일괄 처리 배포를 위한 작성자 점수 매기기 스크립트
적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
일괄 처리 엔드포인트를 사용하면 대규모로 장기 실행 유추를 수행하는 모델을 배포할 수 있습니다. 모델을 배포할 때 채점 스크립트(일괄 처리 드라이버 스크립트라고도 함)를 만들고 지정하여 입력 데이터에 대해 이를 사용하여 예측을 만드는 방법을 나타내야 합니다. 이 문서에서는 다양한 시나리오에 대한 모델 배포에서 채점 스크립트를 사용하는 방법을 알아봅니다. 일괄 처리 엔드포인트에 대한 모범 사례에 대해서도 알아봅니다.
팁
MLflow 모델에는 채점 스크립트가 필요하지 않습니다. 자동 생성됩니다. MLflow 모델에서 일괄 처리 엔드포인트가 작동하는 방식에 대한 자세한 내용은 일괄 처리 배포에서 MLflow 모델 사용 전용 자습서를 참조하세요.
Warning
일괄 처리 엔드포인트 아래에 자동화된 ML 모델을 배포하려면 자동화된 ML이 온라인 엔드포인트에서만 작동하는 채점 스크립트를 제공한다는 점에 유의해야 합니다. 해당 채점 스크립트는 일괄 처리 실행용으로 설계되지 않았습니다. 모델의 기능에 맞게 사용자 지정된 채점 스크립트를 만드는 방법에 대한 자세한 내용을 보려면 다음 지침을 따릅니다.
채점 스크립트 이해
채점 스크립트는 모델을 실행하고 일괄 처리 배포 실행기가 제출하는 입력 데이터를 읽는 방법을 지정하는 Python 파일(.py)입니다. 각 모델 배포는 만들 때 채점 스크립트를 다른 모든 필수 종속성과 함께 제공합니다. 채점 스크립트는 일반적으로 다음과 같습니다.
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
점수 매기기 스크립트에는 다음의 두 가지 메서드가 포함되어야 합니다.
init 메서드
비용이 많이 드는 준비 또는 일반적인 준비에 init() 메서드를 사용합니다. 예를 들어, 모델을 메모리에 로드하는 데 사용합니다. 전체 일괄 작업 시작 시 이 함수를 한 번 호출합니다. 모델의 파일은 환경 변수 AZUREML_MODEL_DIR에 의해 결정된 경로에서 사용할 수 있습니다. 모델 등록 방법에 따라 해당 파일이 폴더에 포함될 수 있습니다. 다음 예에서는 모델의 model 폴더에 여러 파일이 있습니다. 자세한 내용은 모델이 사용하는 폴더를 확인하는 방법을 참조하세요.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
이 예에서는 모델을 전역 변수 model에 배치합니다. 채점 함수에 대한 유추를 수행하는 데 필요한 자산을 사용 가능하게 하려면 전역 변수를 사용합니다.
run 메서드
일괄 처리 배포가 생성하는 각 미니 일괄 처리의 점수를 처리하려면 run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] 메서드를 사용합니다. 이 메서드는 입력 데이터에 대해 생성된 각 mini_batch에 대해 한 번씩 호출됩니다. 일괄 처리 배포는 배포 구성 방식에 따라 일괄 처리로 데이터를 읽습니다.
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
메서드는 파일 경로 목록을 매개 변수(mini_batch)로 받습니다. 이 목록을 사용하여 각 파일을 반복하고 개별적으로 처리하거나 전체 일괄 처리를 읽고 한 번에 처리할 수 있습니다. 최상의 옵션은 컴퓨터 메모리와 달성해야 하는 처리량에 따라 다릅니다. 전체 데이터 일괄 처리를 한 번에 읽는 방법을 설명하는 예를 보려면 높은 처리량 배포를 참조하세요.
참고 항목
작업 배포 방식
일괄 처리 배포는 파일 수준에서 작업을 배포합니다. 즉, 100개 파일이 포함된 폴더와 10개 파일의 미니 일괄 처리가 각각 10개 파일로 구성된 10개의 일괄 처리를 생성합니다. 관련 파일의 크기는 관련이 없습니다. 파일이 너무 커서 대규모 미니 일괄 처리로 처리할 수 없는 경우 파일을 더 작은 파일로 분할하여 더 높은 수준의 병렬 처리를 달성하거나 미니 일괄 처리당 파일 수를 줄이는 것이 좋습니다. 현재 일괄 처리 배포에서는 파일 크기 배포의 불균형을 고려할 수 없습니다.
run() 메서드는 Pandas DataFrame 또는 배열/목록을 반환해야 합니다. 반환되는 각 출력 요소는 입력 mini_batch에서 입력 요소의 성공적인 실행 1건을 나타냅니다. 파일 또는 폴더 데이터 자산의 경우 반환된 각 행/요소는 처리된 단일 파일을 나타냅니다. 표 형식 데이터 자산의 경우 반환된 각 행/요소는 처리된 파일의 행을 나타냅니다.
