.
이전 요구 사항을 충족하면 다음 CLI 명령 및 YAML 정의를 사용하여 모델 모니터링을 설정할 수 있습니다.
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
다음 YAML에는 수집한 프로덕션 유추 데이터를 사용하여 모델 모니터링에 대한 정의가 포함되어 있습니다.
# model-monitoring-with-collected-data.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with your own production data
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_inputs
pre_processing_component: azureml:production_data_preprocessing:1.0.0
reference_data:
input_data:
path: azureml:my_model_training_data:1 # use training data as comparison baseline
type: mltable
data_context: training
data_column_names:
target_column: is_fraud
features:
top_n_feature_importance: 20 # monitor drift for top 20 features
alert_enabled: true
metric_thresholds:
numerical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_prediction_drift: # monitoring signal name, any user defined name works
type: prediction_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_outputs
pre_processing_component: azureml:production_data_preprocessing:1.0.0
reference_data:
input_data:
path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset
type: mltable
data_context: validation
alert_enabled: true
metric_thresholds:
categorical:
pearsons_chi_squared_test: 0.02
alert_notification:
emails:
- abc@example.com
- def@example.com
사용자 지정 신호 및 메트릭을 사용하여 모델 모니터링 설정
Azure Machine Learning 모델 모니터링을 사용하면 사용자 지정 신호를 정의하고 선택한 메트릭을 구현하여 모델을 모니터링할 수 있습니다. 이 사용자 지정 신호를 Azure Machine Learning 구성 요소로 등록할 수 있습니다. Azure Machine Learning 모델 모니터링 작업이 지정된 일정에 따라 실행되면 미리 빌드된 신호(데이터 드리프트, 예측 드리프트 및 데이터 품질)와 마찬가지로 사용자 지정 신호 내에서 정의한 메트릭을 계산합니다.
모델 모니터링에 사용할 사용자 지정 신호를 설정하려면 먼저 사용자 지정 신호를 정의하고 Azure Machine Learning 구성 요소로 등록해야 합니다. Azure Machine Learning 구성 요소에는 다음과 같은 입력 및 출력 서명이 있어야 합니다.
구성 요소 입력 서명
구성 요소 입력 DataFrame에는 다음 항목이 포함되어야 합니다.
- 전처리 구성 요소의 처리된 데이터가 포함된
mltable - 사용자 지정 신호 구성 요소의 일부로 구현된 메트릭을 각각 나타내는 리터럴 수 예를 들어 하나의 메트릭
std_deviation을 구현한 경우std_deviation_threshold에 대한 입력이 필요합니다. 일반적으로 이름이<metric_name>_threshold인 메트릭당 하나의 입력이 있어야 합니다.
| 서명 이름 | Type | 설명 | 예제 값 |
|---|---|---|---|
| production_data | mltable | 참조 데이터 스키마의 하위 집합과 일치하는 테이블 형식 데이터 세트 | |
| std_deviation_threshold | 리터럴, 문자열 | 구현된 메트릭에 대한 각 임계값 | 2 |
구성 요소 출력 서명
구성 요소 출력 포트에는 다음 서명이 있어야 합니다.
| 서명 이름 | Type | 설명 |
|---|---|---|
| signal_metrics | mltable | 계산된 메트릭을 포함하는 mltable 스키마는 다음 섹션 signal_metrics schema에서 정의됩니다. |
signal_metrics 스키마
구성 요소 출력 DataFrame에는 group, metric_name, metric_value 및 threshold_value의 네 개의 열이 포함되어야 합니다.
| 서명 이름 | Type | 설명 | 예제 값 |
|---|---|---|---|
| group | 리터럴, 문자열 | 이 사용자 지정 메트릭에 적용할 최상위 수준 논리 그룹화 | TRANSACTIONAMOUNT |
| metric_name | 리터럴, 문자열 | 사용자 지정 메트릭의 이름 | std_deviation |
| metric_value | 숫자 | 사용자 지정 메트릭의 값 | 44,896.082 |
| threshold_value | 숫자 | 사용자 지정 메트릭에 대한 임계값 | 2 |
다음 표에서는 std_deviation 메트릭을 계산하는 사용자 지정 신호 구성 요소의 예제 출력을 보여 줍니다.
| group | metric_value | metric_name | threshold_value |
|---|---|---|---|
| TRANSACTIONAMOUNT | 44,896.082 | std_deviation | 2 |
| LOCALHOUR | 3.983 | std_deviation | 2 |
| TRANSACTIONAMOUNTUSD | 54,004.902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7.238 | std_deviation | 2 |
| PHYSICALITEMCOUNT | 5.509 | std_deviation | 2 |
사용자 지정 신호 구성 요소 정의 및 메트릭 계산 코드 예제를 보려면 azureml-examples 리포지토리의 custom_signal을 참조하세요.
사용자 지정 신호 및 메트릭을 사용하기 위한 요구 사항을 충족하면 다음 CLI 명령 및 YAML 정의를 사용하여 모델 모니터링을 설정할 수 있습니다.
az ml schedule create -f ./custom-monitoring.yaml
다음 YAML에는 사용자 지정 신호를 사용한 모델 모니터링에 대한 정의가 포함되어 있습니다. 코드에 대해 알아야 할 몇 가지 사항은 다음과 같습니다.
- Azure Machine Learning에 사용자 지정 신호 정의를 사용하여 구성 요소를 이미 만들고 등록했다고 가정합니다.
- 등록된 사용자 정의 신호 구성요소의
component_id는azureml:my_custom_signal:1.0.0입니다. -
데이터 수집기를 사용하여 데이터를 수집한 경우
pre_processing_component속성을 생략할 수 있습니다. 전처리 구성 요소를 사용하여 데이터 수집기에서 수집하지 않은 프로덕션 데이터를 전처리하려는 경우 이를 지정할 수 있습니다.
# custom-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: my-custom-signal
trigger:
type: recurrence
frequency: day # can be minute, hour, day, week, month
interval: 7 # #every day
create_monitor:
compute:
instance_type: "standard_e4s_v3"
runtime_version: "3.3"
monitoring_signals:
customSignal:
type: custom
component_id: azureml:my_custom_signal:1.0.0
input_data:
production_data:
input_data:
type: uri_folder
path: azureml:my_production_data:1
data_context: test
data_window:
lookback_window_size: P30D
lookback_window_offset: P7D
pre_processing_component: azureml:custom_preprocessor:1.0.0
metric_thresholds:
- metric_name: std_deviation
threshold: 2
alert_notification:
emails:
- abc@example.com
모니터링 결과 해석
모델 모니터를 구성하고 첫 번째 실행이 완료되면 Azure Machine Learning 스튜디오의 모니터링 탭으로 다시 이동하여 결과를 볼 수 있습니다.
기본 모니터링 보기에서 모델 모니터의 이름을 선택하여 모니터 개요 페이지를 확인합니다. 이 페이지에는 구성한 신호에 대한 세부 정보와 함께 해당 모델, 엔드포인트 및 배포가 표시됩니다. 다음 이미지는 데이터 드리프트 및 데이터 품질 신호를 포함하는 모니터링 대시보드를 보여 줍니다. 구성한 모니터링 신호에 따라 대시보드가 다르게 보일 수 있습니다.
