엔터프라이즈 보안 패키지를 사용하여 HDInsight에서 Spark SQL에 대한 Apache Ranger 정책 구성
이 문서에서는 HDInsight의 엔터프라이즈 보안 패키지를 사용하여 Spark SQL에 대한 Apache Ranger 정책을 구성하는 방법을 설명합니다.
이 문서에서는 다음 방법을 설명합니다.
- Apache Ranger 정책을 만듭니다.
- 적용된 Ranger 정책을 확인합니다.
- Spark SQL용 Apache Ranger를 설정하기 위한 지침을 적용합니다.
필수 조건
- 엔터프라이즈 보안 패키지가 포함된 HDInsight 버전 5.1의 Apache Spark 클러스터
Apache Ranger 관리자 UI에 커넥트
브라우저에서 URL
https://ClusterName.azurehdinsight.net/Ranger/을 사용하여 Ranger 관리자 사용자 인터페이스에 연결합니다.Spark 클러스터의 이름으로 변경
ClusterName합니다.Microsoft Entra 관리자 자격 증명을 사용하여 로그인합니다. Microsoft Entra 관리자 자격 증명은 HDInsight 클러스터 자격 증명 또는 Linux HDInsight 노드 SSH(Secure Shell) 자격 증명과 동일하지 않습니다.
도메인 사용자 만들기
do기본 사용자를 만드는 sparkuser 방법에 대한 자세한 내용은 ESP를 사용하여 HDInsight 클러스터 만들기를 참조하세요. 프로덕션 시나리오에서는 사용자가 Microsoft Entra 테넌트에서 온 기본.
Ranger 정책 만들기
이 섹션에서는 다음 두 가지 Ranger 정책을 만듭니다.
- Spark SQL에서 액세스하기
hivesampletable위한 액세스 정책 - 에서 열을 난독 처리하기 위한 마스킹 정책
hivesampletable
Ranger 액세스 정책 만들기
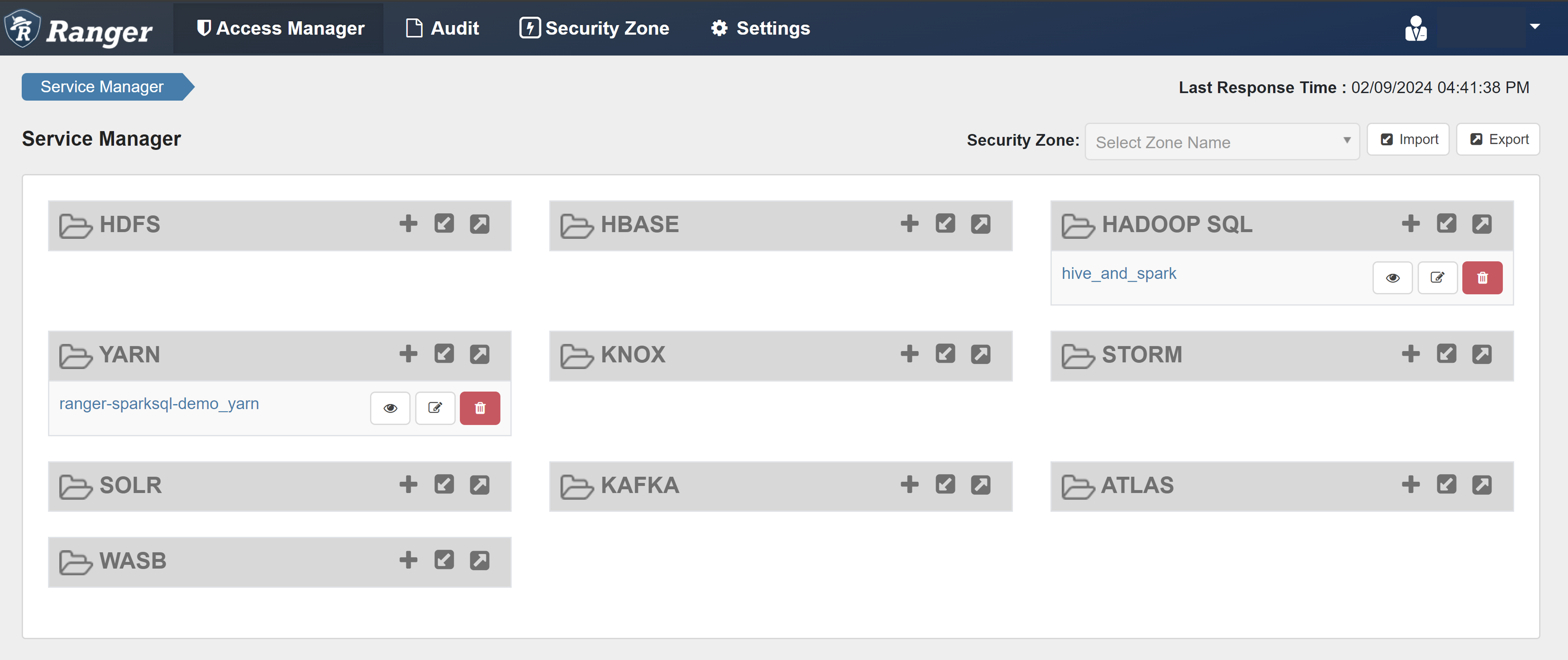
Ranger 관리 UI를 엽니다.
HADOOP SQL에서 hive_and_spark 선택합니다.
액세스 탭에서 새 정책 추가를 선택합니다.
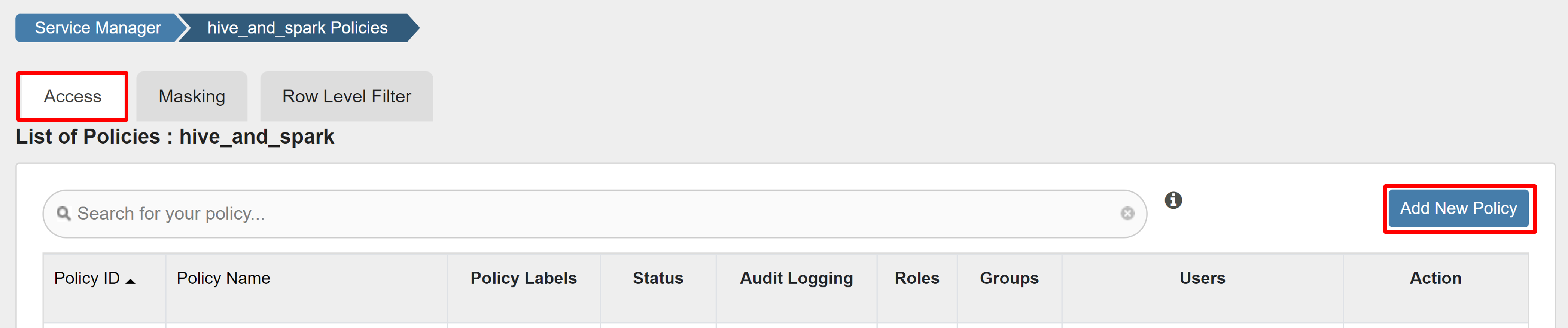
다음 값을 입력합니다.
속성 값 정책 이름 read-hivesampletable-all database default table hivesampletable column * 사용자 선택 sparkuser사용 권한 선택 
do기본 사용자가 사용자 선택으로 자동으로 채워지지 않는 경우 Ranger가 Microsoft Entra ID와 동기화될 때까지 잠시 기다립니다.
추가를 선택하여 정책을 저장합니다.
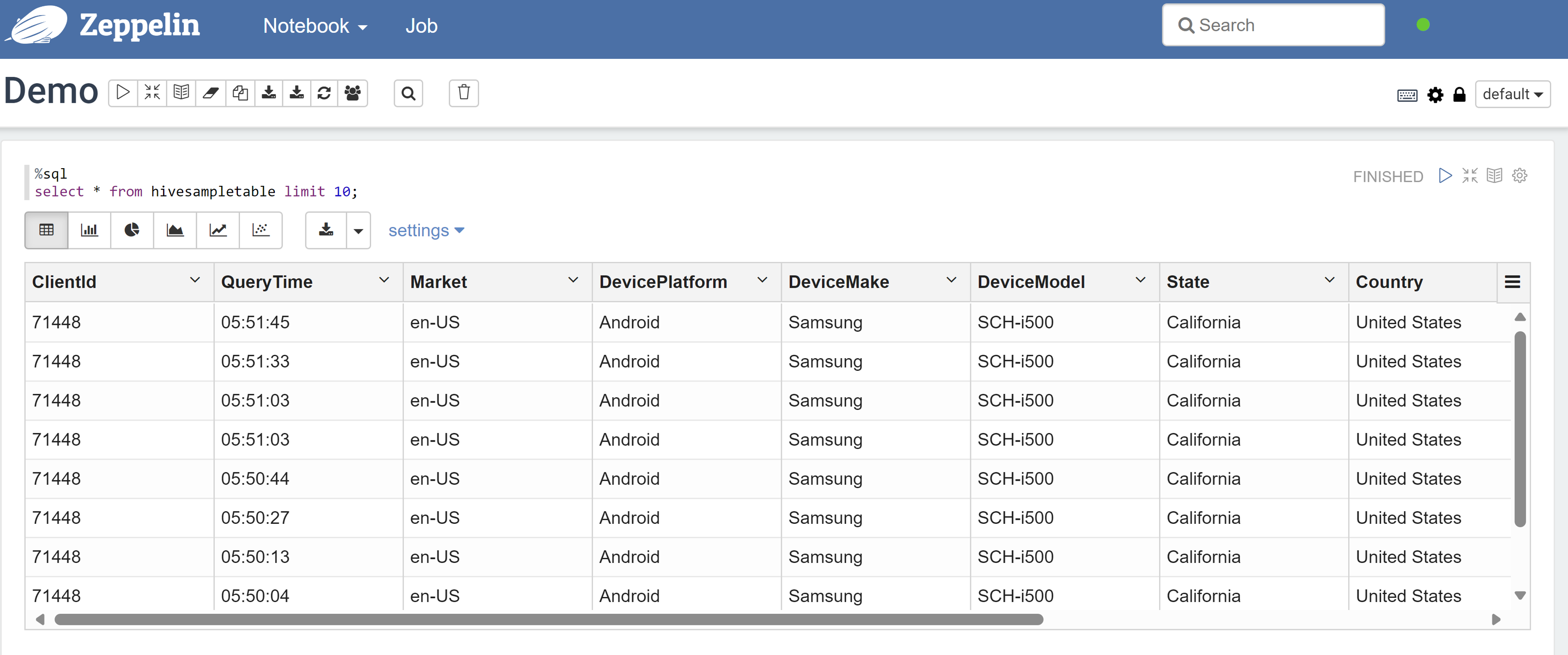
Zeppelin Notebook을 열고 다음 명령을 실행하여 정책을 확인합니다.