Important
예측을 작성하는 방법
run() 함수가 반환하는 모든 내용은 일괄 작업이 생성하는 출력 예측 파일에 추가됩니다. 이 함수에서 올바른 데이터 형식을 반환해야 합니다. 단일 예측을 출력해야 하는 경우 배열을 반환합니다. 여러 정보를 반환해야 하는 경우 Pandas DataFrame을 반환합니다. 예를 들어 표 형식 데이터의 경우 원래 레코드에 예측을 추가할 수 있습니다. 이를 수행하려면 Pandas DataFrame을 사용합니다. Pandas DataFrame에는 열 이름이 포함될 수 있지만 출력 파일에는 해당 이름이 포함되지 않습니다.
다른 방식으로 예측을 작성하려면 일괄 처리 배포에서 출력을 사용자 지정할 수 있습니다.
Warning
run 함수에서는 pandas.DataFrame 대신 복합 데이터 형식(또는 복합 데이터 형식 목록)을 출력하지 마세요. 해당 출력은 문자열로 변환되어 읽기 어려워집니다.
결과 DataFrame 또는 배열은 표시된 출력 파일에 추가됩니다. 결과의 카디널리티에 대한 요구 사항은 없습니다. 하나의 파일은 출력에 1개 이상의 행/요소를 생성할 수 있습니다. 결과 DataFrame 또는 배열의 모든 요소는 있는 그대로 출력 파일에 기록됩니다(output_action이 summary_only가 아님을 고려).
채점을 위한 Python 패키지
일괄 처리 배포가 실행되는 환경에서 채점 스크립트를 실행하는 데 필요한 라이브러리를 표시해야 합니다. 채점 스크립트의 경우 배포별로 환경이 표시됩니다. 일반적으로 다음과 같은 conda.yml 종속성 파일을 사용하여 요구 사항을 나타냅니다.
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
모델의 환경을 표시하는 방법에 대한 자세한 내용은 일괄 처리 배포 만들기를 참조하세요.
다른 방식으로 예측 작성
기본적으로 일괄 처리 배포는 배포에 표시된 대로 모델의 예측을 단일 파일에 씁니다. 그러나 경우에 따라 여러 파일에 예측을 작성해야 합니다. 예를 들어, 분할된 입력 데이터의 경우 분할된 출력도 생성할 수 있습니다. 이러한 경우 일괄 처리 배포의 출력을 사용자 지정하여 다음을 나타낼 수 있습니다.
- 예측을 작성하는 데 사용되는 파일 형식(CSV, Parquet, json 등)
- 출력에서 데이터가 분할되는 방식
이를 달성하는 방법에 대한 자세한 내용을 보려면 일괄 처리 배포에서 출력 사용자 지정을 참조하세요.
점수 매기기 스크립트의 소스 제어
채점 스크립트를 소스 제어 하에 두는 것이 좋습니다.
점수 매기기 스크립트 작성 모범 사례
많은 양의 데이터를 처리하는 채점 스크립트를 작성할 때 다음을 포함한 여러 요소를 고려해야 합니다.
- 각 파일의 크기
- 각 파일의 데이터 양
- 각 파일을 읽는 데 필요한 메모리 양
- 전체 파일 일괄 처리를 읽는 데 필요한 메모리 양
- 모델의 메모리 공간
- 입력 데이터를 실행하는 경우 모델 메모리 공간
- 컴퓨팅에서 사용 가능한 메모리
일괄 처리 배포는 파일 수준에서 작업을 배포합니다. 즉, 10개 파일의 미니 일괄 처리로 100개 파일이 포함된 폴더는 관련 파일 크기에 관계없이 각각 10개 파일로 구성된 10개의 일괄 처리를 생성합니다. 파일이 너무 커서 대규모 미니 일괄 처리로 처리할 수 없는 경우 파일을 더 작은 파일로 분할하여 더 높은 수준의 병렬 처리를 달성하거나 미니 일괄 처리당 파일 수를 줄이는 것이 좋습니다. 현재 일괄 처리 배포에서는 파일 크기 배포의 불균형을 고려할 수 없습니다.
병렬 처리 수준과 점수 매기기 스크립트 간의 관계
배포 구성은 각 미니 일괄 처리의 크기와 각 노드의 작업자 수 모두를 제어합니다. 이는 유추를 수행하기 위해 전체 미니 일괄 처리를 읽을지, 파일별로 유추를 실행할지, 행별로 유추를 실행할지(테이블 형식의 경우) 결정할 때 중요합니다. 자세한 내용은 미니 일괄 처리, 파일 또는 행 수준에서 유추 실행을 참조하세요.
동일한 인스턴스에서 여러 작업자를 실행하는 경우 메모리가 모든 작업자에서 공유된다는 팩트를 고려해야 합니다. 노드당 작업자 수가 증가하면 일반적으로 미니 일괄 처리 크기가 감소하거나 데이터 크기와 컴퓨팅 SKU가 동일하게 유지되는 경우 채점 전략이 변경됩니다.
미니 일괄 처리, 파일 또는 행 수준에서 유추 실행
일괄 처리 엔드포인트는 미니 일괄 처리당 한 번씩 채점 스크립트에서 run() 함수를 호출합니다. 그러나 전체 일괄 처리, 한 번에 하나의 파일 또는 표 형식 데이터의 경우 한 번에 하나의 행에 대해 유추를 실행할 것인지 결정할 수 있습니다.
미니 일괄 처리 수준
일반적으로 일괄 처리에 대해 한 번에 유추를 실행하여 일괄 처리 채점 프로세스에서 높은 처리량을 달성하려고 합니다. 이는 유추 디바이스의 채도를 달성하려는 GPU를 통해 유추를 실행하는 경우에 발생합니다. TensorFlow 또는 PyTorch 데이터 로더와 같이 데이터가 메모리에 맞지 않는 경우 일괄 처리 자체를 처리할 수 있는 데이터 로더를 사용할 수도 있습니다. 이러한 경우 전체 일괄 처리에 대해 유추를 실행할 수 있습니다.
Warning
일괄 처리 수준에서 유추를 실행하려면 메모리 요구 사항을 올바르게 설명하고 메모리 부족 예외를 방지하기 위해 입력 데이터 크기를 면밀히 제어해야 할 수 있습니다. 전체 미니 일괄 처리를 메모리에 로드할 수 있는지 여부는 미니 일괄 처리 크기, 클러스터의 인스턴스 크기, 각 노드의 작업자 수 및 미니 일괄 처리 크기에 따라 다릅니다.
이를 달성하는 방법을 알아보려면 높은 처리량 배포를 참조하세요. 이 예는 한 번에 전체 파일 일괄 처리를 처리합니다.
파일 수준
유추를 수행하는 가장 쉬운 방법 중 하나는 미니 일괄 처리의 모든 파일을 반복한 다음 그 위에 모델을 실행하는 것입니다. 이미지 처리 등의 경우에는 이것이 좋은 생각일 수 있습니다. 표 형식 데이터의 경우 각 파일의 행 수를 정확하게 예측해야 할 수도 있습니다. 이 예상 비용은 모델이 전체 데이터를 메모리에 로드하고 이에 대한 유추를 수행하기 위한 메모리 요구 사항을 처리할 수 있는지 여부를 보여줄 수 있습니다. 일부 모델(특히 순환 신경망을 기반으로 한 모델)은 잠재적으로 비선형 행 수가 있는 메모리 공간을 펼치고 표시합니다. 메모리 비용이 높은 모델의 경우 행 수준에서 유추를 실행하는 것이 좋습니다.
팁
더 나은 병렬화를 위해 한 번에 읽기에는 너무 큰 파일을 여러 개의 작은 파일로 나누는 것이 좋습니다.
이를 수행하는 방법을 알아보려면 일괄 처리 배포를 통한 이미지 처리를 참조하세요. 해당 예는 한 번에 파일을 처리합니다.
행 수준(테이블 형식)
입력 크기에 문제가 있는 모델의 경우 행 수준에서 유추를 실행하는 것이 좋습니다. 일괄 처리 배포는 여전히 파일의 미니 일괄 처리와 함께 채점 스크립트를 제공합니다. 그러나 한 번에 하나의 파일, 한 행을 읽습니다. 이는 비효율적으로 보일 수 있지만 일부 딥 러닝 모델의 경우 하드웨어 리소스의 크기를 조정하지 않고 유추를 수행하는 유일한 방법일 수 있습니다.
이를 수행하는 방법을 알아보려면 일괄 처리 배포를 통한 텍스트 처리를 참조하세요. 이 예는 한 번에 한 행씩 처리합니다.
폴더인 모델 사용
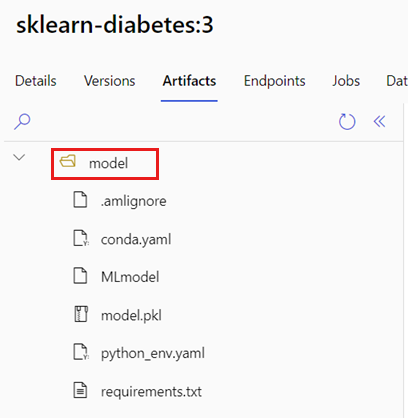
AZUREML_MODEL_DIR 환경 변수에는 선택한 모델 위치에 대한 경로가 포함되어 있으며, init() 함수는 일반적으로 이를 사용하여 모델을 메모리에 로드합니다. 그러나 일부 모델의 경우 해당 파일이 폴더에 포함될 수 있으므로 모델을 로드할 때 이를 고려해야 할 수도 있습니다. 다음과 같이 모델의 폴더 구조를 식별할 수 있습니다.
Azure Machine Learning 포털로 이동합니다.
모델 섹션으로 이동합니다.
배포하려는 모델을 선택하고 Artifacts 탭을 선택합니다.
표시된 폴더를 기록해 두세요. 이 폴더는 모델을 등록할 때 표시되었습니다.

모델을 로드하려면 다음 경로를 사용합니다.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)