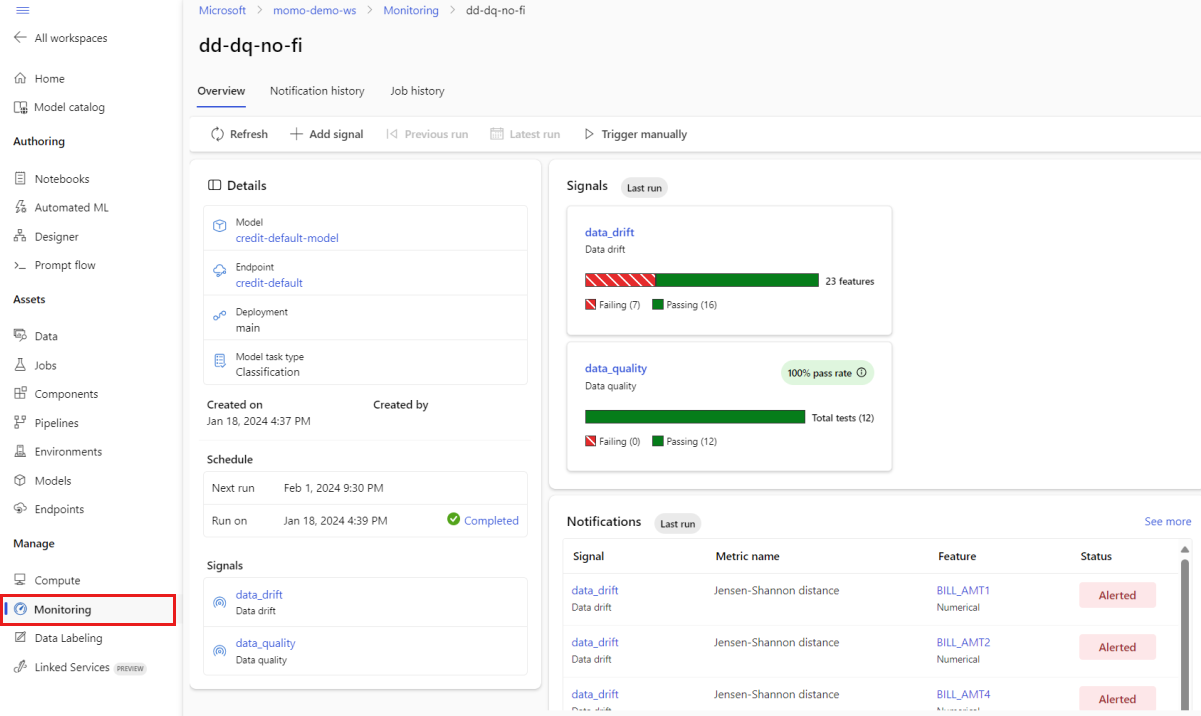
대시보드의 알림 섹션에서 각 신호에 대해 해당 메트릭에 대해 구성된 임계값을 위반하는 기능을 확인합니다.
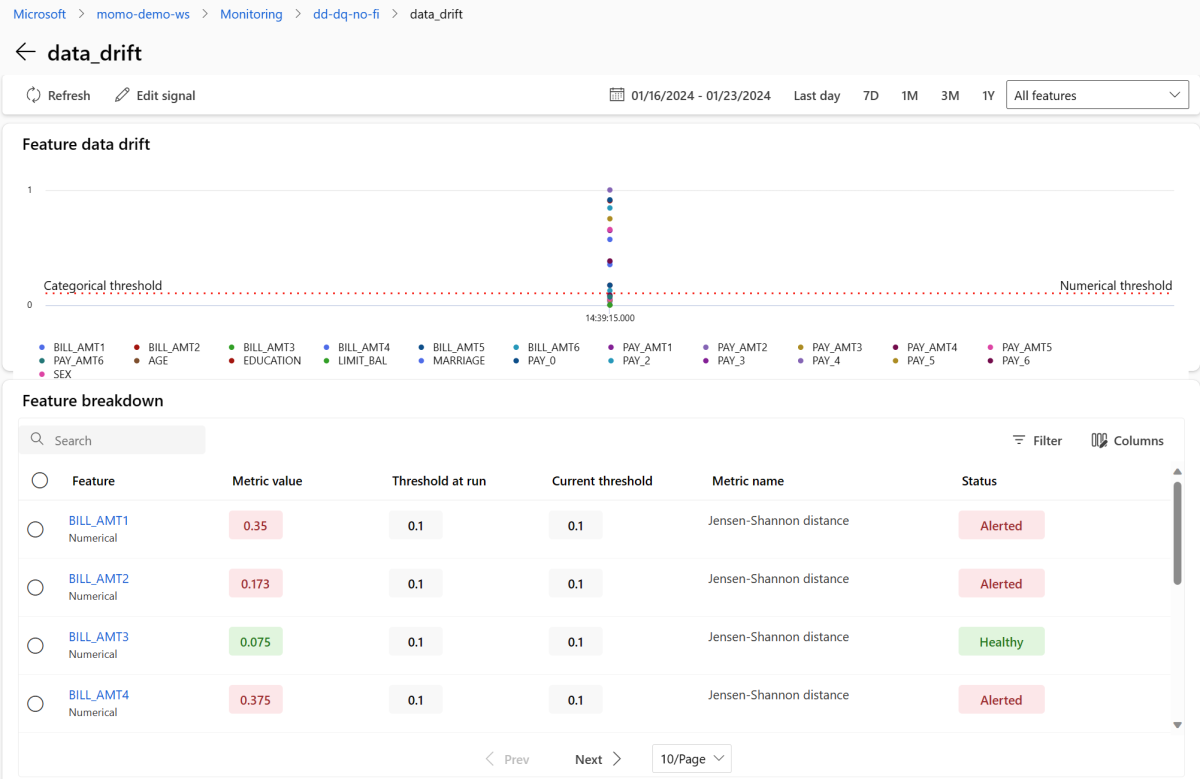
data_drift를 선택하여 데이터 드리프트 세부 정보 페이지로 이동합니다. 세부 정보 페이지에서 모니터링 구성에 포함된 각 숫자 및 범주 기능에 대한 데이터 드리프트 메트릭 값을 볼 수 있습니다. 모니터에 둘 이상의 실행이 있는 경우 각 기능에 대한 추세선이 표시됩니다.
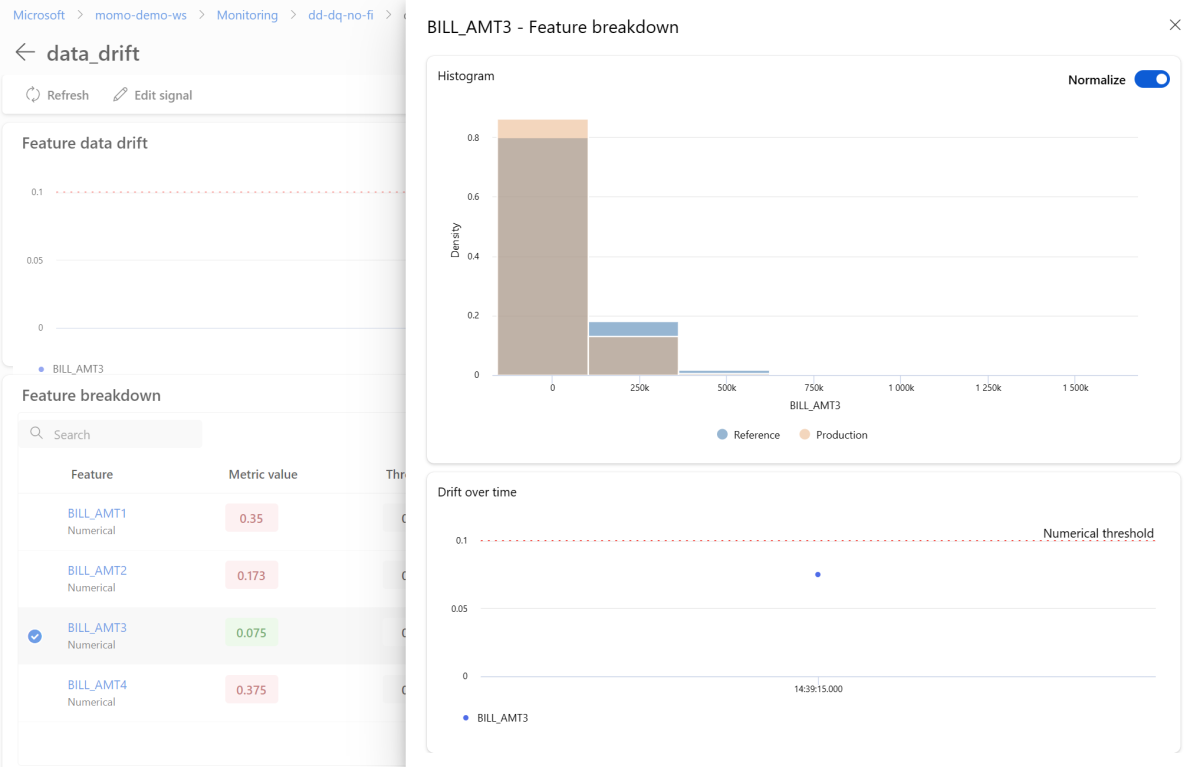
개별 기능을 자세히 보려면 참조 배포와 비교하여 프로덕션 배포를 볼 기능의 이름을 선택합니다. 또한 이 보기를 사용하면 해당 특정 기능에 대해 시간이 지남에 따라 드리프트를 추적할 수 있습니다.
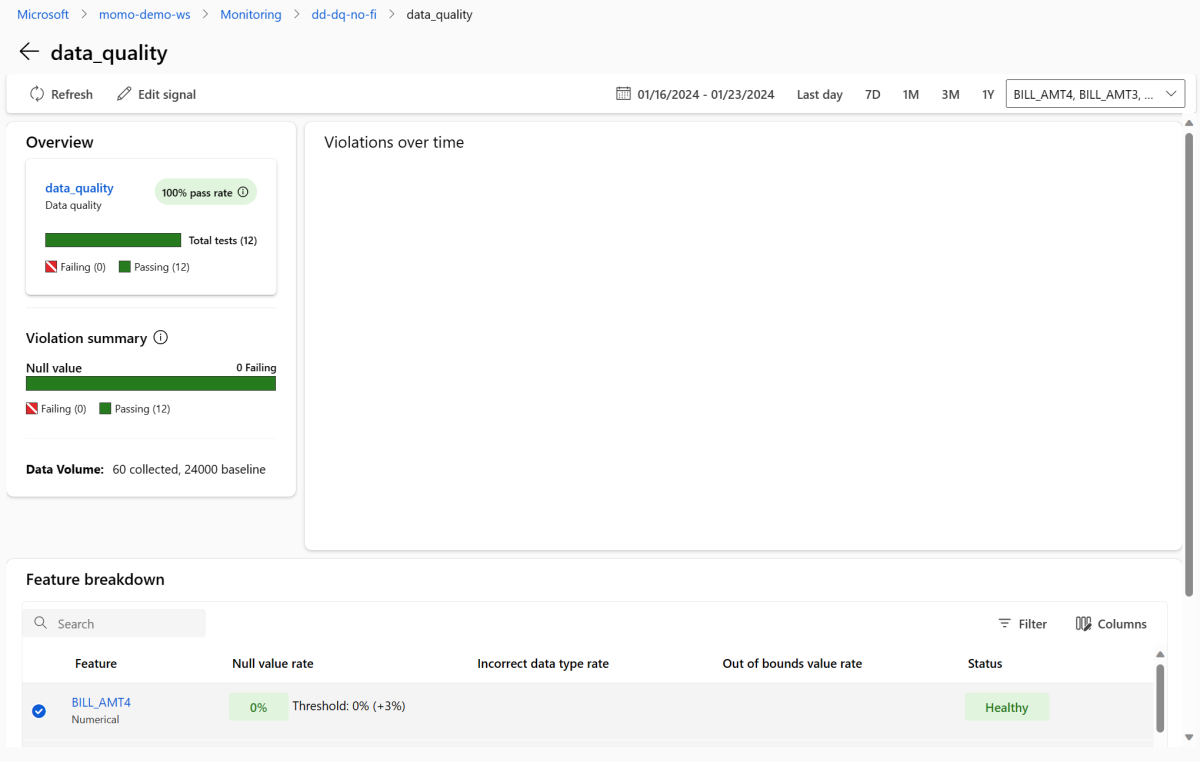
모니터링 대시보드로 돌아가서 data_quality를 선택하여 데이터 품질 신호 페이지를 봅니다. 이 페이지에서 모니터링하는 각 기능에 대한 null 값 속도, 범위를 벗어난 속도 및 데이터 형식 오류 비율을 볼 수 있습니다.