%sql select * from hivesampletable limit 10;정책이 적용되기 전의 결과는 다음과 같습니다.
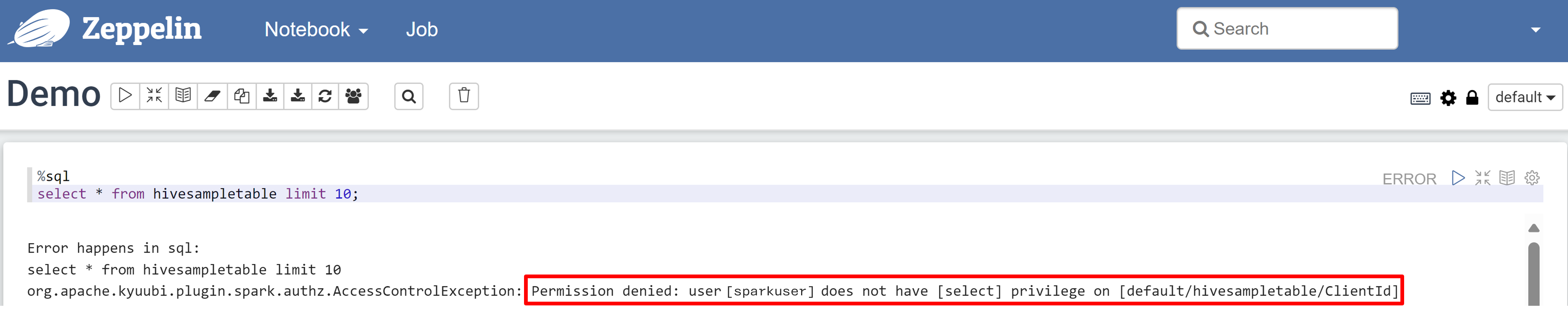
정책이 적용된 후의 결과는 다음과 같습니다.




Ranger 마스킹 정책 만들기
다음 예제에서는 열을 마스킹하는 정책을 만드는 방법을 보여줍니다.
마스킹 탭에서 새 정책 추가를 선택합니다.
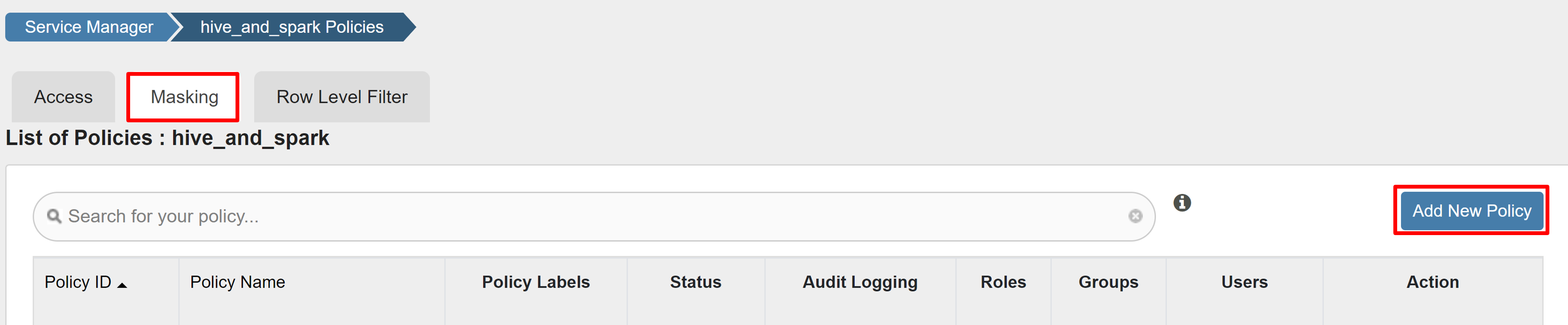
다음 값을 입력합니다.
속성 값 정책 이름 mask-hivesampletable Hive 데이터베이스 default Hive 테이블 hivesampletable Hive 열 devicemake 사용자 선택 sparkuser액세스 유형 선택 마스킹 옵션 선택 해시 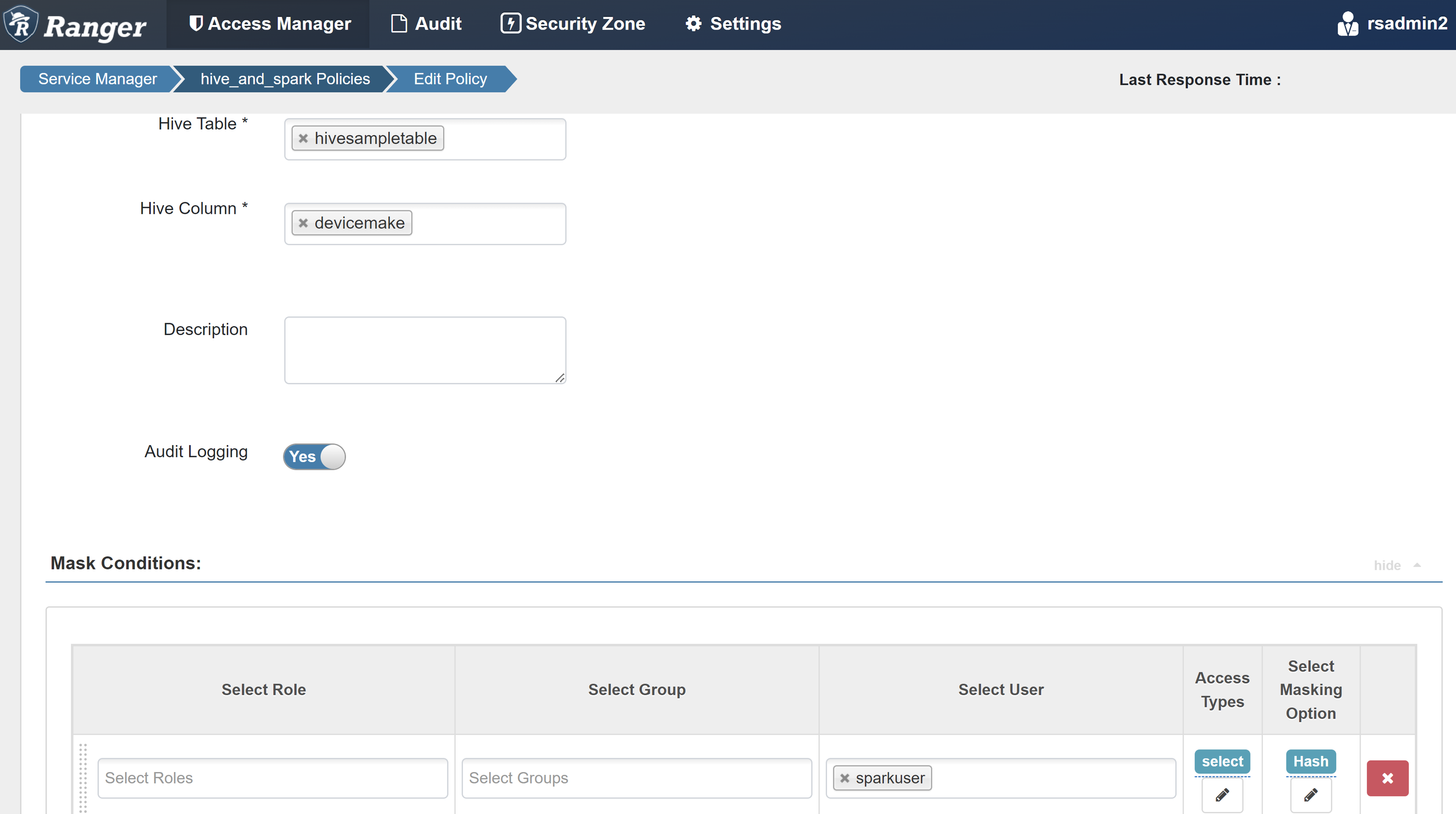
저장을 선택하여 정책을 저장합니다.
Zeppelin Notebook을 열고 다음 명령을 실행하여 정책을 확인합니다.
%sql select clientId, deviceMake from hivesampletable;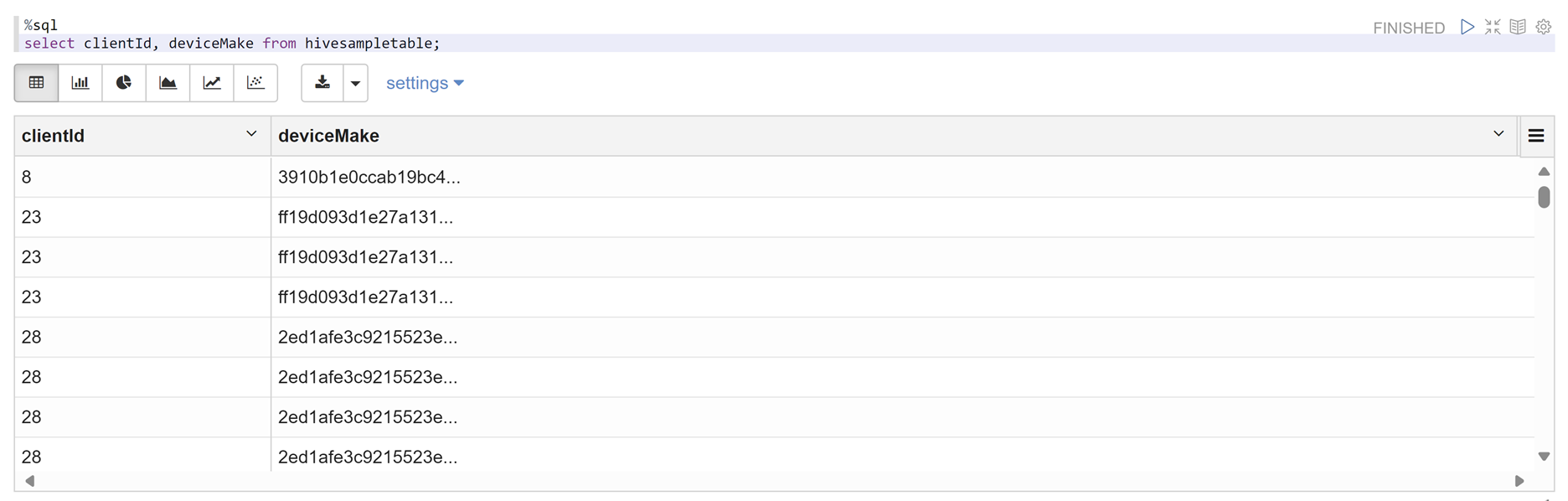



참고 항목
기본적으로 Hive 및 Spark SQL에 대한 정책은 Ranger에서 일반적입니다.
Spark SQL용 Apache Ranger 설정 지침 적용
다음 시나리오에서는 새 Ranger 데이터베이스를 사용하고 기존 Ranger 데이터베이스를 사용하여 HDInsight 5.1 Spark 클러스터를 만들기 위한 지침을 살펴봅니다.
시나리오 1: HDInsight 5.1 Spark 클러스터를 만드는 동안 새 Ranger 데이터베이스 사용
새 Ranger 데이터베이스를 사용하여 클러스터를 만들면 Hive 및 Spark에 대한 Ranger 정책을 포함하는 관련 Ranger 리포지토리가 Ranger 데이터베이스의 Hadoop SQL 서비스에 hive_and_spark 이름으로 만들어집니다.

정책을 편집하면 Hive와 Spark 모두에 적용됩니다.
다음 사항을 고려합니다.
Hive(예: DB1) 및 Spark(예: DB1) 카탈로그에 사용되는 이름이 같은 두 개의 메타스토어 데이터베이스가 있는 경우:
- Spark에서 Spark 카탈로그(
metastore.catalog.default=spark)를 사용하는 경우 정책은 Spark 카탈로그의 DB1 데이터베이스에 적용됩니다. - Spark에서 Hive 카탈로그(
metastore.catalog.default=hive)를 사용하는 경우 정책은 Hive 카탈로그의 DB1 데이터베이스에 적용됩니다.
Ranger의 관점에서 볼 때 Hive 및 Spark 카탈로그의 DB1을 구별할 수 있는 방법은 없습니다.
이러한 경우 다음 중 하나를 수행하는 것이 좋습니다.
- Hive 및 Spark 모두에 Hive 카탈로그를 사용합니다.
- 정책이 카탈로그 전체의 데이터베이스에 적용되지 않도록 Hive 및 Spark 카탈로그에 대해 서로 다른 데이터베이스, 테이블 및 열 이름을 유지 관리합니다.
- Spark에서 Spark 카탈로그(
Hive 및 Spark 모두에 Hive 카탈로그를 사용하는 경우 다음 예제를 고려하세요.
현재 xyz 사용자를 사용하여 Hive를 통해 table1이라는 테이블을 만듭니다. 소유자가 xyz 사용자인 table1.db HDFS(Hadoop Distributed File System) 파일을 만듭니다.
이제 사용자 abc 를 사용하여 Spark SQL 세션을 시작한다고 상상해 보십시오. 이 사용자 abc 세션에서 table1에 아무것도 쓰려고 하면 테이블 소유자가 xyz이므로 실패할 수밖에 없습니다.
이 경우 Hive 및 Spark SQL에서 동일한 사용자를 사용하여 테이블을 업데이트하는 것이 좋습니다. 해당 사용자에게는 업데이트 작업을 수행할 수 있는 충분한 권한이 있어야 합니다.
시나리오 2: HDInsight 5.1 Spark 클러스터를 만드는 동안 기존 Ranger 데이터베이스(기존 정책 포함) 사용
기존 Ranger 데이터베이스를 사용하여 HDInsight 5.1 클러스터를 만들면 이 데이터베이스에 새 Ranger 리포지토리가 hive_and_spark 형식의 새 클러스터 이름으로 다시 만들어집니다.

Hadoop SQL 서비스 내의 기존 Ranger 데이터베이스에 oldclustername_hive 이름 아래에 이미 Ranger 리포지토리에 정의된 정책이 있다고 가정해 보겠습니다. 새 HDInsight 5.1 Spark 클러스터에서 동일한 정책을 공유하려고 합니다. 이 목표를 달성하려면 다음 단계를 사용합니다.
참고 항목
Ambari 관리자 권한이 있는 사용자는 구성 업데이트를 수행할 수 있습니다.
새 HDInsight 5.1 클러스터에서 Ambari UI를 엽니다.
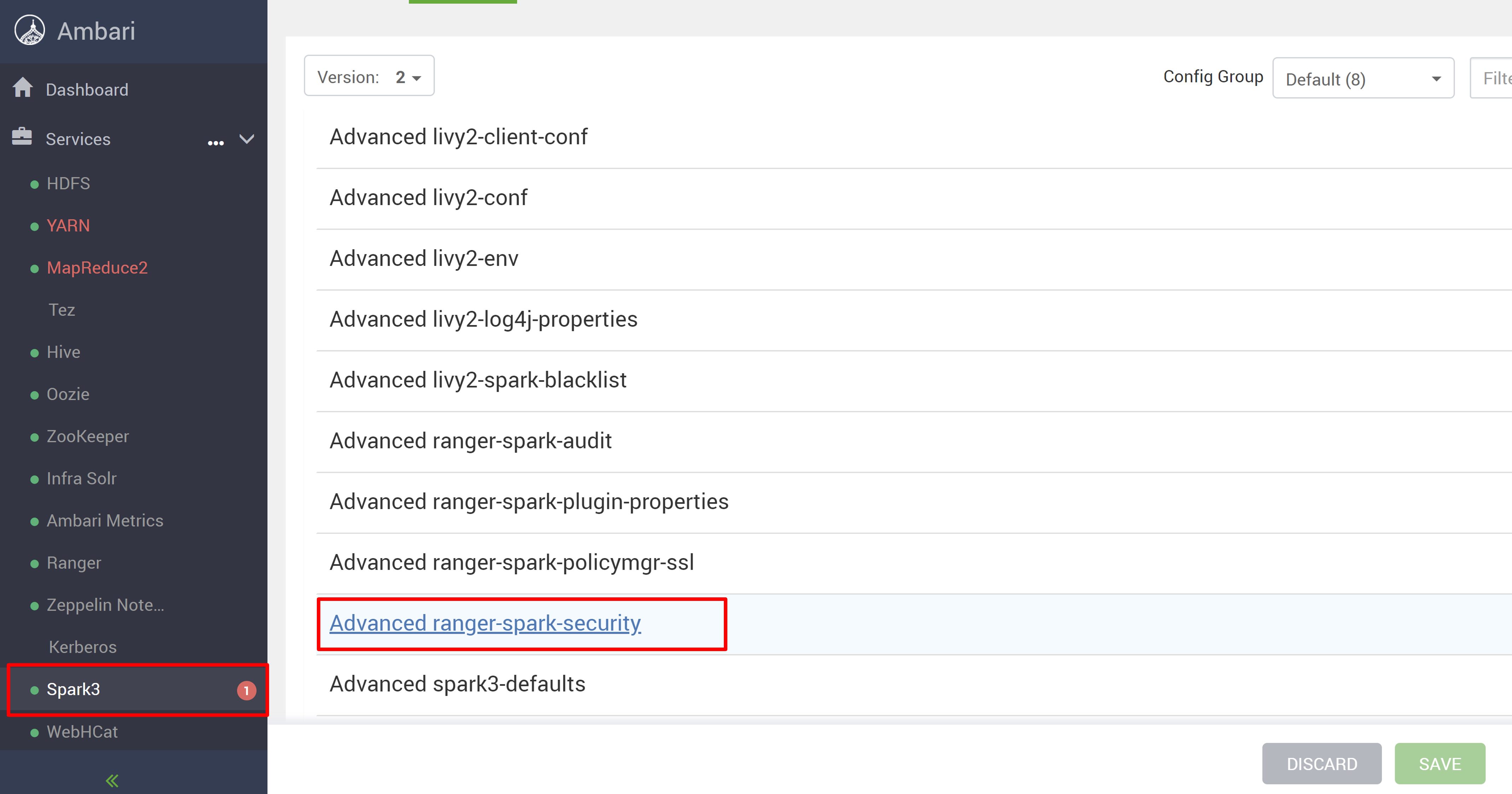
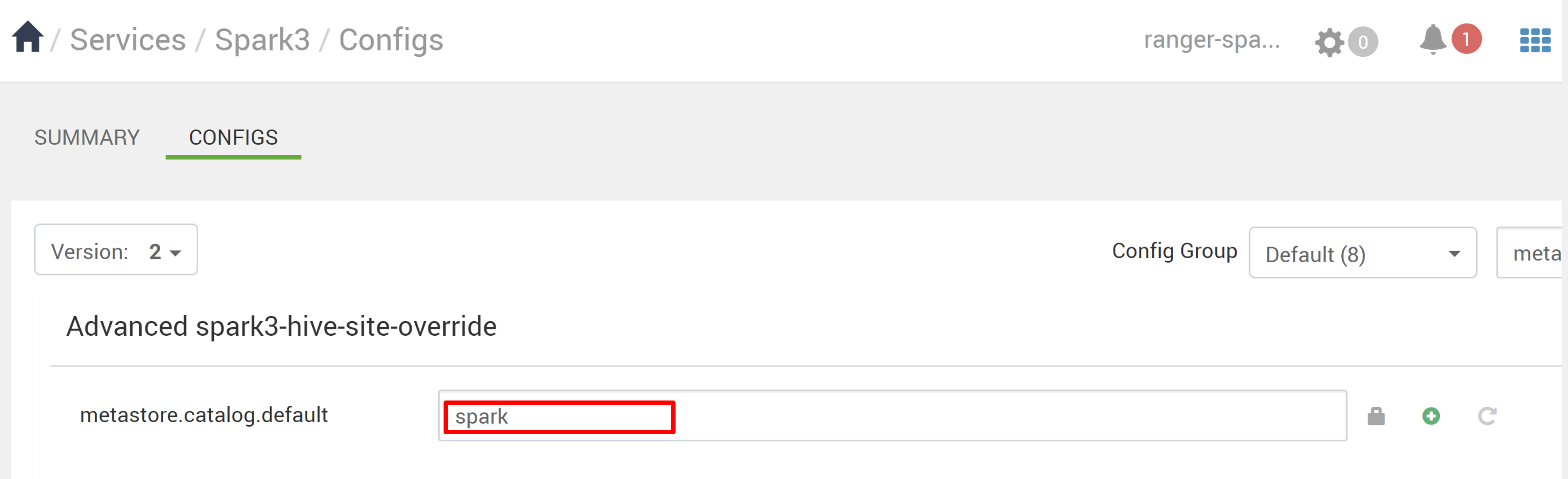
Spark3 서비스로 이동한 다음 Configs로 이동합니다.
Advanced ranger-spark-security 구성을 엽니다.
또는 SSH를 사용하여 /etc/spark3/conf에서 이 구성을 열 수도 있습니다.
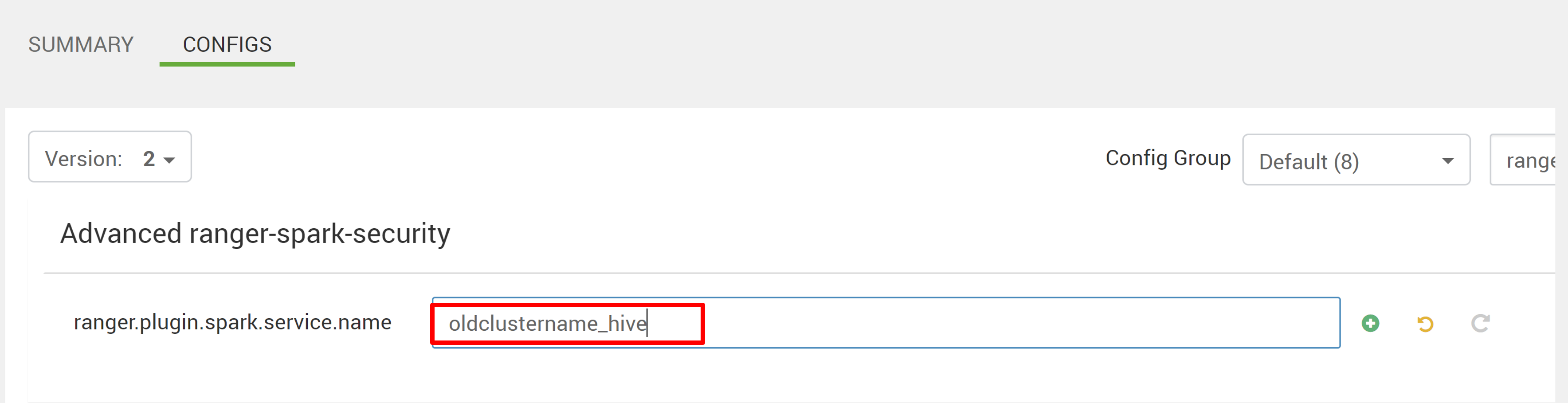
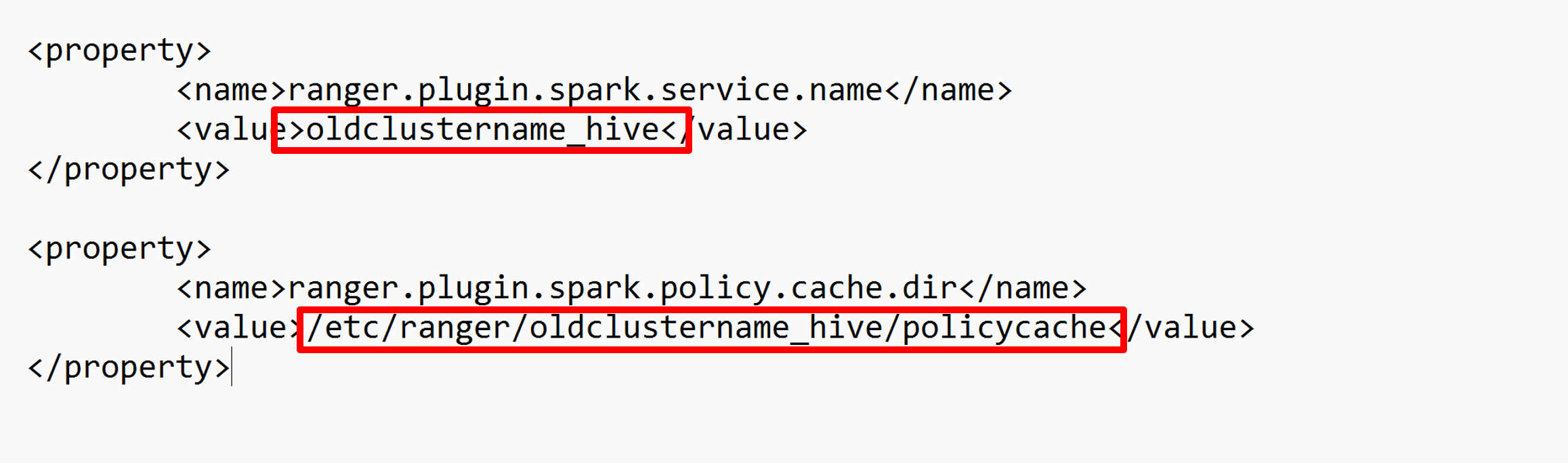
두 구성(ranger.plugin.spark.service.name 및 ranger.plugin.spark.policy.cache.dir)을 편집하여 이전 정책 리포지토리 oldclustername_hive 가리킨 다음 구성을 저장합니다.
Ambari:
XML 파일:
Ambari에서 Ranger 및 Spark 서비스를 다시 시작합니다.
Ranger 관리자 UI를 열고 HADOOP SQL 서비스에서 편집 단추를 클릭합니다.
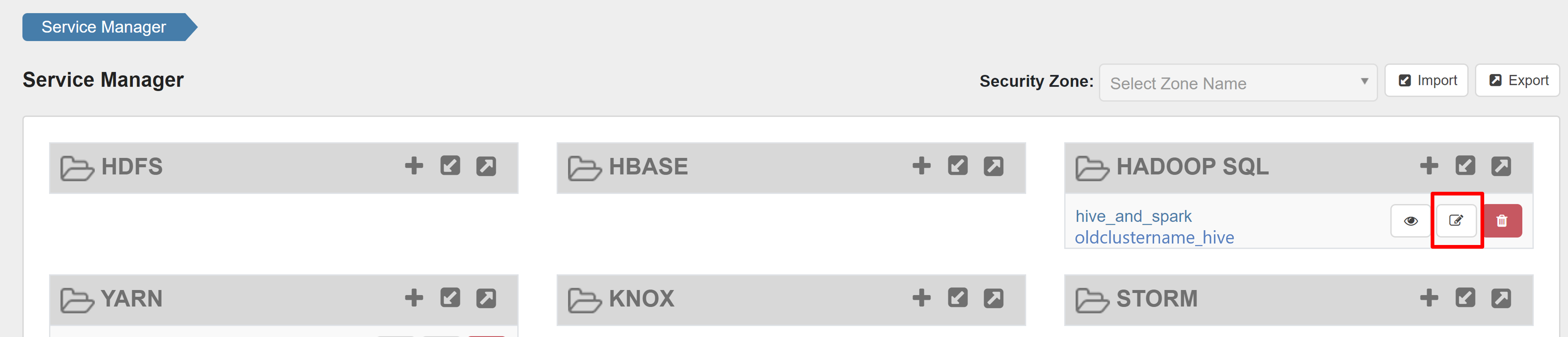
oldclustername_hive 서비스의 경우 policy.download.auth.users 및 tag.download.auth.users 목록에 rangersparklookup 사용자를 추가하고 저장을 클릭합니다.






정책은 Spark 카탈로그의 데이터베이스에 적용됩니다. Hive 카탈로그의 데이터베이스에 액세스하려는 경우:
Ambari에서 Spark3>구성으로 이동합니다.
metastore.catalog.default를 spark에서 hive로 변경합니다.

알려진 문제
- Ranger 관리자가 다운된 경우 Spark SQL과 Apache Ranger 통합이 작동하지 않습니다.
- Ranger 감사 로그에서 리소스 열을 마우스로 가리키면 실행한 전체 쿼리를 표시할 수 없습니다.