Azure 가상 네트워크에서 Azure Machine Learning 스튜디오 사용
팁
이 문서의 단계 대신 Azure Machine Learning 관리되는 가상 네트워크를 사용할 수 있습니다. 관리되는 가상 네트워크를 통해 Azure Machine Learning은 작업 영역 및 관리 컴퓨팅에 대한 네트워크 격리 작업을 처리합니다. Azure Storage 계정과 같이 작업 영역에 필요한 리소스에 대한 프라이빗 엔드포인트를 추가할 수도 있습니다. 자세한 내용은 작업 영역 관리되는 네트워크 격리를 참조하세요.
이 문서에서는 가상 네트워크에서 Azure Machine Learning 스튜디오를 사용하는 방법을 설명합니다. 스튜디오에는 AutoML, 디자이너, 데이터 레이블 지정과 같은 기능이 포함되어 있습니다.
일부 스튜디오 기능은 가상 네트워크에서 기본적으로 사용하지 않도록 설정되어 있습니다. 해당 기능을 다시 사용하도록 설정하려면 스튜디오에서 사용하려는 스토리지 계정에 대해 관리 ID를 사용하도록 설정해야 합니다.
다음 작업은 가상 네트워크에서 기본적으로 사용하지 않도록 설정되어 있습니다.
- 스튜디오에서 데이터 미리 보기.
- 디자이너에서 데이터 시각화
- 디자이너에서 모델 배포
- AutoML 실험 제출
- 레이블 지정 프로젝트 시작.
스튜디오는 가상 네트워크의 다음 데이터 저장소 형식에서 데이터를 읽을 수 있도록 지원합니다.
- Azure Storage 계정(BLOB 및 파일)
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure SQL Database
이 문서에서는 다음 방법을 설명합니다.
- 가상 네트워크 내에 저장된 데이터에 대한 액세스 권한을 스튜디오에 제공합니다.
- 가상 네트워크 내의 리소스에서 스튜디오에 액세스합니다.
- 스튜디오가 스토리지 보안에 미치는 영향을 이해합니다.
필수 조건
일반적인 가상 네트워크 시나리오 및 아키텍처를 이해하려면 네트워크 보안 개요를 참조하세요.
사용할 기존 가상 네트워크 및 서브넷.
- 보안 작업 영역을 만드는 방법을 알아보려면 자습서: 보안 작업 영역 만들기, Bicep 템플릿 또는 Terraform 템플릿을 참조하세요.
제한 사항
Azure Storage Account
스토리지 계정이 가상 네트워크에 있는 경우 Studio를 사용하기 위한 추가 유효성 검사 요구 사항이 있습니다.
- 스토리지 계정이 서비스 엔드포인트를 사용하는 경우 작업 영역 프라이빗 엔드포인트와 스토리지 서비스 엔드포인트는 가상 네트워크의 동일한 서브넷에 있어야 합니다.
- 스토리지 계정이 프라이빗 엔드포인트를 사용하는 경우 작업 영역 프라이빗 엔드포인트와 스토리지 프라이빗 엔드포인트는 동일한 가상 네트워크에 있어야 합니다. 이 경우 서로 다른 서브넷에 있을 수 있습니다.
디자이너 샘플 파이프라인
사용자가 디자이너 홈페이지에서 샘플 파이프라인을 실행할 수 없는 알려진 문제가 있습니다. 이 문제는 샘플 파이프라인에 사용된 샘플 데이터 세트가 Azure 전역 데이터 세트이기 때문에 발생합니다. 가상 네트워크 환경에서는 접속할 수 없습니다.
이 문제를 해결하려면 공용 작업 영역을 사용하여 샘플 파이프라인을 실행합니다. 또는 가상 네트워크 내의 작업 영역에서 샘플 데이터 세트를 사용자 고유의 데이터 세트로 바꿉니다.
데이터 저장소: Azure Storage 계정
Azure Blob 및 File Storage에 저장된 데이터에 대한 액세스를 사용하도록 설정하려면 다음 단계를 사용합니다.
팁
작업 영역의 기본 스토리지 계정에는 첫 번째 단계가 필요하지 않습니다. 다른 모든 단계는 VNet 뒤에 있는 모든 스토리지 계정에 필요하며 기본 스토리지 계정을 포함하여 작업 영역에서 사용됩니다.
스토리지 계정이 작업 영역의 기본 스토리지인 경우 이 단계를 건너뛰세요. 기본값이 아닌 경우 Blob Storage에서 데이터를 읽을 수 있도록 Azure Storage 계정에 대한 작업 영역 관리 ID에 'Storage Blob 데이터 읽기 권한자' 역할을 부여합니다.
자세한 내용은 Blob 데이터 읽기 권한자 기본 제공 역할을 참조하세요.
Azure 사용자 ID에 Azure Storage 계정에 대한 Storage Blob 데이터 읽기 권한자 역할을 부여합니다. 작업 영역 관리 ID에 읽기 권한자 역할이 있는 경우에도 스튜디오는 사용자 ID를 사용하여 Blob Storage에 대한 데이터에 액세스합니다.
자세한 내용은 Blob 데이터 읽기 권한자 기본 제공 역할을 참조하세요.
스토리지 프라이빗 엔드포인트에 대한 읽기 권한자 역할을 작업 영역 관리 ID에 부여합니다. 스토리지 서비스가 프라이빗 엔드포인트를 사용하는 경우 작업 영역의 관리 ID에 프라이빗 엔드포인트에 대한 읽기 권한자 액세스 권한을 부여합니다. Microsoft Entra ID의 작업 영역 관리 ID는 Azure Machine Learning 작업 영역과 이름이 동일합니다. Blob 및 파일 스토리지 형식 모두에 프라이빗 엔드포인트가 필요합니다.
팁
스토리지 계정에는 여러 프라이빗 엔드포인트가 있을 수 있습니다. 예를 들어 하나의 스토리지 계정에는 Blob, 파일 및 dfs(Azure Data Lake Storage Gen2)에 대한 별도의 프라이빗 엔드포인트가 있을 수 있습니다. 이러한 모든 엔드포인트에 관리 ID를 추가합니다.
자세한 내용은 판독기 기본 제공 역할을 참조하세요.
기본 스토리지 계정에 관리 ID 인증을 사용하도록 설정합니다. 각 Azure Machine Learning 작업 영역에는 기본 Blob Storage 계정과 기본 파일 저장소 계정이라는 두 개의 기본 스토리지 계정이 있습니다. 둘 다 작업 영역을 만들 때 정의됩니다. 데이터 저장소 관리 페이지에서 새 기본값을 설정할 수도 있습니다.
다음 표에서는 작업 영역 기본 스토리지 계정에 대해 관리 ID 인증을 사용해야 하는 이유에 대해 설명합니다.
스토리지 계정 주의 작업 영역 기본 Blob 스토리지 디자이너의 모델 자산을 저장합니다. 디자이너에서 모델을 배포하려면 해당 스토리지 계정에서 관리 ID 인증을 사용하도록 설정합니다. 관리 ID 인증을 사용하지 않도록 설정하면 사용자의 ID가 Blob에 저장된 데이터에 액세스하는 데 사용됩니다.
관리 ID를 사용하도록 구성된 기본이 아닌 데이터 저장소를 사용하는 경우 디자이너 파이프라인을 시각화하고 실행할 수 있습니다. 그러나 기본 데이터 저장소에서 관리 ID를 사용하도록 설정하지 않고 학습된 모델을 배포하려고 하면 어떤 데이터 저장소를 사용 중이든 배포가 실패합니다.작업 영역 기본 파일 저장소 AutoML 실험 자산을 저장합니다. AutoML 실험을 제출하려면 해당 스토리지 계정에서 관리 ID 인증을 사용하도록 설정합니다. 관리 ID 인증을 사용하도록 데이터 저장소 구성. 서비스 엔드포인트나 프라이빗 엔드포인트를 사용하여 가상 네트워크에 Azure 스토리지 계정을 추가한 후 관리 ID 인증을 사용하도록 데이터 저장소를 구성해야 합니다. 그러면 스튜디오에서 스토리지 계정의 데이터에 액세스할 수 있습니다.
Azure Machine Learning은 데이터 저장소를 사용하여 스토리지 계정에 연결합니다. 새 데이터 저장소를 생성할 때 관리 ID 인증을 사용하도록 데이터 저장소를 구성하려면 다음 단계를 따르세요.
스튜디오에서 데이터 저장소를 선택합니다.
새 데이터 저장소를 만들려면 + 만들기을 선택합니다.
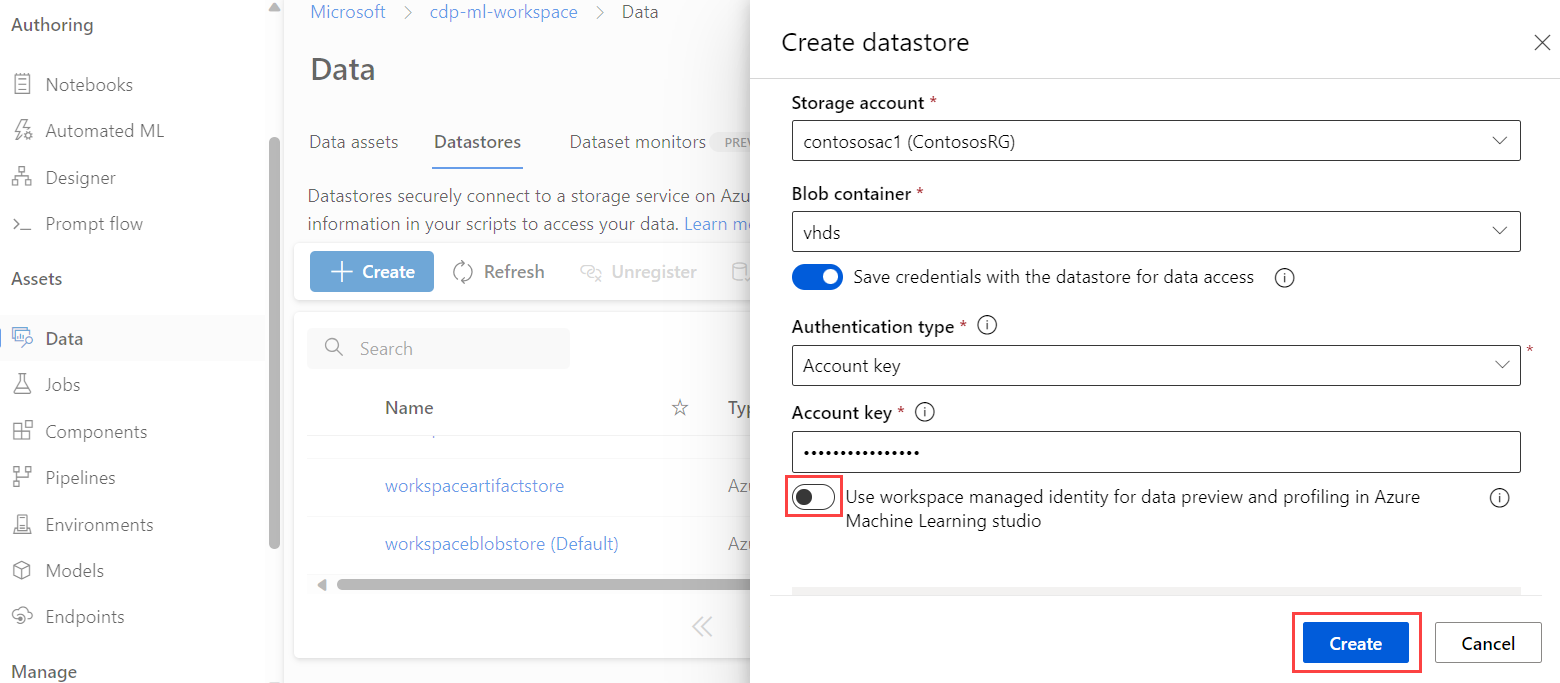
데이터 저장소 설정에서 Azure Machine Learning 스튜디오의 데이터 미리 보기 및 프로파일링을 위해 작업 영역 관리 ID 사용 스위치를 켭니다.
Azure Storage 계정의 네트워킹 설정에서
Microsoft.MachineLearningService/workspaces리소스 종류를 추가하고 작업 영역에 인스턴스 이름을 설정합니다.
이러한 단계에서는 Azure RBAC(역할 기반 액세스 제어)를 사용하여 작업 영역의 관리 ID를 읽기 권한자로 새 스토리지 서비스에 추가합니다. 읽기 권한자 액세스를 사용하면 작업 영역에서 리소스를 볼 수 있지만 변경할 수는 없습니다.


데이터 저장소: Azure Data Lake Storage Gen1 사용
Azure Data Lake Storage Gen1을 데이터 저장소로 사용하는 경우 POSIX 스타일 액세스 제어 목록만 사용할 수 있습니다. 다른 보안 원칙과 마찬가지로 리소스에 작업 영역의 관리 ID 액세스 권한을 할당할 수 있습니다. 자세한 내용은 Azure Data Lake Storage Gen1의 액세스 제어를 참조하세요.
데이터 저장소: Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2를 데이터 저장소로 사용하는 경우 Azure RBAC 및 POSIX 스타일 ACL(액세스 제어 목록)을 모두 사용하여 가상 네트워크 내부의 데이터 액세스를 제어할 수 있습니다.
Azure RBAC를 사용하려면 이 문서의 데이터 저장소: Azure Storage 계정 섹션의 단계를 따릅니다. Data Lake Storage Gen2는 Azure Storage를 기준으로 하므로 Azure RBAC를 사용할 때 동일한 단계가 적용됩니다.
ACL을 사용하려면 다른 보안 원칙과 마찬가지로 작업 영역의 관리 ID에 액세스 권한을 할당하면 됩니다. 자세한 내용은 파일 및 디렉터리에 대한 액세스 제어 목록을 참조하세요.
데이터 저장소: Azure SQL 데이터베이스
관리 ID를 사용하여 Azure SQL Database에 저장된 데이터에 액세스하려면 관리 ID에 매핑되는 SQL 포함된 사용자를 만들어야 합니다. 외부 공급자로부터 사용자를 만드는 방법에 대한 자세한 내용은 Microsoft Entra ID에 매핑된 포함된 사용자 만들기를 참조하세요.
SQL 포함된 사용자를 만든 후에는 GRANT T-SQL 명령사용하여 해당 사용자에게 권한을 부여합니다.
중간 구성 요소 출력
Azure Machine Learning 디자이너 중간 구성 요소 출력을 사용하는 경우 디자이너의 모든 구성 요소에 대한 출력 위치를 지정할 수 있습니다. 이 출력은 보안, 로깅 또는 감사를 위해 중간 데이터 세트를 별도의 위치에 저장하는 데 사용할 수 있습니다. 출력을 지정하려면 다음 단계를 사용합니다.
- 출력을 지정하려는 구성 요소를 선택합니다.
- 구성 요소 설정 창에서 출력 설정을 선택합니다.
- 각 구성 요소 출력에 사용할 데이터 저장소를 지정합니다.
가상 네트워크의 중간 스토리지 계정에 대한 액세스 권한이 있는지 확인합니다. 그렇지 않으면 파이프라인이 실패합니다.
또한 출력 데이터를 시각화하려면 중간 스토리지 계정에 관리 ID 인증을 사용하도록 설정합니다.
VNet 내의 리소스에서 스튜디오에 액세스
가상 네트워크 내의 리소스(예: 컴퓨팅 인스턴스 또는 가상 머신)에서 스튜디오에 액세스하는 경우 가상 네트워크에서 스튜디오로의 아웃바운드 트래픽을 허용해야 합니다.
예를 들어, NSG(네트워크 보안 그룹)를 사용하여 아웃바운드 트래픽을 제한하는 경우 AzureFrontDoor.Frontend의 서비스 태그 대상에 규칙을 추가합니다.
방화벽 설정
Azure Storage 계정과 같은 일부 저장소 서비스에는 해당 특정 서비스 인스턴스의 퍼블릭 엔드포인트에 적용되는 방화벽 설정이 있습니다. 일반적으로 이 설정을 사용하면 공용 인터넷에서 특정 IP 주소의 액세스를 허용하거나 허용하지 않을 수 있습니다. Azure Machine Learning 스튜디오를 사용하는 경우에는 지원되지 않습니다. Azure Machine Learning SDK 또는 CLI를 사용할 때 지원됩니다.
팁
Azure Firewall 서비스를 사용하는 경우 Azure Machine Learning 스튜디오가 지원됩니다. 자세한 내용은 인바운드 및 아웃바운드 네트워크 트래픽 구성을 참조하세요.
관련 콘텐츠
이 문서는 Azure Machine Learning 워크플로 보안에 대한 시리즈의 일부입니다. 이 시리즈의 다른 문서를 참조하세요.