모델 모니터링은 연속 프로세스입니다. Azure Machine Learning 모델 모니터링을 사용하면 여러 모니터링 신호를 구성하여 프로덕션 환경에서 모델의 성능을 광범위하게 볼 수 있습니다.
Azure Event Grid와 Azure Machine Learning 모델 모니터링 통합
Azure Machine Learning 모델 모니터링에서 생성된 이벤트를 사용하여 Azure Event Grid에서 이벤트 기반 애플리케이션, 프로세스 또는 CI/CD 워크플로를 설정할 수 있습니다. Azure Event Hubs, Azure 함수 및 논리 앱과 같은 다양한 이벤트 처리기를 통해 이벤트를 사용할 수 있습니다. 모니터에서 검색한 드리프트에 따라 기계 학습 파이프라인을 설정하여 모델을 다시 학습시키고 다시 배포하는 등의 작업을 프로그래밍 방식으로 수행할 수 있습니다.
Event Grid와 Azure Machine Learning 모델 모니터링 통합을 시작하려면 다음을 수행합니다.
Azure Portal에서 설정의 단계를 따릅니다. 이벤트 구독에 이름(예: MonitoringEvent)을 지정하고 이벤트 유형 아래에서 Run status changed 상자만 선택합니다.
Warning
이벤트 유형에 대해 Run status changed를 선택해야 합니다. Azure Machine Learning 모델 모니터링 대신 데이터 드리프트 v1에 적용되므로 Dataset drift detected를 선택하지 마세요.
이벤트 필터링 및 구독의 단계에 따라 시나리오에 대한 이벤트 필터링을 설정합니다. 필터 탭으로 이동하여 고급 필터 아래에서 다음 키, 연산자 및 값을 추가합니다.
-
키:
data.RunTags.azureml_modelmonitor_threshold_breached - 값: 메트릭 임계값을 위반하는 하나 이상의 기능으로 인해 실패함
- 연산자: 문자열 포함
이 필터를 사용하면 Azure Machine Learning 작업 영역 내의 모든 모니터에 대해 실행 상태가 변경될 때(완료됨에서 실패로 또는 실패에서 완료됨으로) 이벤트가 생성됩니다.
-
키:
모니터링 수준에서 필터링하려면 고급 필터 아래에서 키, 연산자 및 값을 사용합니다.
-
키:
data.RunTags.azureml_modelmonitor_threshold_breached -
값:
your_monitor_name_signal_name - 연산자: 문자열 포함
your_monitor_name_signal_name이 이벤트를 필터링하려는 특정 모니터의 신호 이름인지 확인합니다. 예:credit_card_fraud_monitor_data_drift. 이 필터가 작동하려면 이 문자열이 모니터링 신호의 이름과 일치해야 합니다. 이 경우 모니터 이름과 신호 이름을 모두 사용하여 신호 이름을 지정해야 합니다.-
키:
이벤트 구독 구성을 완료한 경우 Azure Event Hubs와 같은 이벤트 처리기로 사용할 원하는 엔드포인트를 선택합니다.
이벤트가 캡처된 후 엔드포인트 페이지에서 볼 수 있습니다.

Azure Monitor 메트릭 탭에서 이벤트를 볼 수도 있습니다.
