Windows Data Science Virtual Machine을 사용하는 데이터 과학
Windows DSVM(Data Science Virtual Machine)은 데이터 탐색 및 모델링 작업을 지원하는 강력한 데이터 과학 개발 환경입니다. 이 환경은 미리 빌드되어 여러 가지 인기 있는 데이터 분석 도구가 미리 번들로 제공되어 온-프레미스, 클라우드 또는 하이브리드 배포에 대한 분석을 쉽게 시작할 수 있습니다.
DSVM은 Azure 서비스와 긴밀하게 작동합니다. 이미 Azure, Azure Synapse(이전의 SQL DW), Azure Data Lake, Azure Storage 또는 Azure Cosmos DB에 저장된 데이터를 읽고 처리할 수 있습니다. 또한 Azure Machine Learning과 같은 다른 분석 도구를 활용할 수도 있습니다.
이 문서에서는 DSVM을 사용하여 데이터 과학 작업을 처리하고 다른 Azure 서비스와 상호 작용하는 방법을 알아봅니다. DSVM이 처리할 수 있는 작업의 샘플은 다음과 같습니다.
- Jupyter Notebook을 사용하여 Python 2, Python 3 및 Microsoft R을 사용하여 브라우저에서 데이터를 실험합니다. (Microsoft R은 고성능을 위해 설계된 엔터프라이즈용 R 버전입니다.)
- Microsoft Machine Learning Server 및 Python을 사용하여 DSVM에서 로컬로 데이터를 검색하고 모델을 개발합니다.
- Azure Portal 또는 PowerShell을 사용하여 Azure 리소스를 관리합니다.
- DSVM에 탑재 가능한 드라이브로 Azure Files 공유를 사용하여 스토리지의 크기를 조정하고 대규모 데이터 세트/코드를 전체 팀과 공유합니다.
- GitHub을 통해 팀과 코드를 공유합니다. 사전 설치된 Git 클라이언트인 Git Bash와 Git GUI를 사용하여 리포지토리에 액세스합니다.
- Azure 데이터 및 분석 서비스에 액세스
- Azure Blob 스토리지
- Azure Cosmos DB
- Azure Synapse(이전의 SQL DW)
- Azure SQL Database
- DSVM에 사전 설치된 Power BI Desktop 인스턴스를 사용하여 보고서와 대시보드를 작성하고 클라우드에 배포합니다.
- 가상 머신에 더 많은 도구를 설치합니다.
참고 항목
이 문서에 나와 있는 많은 데이터 스토리지 및 분석 서비스에는 추가 사용량 요금이 적용됩니다. 자세한 내용은 Azure 가격 페이지를 참조하세요.
필수 구성 요소
- Azure 구독 Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
- Azure Portal에 프로비전된 DSVM입니다. 자세한 내용은 가상 머신 만들기 리소스를 참조하세요.
참고 항목
Azure Az PowerShell 모듈을 사용하여 Azure와 상호 작용하는 것이 좋습니다. 시작하려면 Azure PowerShell 설치를 참조하세요. Az PowerShell 모듈로 마이그레이션하는 방법에 대한 자세한 내용은 Azure PowerShell을 AzureRM에서 Azure로 마이그레이션을 참조하세요.
Jupyter Notebook 사용
Jupyter Notebook은 데이터 검색 및 모델링을 위한 브라우저 기반 "IDE"를 제공합니다. Jupyter Notebook에서 Python 2, Python 3 또는 R을 사용할 수 있습니다.
Jupyter Notebook을 시작하려면 시작 메뉴 또는 바탕 화면에서 Jupyter Notebook아이콘을 선택합니다. DSVM 명령 프롬프트에서 기존 Notebook을 호스팅하거나 새 Notebook을 만들 디렉터리에서 jupyter notebook 명령을 실행할 수도 있습니다.
Jupyter를 시작한 후 /notebooks 디렉터리로 이동합니다. 이 디렉터리는 DSVM에 미리 패키지된 예제 Notebook을 호스팅합니다. 마케팅 목록의 구성원을 관리할 수 있습니다.
- Notebook을 선택하여 코드를 살펴봅니다.
- 각 셀을 실행하려면 Shift+Enter 키를 선택합니다.
- Notebook 전체를 실행하려면 셀>실행을 선택합니다.
- 새 Notebook을 만듭니다. Jupyter 아이콘(왼쪽 상단 모서리)을 선택하고 새로 만들기 단추를 선택한 다음 Notebook 언어(커널이라고도 함)를 선택합니다.
참고 항목
현재 Jupyter에서는 Python 2.7, Python 3.6, R, Julia, PySpark 커널이 지원됩니다. R 커널은 오픈 소스 R과 Microsoft R 모두에서 프로그래밍을 지원합니다. Notebook에서 데이터를 탐색하고, 모델을 빌드하고, 선택한 라이브러리로 해당 모델을 테스트할 수 있습니다.
Microsoft Machine Learning Server를 사용하여 데이터 검색 및 모델 개발
참고 항목
Machine Learning Server 독립 실행형에 대한 지원은 2021년 7월 1일에 종료되었습니다. 2021년 6월 30일 이후 DSVM 이미지에서 제거했습니다. 기존 배포에서는 여전히 소프트웨어에 액세스할 수 있지만 지원은 2021년 7월 1일 이후 종료되었습니다.
DSVM에서 직접 데이터 분석에 R과 Python을 사용할 수 있습니다.
R의 경우 Visual Studio용 R 도구를 사용할 수 있습니다. Microsoft는 오픈 소스 CRAN R 리소스 외에도 다른 라이브러리를 제공합니다. 이러한 라이브러리는 확장성 있는 분석과 병렬 청크 분할 분석의 메모리 크기 제한 사항을 초과하는 데이터 청크 분할을 분석하는 기능을 모두 제공합니다.
Python의 경우 Visual Studio Community 버전 등의 IDE를 사용할 수 있습니다. 여기에는 PTVS(Visual Studio용 Python 도구) 확장이 사전 설치되어 있습니다. 기본적으로 루트 Conda 환경인 Python 3.6만 PTVS에서 구성됩니다. Anaconda Python 2.7을 사용하도록 설정하려면:
- 각 버전에 맞게 사용자 지정 환경을 만듭니다. Visual Studio Community 버전에서 도구>Python 도구>Python 환경을 선택한 다음 + 사용자 지정을 선택합니다.
- 설명을 제공하고, Anaconda Python 2.7에 대한 환경 접두사 경로를 c:\anaconda\envs\python2로 설정합니다.
- 자동 검색>적용을 차례로 선택하여 환경을 저장합니다.
Python 환경을 만드는 방법에 대한 자세한 내용은 PTVS 설명서 리소스를 참조하세요.
이제 새로운 Python 프로젝트를 만들 수 있습니다. 파일>새로 만들기>프로젝트>Python을 선택하고 빌드하려는 Python 애플리케이션 형식을 선택합니다. 마우스 오른쪽 단추로 Python 환경을 클릭한 다음, Python 환경 추가/제거를 선택하여 현재 프로젝트에 대한 Python 환경을 원하는 버전(Python 2.7 또는 3.6)으로 설정할 수 있습니다. PTVS 사용에 대한 자세한 내용은 제품 설명서를 참조하세요.
Azure 리소스 관리
DSVM을 사용하면 가상 머신에서 로컬로 분석 솔루션을 빌드할 수 있습니다. 또한 Azure 클라우드 플랫폼의 서비스에 액세스할 수 있습니다. Azure는 DSVM에서 관리하고 액세스할 수 있는 컴퓨팅, 스토리지, 데이터 분석 등 다양한 서비스를 제공합니다.
Azure 구독 및 클라우드 리소스를 관리하는 데 사용할 수 있는 옵션은 두 가지입니다.
브라우저에서 Azure Portal을 참조하세요.
PowerShell 스크립트를 사용합니다. 바탕 화면 바로 가기 또는 시작 메뉴에서 Azure PowerShell을 실행합니다. 자세한 내용은 Microsoft Azure PowerShell 설명서 리소스를 참조하세요.
공유 파일 시스템을 사용하여 스토리지 확장
데이터 과학자는 팀 내에서 대용량 데이터 세트, 코드 또는 기타 리소스를 공유할 수 있습니다. DSVM에는 약 45GB의 사용 가능한 공간이 있습니다. 스토리지를 확장하려면 Azure Files를 사용하여 하나 이상의 DSVM 인스턴스에 탑재하거나 REST API를 통해 액세스할 수 있습니다. Azure Portal 또는 Azure PowerShell을 사용하여 추가 전용 데이터 디스크를 추가할 수도 있습니다.
참고 항목
Azure Files 공유의 최대 공간은 5TB입니다. 각 파일의 크기 제한은 1TB입니다.
이 Azure PowerShell 스크립트는 Azure Files 공유를 만듭니다.
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
Azure의 모든 가상 머신에서 Azure Files 공유를 탑재할 수 있습니다. 대기 시간과 데이터 전송 요금을 방지하려면 VM과 스토리지 계정을 동일한 Azure 데이터 센터에 두는 것이 좋습니다. 다음 Azure PowerShell 명령은 DSVM에 드라이브를 탑재합니다.
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
VM의 일반적인 드라이브처럼 이 드라이브에 액세스할 수 있습니다.
GitHub에서 코드 공유
GitHub 코드 리포지토리는 Developer Community가 공유하는 다양한 도구에 대한 코드 샘플과 코드 원본을 호스팅합니다. Github는 코드 파일 버전을 추적하고 저장하는 기술로 Git를 사용합니다. GitHub는 사용자만의 리포지토리를 만드는 플랫폼 역할도 합니다. 고유의 리포지토리는 팀의 공유 코드와 설명서를 저장하고, 버전 제어를 구현하고, 코드를 보고 기여하려는 관련자의 액세스 권한을 제어할 수 있습니다. GitHub는 팀 내 협업, 커뮤니티에서 개발한 코드 사용, 커뮤니티에 대한 코드 기여를 지원합니다. Git에 대한 자세한 내용은 GitHub 도움말 페이지를 참조하세요.
DSVM은 GitHub 리포지토리에 액세스하기 위해 명령줄 및 GUI에서 클라이언트 도구와 함께 로드됩니다. Git Bash 명령줄 도구는 Git 및 GitHub와 함께 작동합니다. Visual Studio는 DSVM에 설치되며 Git 확장을 포함하고 있습니다. 시작 메뉴와 바탕 화면에는 이러한 도구의 아이콘이 있습니다.
git clone 명령을 사용하여 GitHub 리포지토리에서 코드를 다운로드합니다. 예를 들어, Microsoft에서 현재 디렉터리에 게시한 데이터 과학 리포지토리를 다운로드하려면 Git Bash에서 다음 명령을 실행합니다.
git clone https://github.com/Azure/DataScienceVM.git
Visual Studio에서는 동일한 복제 작업을 처리할 수 있습니다. Visual Studio에서 Git 및 GitHub 도구에 액세스하는 방법을 보여 주는 스크린샷.

GitHub 리포지토리에서 사용 가능한 github.com 리소스를 활용할 수 있습니다. 자세한 내용은 GitHub 치트 시트 리소스를 참조하세요.
Azure 데이터 및 분석 서비스에 액세스
Azure Blob 스토리지
Azure Blob Storage는 대규모와 소규모 데이터 리소스 모두를 위한 안정적이고 경제적인 클라우드 스토리지 서비스입니다. 이 섹션에서는 데이터를 Blob Storage로 옮기고 Azure Blob에 저장된 데이터에 액세스하는 방법을 설명합니다.
필수 조건
Azure Portal에서 만든 Azure Blob Storage 계정입니다.
다음 명령을 사용하여 명령줄 AzCopy 도구가 사전 설치되어 있는지 확인합니다.
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exeazcopy.exe를 호스팅하는 디렉터리는 이미 PATH 환경 변수에 있으므로, 이 도구를 실행할 때 전체 명령 경로를 입력하지 않아도 됩니다. AzCopy 도구에 대한 자세한 내용은 AzCopy 설명서를 참조합니다.
Azure Storage Explorer 도구를 시작합니다. 이 도구는 Storage Explorer 웹 페이지에서 다운로드 할 수 있습니다.


VM에서 Azure Blob으로 데이터 이동: AzCopy
로컬 파일과 Blob 스토리지 간에 데이터를 이동하려면 명령줄 또는 PowerShell에서 AzCopy를 사용할 수 있습니다.
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
- C:\myfolder를 파일을 호스팅하는 디렉터리 경로로 바꿉니다.
- mystorageaccount를 Blob Storage 계정 이름으로 바꿉니다.
- mycontainer를 컨테이너 이름으로 바꿉니다.
- 스토리지 계정 키를 Blob Storage 액세스 키로 바꿉니다.
스토리지 계정 자격 증명은 Azure Portal에서 찾을 수 있습니다.
PowerShell 또는 명령 프롬프트에서 AzCopy 명령을 실행합니다. 다음은 AzCopy 명령의 예입니다.
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
AzCopy 명령을 실행하여 Azure Blob에 파일을 복사하면 파일이 Azure Storage Explorer에 표시됩니다.

VM에서 Azure Blob으로 데이터 이동: Azure Storage Explorer
Azure Storage Explorer를 사용하여 VM의 로컬 파일에서 데이터를 업로드할 수도 있습니다.
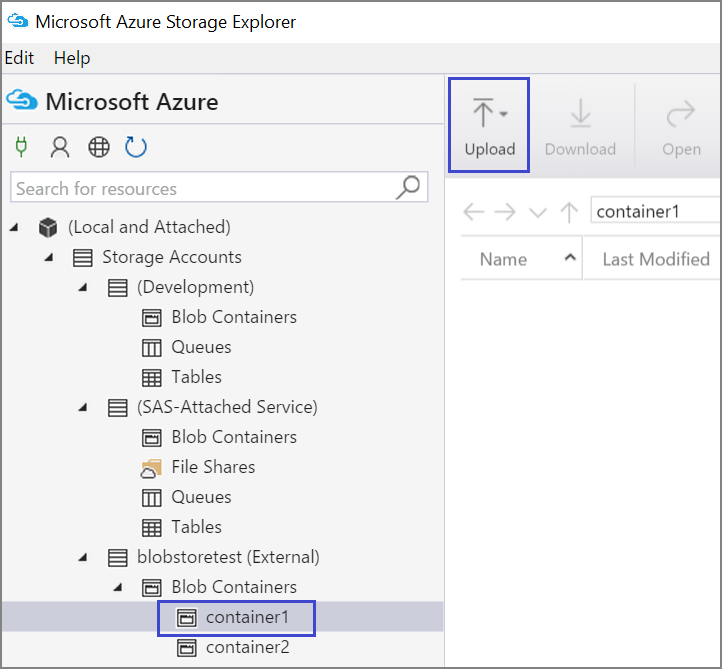
컨테이너에 데이터를 업로드하려면 대상 컨테이너를 선택하고 업로드 단추를 선택합니다.
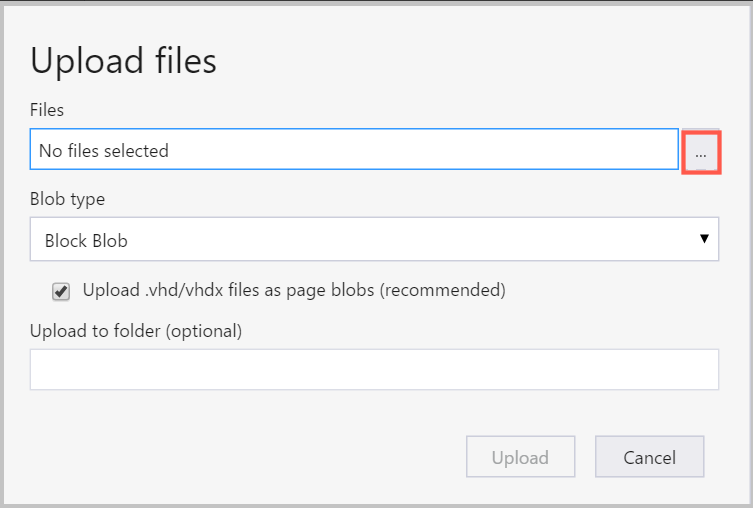
파일 상자 오른쪽의 줄임표(...)를 선택하고 파일 시스템에서 업로드할 파일을 하나 이상 선택한 후에 업로드를 선택하여 파일 업로드를 시작합니다.


Azure Blob에서 데이터 읽기: Python ODBC
BlobService 라이브러리는 Jupyter Notebook이나 Python 프로그램에 있는 blob에서 직접 데이터를 읽을 수 있습니다. 먼저 필요한 패키지를 가져옵니다.
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
Blob Storage 계정 자격 증명을 연결하고, Blob에서 데이터를 읽습니다.
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
데이터를 데이터 프레임으로 읽힙니다.

Azure Synapse Analytics 및 데이터베이스
Azure Synapse Analytics는 엔터프라이즈급 SQL Server 환경을 갖춘 탄력적인 "서비스 제공 데이터 웨어하우스"입니다. 이 리소스는 Azure Synapse Analytics를 프로비전하는 방법을 설명합니다. Azure Synapse Analytics를 프로비전한 후, 이 연습에서는 Azure Synapse Analytics 내의 데이터를 사용하여 데이터 업로드, 검색 및 모델링을 처리하는 방법을 설명합니다.
Azure Cosmos DB
Azure Cosmos DB는 클라우드 기반 NoSQL 데이터베이스입니다. 예를 들어, JSON 문서를 처리할 수 있으며, 문서를 저장하고 쿼리할 수 있습니다. 다음 예 단계에서는 DSVM에서 Azure Cosmos DB에 액세스하는 방법을 보여 줍니다.
Azure Cosmos DB Python SDK는 이미 DSVM에 설치되어 있습니다. 업데이트하려면 명령 프롬프트에서
pip install pydocumentdb --upgrade를 실행합니다.Azure Portal에서 Azure Cosmos DB 계정 및 데이터베이스를 만듭니다.
Microsoft 다운로드 센터에서 Azure Cosmos DB 데이터 마이그레이션 도구를 다운로드하고, 원하는 디렉터리에 압축을 풉니다.
마이그레이션 도구에 대한 다음 명령 매개 변수를 사용하여 공용 Blob에 저장된 JSON 데이터(화산 데이터)를 Azure Cosmos DB로 가져옵니다. (Azure Cosmos DB 데이터 마이그레이션 도구를 설치한 디렉터리의 dtui.exe를 사용합니다.) 아래의 원본 및 대상 위치를 다음 매개 변수와 함께 입력합니다.
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
데이터를 가져오면 Jupyter로 이동하여 DocumentDBSample이라는 Notebook을 열 수 있습니다. 여기에는 Azure Cosmos DB에 액세스하고 몇 가지 기본 쿼리를 처리하는 Python 코드가 포함되어 있습니다. Azure Cosmos DB에 대한 자세한 내용은 Azure Cosmos DB 서비스 설명서 페이지를 참조하세요.
Power BI 보고서 및 대시보드 사용
이전 Azure Cosmos DB 예에서 설명한 Volcano JSON 파일을 Power BI Desktop에서 시각화하여 데이터 자체에 대한 시각적 인사이트를 얻을 수 있습니다. 이 Power BI 문서에서는 자세한 단계를 제공합니다. 다음은 개략적인 단계입니다.
- Power BI Desktop을 열고 Get Data를 선택합니다. 다음 URL을 지정합니다.
https://cahandson.blob.core.windows.net/samples/volcano.json. - 목록으로 가져온 JSON 레코드가 표시되어야 합니다. 목록을 표로 변환하여 Power BI에서 사용할 수 있도록 합니다.
- 열을 확장하려면 확장(화살표) 아이콘을 선택합니다.
- 위치는 레코드 필드입니다. 레코드를 확장하고 좌표만 선택합니다. Coordinate는 목록 열입니다.
- 새 열을 추가하여 목록 좌표 열을 쉼표로 구분된 LatLong 열로 변환합니다.
Text.From([coordinates]{1})&","&Text.From([coordinates]{0})수식을 사용하여 좌표 목록 필드의 두 요소를 연결합니다. - Elevation 열을 10진수로 변환하고, 닫기 및 적용 단추를 선택합니다.
이전 단계의 대안으로 다음 코드를 사용할 수 있습니다. Power BI의 고급 편집기에서 사용되는 단계를 스크립팅하여 데이터 변환을 쿼리 언어로 작성합니다.
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
이제 Power BI 데이터 모델에 데이터가 있습니다. Power BI Desktop 인스턴스는 다음과 같이 표시됩니다.

데이터 모델을 사용하여 보고서와 시각화를 작성할 수 있습니다. 이 Power BI 문서에서는 보고서를 작성하는 방법을 설명합니다.
동적으로 DSVM 크기 조정
프로젝트 요구 사항에 맞게 DSVM의 크기를 조정하거나 크기 조정할 수 있습니다. VM을 저녁 또는 주말에 사용할 필요가 없는 경우 Azure Portal에서 VM을 종료할 수 있습니다.
참고 항목
VM에서 운영 체제의 종료 단추만 사용하는 경우 컴퓨팅 요금이 부과됩니다. 대신 Azure Portal 또는 Cloud Shell을 사용하여 DSVM의 할당을 취소해야 합니다.
대규모 분석 프로젝트의 경우 더 많은 CPU, 메모리 또는 디스크 용량이 필요할 수 있습니다. 그렇다면 사용자의 컴퓨팅 및 예산 요구 사항을 충족하는 딥 러닝을 위한 다양한 CPU 코어 수, 메모리 용량, 디스크 유형(반도체 드라이브 포함), GPU 기반 인스턴스를 갖춘 VM을 찾을 수 있습니다. Azure Virtual Machines 가격 책정 페이지에는 전체 VM 목록과 시간당 컴퓨팅 가격 책정이 표시됩니다.
더 많은 도구 추가
DSVM은 일반적인 데이터 분석 요구 사항을 많이 처리할 수 있는 미리 빌드된 도구를 제공합니다. 개별적으로 설치하고 환경을 구성할 필요가 없으므로 시간이 절약됩니다. 또한 사용한 리소스에 대해서만 비용을 지불하므로 비용도 절약할 수 있습니다.
이 문서에서 프로파일링한 다른 Azure 데이터 및 분석 서비스를 사용하여 분석 환경을 향상시킬 수 있습니다. 어떤 경우에는 특정 독점 파트너 도구를 포함한 다른 도구가 필요할 수도 있습니다. 필요한 도구를 설치할 수 있는 가상 머신에 대한 모든 관리 액세스 권한이 있습니다. Python과 R에 사전 설치되지 않은 다른 패키지를 설치할 수도 있습니다. Python의 경우 conda 또는 pip를 사용할 수 있습니다. R의 경우 R 콘솔에서 install.packages()를 사용하거나 IDE를 사용하여 패키지>패키지 설치를 차례로 선택할 수 있습니다.
딥 러닝
프레임워크 기반 샘플 외에도 DSVM에서 유효성 검사된 포괄적인 연습 과정을 가져올 수 있습니다. 이러한 연습 과정은 이미지와 텍스트/언어 분석 도메인에서 딥러닝 애플리케이션 개발을 시작하는 데 도움이 됩니다.
다양한 프레임워크에서 신경망 실행: 이 연습에서는 코드를 한 프레임워크에서 다른 프레임워크로 마이그레이션하는 방법을 보여 줍니다. 또한 프레임워크 간에 모델 및 런타임 성능을 비교하는 방법을 보여 줍니다.
이미지 내 제품을 검색하는 엔드투엔드 솔루션을 빌드하는 방법 가이드: 이미지 검색은 이미지 내의 개체를 찾고 분류할 수 있는 기술입니다. 이 기술에는 많은 실제 비즈니스 영역에서 엄청난 보상을 가져올 수 있는 잠재력이 있습니다. 예를 들어, 판매점은 이 기술을 사용하여 고객이 선반에서 집어든 제품을 식별할 수 있습니다. 이 정보는 소매점에서 제품 인벤토리를 관리하는 데 도움이 됩니다.
오디오 딥 러닝: 이 자습서에서는 도시 소리 데이터 세트에서 오디오 이벤트를 검색하기 위한 딥 러닝 모델을 학습시키는 방법을 보여 줍니다. 또한 오디오 데이터를 사용하는 방법에 대한 개요를 제공합니다.
텍스트 문서 분류: 이 연습에서는 Hierarchical Attention Network 및 LSTM(Long Short Term Memory) 네트워크라는 두 가지 신경망 아키텍처를 빌드하고 학습시키는 방법을 보여 줍니다. 이러한 신경망은 Keras API를 딥 러닝에 사용하여 텍스트 문서를 분류합니다.
요약
이 문서에서는 Microsoft Data Science Virtual Machine에서 수행할 수 있는 몇 가지 작업에 대해 설명했습니다. DSVM을 효과적인 분석 환경으로 만들기 위해 수행할 수 있는 더 많은 작업이 있습니다.