자습서: Azure Import/Export를 사용하여 Azure Files로 데이터 전송 | Microsoft Docs
이 아티클에서는 Azure Import/Export 서비스를 사용하여 Azure Files로 많은 양의 데이터를 안전하게 가져오는 방법에 대한 단계별 지침을 제공합니다. 데이터를 가져오려면 서비스를 사용하여 데이터가 포함된 지원되는 디스크 드라이브를 Azure 데이터 센터로 운송해야 합니다.
Import/Export 서비스는 Azure Storage로 Azure Files의 가져오기만을 지원합니다. Azure Files 내보내기는 지원되지 않습니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Azure Files로 데이터를 가져오기 위한 필수 조건
- 1단계: 드라이브 준비
- 2단계: 가져오기 작업 만들기
- 3단계: Azure 데이터 센터에 드라이브 배송
- 4단계: 추적 정보를 사용하여 작업 업데이트
- 5단계: Azure에 대한 데이터 업로드 확인
필수 조건
가져오기 작업을 만들어 Azure Files로 데이터를 전송하기 전에 다음 필수 조건 목록을 신중하게 검토하고 완료해야 합니다. 다음을 수행해야 합니다.
- Import/Export 서비스에 사용할 활성 Azure 구독이 있어야 합니다.
- Azure Storage 계정이 하나 이상 있어야 합니다. Import/Export 서비스에 지원되는 스토리지 계정 및 스토리지 유형 목록을 참조하세요. 새 스토리지 계정을 만드는 방법에 대한 자세한 내용은 스토리지 계정을 만드는 방법을 참조하세요.
- 지원되는 형식에 속한 적절한 개수의 디스크가 있어야 합니다.
- 지원되는 OS 버전을 실행하는 Windows 시스템이 있어야 합니다.
- Windows 시스템에서 파일용 Azure Import/Export 버전 2 도구의 현재 릴리스를 다운로드합니다.
- WAImportExport 버전 2를 다운로드합니다. 현재 버전은 2.2.0.300입니다.
WaImportExportV2기본 폴더에 압축을 풉니다. 예:C:\WaImportExportV2.
- 유효한 운송업체 계정과 주문에 대한 추적 번호가 있어야 합니다.
- 주문에 대한 배송 탭의 운송업체 이름 목록에 있는 운송업체를 사용해야 합니다. 운송업체 계정이 없는 경우 운송업체에 문의하여 계정을 만드세요.
- 운송업체 계정은 유효해야 하고, 잔액이 있어야 하며, 반품 기능이 있어야 합니다. Microsoft는 선택한 이동 통신 사업자를 사용하여 모든 스토리지 미디어를 반환합니다.
- 운송업체 계정에서 Import/Export 작업에 대한 추적 번호를 생성합니다. 모든 작업에는 별도의 추적 번호가 있어야 합니다. 추적 번호가 동일한 여러 작업은 지원되지 않습니다.
1단계: 드라이브 준비
외부 디스크를 파일 공유에 연결하고 WAImportExport.exe 파일을 실행합니다. 이 단계에서는 업무 일지 파일을 생성합니다. 업무 일지 파일에는 드라이브 일련 번호, 암호화 키 및 스토리지 계정 세부 정보와 같은 기본 정보가 저장됩니다.
다음 단계를 수행하여 드라이브를 준비합니다.
SATA 커넥터를 통해 디스크 드라이브를 Windows 시스템에 연결합니다.
각 드라이브에 단일 NTFS 볼륨을 만듭니다. 볼륨에 드라이브 문자를 할당합니다. 탑재 지점은 사용하지 마세요.
도구가 있는 루트 폴더에서 dataset.csv 파일을 수정합니다. 파일 또는 폴더 중 하나 또는 둘 다를 가져올지에 따라 다음 예제와 비슷한 dataset.csv 파일에 항목을 추가합니다.
파일을 가져오려면: 다음 예에서 F: 드라이브에 복사할 데이터가 있습니다. MyFile1.txt 파일을 MyAzureFileshare1의 루트에 복사합니다. MyAzureFileshare1이 없으면 Azure Storage 계정에 만들어집니다. 폴더 구조는 유지됩니다.
BasePath,DstItemPathOrPrefix,ItemType "F:\MyFolder1\MyFile1.txt","MyAzureFileshare1/MyFile1.txt",file폴더를 가져오려면: MyFolder2 아래의 모든 파일과 폴더가 fileshare에 반복적으로 복사됩니다. 폴더 구조는 유지됩니다. 대상 폴더에 있는 기존 파일과 이름이 같은 파일을 가져오는 경우 가져온 파일이 해당 파일을 덮어쓰게 됩니다.
"F:\MyFolder2\","MyAzureFileshare1/",file참고 항목
이전 버전의 도구에 이미 있는 파일을 가져올 때 수행할 작업을 선택할 수 있는 /Disposition 매개 변수는 Azure Import/Export 버전 2.2.0.300에서 지원되지 않습니다. 이전 도구 버전에서는 기존 파일과 이름이 같은 가져온 파일의 이름이 기본적으로 바뀌었습니다.
가져온 폴더 또는 파일에 해당하는 같은 파일에 여러 항목을 만들 수 있습니다.
"F:\MyFolder1\MyFile1.txt","MyAzureFileshare1/MyFile1.txt",file "F:\MyFolder2\","MyAzureFileshare1/",file
도구가 있는 루트 폴더에서 driveset.csv 파일을 수정합니다. 다음 예제와 비슷한 driveset.csv 파일에 항목을 추가합니다. 드라이브 집합 파일에는 디스크 및 해당하는 드라이브 문자 목록이 있으므로 도구는 준비해야 할 디스크 목록을 올바르게 선택할 수 있습니다.
이 예제에서는 두 개의 디스크가 연결되어 있고 기본 NTFS 볼륨 G:\ 및 H:\가 생성되었다고 가정합니다. G:가 이미 암호화된 반면 H:\는 암호화되지 않았습니다. 도구는 H:\만을 호스트하는 디스크를 포맷하고 암호화합니다(G: 제외).
암호화되지 않은 디스크의 경우: 암호화를 지정하여 디스크에서 BitLocker 암호화를 사용합니다.
DriveLetter,FormatOption,SilentOrPromptOnFormat,Encryption,ExistingBitLockerKey H,Format,SilentMode,Encrypt,이미 암호화되어 있는 디스크의 경우: AlreadyEncrypted를 지정하고 BitLocker 키를 제공합니다.
DriveLetter,FormatOption,SilentOrPromptOnFormat,Encryption,ExistingBitLockerKey G,AlreadyFormatted,SilentMode,AlreadyEncrypted,060456-014509-132033-080300-252615-584177-672089-411631여러 드라이브에 해당하는 같은 파일에 여러 항목을 만들 수 있습니다. 드라이브 집합 CSV 파일 준비에 대해 자세히 알아보세요.
PrepImport옵션을 사용하여 디스크 드라이브에 대한 데이터를 복사하고 준비합니다. 새 복사 세션을 사용하여 디렉터리 및/또는 파일을 복사하는 첫 번째 복사 세션의 경우 다음과 같은 명령을 실행합니다..\WAImportExport.exe PrepImport /j:<JournalFile> /id:<SessionId> [/logdir:<LogDirectory>] [/silentmode] [/InitialDriveSet:<driveset.csv>]/DataSet:<dataset.csv>아래에 가져오기 예제가 나와 있습니다.
.\WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#1 /InitialDriveSet:driveset.csv /DataSet:dataset.csv /logdir:C:\logs참고 항목
클라이언트에서 긴 경로를 사용하도록 설정하지 않고 데이터 복사본의 경로 및 파일 이름이 256자를 초과하는 경우 WAImportExport 도구는 실패를 보고합니다. 이러한 종류의 오류를 방지하려면 Windows 클라이언트에서 긴 경로를 사용하도록 설정합니다.
명령줄을 실행할 때마다
/j:매개 변수와 함께 제공된 이름의 업무 일지 파일이 만들어집니다. 준비한 각 드라이브에는 가져오기 작업을 만들 때 업로드해야 하는 업무 일지 파일이 있습니다. 업무 일지 파일이 없는 드라이브는 처리되지 않습니다.Important
디스크 준비를 완료한 후에는 저널 파일이나 디스크 드라이브의 데이터를 수정하지 말고 디스크를 다시 포맷하지 마세요.
추가 예제는 업무 일지 파일에 대한 샘플로 이동합니다.
2단계: 가져오기 작업 만들기
포털을 통해 Azure Import/Export 작업에서 가져오기 작업을 주문하려면 다음 단계를 수행합니다.
Microsoft Azure 자격 증명을 사용하여 다음 URL에서 로그인합니다. https://portal.azure.com
+ 리소스 만들기를 선택하고 Azure Data Box를 검색합니다. Azure Data Box를 선택합니다.

만들기를 실행합니다.
![Azure Data Box를 선택한 후 Azure Portal 화면 위쪽의 스크린샷 [만들기] 단추가 강조 표시되어 있습니다.](../includes/media/storage-import-export-preview-import-steps/import-export-order-preview-02.png)
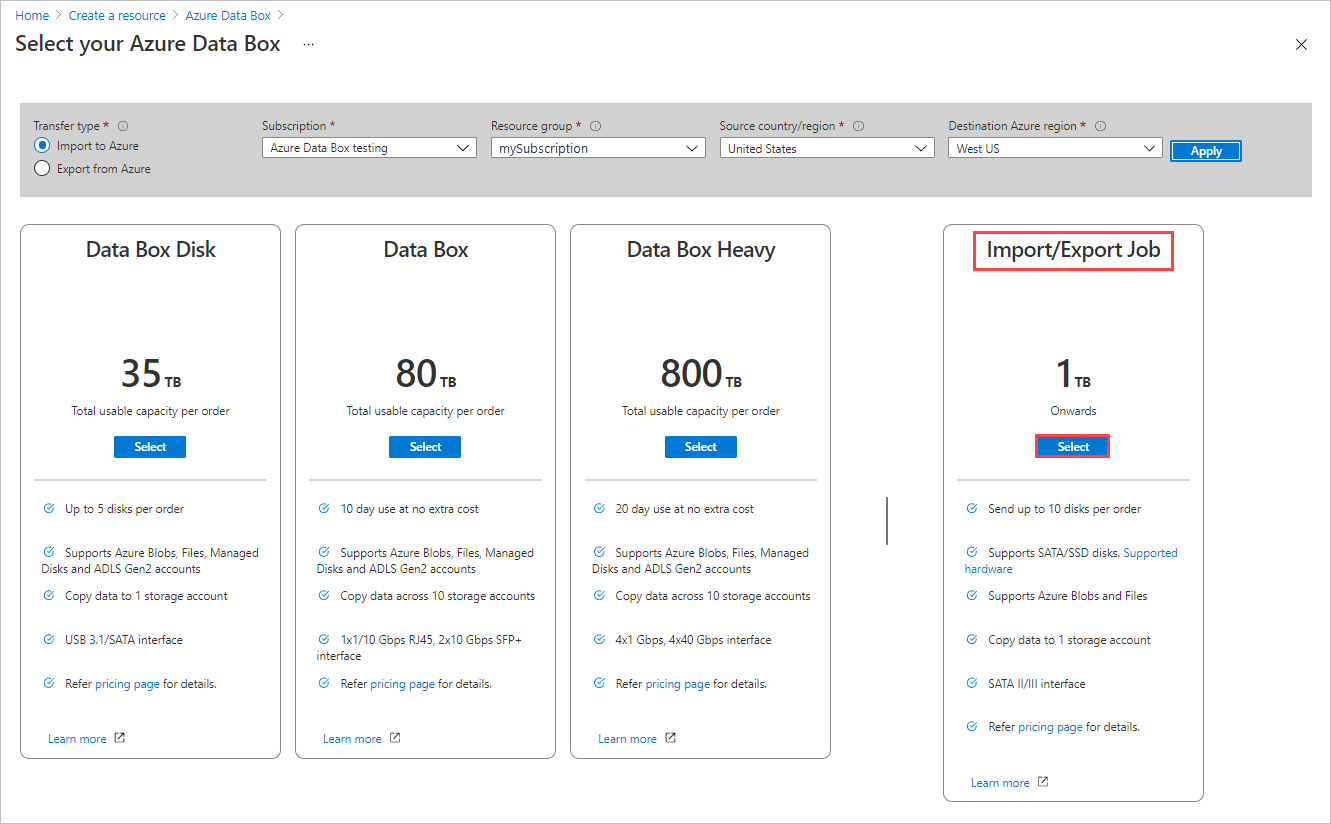
가져오기 주문을 시작하려면 다음 옵션을 선택합니다.
- Azure로 가져오기 전송 형식을 선택합니다.
- Import/Export 작업에 사용할 구독을 선택합니다.
- 리소스 그룹을 선택합니다.
- 작업의 원본 국가/지역을 선택합니다.
- 작업에 대한 대상 Azure 지역을 선택합니다.
- 그런 다음 적용을 선택합니다.

Import/Export 작업에 대해 선택 단추를 선택합니다.
기본 사항에서
- 작업에 대한 설명이 포함된 이름을 입력합니다. 이름을 사용하여 작업 진행 상황을 추적합니다.
- 이름은 3~ 24자여야 합니다.
- 이름에는 문자, 숫자 및 하이픈만 포함해야 합니다.
- 이름은 문자 또는 숫자로 시작하고 끝나야 합니다.

다음: 작업 세부 정보 >를 선택하여 계속 진행합니다.
- 작업에 대한 설명이 포함된 이름을 입력합니다. 이름을 사용하여 작업 진행 상황을 추적합니다.
작업 세부 정보에서:
더 진행하기 전에 최신 WAImportExport 도구를 사용하고 있는지 확인합니다. 이 도구는 업로드한 저널 파일을 읽는 데 사용됩니다. 다운로드 링크를 사용하여 도구를 업데이트할 수 있습니다.
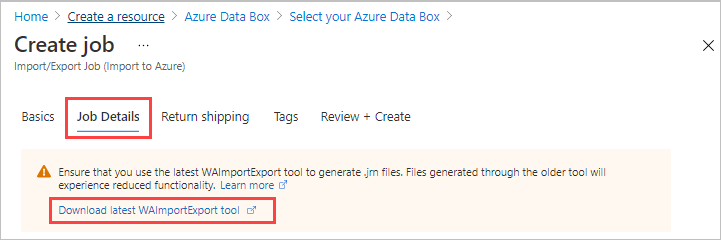
필요한 경우 작업의 대상 Azure 지역을 변경합니다.
작업에 사용할 스토리지 계정을 하나 이상 선택합니다. 필요한 경우 새 스토리지 계정을 만들 수 있습니다.
드라이브 정보에서 복사 단추를 사용하여 이전 1단계: 드라이브 준비에서 만든 각 저널 파일을 업로드합니다. 저널 파일을 업로드하면 드라이브 ID가 표시됩니다.
waimportexport.exe version1이 사용된 경우 준비한 각 드라이브에 대해 파일을 하나씩 업로드합니다.저널 파일이 2MB보다 크면 저널 파일과 함께 만들어진
<Journal file name>_DriveInfo_<Drive serial ID>.xml을 사용할 수 있습니다.
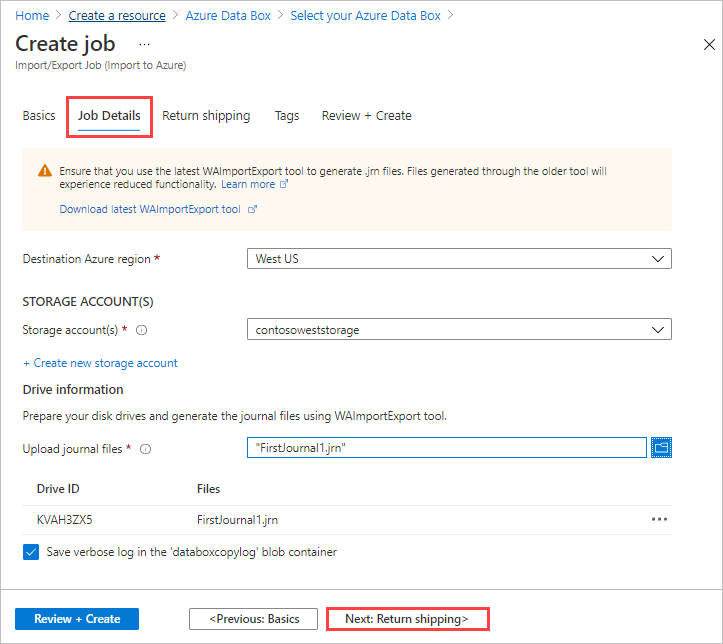
반송에서 다음을 수행합니다.
운송업체 드롭다운 목록에서 운송업체를 선택합니다. 선택한 지역에 대한 Microsoft 데이터 센터의 위치에 따라 사용 가능한 운송업체가 결정됩니다.
운송업체 계정 번호를 입력합니다. 유효한 운송업체 계정의 계정 번호가 필요합니다.
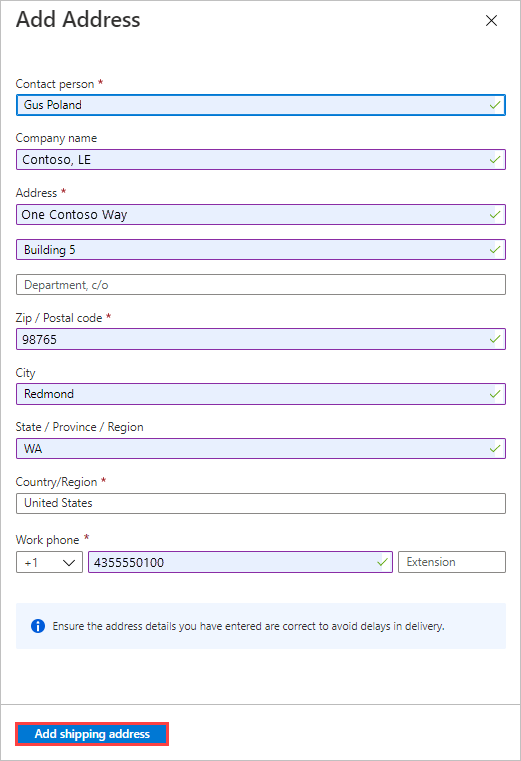
반환 주소 영역에서 + 주소 추가 단추를 선택하고 배송할 주소를 추가합니다.
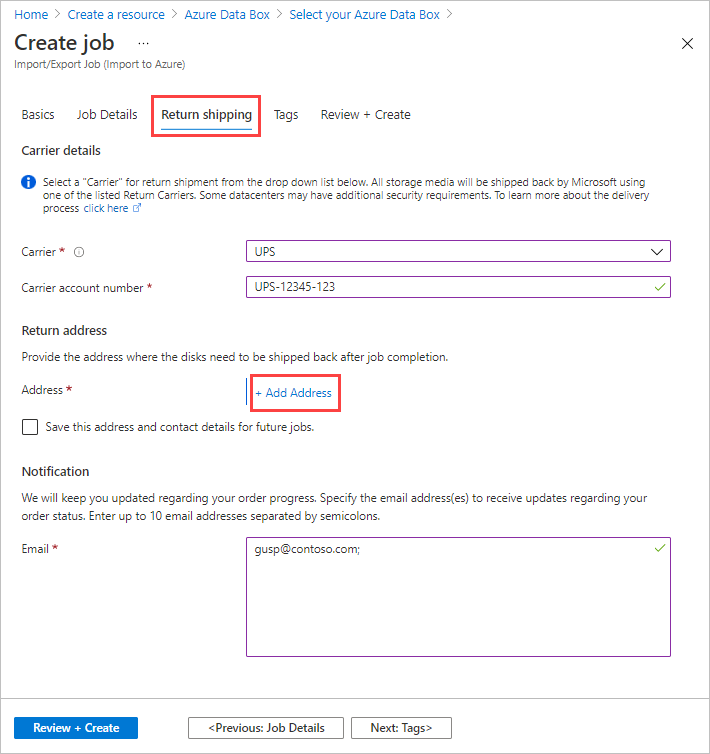
주소 추가 블레이드에서 주소를 추가하거나 기존 주소를 사용할 수 있습니다. 주소 입력란을 완료했으면 배송지 주소 추가를 선택합니다.
알림 영역에서 작업 진행 상황을 알리려는 사용자의 이메일 주소를 입력합니다.
팁
단일 사용자의 이메일 주소를 지정하는 대신, 관리자가 떠나더라도 알림을 받을 수 있도록 그룹 메일을 제공합니다.

검토 + 만들기를 선택하여 계속 진행합니다.
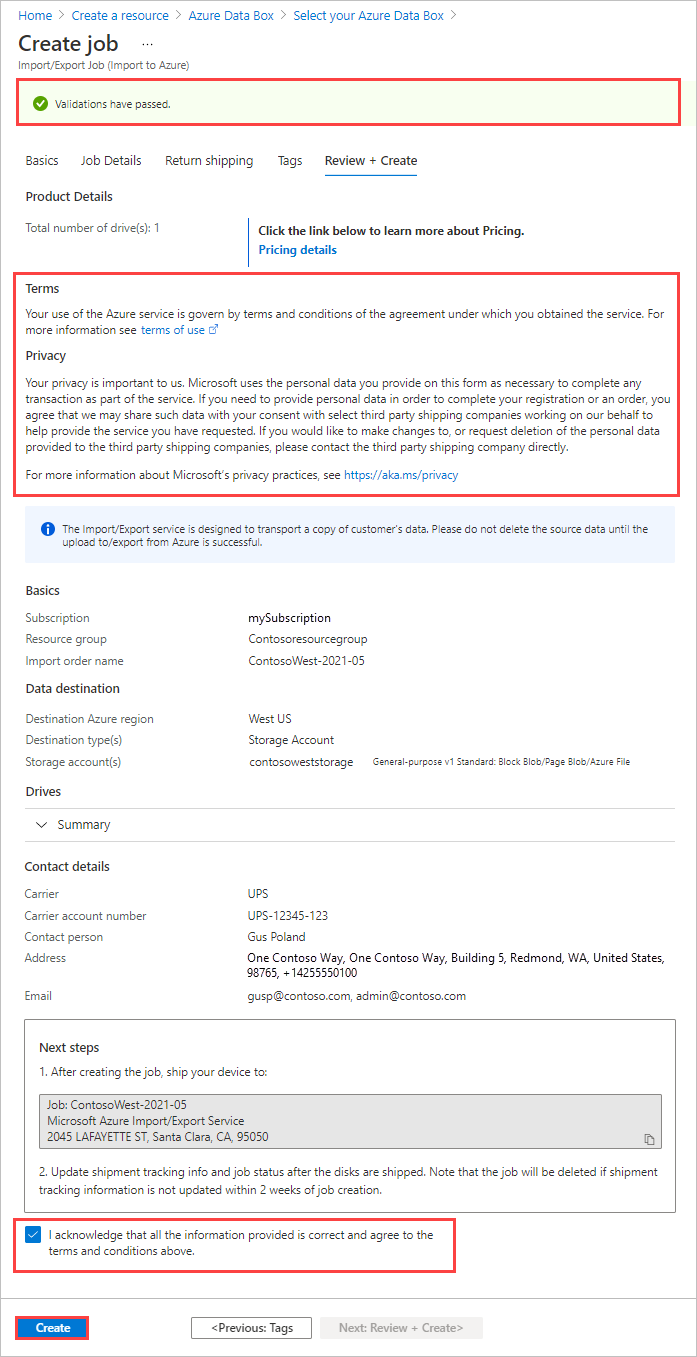
검토 + 만들기에서:
- 약관 및 개인정보보호 정보를 검토한 다음, "입력한 모든 정보가 올바르며 사용 약관에 동의한다는 사실을 인지합니다." 확인란을 선택합니다. 그러면 유효성 검사가 수행됩니다.
- 작업 정보를 검토합니다. 작업 이름과 디스크를 반송할 Azure 데이터 센터 배송지 주소를 적어 둡니다. 이 정보는 나중에 운송 레이블에 사용됩니다.
- 만들기를 실행합니다.
작업이 만들어지면 다음 메시지가 표시됩니다.

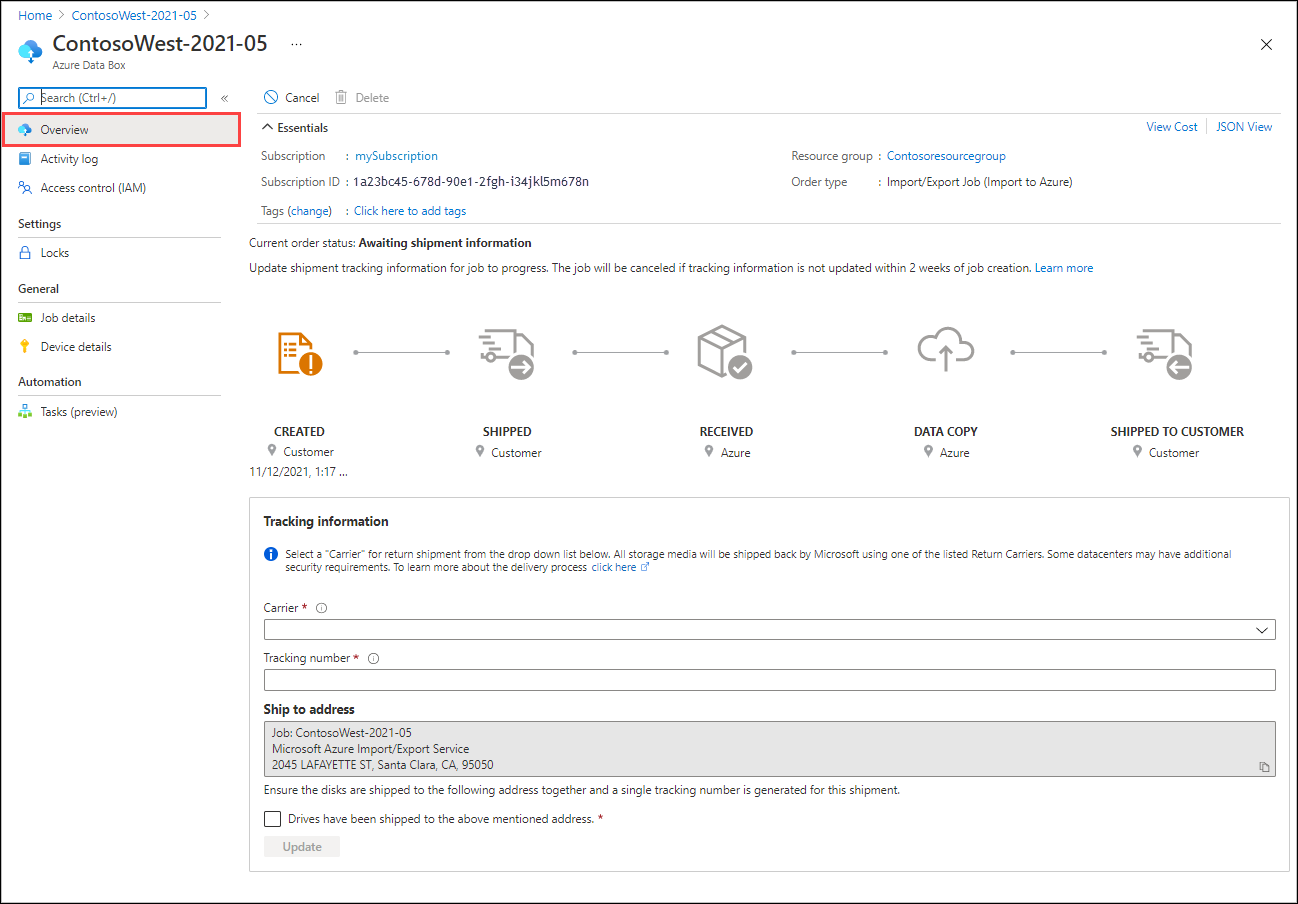
리소스로 이동을 선택하여 작업의 개요를 열 수 있습니다.



3단계: Azure 데이터 센터에 드라이브 운송
FedEx, UPS 또는 DHL을 통해 패키지를 Azure 데이터 센터로 보낼 수 있습니다. FedEx/DHL 이외의 운송업체를 사용하려면 adbops@microsoft.com에 있는 Azure Data Box 운영 팀에 문의하세요.
- Microsoft에서 드라이브를 반환하는 데 사용할 유효한 FedEx, UPS 또는 DHL 운송업체 계정 번호를 제공합니다.
- 패키지를 발송할 때는 Microsoft Azure 서비스 조건을 따라야 합니다.
- 잠재적 손상 및 처리 지연을 방지하기 위해 디스크를 적절하게 패키지합니다. 다음 권장 모범 사례를 따릅니다.
- 보호 버블 랩으로 디스크 드라이브를 안전하게 래핑합니다. 거품형 랩은 충격 흡수제 역할을 하며 전송 중에 드라이브가 충격으로부터 보호합니다. 배송 전에 전체 드라이브가 완전히 덮여 있고 쿠션이 있는지 확인합니다.
- 포장된 드라이브를 폼 운송업체 내에 놓습니다. 폼 운송업체는 추가적인 보호 기능을 제공하며 운송 중에 드라이브를 안전하게 보관합니다.
4단계: 추적 정보를 사용하여 작업 업데이트
디스크를 배송한 후 Azure Portal의 작업으로 돌아가서 추적 정보를 입력합니다.
추적 세부 정보를 제공한 후에는 작업 상태가 배송으로 변경되고 작업을 취소할 수 없습니다. 만들기 상태에 있는 동안에만 작업을 취소할 수 있습니다.
Important
작업을 만든 지 2 주 이내에 추적 번호를 업데이트하지 않으면, 작업이 만료됩니다.
Portal에서 만든 작업에 대한 추적 정보를 완료하려면 다음 단계를 수행합니다.
Azure Portal에서 작업을 엽니다.
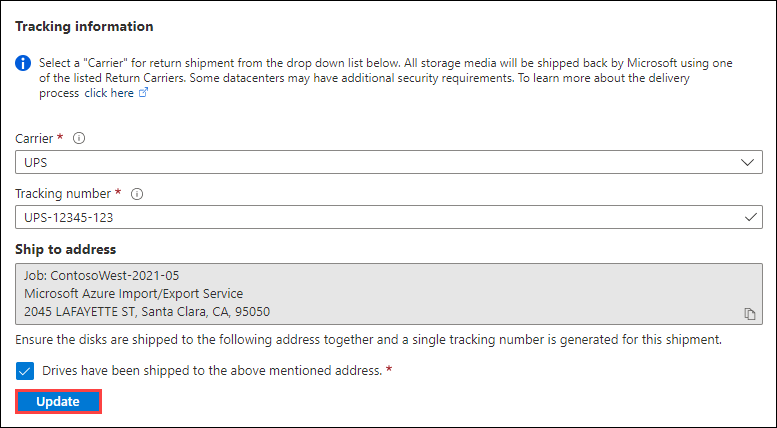
개요 창에서 추적 정보까지 아래로 스크롤한 후 항목을 완료합니다.
- 운송업체 및 추적 번호를 제공합니다.
- 배송지 주소가 올바른지 확인합니다.
- "드라이브가 위에서 언급한 주소로 배송되었습니다." 확인란을 선택합니다.
- 완료되면 업데이트를 선택합니다.
개요 창에서 작업 진행률을 추적할 수 있습니다. 각 작업 상태에 대한 설명을 보려면 작업 상태 보기로 이동합니다.
![]()
5단계: Azure에 대한 데이터 업로드 확인
작업을 완료까지 추적한 다음 업로드가 성공했으며 모든 데이터가 있는지 확인합니다.
완료된 작업의 데이터 복사 세부 정보를 검토하여 작업에 포함된 각 드라이브의 로그를 찾습니다.
- 자세한 정보 로그를 사용하여 성공적으로 전송된 각 파일을 확인합니다.
- 실패한 각 데이터 복사의 원본을 찾으려면 복사 로그를 사용합니다.

자세한 내용은 가져오기 및 내보내기에서 복사 로그 검토를 참조하세요.
데이터 전송을 확인한 후 온-프레미스 데이터를 삭제할 수 있습니다. 업로드가 성공했는지 확인한 후에만 온-프레미스 데이터를 삭제합니다.
참고 항목
파일용 Azure Import/Export 도구의 최신 버전(2.2.0.300)에서 파일 공유에 사용 가능한 공간이 충분하지 않은 경우 데이터는 더 이상 여러 Azure 파일 공유로 자동 분할되지 않습니다. 대신, 복사에 실패하고 지원팀에서 연락을 드립니다. 공유 공간을 만들기 위해 일부 데이터를 이동해야 할 수 있습니다.
업무 일지 파일에 대한 샘플
드라이브를 추가하려면 새 드라이브 집합 파일을 만들고 아래 명령을 실행합니다.
InitialDriveset .csv 파일에 지정된 것과 다른 디스크 드라이브에 대한 후속 복사 세션의 경우 새 드라이브 집합 .csv 파일을 지정하고 AdditionalDriveSet 매개 변수에 값으로 제공합니다. 동일한 저널 파일 이름을 사용하고 새 세션 ID를 제공합니다. AdditionalDriveset CSV 파일의 형식은 InitialDriveSet 형식과 같습니다.
WAImportExport.exe PrepImport /j:<JournalFile> /id:<SessionId> /AdditionalDriveSet:<driveset.csv>
아래에 가져오기 예제가 나와 있습니다.
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#3 /AdditionalDriveSet:driveset-2.csv
추가 데이터를 동일한 드라이브 집합에 추가하려면 후속 복사 세션에 PrepImport 명령을 사용하여 추가 파일/디렉터리를 복사합니다.
InitialDriveset.csv 파일에서 지정된 동일한 하드 디스크 드라이브에 대한 후속 복사 세션의 경우 동일한 업무 일지 파일 이름을 지정하고, 새 세션 ID를 제공합니다. 스토리지 계정 키를 제공하지 않아도 됩니다.
WAImportExport PrepImport /j:<JournalFile> /id:<SessionId> /j:<JournalFile> /id:<SessionId> [/logdir:<LogDirectory>] DataSet:<dataset.csv>
아래에 가져오기 예제가 나와 있습니다.
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#2 /DataSet:dataset-2.csv