대화형 개발 중에 Azure 클라우드 스토리지의 데이터에 액세스
적용 대상:  Python SDK azure-ai-ml v2(현재)
Python SDK azure-ai-ml v2(현재)
기계 학습 프로젝트는 일반적으로 EDA(예비 데이터 분석), 데이터 전처리(정리, 기능 엔지니어링)로 시작하며, 가설의 유효성을 검사하기 위한 ML 모델 프로토타입을 빌드하는 과정이 포함됩니다. 이 프로토타입 프로젝트 단계는 기본적으로 고도의 대화형 방식이며, Jupyter Notebook 또는 Python 대화형 콘솔이 포함된 IDE에서 개발하는 데 적합합니다. 이 문서에서는 다음 방법을 알아봅니다.
- Azure Machine Learning 데이터 저장소 URI의 데이터에 파일 시스템처럼 액세스합니다.
mltablePython 라이브러리를 사용하여 Pandas로 데이터를 구체화합니다.mltablePython 라이브러리를 사용하여 Azure Machine Learning 데이터 자산을 Pandas로 구체화합니다.azcopy유틸리티를 사용하여 명시적 다운로드를 통해 데이터를 구체화합니다.
필수 조건
- Azure Machine Learning 작업 영역 자세한 내용은 포털에서 또는 Python SDK(v2)를 사용하여 Azure Machine Learning 작업 영역 관리를 참조하세요.
- Azure Machine Learning 데이터 저장소 자세한 내용은 데이터 저장소 만들기를 참조하세요.
팁
이 문서의 지침에서는 대화형 개발 중 데이터 액세스를 설명합니다. Python 세션을 실행할 수 있는 모든 호스트에 적용됩니다. 여기에는 로컬 컴퓨터, 클라우드 VM, GitHub Codespace 등이 포함될 수 있습니다. 사전 구성된 완전 관리형 클라우드 워크스테이션인 Azure Machine Learning 컴퓨팅 인스턴스를 사용하는 것이 좋습니다. 자세한 내용은 Azure Machine Learning 컴퓨팅 인스턴스 만들기를 참조하세요.
Important
Python 환경에 최신 azure-fsspec, mltable 및 azure-ai-ml python 라이브러리가 설치되어 있는지 확인합니다.
pip install -U azureml-fsspec==1.3.1 mltable azure-ai-ml
최신 azure-fsspec 패키지 버전은 시간이 지남에 따라 변경될 수 있습니다. azure-fsspec 패키지에 대한 자세한 내용을 보려면 이 리소스를 방문하세요.
파일 시스템과 같은 데이터 저장소 URI의 데이터에 액세스
Azure Machine Learning 데이터 저장소는 기존 Azure 스토리지 계정에 대한 참조입니다. 데이터 저장소 생성 및 사용의 이점은 다음과 같습니다.
- 다양한 스토리지 유형(Blob/Files/ADLS)과 상호 작용하는 일반적이고 사용하기 쉬운 API가 제공됩니다.
- 팀 운영에서 유용한 데이터 저장소를 쉽게 검색할 수 있습니다.
- 데이터에 액세스하기 위해 자격 증명 기반(예: SAS 토큰) 및 ID 기반(Microsoft Entra ID 또는 관리 ID 사용) 액세스를 모두 지원합니다.
- 자격 증명 기반 액세스의 경우 스크립트에서 키 노출을 무효화하기 위해 연결 정보가 보호됩니다.
- Studio UI에서 데이터를 찾아보고 데이터 저장소 URI를 복사하여 붙여넣습니다.
데이터 저장소 URI는 Azure Storage 계정의 스토리지 위치(경로)에 대한 참조인 URI(Uniform Resource Identifier)입니다. 데이터 저장소 URI의 형식은 다음과 같습니다.
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
이러한 데이터 저장소 URI는 파일 시스템 사양(fsspec)의 알려진 구현으로, 로컬, 원격 및 포함된 파일 시스템과 바이트 스토리지에 대한 통합 Python 인터페이스입니다. 먼저, pip를 사용하여 azureml-fsspec 패키지와 해당 종속성 azureml-dataprep 패키지를 설치합니다. 그런 다음, Azure Machine Learning 데이터 저장소 fsspec 구현을 사용할 수 있습니다.
Azure Machine Learning 데이터 저장소 fsspec 구현은 Azure Machine Learning 데이터 저장소에서 사용하는 자격 증명/ID 통과를 자동으로 처리합니다. 스크립트에서 계정 키 노출과 컴퓨팅 인스턴스에서 추가적인 로그인 절차를 모두 방지할 수 있습니다.
예를 들어 Pandas에서 데이터 저장소 URI를 직접 사용할 수 있습니다. 이 예제에서는 CSV 파일을 읽는 방법을 보여 줍니다.
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
팁
데이터 저장소 URI 형식을 기억하지 않으려면 다음 단계에 따라 Studio UI에서 데이터 저장소 URI를 복사하여 붙여넣을 수 있습니다.
- 왼쪽 메뉴에서 데이터를 선택한 다음, 데이터 저장소 탭을 선택합니다.
- 데이터 저장소 이름을 선택한 다음, 찾아보기를 선택합니다.
- pandas로 읽을 파일/폴더를 찾고 옆에 있는 줄임표(...)를 선택합니다. 메뉴에서 URI 복사를 선택합니다. 데이터 저장소 URI를 선택하여 Notebook/스크립트에 복사할 수 있습니다.
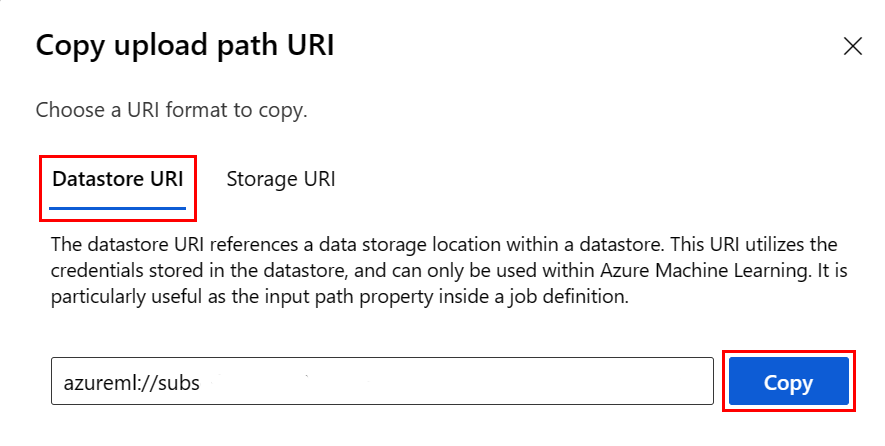
Azure Machine Learning 파일 시스템을 인스턴스화하여 파일 시스템과 유사한 명령(예: ls, glob, exists, open)을 처리할 수도 있습니다.
ls()메서드는 특정 디렉터리의 파일을 나열합니다. ls(), ls(.), ls(<<folder_level_1>/<folder_level_2>)를 사용하여 파일을 나열할 수 있습니다. 상대 경로에서 '.' 및 '..'를 모두 지원합니다.glob()메서드는 '*' 및 '**' 와일드 카드 사용을 지원합니다.exists()메서드는 지정된 파일이 현재 루트 디렉터리에 존재하는지 여부를 나타내는 부울 값을 반환합니다.open()메서드는 파일과 유사한 개체를 반환합니다. 이 개체는 Python 파일로 작동해야 하는 다른 라이브러리에 전달될 수 있습니다. 코드에서는 이 개체를 일반 Python 파일 개체인 것처럼 사용할 수도 있습니다. 이러한 파일과 유사한 개체는 다음 예제에 표시된 것처럼with컨텍스트 사용법을 준수합니다.
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
AzureMachineLearningFileSystem을 통해 파일 업로드
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath는 로컬 경로이고 rpath는 원격 경로입니다.
rpath에 지정한 폴더가 아직 존재하지 않으면, 해당 폴더가 만들어집니다.
세 가지 '덮어쓰기' 모드를 지원합니다.
- APPEND: 대상 경로에 같은 이름의 파일이 있는 경우 APPEND는 원본 파일을 유지합니다.
- FAIL_ON_FILE_CONFLICT: 대상 경로에 동일한 이름의 파일이 있는 경우 FAIL_ON_FILE_CONFLICT가 오류를 throw합니다.
- MERGE_WITH_OVERWRITE: 대상 경로에 동일한 이름의 파일이 있는 경우 MERGE_WITH_OVERWRITE는 기존 파일을 새 파일로 덮어씁니다.
AzureMachineLearningFileSystem을 통해 파일 다운로드
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
예제
이러한 예제에서는 일반적인 시나리오에서 파일 시스템 사양을 사용하는 방법을 보여 줍니다.
pandas로 단일 CSV 파일 읽기
다음과 같이 단일 CSV 파일을 Pandas로 읽을 수 있습니다.
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
CSV 파일 폴더를 Pandas로 읽기
Pandas read_csv() 메서드는 CSV 파일 폴더 읽기를 지원하지 않습니다. 이를 처리하려면 csv 경로를 glob으로 처리하고 Pandas concat() 메서드를 사용하여 이를 데이터 프레임에 연결합니다. 다음 코드 샘플은 Azure Machine Learning 파일 시스템을 사용하여 이 연결을 구현하는 방법을 보여 줍니다.
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Dask로 CSV 파일 읽어 들이기
이 예제에서는 Dask 데이터 프레임으로 CSV 파일을 읽는 방법을 보여 줍니다.
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
parquet 파일 폴더를 Pandas로 읽기
Parquet 파일은 ETL 프로세스의 일부로 일반적으로 폴더에 기록되며, 이 폴더는 진행률, 커밋 등과 같은 ETL 관련 파일을 내보낼 수 있습니다. 이 예제에서는 ETL 프로세스에서 생성된 파일(_로 시작하는 파일)을 보여줍니다. 이 파일은 데이터의 parquet 파일을 생성합니다.
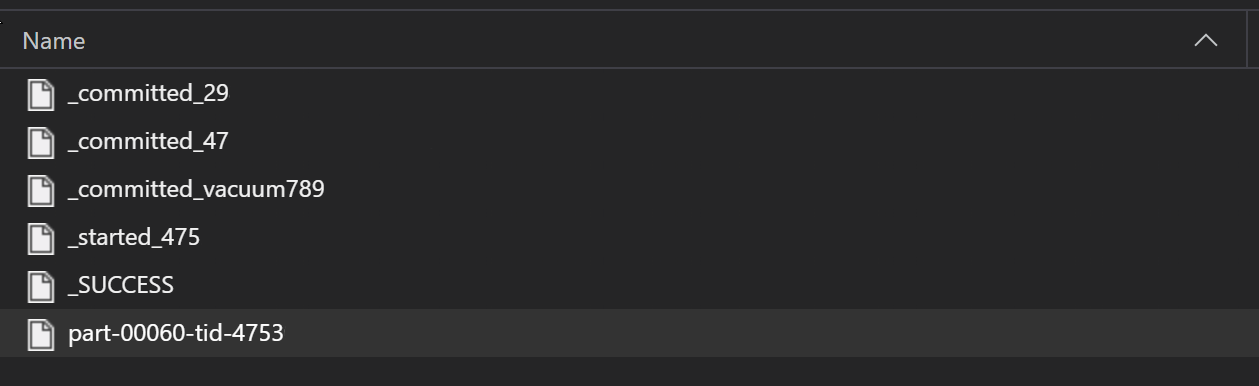
이러한 시나리오에서는 폴더의 parquet 파일만 읽고 ETL 프로세스 파일은 무시합니다. 이 코드 샘플은 GLOB 패턴이 폴더의 Parquet 파일만 읽을 수 있는 방법을 보여줍니다.
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Azure Databricks 파일 시스템(dbfs)의 데이터 액세스
파일 시스템 사양(fsspec)에는 알려진 구현의 범위가 있으며 Databricks 파일 시스템(dbfs)을 포함합니다.
dbfs 리소스의 데이터에 액세스하려면 다음이 필요합니다.
adb-<some-number>.<two digits>.azuredatabricks.net형식의 인스턴스 이름입니다. Azure Databricks 작업 영역의 URL에서 이 값을 찾을 수 있습니다.- PAT(개인용 액세스 토큰): PAT 생성에 대한 자세한 내용은 Azure Databricks 개인용 액세스 토큰을 사용한 인증을 참조하세요.
이러한 값을 사용하여 컴퓨팅 인스턴스의 PAT 토큰에 대한 환경 변수를 만들어야 합니다.
export ADB_PAT=<pat_token>
그러면 다음 예제와 같이 Pandas의 데이터에 액세스할 수 있습니다.
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
pillow를 사용하여 이미지 읽기
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
PyTorch 사용자 지정 데이터 세트 예제
이 예제에서는 이미지 처리를 위한 PyTorch 사용자 지정 데이터 세트를 만듭니다. 다음과 같은 전체 구조를 가진 주석 파일(CSV 형식)이 존재한다고 가정합니다.
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
하위 폴더는 해당 레이블에 따라 이러한 이미지를 저장합니다.
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
사용자 지정 PyTorch 데이터 세트 클래스는 다음과 같이 __init__, __len__ 및 __getitem__의 세 가지 함수를 구현해야 합니다.
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
그런 다음, 여기에 표시된 대로 데이터 세트를 인스턴스화할 수 있습니다.
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
mltable 라이브러리를 사용하여 데이터를 Pandas로 구체화
mltable 라이브러리는 클라우드 스토리지의 데이터에 액세스하는 데도 도움이 될 수 있습니다. mltable을 사용하여 Pandas로 데이터를 읽는 일반적인 형식은 다음과 같습니다.
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
지원되는 경로
mltable 라이브러리는 다양한 경로 형식에서 표 형식 데이터 읽기를 지원합니다.
| 위치 | 예제 |
|---|---|
| 로컬 컴퓨터의 경로 | ./home/username/data/my_data |
| 퍼블릭 http(s) 서버의 경로 | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Azure Storage의 경로 | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| 긴 형식의 Azure Machine Learning 데이터 저장소 | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
참고 항목
mltable은 Azure Storage 및 Azure Machine Learning 데이터 저장소의 경로에 대한 사용자 자격 증명 통과를 수행합니다. 기본 스토리지의 데이터에 액세스할 수 있는 권한이 없으면 데이터에 액세스할 수 없습니다.
파일, 폴더 및 GLOB
mltable은 다음에 대한 읽기를 지원합니다.
- 파일(예:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv) - 폴더(예:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/) - GLOB 패턴(예:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv) - 파일, 폴더 및/또는 GLOB 패턴의 조합
mltable 유연성을 통해 로컬 및 클라우드 스토리지의 조합과 파일/폴더/GLOB의 조합에서 데이터를 단일 데이터 프레임으로 구체화할 수 있습니다. 예시:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
지원되는 파일 형식
mltable은 다음 파일 형식을 지원합니다.
- 구분된 텍스트(예: CSV 파일):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - 델타:
mltable.from_delta_lake(paths=[path]) - JSON Lines 형식:
mltable.from_json_lines_files(paths=[path])
예제
CSV 파일 읽기
이 코드 조각의 자리 표시자(<>)를 특정 세부 정보로 업데이트합니다.
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
폴더의 parquet 파일 읽기
이 예제에서는 mltable이 와일드카드와 같은 GLOB 패턴을 사용하여 parquet 파일만 읽도록 하는 방법을 보여 줍니다.
이 코드 조각의 자리 표시자(<>)를 특정 세부 정보로 업데이트합니다.
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
데이터 자산 읽기
이 섹션에서는 Pandas에서 Azure Machine Learning 데이터 자산에 액세스하는 방법을 보여줍니다.
테이블 자산
이전에 Azure Machine Learning(mltable 또는 V1 TabularDataset)에서 테이블 자산을 만든 경우 다음 코드를 사용하여 해당 테이블 자산을 Pandas에 로드할 수 있습니다.
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
파일 자산
파일 자산(예: CSV 파일)을 등록한 경우 다음 코드를 사용하여 해당 자산을 Pandas 데이터 프레임으로 읽을 수 있습니다.
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
폴더 자산
폴더 자산(uri_folder 또는 V1 FileDataset)(예: CSV 파일이 포함된 폴더)을 등록한 경우 다음 코드를 사용하여 해당 자산을 Pandas 데이터 프레임으로 읽을 수 있습니다.
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Pandas를 사용한 대용량 데이터 볼륨 읽기 및 처리에 대한 참고 사항
팁
Pandas는 대용량 데이터 세트를 처리하도록 설계되지 않았습니다. Pandas는 컴퓨팅 인스턴스의 메모리에 맞는 데이터만 처리할 수 있습니다.
대규모 데이터 세트의 경우 Azure Machine Learning 관리형 Spark를 사용하는 것이 좋습니다. PySpark Pandas API를 제공합니다.
원격 비동기 작업으로 스케일 업하기 전에 대규모 데이터 세트의 작은 하위 집합에서 빠르게 반복할 수 있습니다. mltable은 take_random_sample 메서드를 사용하여 대규모 데이터의 샘플을 가져오는 기능을 기본 제공합니다.
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
다음 작업을 통해 대규모 데이터의 하위 집합을 사용할 수도 있습니다.
azcopy 유틸리티를 사용하여 데이터 다운로드
azcopy 유틸리티를 사용하여 데이터를 호스트(로컬 컴퓨터, 클라우드 VM, Azure Machine Learning 컴퓨팅 Instance 등)의 로컬 SSD에 파일 시스템으로 다운로드합니다. Azure Machine Learning 컴퓨팅 인스턴스에 사전 설치된 azcopy 유틸리티는 데이터 다운로드를 처리합니다. Azure Machine Learning 컴퓨팅 인스턴스 또는 DSVM(Data Science Virtual Machine)을 사용하지 않는 경우 azcopy를 설치해야 할 수 있습니다. 자세한 내용은 azcopy를 참조하세요.
주의
컴퓨팅 인스턴스의 /home/azureuser/cloudfiles/code 위치에 데이터를 다운로드하지 않는 것이 좋습니다. 이 위치는 데이터가 아닌 Notebook 및 코드 아티팩트를 저장하도록 설계되었습니다. 학습 시 이 위치에서 데이터를 읽으면 상당한 성능 오버헤드가 발생합니다. 대신 컴퓨팅 노드의 로컬 SSD인 home/azureuser에 데이터 스토리지를 사용하는 것이 좋습니다.
터미널을 열고 새 디렉터리를 만듭니다. 예를 들면 다음과 같습니다.
mkdir /home/azureuser/data
다음을 사용하여 azcopy에 로그인합니다.
azcopy login
다음으로, 스토리지 URI를 사용하여 데이터를 복사할 수 있습니다.
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST