온라인 엔드포인트에 MLflow 모델 배포
적용 대상:  Azure CLI ml 확장 v2(현재)
Azure CLI ml 확장 v2(현재)
이 문서에서는 실시간 유추를 위해 MLflow 모델을 온라인 엔드포인트에 배포하는 방법을 알아봅니다. MLflow 모델을 온라인 엔드포인트에 배포하는 경우 이 기능은 코드 없는 배포이므로 채점 스크립트 또는 환경을 지정할 필요가 없습니다.
코드 없는 배포의 경우 Azure Machine Learning은 다음을 수행합니다.
conda.yaml파일에 제공된 Python 패키지를 동적으로 설치합니다. 따라서 종속성은 컨테이너 런타임 중에 설치됩니다.- 다음 항목을 포함하는 MLflow 기본 이미지/큐레이팅된 환경을 제공합니다.
azureml-inference-server-httpmlflow-skinny- 추론의 채점 스크립트
팁
공용 네트워크에 액세스할 수 없는 작업 영역: 송신 연결 없이 MLflow 모델을 온라인 엔드포인트에 배포하려면 먼저 모델 패키징(미리 보기)을 해야 합니다. 모델 패키징을 사용하면 인터넷 연결이 필요 없습니다. 그렇지 않으면 Azure Machine Learning이 MLflow 모델에 필요한 Python 패키지를 동적으로 설치해야 합니다.
예에 대한 정보
이 예에서는 MLflow 모델을 온라인 엔드포인트에 배포하여 예측을 수행하는 방법을 보여줍니다. 이 예에서는 Diabetes 데이터 세트를 기반으로 하는 MLflow 모델을 사용합니다. 이 데이터 세트에는 10가지 기준 변수가 포함되어 있는데, 이러한 변수는 442명의 당뇨병 환자로부터 얻은 나이, 성별, 체질량 지수, 평균 혈압 및 6가지 혈청 측정값입니다. 또한 기준 후 1년 동안 질병 진행의 정량적 측정인 관심 응답이 포함되어 있습니다.
이 모델은 scikit-learn 회귀자를 사용하여 학습되었으며 필요한 모든 전처리가 파이프라인으로 패키징되어 이 모델을 원시 데이터에서 예측으로 이동하는 엔드투엔드 파이프라인으로 만듭니다.
이 문서의 정보는 azureml-examples 리포지토리에 포함된 코드 샘플을 기반으로 합니다. YAML 및 기타 파일을 복사/붙여넣기할 필요 없이 명령을 로컬로 실행하려면 리포지토리를 복제한 다음, Azure CLI를 사용하는 경우 디렉터리를 cli로 변경합니다. Python용 Azure Machine Learning SDK를 사용하는 경우 디렉터리를 sdk/python/endpoints/online/mlflow로 변경합니다.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Jupyter Notebooks에서 따라 하기
복제된 리포지토리에서 온라인 엔드포인트에 MLflow 모델 배포 Notebook을 열어 Azure Machine Learning Python SDK를 사용하는 단계를 수행할 수 있습니다.
필수 조건
이 문서의 단계를 수행하기 전에 다음과 같은 필수 구성 요소가 있는지 확인합니다.
Azure 구독 Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다. Azure Machine Learning 평가판 또는 유료 버전을 사용해 보세요.
Azure RBAC(Azure 역할 기반 액세스 제어)는 Azure Machine Learning의 작업에 대한 액세스 권한을 부여하는 데 사용됩니다. 이 문서의 단계를 수행하려면 사용자 계정에 Azure Machine Learning 작업 영역에 대한 소유자 또는 기여자 역할이 할당되거나
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*를 허용하는 사용자 지정 역할이 할당되어야 합니다. 역할에 대한 자세한 내용은 Azure Machine Learning 작업 영역 액세스 관리를 참조하세요.작업 영역에 MLflow 모델이 등록되어 있어야 합니다. 이 문서에서는 Diabetes 데이터 세트에 대해 학습된 모델을 작업 영역에 등록합니다.
