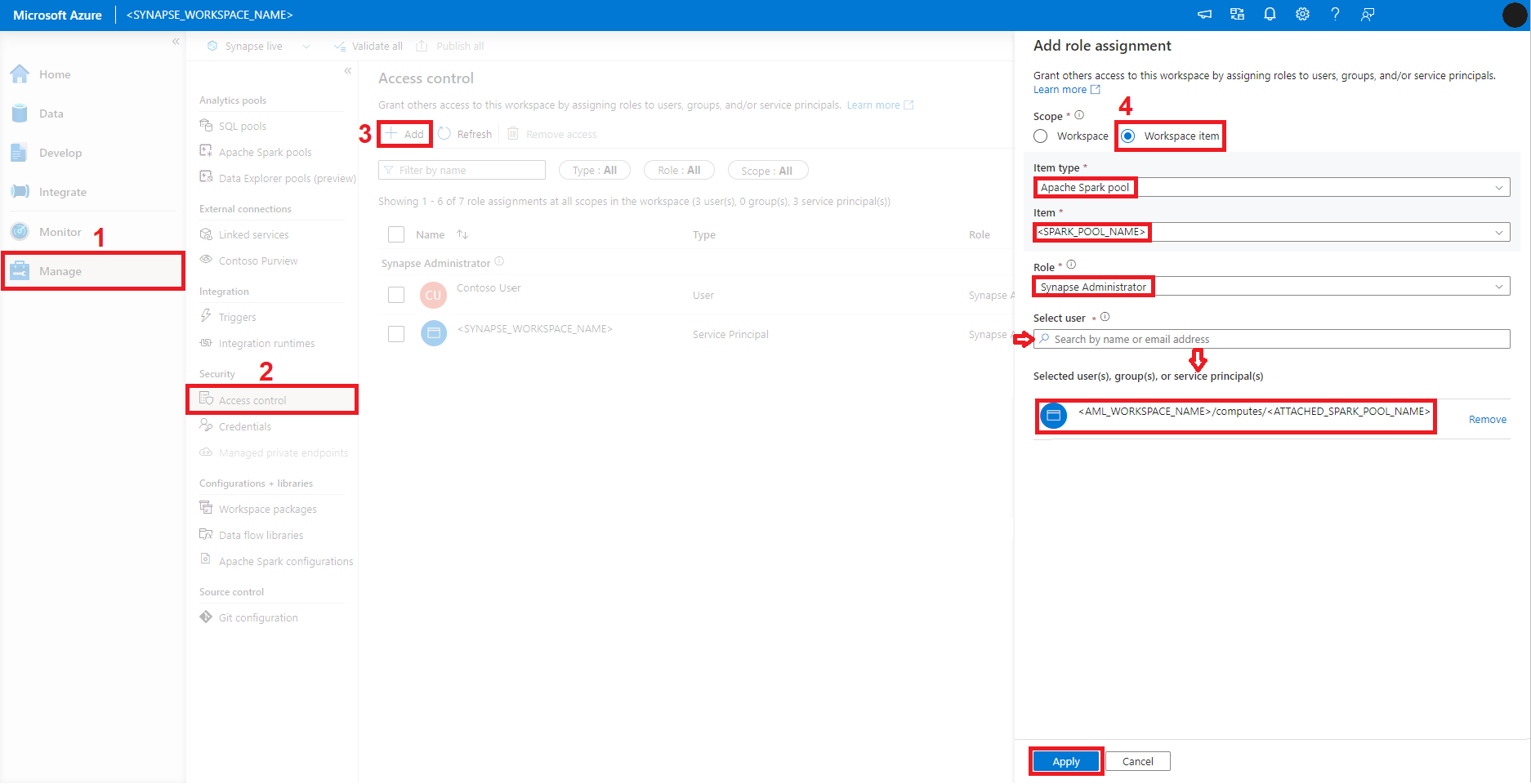
적용 대상:  Azure CLI ml 확장 v2(현재)
Azure CLI ml 확장 v2(현재)
Azure Machine Learning CLI를 사용하면 명령줄 인터페이스의 직관적인 YAML 구문과 명령을 사용하여 Synapse Spark 풀을 연결하고 관리할 수 있습니다.
YAML 구문을 사용하여 연결된 Synapse Spark 풀을 정의하려면 YAML 파일이 다음 속성을 포함해야 합니다.
name – 연결된 Synapse Spark 풀의 이름입니다.
type – 이 속성은 synapsespark로 설정합니다.
resource_id – 이 속성은 Azure Synapse Analytics 작업 영역에서 만들어진 Synapse Spark 풀의 리소스 ID 값을 제공해야 합니다. Azure 리소스 ID에는 다음이 포함됩니다.
Azure 구독 ID,
리소스 그룹 이름,
Azure Synapse Analytics 작업 영역 이름 및
Synapse Spark 풀의 이름.
name: <ATTACHED_SPARK_POOL_NAME>
type: synapsespark
resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>
identity – 이 속성은 연결된 Synapse Spark 풀에 할당할 ID 형식을 정의합니다. 다음 값 중 하나를 사용할 수 있습니다.
identity 형식 user_assigned의 경우 user_assigned_identities 값 목록도 제공해야 합니다. 각 사용자 할당 ID는 사용자 할당 ID의 resource_id 값을 사용하여 목록의 요소로 선언되어야 합니다. 목록의 첫 번째 사용자 할당 ID는 기본적으로 작업을 제출하는 데 사용됩니다.
name: <ATTACHED_SPARK_POOL_NAME>
type: synapsespark
resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>
identity:
type: user_assigned
user_assigned_identities:
- resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>
위의 YAML 파일은 az ml compute attach 명령에서 --file 매개 변수로 사용할 수 있습니다. Synapse Spark 풀은 다음과 같이 az ml compute attach 명령을 사용하여 구독의 지정된 리소스 그룹에 있는 Azure Machine Learning 작업 영역에 연결할 수 있습니다.
az ml compute attach --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
이 샘플은 위 명령의 예상 출력을 보여 줍니다.
Class SynapseSparkCompute: This is an experimental class, and may change at any time. Please visit https://aka.ms/azuremlexperimental for more information.
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-13 19:01:05.109840+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
}
YAML 사양 파일에 이름이 지정된 연결된 Synapse Spark 풀이 작업 영역에 이미 있는 경우 az ml compute attach 명령 실행은 YAML 사양 파일에 제공된 정보로 기존 풀을 업데이트합니다. YAML 사양 파일을 통해
값을 업데이트할 수 있습니다.
연결된 Synapse Spark 풀의 세부 정보를 표시하려면 az ml compute show 명령을 실행합니다. 다음과 같이 연결된 Synapse Spark 풀의 이름을 --name 매개 변수와 함께 전달합니다.
az ml compute show --name <ATTACHED_SPARK_POOL_NAME> --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
이 샘플은 위 명령의 예상 출력을 보여 줍니다.
<ATTACHED_SPARK_POOL_NAME>
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-13 19:01:05.109840+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
}
작업 영역에 연결된 Synapse Spark 풀을 포함하여 모든 컴퓨팅 목록을 보려면 az ml compute list 명령을 사용합니다. 다음과 같이 name 매개 변수를 사용하여 작업 영역의 이름을 전달합니다.
az ml compute list --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
이 샘플은 위 명령의 예상 출력을 보여 줍니다.
[
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-09 21:28:54.871251+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"identity": {
"principal_id": "<PRINCIPAL_ID>",
"tenant_id": "<TENANT_ID>",
"type": "system_assigned"
},
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
},
...
]
적용 대상: Python SDK azure-ai-ml v2(현재)
Azure Machine Learning Python SDK는 Azure Machine Learning Notebooks의 Python 코드를 사용하여 Synapse Spark 풀을 연결하고 관리하기 위한 편리한 함수를 제공합니다.
Python SDK를 사용하여 Synapse Compute를 연결하려면 먼저 azure.ai.ml.MLClient 클래스의 인스턴스를 만듭니다. Azure Machine Learning Services와의 상호 작용을 위한 편리한 함수를 제공합니다. 다음 코드 샘플은 azure.identity.DefaultAzureCredential을(를) 사용하여 지정된 Azure 구독의 리소스 그룹에 있는 작업 영역에 연결합니다. 다음 코드 샘플에서 다음 매개 변수로 SynapseSparkCompute을(를) 정의합니다.
name - 새로 연결된 Synapse Spark 풀의 사용자 정의 이름입니다.resource_id - Azure Synapse Analytics 작업 영역에서 이전에 만든 Synapse Spark 풀의 리소스 ID
azure.ai.ml.MLClient.begin_create_or_update() 함수 호출은 정의된 Synapse Spark 풀을 Azure Machine Learning 작업 영역에 연결합니다.
from azure.ai.ml import MLClient
from azure.ai.ml.entities import SynapseSparkCompute
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_comp = SynapseSparkCompute(name=synapse_name, resource_id=synapse_resource)
ml_client.begin_create_or_update(synapse_comp)
시스템 할당 ID를 사용하는 Synapse Spark 풀을 연결하려면 형식이 SystemAssigned로 설정된 IdentityConfiguration을 SynapseSparkCompute 클래스의 identity 매개 변수로 전달합니다. 이 코드 조각은 시스템 할당 ID를 사용하는 Synapse Spark 풀을 연결합니다.
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import SynapseSparkCompute, IdentityConfiguration
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_identity = IdentityConfiguration(type="SystemAssigned")
synapse_comp = SynapseSparkCompute(
name=synapse_name, resource_id=synapse_resource, identity=synapse_identity
)
ml_client.begin_create_or_update(synapse_comp)
Synapse Spark 풀은 사용자 할당 ID를 사용할 수도 있습니다. 사용자 할당 ID의 경우 IdentityConfiguration 클래스를 SynapseSparkCompute 클래스의 identity 매개 변수로 사용하여 관리 ID 정의를 전달할 수 있습니다. 이 방식으로 사용되는 관리 ID 정의의 경우 type을 UserAssigned로 설정합니다. 또한 user_assigned_identities 매개 변수를 전달합니다. user_assigned_identities 매개 변수는 UserAssignedIdentity 클래스의 개체 목록입니다. 사용자 할당 ID의 resource_id은(는) 각 UserAssignedIdentity 클래스 개체를 채웁니다. 이 코드 조각은 사용자 할당 ID를 사용하는 Synapse Spark 풀을 연결합니다.
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
SynapseSparkCompute,
IdentityConfiguration,
UserAssignedIdentity,
)
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_identity = IdentityConfiguration(
type="UserAssigned",
user_assigned_identities=[
UserAssignedIdentity(
resource_id="/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>"
)
],
)
synapse_comp = SynapseSparkCompute(
name=synapse_name, resource_id=synapse_resource, identity=synapse_identity
)
ml_client.begin_create_or_update(synapse_comp)
참고 항목
azure.ai.ml.MLClient.begin_create_or_update() 함수는 지정된 이름의 풀이 작업 영역에 아직 없는 경우 새 Synapse Spark 풀을 연결합니다. 그러나 지정된 이름을 가진 Synapse Spark 풀이 이미 작업 영역에 연결된 경우 azure.ai.ml.MLClient.begin_create_or_update() 함수를 호출하면 연결된 기존 풀이 새 ID로 업데이트됩니다.