Apache Spark 풀을 사용한 데이터 랭글링(사용되지 않음)
적용 대상:  Python SDK azureml v1
Python SDK azureml v1
Warning
Python SDK v1에서 사용할 수 있는 Azure Machine Learning과의 Azure Synapse Analytics 통합은 더 이상 사용되지 않습니다. 사용자는 Azure Machine Learning에 등록된 Synapse 작업 영역을 연결된 서비스로 계속 사용할 수 있습니다. 그러나 새 Synapse 작업 영역은 더 이상 연결된 서비스로 Azure Machine Learning에 등록할 수 없습니다. CLI v2 및 Python SDK v2에서 사용할 수 있는 서버리스 Spark 컴퓨팅 및 연결된 Synapse Spark 풀을 사용하는 것이 좋습니다. 자세한 내용은 https://aka.ms/aml-spark을 참조하세요.
이 문서에서는 Jupyter Notebook의 Azure Synapse Analytics를 기반으로 하는 전용 Synapse 세션 내에서 데이터 랭글링 작업을 대화형으로 수행하는 방법을 알아봅니다. 이러한 작업은 Azure Machine Learning Python SDK를 사용합니다. Azure Machine Learning 파이프라인에 대한 자세한 내용은 Machine Learning 파이프라인에서 Apache Spark(Azure Synapse Analytics 제공)를 사용하는 방법(미리 보기)을 참조하세요. Synapse 작업 영역에서 Azure Synapse Analytics를 사용하는 방법에 대한 자세한 내용을 보려면 Azure Synapse Analytics 시작 시리즈를 참조하세요.
Azure Machine Learning 및 Azure Synapse Analytics 통합
Azure Machine Learning과 Azure Synapse Analytics를 통합(미리 보기)하면 대화형 데이터 탐색 및 준비를 위해 Azure Synapse에서 지원하는 Apache Spark 풀을 연결할 수 있습니다. 이 통합을 통해 기계 학습 모델을 학습하는 데 사용하는 동일한 Python Notebook 내에서 대규모 데이터 랭글링을 위한 전용 컴퓨팅 리소스를 확보할 수 있습니다.
필수 조건
Azure Machine Learning SDK를 설치하거나 SDK가 이미 설치된 Azure Machine Learning 컴퓨팅 인스턴스를 사용하도록 개발 환경을 구성합니다.
Azure Portal, 웹 도구 또는 Synapse Studio를 사용하여 Apache Spark 풀을 만듭니다.
다음 코드를 사용하여
azureml-synapse패키지(미리 보기)를 설치합니다.pip install azureml-synapseAzure Machine Learning Python SDK를 사용하거나 Azure Machine Learning 스튜디오를 통해 Azure Machine Learning 작업 영역과 Azure Synapse Analytics 작업 영역을 연결합니다.
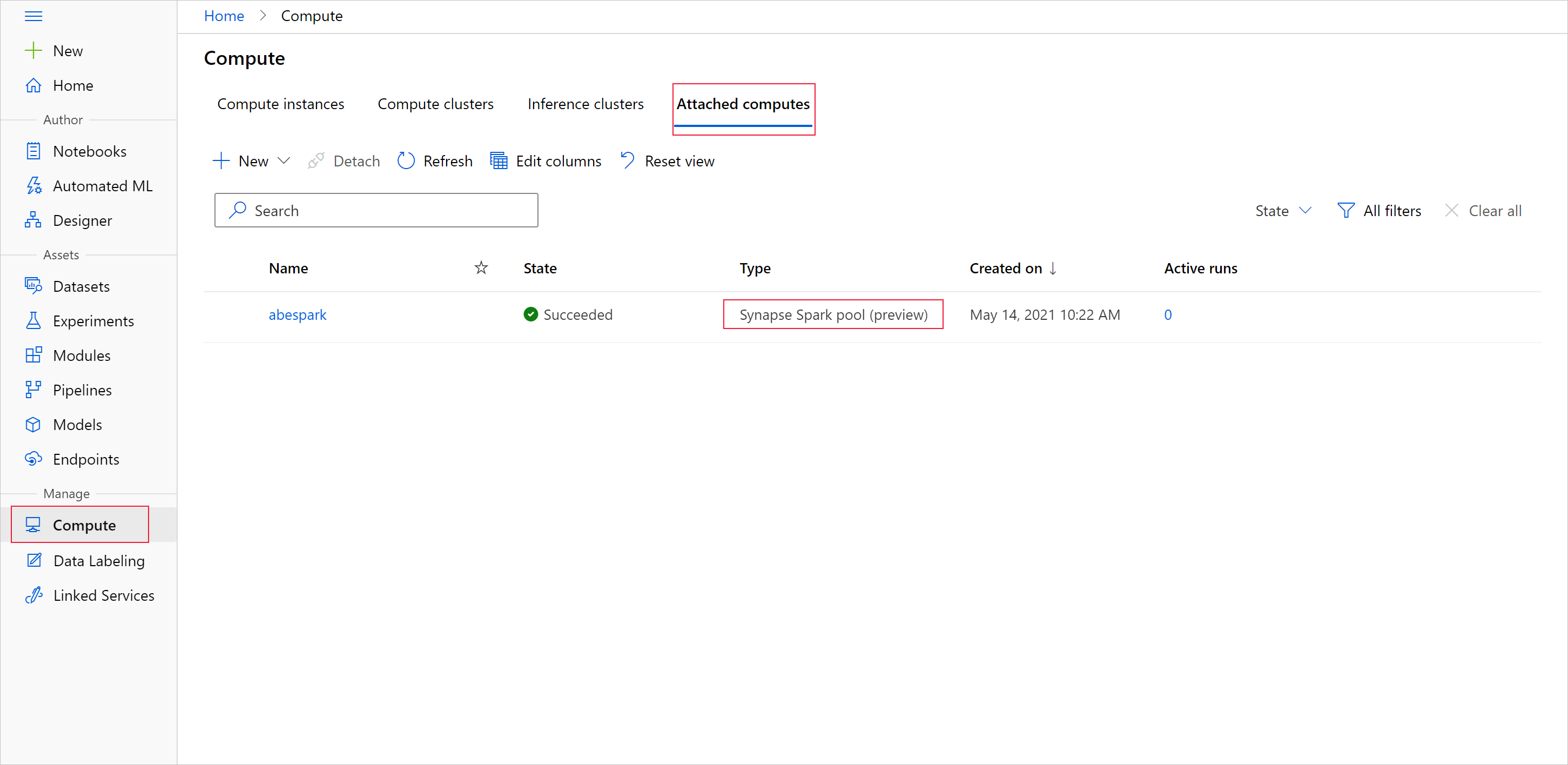
데이터 랭글링 작업을 위해 Synapse Spark 풀을 시작합니다.
Apache Spark 풀을 사용하여 데이터 준비를 시작하려면 연결된 Spark Synapse 컴퓨팅 이름을 지정합니다. 연결된 컴퓨팅 탭 아래의 Azure Machine Learning 스튜디오에서 이 이름을 찾을 수 있습니다.
Important
Apache Spark 풀을 계속 사용하려면 데이터 랭글링 작업 전반에 걸쳐 사용할 컴퓨팅 리소스를 지정해야 합니다. 단일 코드 줄에는 %synapse를 사용하고 여러 줄에는 %%synapse를 사용합니다.
%synapse start -c SynapseSparkPoolAlias
세션이 시작되면 세션의 메타데이터를 확인할 수 있습니다.
%synapse meta
Apache Spark 세션 중에 사용할 Azure Machine Learning 환경을 지정할 수 있습니다. 환경에 지정된 Conda 종속성만 적용됩니다. Docker 이미지는 지원되지 않습니다.
Warning
환경 Conda 종속성에 지정된 Python 종속성은 Apache Spark 풀에서 지원되지 않습니다. 현재는 수정된 Python 버전만 지원됩니다. Python 버전을 확인하려면 스크립트에 sys.version_info를 포함합니다.
이 코드는 세션이 시작되기 전에 azureml-core 버전 1.20.0 및 numpy 버전 1.17.0을 설치하기 위해 myenv 환경 변수를 만듭니다. 그런 다음, Apache Spark 세션 start 문에 이 환경을 포함할 수 있습니다.
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
사용자 지정 환경에서 Apache Spark 풀을 사용하여 데이터 준비를 시작하려면 Apache Spark 세션 중에 사용할 Apache Spark 풀 이름과 환경을 모두 지정합니다. 구독 ID, 기계 학습 작업 영역 리소스 그룹 및 기계 학습 작업 영역의 이름을 제공할 수 있습니다.
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
스토리지에서 데이터 로드
Apache Spark 세션이 시작된 후 준비하려는 데이터를 읽습니다. 데이터 로드는 Azure Blob Storage 및 Azure Data Lake Storage Generation 1 및 2에서 지원됩니다.
이러한 스토리지 서비스에서 데이터를 로드하는 두 가지 옵션이 있습니다.
HDFS(Hadoop 분산 파일 시스템) 경로를 사용하여 스토리지에서 데이터를 직접 로드합니다.
기존의 Azure Machine Learning 데이터 세트에서 데이터를 읽습니다.
이러한 스토리지 서비스에 액세스하려면 Storage Blob 데이터 읽기 권한자 권한이 필요합니다. 이러한 스토리지 서비스에 데이터를 다시 쓰려면 Storage Blob 데이터 기여자 권한이 필요합니다. 스토리지 권한 및 역할에 대해 자세히 알아보세요.
HDFS(Hadoop Distributed Files System) 경로를 사용하여 데이터 로드
해당 HDFS 경로를 사용하여 스토리지에서 데이터를 로드하고 읽으려면 사용 가능한 데이터 액세스 인증 자격 증명이 필요합니다. 이 자격 증명은 스토리지 유형에 따라 다릅니다. 이 코드 샘플은 SAS(공유 액세스 서명) 토큰 또는 액세스 키를 사용하여 Azure Blob Storage의 데이터를 Spark 데이터 프레임으로 읽는 방법을 보여 줍니다.
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
이 코드 샘플은 서비스 주체 자격 증명을 사용하여 ADLS Gen 1(Azure Data Lake Storage Generation 1)에서 데이터를 읽는 방법을 보여 줍니다.
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
이 코드 샘플은 서비스 주체 자격 증명을 사용하여 ADLS Gen 2(Azure Data Lake Storage Generation 2)에서 데이터를 읽는 방법을 보여 줍니다.
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
등록된 데이터 세트에서 데이터 읽기
Spark 데이터 프레임으로 변환하는 경우 기존에 등록된 데이터 세트를 작업 영역에 배치하고 데이터 준비를 수행할 수도 있습니다. 이 예에서는 작업 영역에 인증하고, Blob Storage의 파일을 참조하는 등록된 TabularDataset(blob_dset)를 획득하고 해당 TabularDataset를 Spark 데이터 프레임으로 변환합니다. 데이터 세트를 Spark 데이터 프레임으로 변환할 때 pyspark 데이터 탐색 및 준비 라이브러리를 사용할 수 있습니다.
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
데이터 랭글링 작업 수행
데이터를 검색하고 탐색한 후 데이터 랭글링 작업을 수행할 수 있습니다. 이 코드 샘플은 이전 섹션의 HDFS 예를 확장합니다. Survivor 열을 기준으로 Spark 데이터 프레임 df의 데이터와 Age를 기준으로 나열되는 그룹을 필터링합니다.
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
스토리지에 데이터 저장 및 Spark 세션 중지
데이터 탐색 및 준비가 완료되면 준비된 데이터를 나중에 사용할 수 있게 Azure의 스토리지 계정에 저장합니다. 이 코드 샘플에서는 준비된 데이터가 Azure Blob Storage에 쓰기 저장되어 training_data 디렉터리의 원본 Titanic.csv 파일을 덮어씁니다. 스토리지에 다시 쓰려면 Storage Blob 데이터 기여자 권한이 필요합니다. 자세한 내용은 Blob 데이터에 액세스하기 위한 Azure 역할 할당을 참조하세요.
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
데이터 준비를 완료하고 준비된 데이터를 스토리지에 저장한 후 다음 명령을 사용하여 Apache Spark 풀 사용을 종료합니다.
%synapse stop
준비된 데이터를 나타내기 위해 데이터 세트를 만듭니다.
모델 학습을 위해 준비된 데이터를 사용할 준비가 되면 Azure Machine Learning 데이터 저장소를 사용하여 스토리지에 연결하고 Azure Machine Learning 데이터 세트와 함께 사용할 파일을 지정합니다.
이 코드 예
- 준비된 데이터를 저장한 스토리지 서비스에 연결하는 데이터 저장소를 이미 만들었다고 가정합니다.
- get() 메서드를 사용하여 작업 영역
ws에서 기존 데이터 저장소(mydatastore)를 검색합니다. mydatastoretraining_data디렉터리에 있는 준비된 데이터 파일을 참조하기 위해 FileDataset,train_ds를 만듭니다.- 변수
input1을 만듭니다. 나중에 이 변수를 사용하면 학습 작업을 위한 컴퓨팅 대상에서train_ds데이터 세트의 데이터 파일을 사용할 수 있습니다.
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
ScriptRunConfig를 사용하여 Synapse Spark 풀에 실험 실행을 제출합니다.
데이터 랭글링 작업을 자동화하고 프로덕션화할 준비가 되었으면 ScriptRunConfig 개체를 사용하여 연결된 Synapse Spark 풀에 실험 실행을 제출할 수 있습니다. 마찬가지로, Azure Machine Learning 파이프라인이 있으면 파이프라인에서 SynapseSparkStep을 사용하여 Synapse Spark 풀을 데이터 준비 단계의 컴퓨팅 대상으로 지정할 수 있습니다. Synapse Spark 풀에 대한 데이터의 가용성은 데이터 세트 형식에 따라 다릅니다.
- FileDataset의 경우
as_hdfs()메서드를 사용할 수 있습니다. 실행이 제출되면 데이터 세트가 Synapse Spark 풀에 HFDS(Hadoop 분산 파일 시스템)로 제공됩니다. - TabularDataset의 경우
as_named_input()메서드를 사용할 수 있습니다.
다음 코드 샘플
- 이전 코드 예에서 만들어진 FileDataset
train_ds에서 변수input2를 만듭니다. HDFSOutputDatasetConfiguration클래스를 사용하여 변수output을 만듭니다. 실행이 완료된 다음 이 클래스는mydatastore데이터 저장소에서test데이터 세트로 실행 출력을 저장할 수 있게 해줍니다. Azure Machine Learning 작업 영역에서test데이터 세트는registered_dataset이름으로 등록됩니다.- 실행이 Synapse Spark 풀에서 수행하는 데 사용해야 하는 설정을 구성합니다.
- 다음을 목적으로 ScriptRunConfig 매개변수를 정의합니다.
- 실행을 위해
dataprep.py스크립트를 사용합니다. - 입력으로 사용할 데이터와 해당 데이터를 Synapse Spark 풀에서 사용할 수 있도록 만드는 방법을 지정합니다.
output출력 데이터를 저장할 위치를 지정합니다.
- 실행을 위해
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
run_config.spark.configuration 및 일반 Spark 구성에 대한 자세한 내용은 SparkConfiguration 클래스 및 Apache Spark의 구성 설명서를 참조하세요.
ScriptRunConfig 개체를 설정하고 나면 실행을 제출할 수 있습니다.
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
이 예에 사용된 dataprep.py 스크립트에 대한 정보를 포함한 자세한 내용은 Notebook 예를 참조하세요.
데이터를 준비한 후에는 이를 학습 작업의 입력으로 사용할 수 있습니다. 위의 코드 예에서는 학습 작업에 대한 입력 데이터로 registered_dataset를 지정합니다.
예제 Notebook
Azure Synapse Analytics 및 Azure Machine Learning 통합 기능에 대한 자세한 개념 및 데모는 예제 Notebook을 검토하세요.
- Azure Machine Learning 작업 영역의 Notebook에서 대화형 Spark 세션 실행
- 컴퓨팅 대상으로 Synapse Spark 풀을 사용하여 Azure Machine Learning 실험 실행 제출