또한 다음을 수행해야 합니다.
- Azure CLI 및
ml확장을 Azure CLI에 설치합니다. CLI 설치에 대한 자세한 내용은 CLI(v2) 설치 및 설정을 참조하세요.
- Azure CLI 및
작업 영역에 연결
먼저 작업을 수행할 Azure Machine Learning 작업 영역에 연결합니다.
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
모델 등록
등록된 모델만 온라인 엔드포인트에 배포할 수 있습니다. 이 예제의 경우 리포지토리에 모델의 로컬 복사본이 이미 있으므로 작업 영역의 레지스트리에만 모델을 게시하면 됩니다. 배포하려는 모델이 이미 등록된 경우 이 단계를 건너뛸 수 있습니다.
MODEL_NAME='sklearn-diabetes'
az ml model create --name $MODEL_NAME --type "mlflow_model" --path "endpoints/online/ncd/sklearn-diabetes/model"

모델이 실행 내부에 로그된 경우 어떻게 되나요?
모델이 실행 내부에 로그된 경우 모델을 직접 등록하면 됩니다.
모델을 등록하려면 모델이 저장된 위치를 알아야 합니다. MLflow의 autolog 기능을 사용하는 경우 모델의 경로는 모델 유형 및 프레임워크에 따라 달라집니다. 모델의 폴더 이름을 확인하려면 작업 출력을 확인해야 합니다. 이 폴더에는 MLModel이라는 파일이 들어 있습니다.
log_model 메서드를 사용하여 모델을 수동으로 로그하는 경우 모델의 경로를 메서드에 인수로 전달합니다. 예를 들어 mlflow.sklearn.log_model(my_model, "classifier")를 사용하여 모델을 로그하는 경우 모델이 저장된 경로는 classifier입니다.
Azure Machine Learning CLI v2를 사용하여 학습 작업 출력에서 모델을 만듭니다. 다음 예제에서는 $MODEL_NAME이라는 모델은 ID $RUN_ID가 있는 작업의 아티팩트를 사용하여 등록됩니다. 모델이 저장되는 경로는 $MODEL_PATH입니다.
az ml model create --name $MODEL_NAME --path azureml://jobs/$RUN_ID/outputs/artifacts/$MODEL_PATH
참고 항목
경로 $MODEL_PATH는 모델이 실행에 저장된 위치입니다.

온라인 엔드포인트에 MLflow 모델 배포
모델이 배포될 엔드포인트를 구성합니다. 다음 예제에서는 엔드포인트의 이름과 인증 모드를 구성합니다.
다음 명령을 실행하여 엔드포인트 이름을 설정합니다(
YOUR_ENDPOINT_NAME을 고유한 이름으로 변경).export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"엔드포인트 구성:
create-endpoint.yaml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json name: my-endpoint auth_mode: key엔드포인트 만들기:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/ncd/create-endpoint.yaml배포를 구성합니다. 배포는 실제 유추를 수행하는 모델을 호스팅하는 데 필요한 리소스의 세트입니다.
sklearn-deployment.yaml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-deployment endpoint_name: my-endpoint model: name: mir-sample-sklearn-ncd-model version: 2 path: sklearn-diabetes/model type: mlflow_model instance_type: Standard_DS3_v2 instance_count: 1참고 항목
scoring_script및environment의 자동 생성은pyfunc모델 버전에만 지원됩니다. 다른 모델 버전을 사용하려면 MLflow 모델 배포 사용자 지정을 참조하세요.배포 만들기:
az ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-traffic엔드포인트에 송신 연결이 없는 경우
--with-package플래그를 포함시켜 모델 패키징(미리 보기)을 사용합니다.az ml online-deployment create --with-package --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-traffic배포에 모든 트래픽 할당 지금까지 엔드포인트에는 하나의 배포가 있지만 트래픽이 할당되지 않았습니다.
만들 때
--all-traffic을 사용했기 때문에 Azure CLI에서는 이 단계가 필요 없습니다. 트래픽을 변경해야 하는 경우az ml online-endpoint update --traffic명령을 사용하면 됩니다. 트래픽을 업데이트하는 방법에 대한 자세한 내용은 트래픽을 점진적으로 업데이트를 참조하세요.엔드포인트 구성을 업데이트합니다.
만들 때
--all-traffic을 사용했기 때문에 Azure CLI에서는 이 단계가 필요 없습니다. 트래픽을 변경해야 하는 경우az ml online-endpoint update --traffic명령을 사용하면 됩니다. 트래픽을 업데이트하는 방법에 대한 자세한 내용은 트래픽을 점진적으로 업데이트를 참조하세요.


엔드포인트 호출
배포가 준비되면 배포를 사용하여 요청을 처리할 수 있습니다. 배포를 테스트하는 한 가지 방법은 사용 중인 배포 클라이언트에 기본 제공된 호출 기능을 사용하는 것입니다. 다음 JSON은 배포에 대한 샘플 요청입니다.
sample-request-sklearn.json
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
참고 항목
이 예에서는 MLflow 서비스에 사용된 inputs 대신 input_data를 사용했습니다. 이는 Azure Machine Learning에서 엔드포인트에 대한 swagger 계약을 자동으로 생성할 수 있도록 다른 입력 형식이 필요하기 때문입니다. 예상 입력 형식에 대한 자세한 내용은 Azure Machine Learning 및 MLflow 기본 제공 서버에 배포된 모델 간의 차이점을 참조하세요.
다음과 같이 엔드포인트에 요청을 제출합니다.
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
응답은 다음 텍스트와 유사합니다.
[
11633.100167144921,
8522.117402884991
]
Important
MLflow 코드 없는 배포의 경우 로컬 엔드포인트를 통한 테스트는 현재 지원되지 않습니다.
MLflow 모델 배포 사용자 지정
온라인 엔드포인트에 대한 MLflow 모델의 배포 정의에서 채점 스크립트를 지정할 필요가 없습니다. 하지만 지정하도록 선택하고 추론이 실행되는 방법을 사용자 지정할 수 있습니다.
일반적으로 다음과 같은 경우 MLflow 모델 배포를 사용자 지정합니다.
- 모델에
PyFunc특성이 없습니다. - 모델이 실행되는 방식을 사용자 지정해야 합니다. 특정 버전을 사용하여
mlflow.<flavor>.load_model()명령을 통해 모델을 로드하는 상황을 예로 들 수 있습니다. - 모델 자체에서 사전/사후 처리가 수행되지 않는 경우 채점 루틴에서 사전/사후 처리를 수행해야 합니다.
- 모델의 출력을 표 형식 데이터로 잘 나타낼 수 없습니다. 이미지를 나타내는 텐서를 예로 들 수 있습니다.
Important
MLflow 모델 배포에 사용할 채점 스크립트를 지정하도록 선택하는 경우 배포가 실행될 환경도 지정해야 합니다.
단계
사용자 지정 채점 스크립트를 사용하여 MLflow 모델을 배포하려면 다음을 수행합니다.
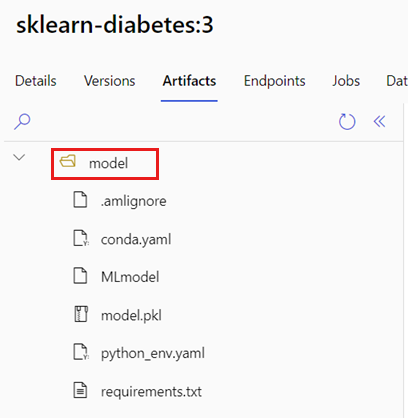
MLflow 모델이 있는 폴더를 찾습니다.
a. Azure Machine Learning Studio로 이동합니다.
b. 모델 섹션으로 이동합니다.
c. 배포하려는 모델을 선택하고 아티팩트 탭으로 이동합니다.
d. 표시되는 폴더를 기록해 둡니다. 이 폴더는 모델을 등록할 때 지정되었습니다.
다음 채점 스크립트를 만듭니다. 이전에 확인한 폴더 이름
model이init()함수에 어떻게 포함되었는지 살펴봅니다.팁
다음 채점 스크립트는 MLflow 모델로 추론을 수행하는 방법에 대한 예시로 제공되었습니다. 이 스크립트를 필요한 대로 조정하거나 일부를 변경하여 시나리오를 반영할 수 있습니다.
score.py
import logging import os import json import mlflow from io import StringIO from mlflow.pyfunc.scoring_server import infer_and_parse_json_input, predictions_to_json def init(): global model global input_schema # "model" is the path of the mlflow artifacts when the model was registered. For automl # models, this is generally "mlflow-model". model_path = os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model") model = mlflow.pyfunc.load_model(model_path) input_schema = model.metadata.get_input_schema() def run(raw_data): json_data = json.loads(raw_data) if "input_data" not in json_data.keys(): raise Exception("Request must contain a top level key named 'input_data'") serving_input = json.dumps(json_data["input_data"]) data = infer_and_parse_json_input(serving_input, input_schema) predictions = model.predict(data) result = StringIO() predictions_to_json(predictions, result) return result.getvalue()Warning
MLflow 2.0 권고: 제공된 채점 스크립트는 MLflow 1.X 및 MLflow 2.X 모두에서 작동합니다. 그러나 해당 버전에서 필요한 입력/출력 형식은 다를 수 있습니다. 사용된 환경 정의를 확인하여 필요한 MLflow 버전을 사용하고 있는지 확인합니다. MLflow 2.0은 Python 3.8+에서만 지원됩니다.
채점 스크립트를 실행할 수 있는 환경을 만듭니다. MLflow 모델이므로 conda 요구 사항도 모델 패키지에 지정됩니다. MLflow 모델에 포함된 파일에 대한 자세한 내용은 MLmodel 형식을 참조하세요. 그 후 이 파일의 conda 종속성을 사용하여 환경을 빌드합니다. 하지만 Azure Machine Learning에서 온라인으로 배포할 때 필요한
azureml-inference-server-http패키지도 포함시켜야 합니다.conda 정의 파일은 다음과 같습니다.
conda.yml
channels: - conda-forge dependencies: - python=3.9 - pip - pip: - mlflow - scikit-learn==1.2.2 - cloudpickle==2.2.1 - psutil==5.9.4 - pandas==2.0.0 - azureml-inference-server-http name: mlflow-env참고 항목
azureml-inference-server-http패키지가 원래 conda 종속성 파일에 추가되었습니다.다음과 같이 이 conda 종속성 파일을 사용하여 환경을 만듭니다.
환경은 배포 구성에서 인라인으로 만들어집니다.
배포 만들기:
다음과 같이 deployment.yml 배포 구성 파일을 만듭니다.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-diabetes-custom endpoint_name: my-endpoint model: azureml:sklearn-diabetes@latest environment: image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04 conda_file: sklearn-diabetes/environment/conda.yml code_configuration: code: sklearn-diabetes/src scoring_script: score.py instance_type: Standard_F2s_v2 instance_count: 1배포 만들기:
az ml online-deployment create -f deployment.yml배포가 완료되면 요청을 처리할 준비가 된 것입니다. 배포를 테스트하는 한 가지 방법은
invoke메서드와 함께 샘플 요청 파일을 사용하는 것입니다.sample-request-sklearn.json
{"input_data": { "columns": [ "age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6" ], "data": [ [ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ], [ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0] ], "index": [0,1] }}다음과 같이 엔드포인트에 요청을 제출합니다.
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json응답은 다음 텍스트와 유사합니다.
{ "predictions": [ 11633.100167144921, 8522.117402884991 ] }Warning
MLflow 2.0 권고: MLflow 1.X에서는
predictions키가 누락됩니다.



리소스 정리
더 이상 엔드포인트를 사용할 일이 없으면 엔드포인트에 연결된 리소스를 삭제합니다.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes