기계 학습 모델의 오류 평가
현재 모델 디버깅 사례의 가장 큰 과제 중 하나는 집계 메트릭을 사용하여 벤치마크 데이터 세트에서 모델의 점수를 매기는 것입니다. 모델 정확도는 데이터 하위 그룹 간에 균일하지 않을 수 있으며 모델이 더 자주 실패하는 입력 코호트가 있을 수 있습니다. 이러한 실패의 직접적인 결과는 안정성과 안전성의 부족, 공정성 문제의 출현, 기계 학습에 대한 신뢰 상실입니다.

오류 분석은 집계 정확도 메트릭에서 멀어집니다. 오류 분포를 개발자에게 투명하게 노출하고 오류를 효율적으로 식별하고 진단할 수 있도록 합니다.
책임 있는 AI 대시보드의 오류 분석 구성 요소는 기계 학습 실무자에게 모델 실패 분포에 대한 더 깊은 이해를 제공하고 잘못된 데이터 코호트를 신속하게 식별하는 데 도움이 됩니다. 이 구성 요소는 전체 벤치마크 오류율에 비해 오류율이 더 높은 데이터 코호트를 식별합니다. 다음을 통해 모델 수명 주기 워크플로의 식별 단계에 기여합니다.
- 오류율이 높은 코호트를 나타내는 의사 결정 트리입니다.
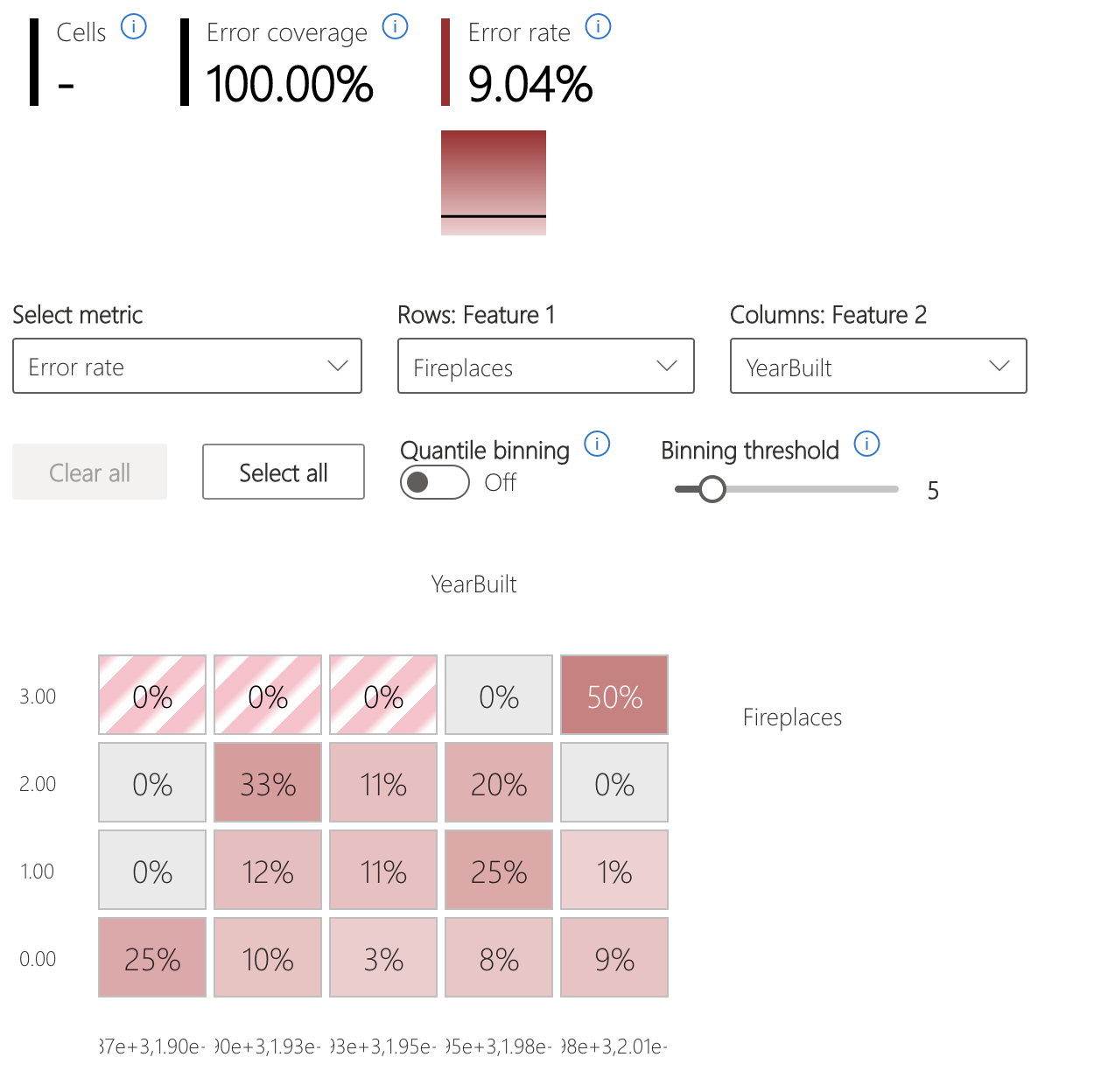
- 입력 기능이 코호트 전체의 오류율에 미치는 영향을 시각화하는 히트맵입니다.
특정 인구 그룹 또는 학습 데이터에서 자주 관찰되지 않는 입력 코호트에 대해 시스템이 저조한 성능을 보일 때 오류의 불일치가 발생할 수 있습니다.
이 구성 요소의 기능은 모델 오류 프로필을 생성하는 오류 분석 패키지에서 제공됩니다.
다음이 필요한 경우 오류 분석을 사용합니다.
- 데이터 세트와 여러 입력 및 기능 차원에서 모델 오류가 분포되는 방식을 깊이 이해합니다.
- 대상 완화 단계를 알리기 위해 집계 성능 메트릭을 분석하여 잘못된 코호트를 자동으로 발견합니다.
오류 트리
종종 오류 패턴은 복잡하고 하나 또는 둘 이상의 기능을 포함합니다. 개발자는 심각한 오류가 있는 숨겨진 데이터 포켓을 발견하기 위해 가능한 모든 기능 조합을 탐색하는 데 어려움을 겪을 수 있습니다.
부담을 완화하기 위해 이진 트리 시각화는 벤치마크 데이터를 예기치 않게 높거나 낮은 오류율을 갖는 해석 가능한 하위 그룹으로 자동 분할합니다. 즉, 트리는 입력 기능을 사용하여 모델 오류를 성공과 최대한 분리합니다. 데이터 하위 그룹을 정의하는 각 노드에 대해 사용자는 다음 정보를 조사할 수 있습니다.
- 오류율: 모델이 잘못된 노드 인스턴스의 일부입니다. 빨간색의 강도를 통해 표시됩니다.
- 오류 적용 범위: 노드에 속하는 모든 오류의 일부입니다. 노드의 유효 노출률을 통해 표시됩니다.
- 데이터 표현: 오류 트리의 각 노드에 있는 인스턴스 수입니다. 노드의 총 인스턴스 수와 함께 노드로 들어오는 에지의 두께를 통해 표시됩니다.

오류 열 지도
보기는 입력 기능의 1차원 또는 2차원 그리드를 기반으로 데이터를 분할합니다. 사용자는 분석을 위해 관심 있는 입력 기능을 선택할 수 있습니다.
히트맵은 오류가 높은 셀을 더 진한 빨간색으로 시각화하여 해당 영역에 사용자의 주의를 집중시킵니다. 이 기능은 실제로 자주 발생하는 오류 테마가 파티션 간에 다를 때 특히 유용합니다. 이 오류 식별 보기에서 분석은 사용자 및 어떤 기능이 실패를 이해하는 데 가장 중요할 수 있는지에 대한 사용자의 지식 또는 가설에 따라 크게 좌우됩니다.
다음 단계
- CLI 및 SDK 또는 Azure Machine Learning 스튜디오 UI를 통해 책임 있는 AI 대시보드를 생성하는 방법을 알아봅니다.
- 지원되는 오류 분석 시각화를 살펴봅니다.
- 책임 있는 AI 대시보드에서 관찰된 인사이트를 기반으로 하여 책임 있는 AI 성과 기록표를 생성하는 방법을 알아봅니다.