구성 요소 및 파이프라인의 입력 및 출력 관리
Azure Machine Learning 파이프라인은 구성 요소 및 파이프라인 수준 모두에서 입력 및 출력을 지원합니다. 이 문서에서는 파이프라인 및 구성 요소 입력/출력과 이러한 기능을 관리하는 방법을 설명합니다.
구성 요소 수준에서 입력 및 출력은 구성 요소 인터페이스를 정의합니다. 한 구성 요소의 출력을 동일한 부모 파이프라인의 다른 구성 요소에 대한 입력으로 사용하여 데이터 또는 모델을 구성 요소 간에 전달할 수 있습니다. 이 상호 연결은 파이프라인 내의 데이터 흐름을 나타냅니다.
파이프라인 수준에서 입력 및 출력을 사용하여 다양한 데이터 입력 또는 매개 변수(예: learning_rate)를 통해 파이프라인 작업을 제출할 수 있습니다. 입력 및 출력은 REST 엔드포인트를 통해 파이프라인을 호출할 때 특히 유용합니다. 파이프라인 입력에 다른 값을 할당하거나 다른 파이프라인 작업의 출력에 액세스할 수 있습니다. 자세한 내용은 일괄 처리 엔드포인트에 대한 작업 및 입력 데이터 만들기를 참조하세요.
입력 및 출력 형식
다음 형식은 구성 요소 또는 파이프라인의 입력 및 출력으로 지원됩니다.
데이터 형식 자세한 내용은 데이터 형식을 참조하십시오.
uri_fileuri_foldermltable
모델 형식.
mlflow_modelcustom_model
다음 기본 형식은 입력에 대해서만 지원됩니다.
- 기본 형식
stringnumberintegerboolean
기본 형식 출력은 지원되지 않습니다.
예제 입력 및 출력
이러한 예제는 Azure Machine Learning 예제 GitHub 리포지토리의 NYC Taxi Data Regression 파이프라인에서 제공됩니다.
- 학습 구성 요소에는
test_split_ratio라는number입력이 있습니다. - 준비 구성 요소에는
uri_folder형식 출력이 있습니다. 구성 요소 소스 코드에서는 입력 폴더에서 csv 파일을 읽고, 파일을 처리하고, 처리된 CSV 파일을 출력 폴더에 씁니다. - 학습 구성 요소에는
mlflow_model형식 출력이 있습니다. 구성 요소 소스 코드에서는mlflow.sklearn.save_model메서드를 사용하여 학습된 모델을 저장합니다.
출력 serialization
출력을 직렬화하는 데이터 또는 모델 출력을 사용하고 스토리지 위치에 파일로 저장합니다. 이후 단계에서는 이 스토리지 위치를 탑재하거나 컴퓨팅 파일 시스템에 파일을 다운로드하거나 업로드하여 작업 실행 중에 파일에 액세스할 수 있습니다.
구성 요소 소스 코드는 일반적으로 메모리에 저장된 출력 개체를 파일로 직렬화해야 합니다. 예를 들어 pandas 데이터 프레임을 CSV 파일로 직렬화할 수 있습니다. Azure Machine Learning은 표준화된 개체 serialization 방법을 정의하지 않습니다. 개체를 파일로 직렬화하는 선호하는 방법을 유연하게 선택할 수 있습니다. 다운스트림 구성 요소에서 이러한 파일을 역직렬화하고 읽는 방법을 선택할 수 있습니다.
데이터 형식 입력 및 출력 경로
데이터 자산 입력/출력의 경우 데이터 위치를 가리키는 경로 매개 변수를 지정해야 합니다. 다음 표에서는 path 매개 변수 예제와 함께 Azure Machine Learning 파이프라인 입력 및 출력에 대해 지원되는 데이터 위치를 보여 줍니다.
| 위치 | 입력 | 출력 | 예시 |
|---|---|---|---|
| 로컬 컴퓨터의 경로 | ./home/<username>/data/my_data |
||
| 퍼블릭 http/s 서버의 경로 | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
||
| Azure Storage의 경로 | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>또는 abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| Azure Machine Learning 데이터 저장소의 경로 | azureml://datastores/<data_store_name>/paths/<path> |
||
| 데이터 자산 경로 | azureml:my_data:<version> |
* 데이터를 읽기 위해 추가 ID 구성이 필요할 수 있으므로 입력의 경우 Azure Storage를 직접 사용하는 것은 권장되지 않습니다. 다양한 파이프라인 작업 유형에서 지원되는 Azure Machine Learning 데이터 저장소 경로를 사용하는 것이 좋습니다.
데이터 형식 입력 및 출력 모드
데이터 형식 입력 및 출력의 경우 여러 다운로드, 업로드 및 탑재 모드 중에서 선택하여 컴퓨팅 대상이 데이터에 액세스하는 방법을 정의할 수 있습니다. 다음 표에서는 다양한 형식의 입력 및 출력에 대해 지원되는 모드를 보여 줍니다.
| Type | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
uri_folder 입력 |
|||||||
uri_file 입력 |
|||||||
mltable 입력 |
|||||||
uri_folder 출력 |
|||||||
uri_file 출력 |
|||||||
mltable 출력 |
대부분의 경우 ro_mount 또는 rw_mount 모드를 사용하는 것이 좋습니다. 자세한 내용은 모드를 참조하세요.
파이프라인의 입력 및 출력 그래프
Azure Machine Learning 스튜디오의 파이프라인 작업 페이지에서 구성 요소 입력 및 출력은 입력/출력 포트라는 작은 원으로 표시됩니다. 이러한 포트는 파이프라인의 데이터 흐름을 나타냅니다. 파이프라인 수준 출력은 쉽게 식별할 수 있는 자주색 상자로 표시됩니다.
NYC Taxi Data Regression 파이프라인 그래프의 다음 스크린샷은 많은 구성 요소 및 파이프라인 입력 및 출력을 보여 줍니다.

입력/출력 포트를 마우스를 가리키면 해당 형식이 표시됩니다.
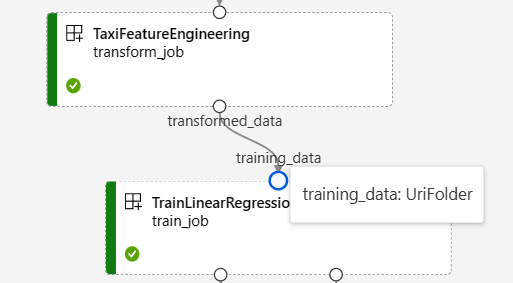
파이프라인 그래프에 기본 형식 입력은 표시되지 않습니다. 이러한 입력은 파이프라인 수준 입력의 경우 파이프라인 작업 개요 패널, 구성 요소 수준 입력의 경우 구성 요소 패널의 설정 탭에 표시됩니다. 구성 요소 패널을 열려면 그래프에서 구성 요소를 두 번 클릭합니다.

스튜디오 디자이너에서 파이프라인을 편집할 때 파이프라인 입력 및 출력은 파이프라인 인터페이스 패널에 있으며 구성 요소 입력 및 출력은 구성 요소 패널에 있습니다.
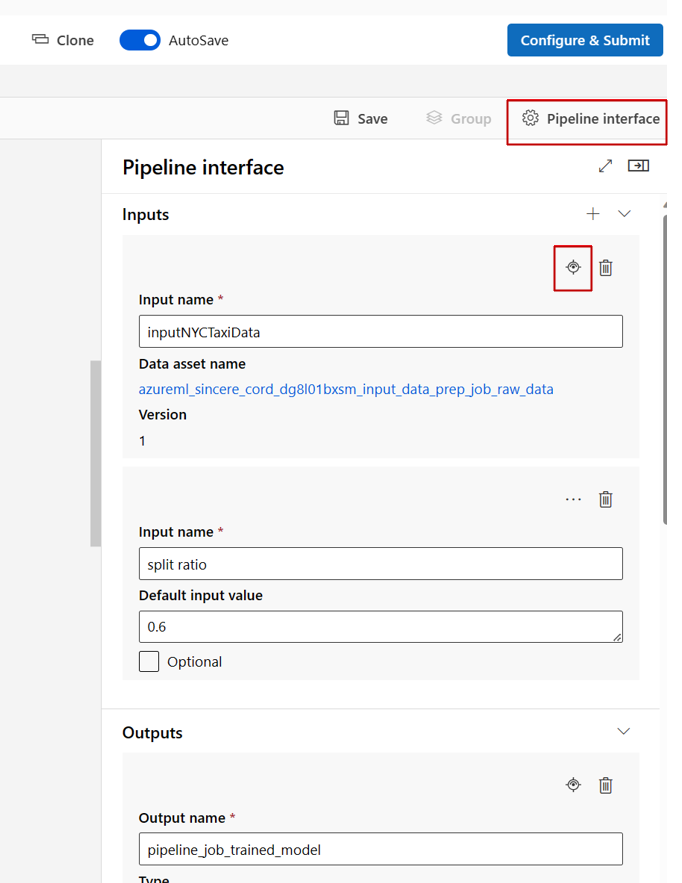
구성 요소 입력/출력을 파이프라인 수준으로 승격
구성 요소의 입력/출력을 파이프라인 수준으로 승격하면 파이프라인 작업을 제출할 때 구성 요소의 입력/출력을 덮어쓸 수 있습니다. 이 기능은 REST 엔드포인트를 사용하여 파이프라인을 트리거하는 데 특히 유용합니다.
다음 예제에서는 구성 요소 입력/출력을 파이프라인 수준 입력/출력으로 승격하는 방법을 보여 줍니다.
다음 파이프라인은 3개의 입력과 3개의 출력을 파이프라인 수준으로 승격합니다. 예를 들어, pipeline_job_training_max_epocs는 루트 수준의 inputs 섹션 아래에 선언되므로 파이프라인 수준 입력입니다.
train_job 아래의 jobs 섹션에서 max_epocs라는 입력은 ${{parent.inputs.pipeline_job_training_max_epocs}}로 참조됩니다. 즉, 이 train_job의 max_epocs 입력은 파이프라인 수준 pipeline_job_training_max_epocs 입력을 참조합니다. 파이프라인 출력은 동일한 스키마를 사용하여 승격됩니다.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
Azure Machine Learning 예제 리포지토리의 train-score-eval 파이프라인(등록된 구성 요소 포함)에서 전체 예제를 찾을 수 있습니다.
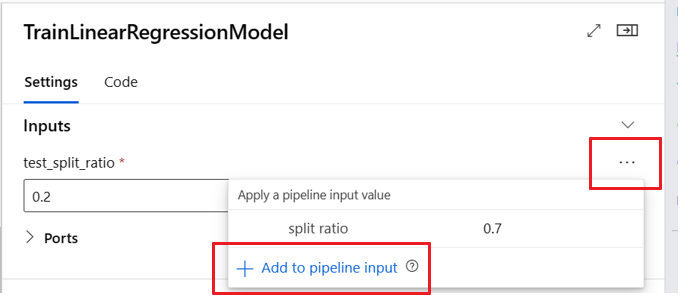
선택적 입력 정의
기본적으로 모든 입력은 필수이며 기본값을 유지하거나 파이프라인 작업을 제출할 때마다 값을 할당해야 합니다. 그러나 선택적 입력을 정의할 수 있습니다.
참고 항목
선택적 출력은 지원되지 않습니다.
선택적 입력 설정 기능은 다음 두 가지 시나리오에서 유용할 수 있습니다.
선택적 데이터/모델 형식 입력이 있고 파이프라인 작업을 제출할 때 값을 할당하지 않으면 파이프라인 구성 요소에 해당 데이터 종속성이 없게 됩니다. 구성 요소의 입력 포트가 구성 요소 또는 데이터/모델 노드에 연결되지 않은 경우 파이프라인은 이전 종속성을 기다리는 대신 구성 요소를 직접 호출합니다.
파이프라인에 대해
continue_on_step_failure = True를 설정했지만node2가node1의 필수 입력을 사용하는 경우node1이 실패하면node2는 실행되지 않습니다.node1입력이 선택 사항인 경우node1이 실패하더라도node2는 실행됩니다. 다음 그래프는 이 시나리오를 보여 줍니다.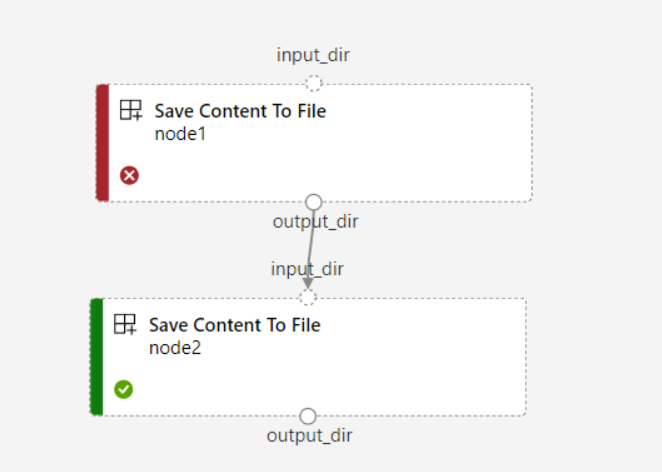
다음 코드 예제는 선택적 입력을 정의하는 방법을 보여 줍니다. 입력이 optional = true로 설정되면 예제의 강조 표시된 줄처럼 $[[]]를 사용하여 명령줄 입력을 수용해야 합니다.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

출력 경로 사용자 지정
기본적으로 구성 요소 출력은 파이프라인 azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}}에 대해 설정한 {default_datastore}에 저장됩니다. 설정하지 않으면 기본적으로 작업 영역 Blob Storage에 저장됩니다.
작업 {name}은 작업 실행 시 확인되며 {output_name}은 구성 요소 YAML에서 정의한 이름입니다. 그러나 출력의 경로를 정의하여 출력을 저장할 위치를 사용자 지정할 수도 있습니다.
train-score-eval pipeline(등록된 구성 요소 예제 포함)의 pipeline.yml 파일은 3개의 파이프라인 수준 출력이 있는 파이프라인을 정의합니다. 다음 명령을 사용하여 pipeline_job_trained_model 출력에 대한 사용자 지정 출력 경로를 설정할 수 있습니다.
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

출력 다운로드
파이프라인 또는 구성 요소 수준에서 출력을 다운로드할 수 있습니다.
파이프라인 수준 출력 다운로드
작업의 모든 출력을 다운로드하거나 특정 출력을 다운로드할 수 있습니다.
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

구성 요소 출력 다운로드
자식 구성 요소의 출력을 다운로드하려면 먼저 파이프라인 작업의 모든 자식 작업을 나열한 다음, 유사한 코드를 사용하여 출력을 다운로드합니다.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
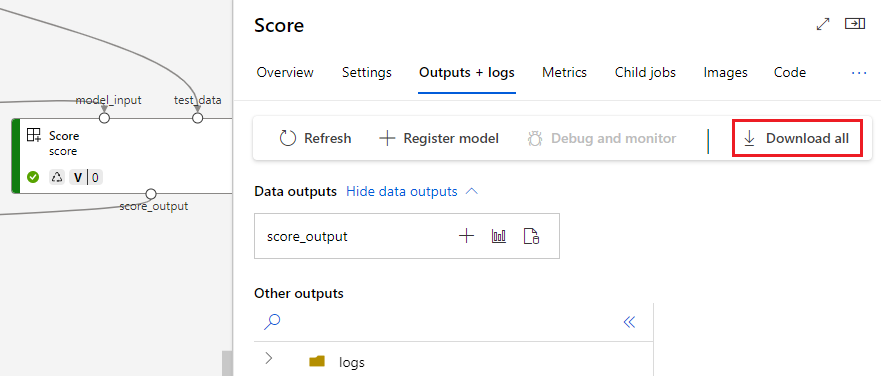
출력을 명명된 자산으로 등록
name 및 version을 출력에 할당하여 구성 요소 또는 파이프라인의 출력을 명명된 자산으로 등록할 수 있습니다. 등록된 자산은 스튜디오 UI, CLI 또는 SDK를 통해 작업 영역에 나열될 수 있으며 향후 작업 영역 작업에서도 참조될 수 있습니다.
파이프라인 수준 출력 등록
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
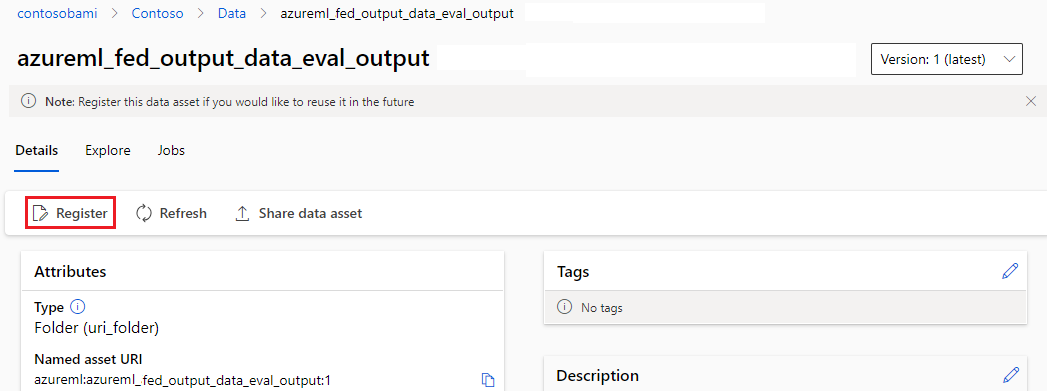
구성 요소 출력 등록
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster