Apache Spark 구조적 스트리밍 개요
Apache Spark 구조적 스트리밍을 사용하면 데이터 스트림 처리를 위한 스케일링 가능하고 처리량이 높은 내결함성 애플리케이션을 구현할 수 있습니다. 구조적 스트리밍은 Spark SQL 엔진을 기반으로 하며, Spark SQL 데이터 프레임 및 데이터 세트의 구문을 개선하므로 일괄 처리 쿼리를 작성하는 것과 같은 방식으로 스트리밍 쿼리를 작성할 수 있습니다.
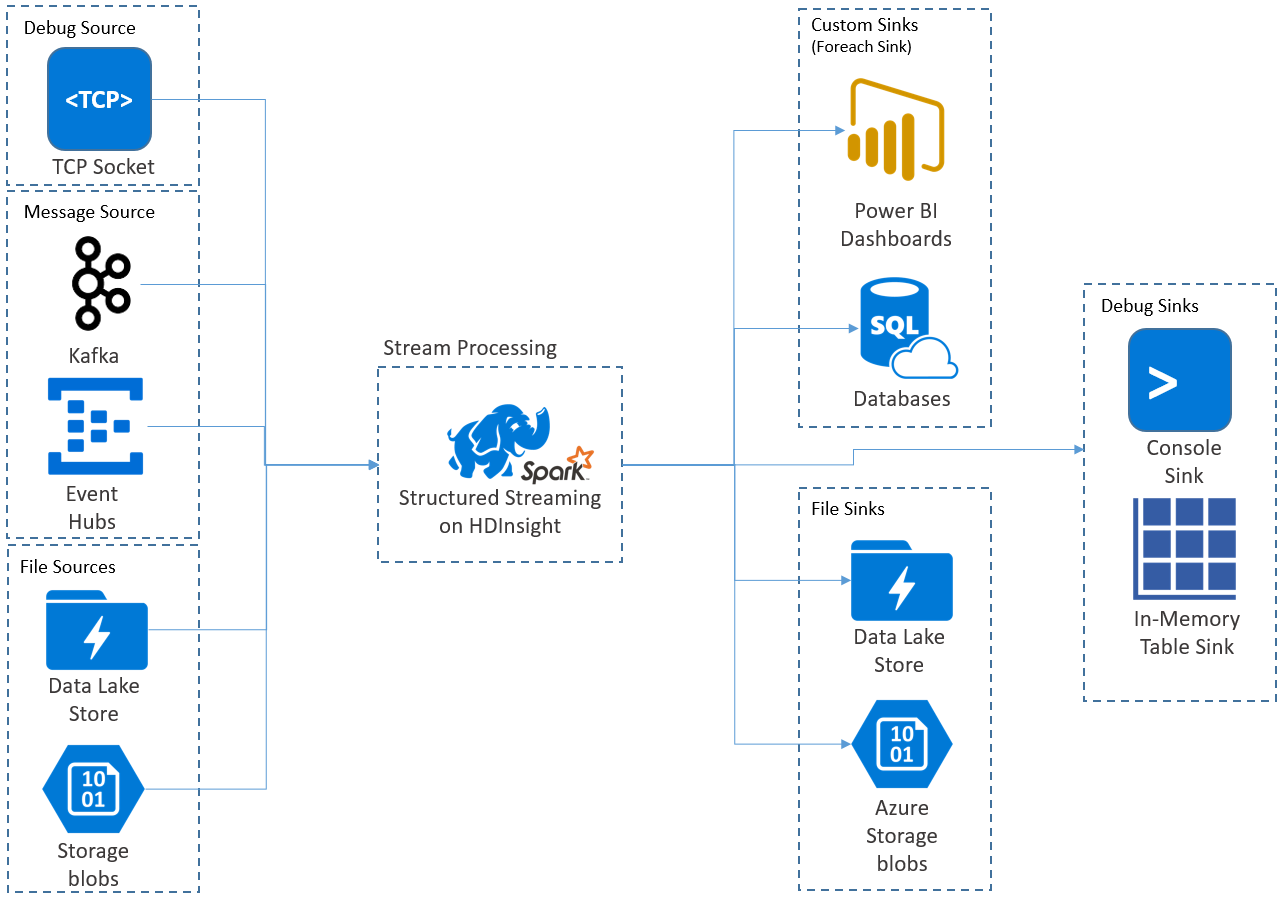
구조적 스트리밍 애플리케이션은 HDInsight Spark 클러스터에서 실행되며, Apache Kafka, 디버깅용 TCP 소켓, Azure Storage 또는 Azure Data Lake Storage의 스트리밍 데이터에 연결됩니다. 외부 스토리지 서비스를 사용하는 후자의 두 가지 옵션을 사용하면 스토리지에 추가된 새 파일을 감시하고 스트리밍된 것처럼 해당 내용을 처리할 수 있습니다.
구조적 스트리밍은 입력 데이터에 작업(예: 선택, 프로젝션, 집계, 창 작업 및 스트리밍 데이터 프레임과 참조 데이터 프레임의 조인)을 적용하는 장기 실행 쿼리를 만듭니다. 그런 다음, 사용자 지정 코드(예: SQL Database 또는 Power BI)를 사용하여 결과를 File Storage(Azure Storage Blob 또는 Data Lake Storage) 또는 데이터 저장소에 출력합니다. 또한 구조적 스트리밍은 로컬로 디버그하기 위해 콘솔에 출력을 제공하고, HDInsight에서 디버그하기 위해 생성된 데이터를 볼 수 있도록 메모리 내 테이블에 출력을 제공합니다.
참고 항목
Spark Structured Streaming은 Spark Streaming(DStreams)을 대체합니다. 향후에는 구조적 스트리밍에 향상된 기능과 유지 관리 기능을 제공하는 한편, DStreams는 유지 관리 모드로만 유지될 것입니다. 현재 구조적 스트리밍은 즉시 지원되는 원본 및 싱크에 대한 DStreams처럼 완벽한 기능이 아니므로 요구 사항을 평가하여 적절한 Spark 스트림 처리 옵션을 선택해야 합니다.
테이블로서의 스트림
Spark 구조적 스트리밍은 데이터 스트림을 깊이 제한이 없는 테이블로 표현합니다. 즉, 테이블은 새 데이터가 도착함에 따라 계속 커집니다. 이 입력 테이블은 장기 실행 쿼리를 통해 지속적으로 처리되며, 결과는 출력 테이블로 보내집니다.

구조적 스트리밍에서 데이터는 시스템에 들어오는 즉시 입력 테이블로 수집됩니다. 이 입력 테이블에 대해 작업을 수행하는 쿼리를 작성합니다(데이터 프레임 및 데이터 세트 API 사용). 쿼리 결과는 결과 테이블이라는 또 다른 테이블을 생성합니다. 결과 테이블에는 쿼리의 결과가 포함되며, 이 테이블에서 관계형 데이터베이스와 같은 외부 데이터 저장소에 대한 데이터를 가져옵니다. 데이터가 입력 테이블에서 처리되는 타이밍은 트리거 간격으로 제어됩니다. 트리거 간격은 기본적으로 0이며, 이 경우 데이터가 들어오는 즉시 구조적 스트리밍에서 처리하려고 시도합니다. 실제로 구조적 스트리밍은 이전 쿼리의 실행을 처리하는 즉시 새로 받은 데이터에 대해 또 다른 처리를 시작합니다. 트리거가 일정한 간격으로 실행되도록 구성하여 스트리밍 데이터를 시간 기반 일괄 처리로 처리할 수 있습니다.
결과 테이블의 데이터는 쿼리가 마지막으로 처리된 이후의 새 데이터만 포함하거나(추가 모드), 새 데이터가 생길 때마다 테이블을 새로 고쳐 스트리밍 쿼리가 시작된 이후의 모든 출력 데이터가 테이블에 포함되도록 할 수 있습니다(전체 모드).
추가 모드
추가 모드에서는 마지막 쿼리가 실행된 이후 결과 테이블에 추가된 행만 결과 테이블에 나타나고 외부 스토리지에 기록됩니다. 예를 들어 가장 간단한 쿼리는 단순히 입력 테이블의 모든 데이터를 변경되지 않은 상태로 결과 테이블에 복사합니다. 트리거 간격이 경과할 때마다 새 데이터가 처리되고 해당 새 데이터를 나타내는 행이 결과 테이블에 표시됩니다.
자동 온도 조절기와 같은 온도 센서에서 원격 분석을 처리하는 시나리오를 살펴보겠습니다. 첫 번째 트리거에서 온도 판독값이 95도인 디바이스 1에 대해 00:01 시간에 하나의 이벤트를 처리했다고 가정합니다. 쿼리의 첫 번째 트리거에서는 00:01이 있는 행만 결과 테이블에 표시됩니다. 00:02에 다른 이벤트가 발생하는 경우 유일한 새 행은 00:02이 있는 행이므로 결과 테이블에는 이 하나의 행만 포함됩니다.
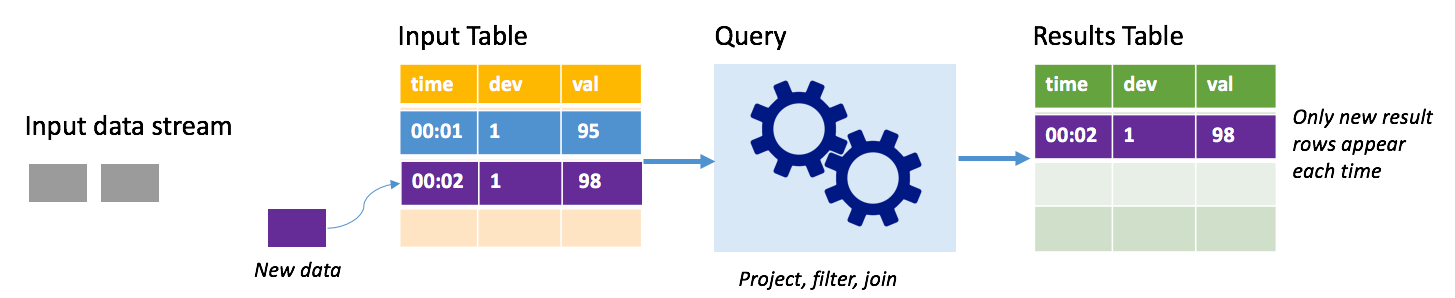
추가 모드를 사용하는 경우 쿼리에서 프로젝션(관심 있는 열 선택), 필터링(특정 조건과 일치하는 행만 선택) 또는 조인(정적 조회 테이블의 데이터로 데이터 보강)을 적용합니다. 추가 모드를 사용하면 관련된 새 데이터 요소만 외부 스토리지로 쉽게 푸시할 수 있습니다.
전체 모드
이번에는 전체 모드를 사용하여 동일한 시나리오를 살펴보겠습니다. 전체 모드에서는 모든 트리거에서 전체 출력 테이블을 새로 고쳐 가장 최근의 트리거 실행뿐만 아니라 모든 실행의 데이터가 테이블에 포함됩니다. 전체 모드를 사용하여 변경되지 않은 상태의 데이터를 입력 테이블에서 결과 테이블에 복사할 수 있습니다. 트리거된 모든 실행에서 새 결과 행이 모든 이전 행과 함께 표시됩니다. 출력 결과 테이블은 쿼리가 시작된 이후 수집된 모든 데이터를 저장하게 되며, 결국에는 메모리가 부족하게 됩니다. 전체 모드는 들어오는 데이터를 어떤 방식으로든 요약하는 집계 쿼리에 사용하기 위한 것이므로 트리거가 있을 때마다 결과 테이블이 새 요약으로 업데이트됩니다.
지금까지 5초 분량의 데이터가 이미 처리되었으며 여섯 번째 초의 데이터를 처리한다고 가정합니다. 입력 테이블에는 00:01 및 00:03에 대한 이벤트가 있습니다. 이 예제 쿼리의 목표는 5초마다 디바이스의 평균 온도를 제공하는 것입니다. 이 쿼리를 구현하면 각각의 5초 시간 범위에 속하는 모든 값을 사용하여 온도의 평균을 계산하고 해당 간격에 대한 평균 온도 행을 생성하는 집계가 적용됩니다. 첫 번째 5초 시간 범위의 끝에 두 개의 튜플, 즉 (00:01, 1, 95) 및 (00:03, 1, 98)이 있습니다. 따라서 00:00~00:05 시간 범위에 대한 집계는 평균 온도가 96.5도인 튜플을 생성합니다. 다음 5초 시간 범위에는 00:06 시간의 데이터 포인트 하나만 있으므로 그 결과 평균 온도는 98도입니다. 00:10 시간에서 전체 모드를 사용하는 경우 쿼리에서 새 행뿐만 아니라 집계된 모든 행을 출력하기 때문에 결과 테이블에는 00:00-00:05 및 00:05-00:10의 두 시간 범위에 대한 행이 있습니다. 따라서 새 시간 범위가 추가됨에 따라 결과 테이블은 계속 커집니다.
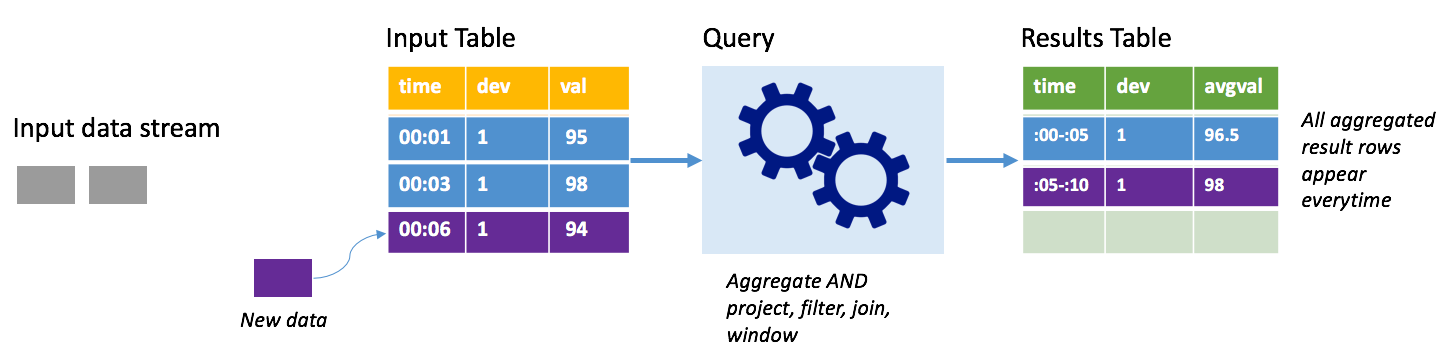
전체 모드를 사용하는 모든 쿼리에서 테이블이 무제한으로 커지도록 하지는 않습니다. 앞의 예에서는 시간 범위별로 온도 평균을 계산하지 않고 디바이스 ID별로 온도 평균을 계산한 것입니다. 결과 테이블에는 해당 디바이스로부터 받은 모든 데이터 포인트에 대한 평균 온도가 포함된 고정된 수의 행(디바이스당 하나씩)이 있습니다. 새 온도를 받는 대로 테이블의 평균이 항상 최신이 되도록 결과 테이블이 업데이트됩니다.
Spark 구조적 스트리밍 애플리케이션의 구성 요소
간단한 예제 쿼리에서는 장기 시간 범위를 기준으로 온도 판독값을 요약할 수 있습니다. 이 경우 데이터는 Azure Storage의 JSON 파일에 저장됩니다(HDInsight 클러스터의 기본 스토리지로 연결됨).
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
이러한 JSON 파일은 HDInsight 클러스터 컨테이너 아래의 temps 하위 폴더에 저장됩니다.
입력 원본 정의
먼저 데이터 원본 및 해당 원본에 필요한 모든 설정을 설명하는 데이터 프레임을 구성합니다. 다음 예제에서는 Azure Storage의 JSON 파일에서 가져오고 읽기 시간에 스키마를 적용합니다.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
쿼리 적용
다음으로, 스트리밍 데이터 프레임에 대해 원하는 작업이 포함된 쿼리를 적용합니다. 이 경우 집계는 모든 행을 1시간 범위로 그룹화한 다음, 해당 1시간 범위에서 최소, 평균 및 최대 온도를 계산합니다.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
출력 싱크 정의
다음으로, 각 트리거 간격 내에서 결과 테이블에 추가되는 행의 대상을 정의합니다. 다음 예제에서는 나중에 SparkSQL을 사용하여 쿼리할 수 있는 temps 메모리 내 테이블에 모든 행을 출력합니다. 전체 출력 모드를 사용하면 매번 모든 시간 범위에 대한 모든 행이 출력됩니다.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
쿼리 시작
스트리밍 쿼리를 시작하고 종료 신호를 받을 때까지 실행합니다.
val query = streamingOutDF.start()
결과 보기
쿼리가 실행되는 동안 동일한 SparkSession에서 쿼리 결과가 저장되는 temps 테이블에 대해 SparkSQL 쿼리를 실행할 수 있습니다.
select * from temps
이 쿼리는 다음과 비슷한 결과를 생성합니다.
| window | 최소(온도) | 평균(온도) | 최대(온도) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
지원되는 입력 데이터 원본, 작업 및 출력 싱크와 함께 Spark 구조적 스트림 API에 대한 자세한 내용은 Apache Spark 구조적 스트리밍 프로그래밍 가이드를 참조하세요.
검사점 및 미리 쓰기 로그
복원력 및 내결함성을 제공하기 위해 구조적 스트리밍은 검사점을 사용하여 노드 오류가 있는 경우에도 중단 없이 스트림 처리를 계속할 수 있도록 합니다. HDInsight에서 Spark는 영구 스토리지(Azure Storage 또는 Data Lake Storage 중 하나)에 대한 검사점을 만듭니다. 이러한 검사점은 스트리밍 쿼리에 대한 진행 정보를 저장합니다. 또한 구조적 스트리밍은 WAL(미리 쓰기 로그)을 사용합니다. WAL은 받았지만 아직 쿼리에서 처리하지 않은 수집된 데이터를 캡처합니다. 오류가 발생하고 WAL에서 처리가 다시 시작되면 원본에서 받은 모든 이벤트가 손실되지 않습니다.
Spark 스트리밍 애플리케이션 배포
일반적으로 Spark Streaming 애플리케이션을 JAR 파일에 로컬로 빌드한 다음, JAR 파일을 HDInsight 클러스터에 연결된 기본 스토리지로 복사하여 HDInsight의 Spark에 배포합니다. POST 작업을 사용하여 클러스터에서 사용할 수 있는 Apache Livy REST API를 통해 애플리케이션을 시작할 수 있습니다. POST의 본문에는 JAR에 대한 경로, main 메서드에서 스트리밍 애플리케이션을 정의하고 실행하는 클래스의 이름, 그리고 필요에 따라 작업의 리소스 요구 사항(예: 실행기, 메모리 및 코어의 수)과 애플리케이션 코드에 필요한 모든 구성 설정을 제공하는 JSON 문서가 포함되어 있습니다.
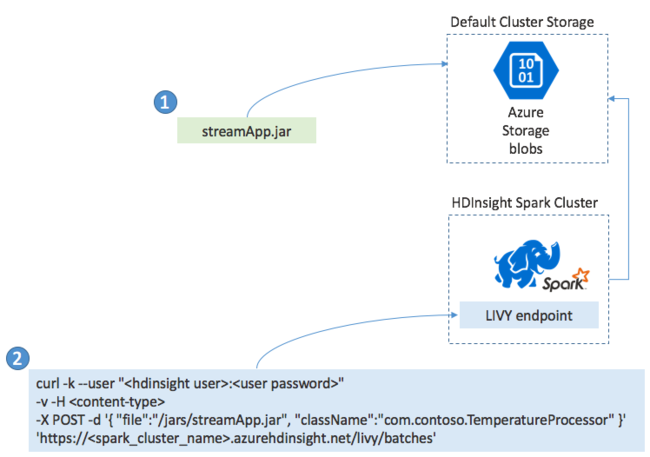
또한 LIVY 엔드포인트에 대한 GET 요청으로 모든 애플리케이션의 상태를 확인할 수 있습니다. 마지막으로 LIVY 엔드포인트에 대한 DELETE 요청을 실행하여 실행 중인 애플리케이션을 종료할 수 있습니다. LIVY API에 대한 자세한 내용은 Apache LIVY를 사용하는 원격 작업을 참조하세요.