Apache Hadoop과 함께 Apache Oozie를 사용하여 Linux 기반 Azure HDInsight에서 워크플로 정의 및 실행
Azure HDInsight에서 Apache Hadoop과 함께 Apache Oozie를 사용하는 방법을 알아봅니다. Oozie는 Hadoop 작업을 관리하는 워크플로 및 코디네이션 시스템입니다. Oozie는 Hadoop 스택과 통합되며 다음 작업을 지원합니다.
- Apache Hadoop MapReduce
- Apache Pig
- Apache Hive
- Apache Sqoop
Oozie를 사용하여 Java 프로그램이나 셸 스크립트와 같은 시스템에 특정한 작업을 예약할 수도 있습니다.
참고 항목
HDInsight를 사용하여 워크플로를 정의하는 또 다른 옵션은 Azure Data Factory를 사용하는 것입니다. Data Factory에 대해 자세히 알아보려면 Data Factory에서 Apache Pig 및 Apache Hive 사용을 참조하세요. Enterprise Security Package가 포함된 클러스터에서 Oozie를 사용하려면 Enterprise Security Package가 포함된 HDInsight Hadoop 클러스터에서 Apache Oozie 실행을 참조하세요.
필수 조건
HDInsight의 Hadoop 클러스터. Linux에서 HDInsight 시작을 참조하세요.
SSH 클라이언트 SSH를 사용해 HDInsight(Apache Hadoop)에 연결을 참조하세요.
Azure SQL Database. Azure Portal을 사용하여 Azure SQL Database에서 단일 데이터베이스 만들기를 참조하세요. 이 문서에서는 oozietest라는 데이터베이스를 사용합니다.
클러스터 기본 스토리지에 대한 URI 체계입니다.
wasb://은 Azure Storage,abfs://는 Azure Data Lake Storage Gen2,adl://은 Azure Data Lake Storage Gen1에 쓰입니다. Azure Storage에 대해 보안 전송이 활성화된 경우 URI는wasbs://입니다. 보안 전송도 참조하세요.
예시 워크플로
이 문서에서 사용되는 워크플로에는 두 가지 작업이 있습니다. 동작은 Hive, Sqoop, MapReduce 또는 기타 프로세스 실행과 같은 작업에 대한 정의입니다.
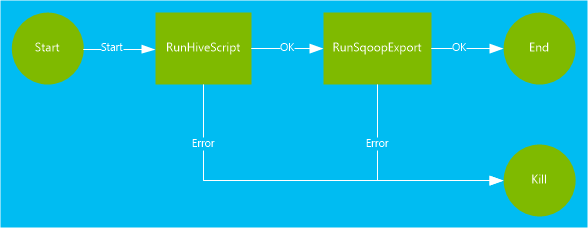
Hive 작업은 HiveQL 스크립트를 실행하여 HDInsight에
hivesampletable포함된 레코드에서 레코드를 추출합니다. 데이터의 각 행은 특정 모바일 디바이스에서의 방문을 설명합니다. 레코드 형식은 다음 텍스트와 유사하게 표시됩니다.8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1이 문서에서 사용된 Hive 스크립트는 각 플랫폼(예: Android 또는 iPhone)에 대한 총 방문 횟수를 계산하여 새 Hive 테이블에 저장합니다.
Hive에 대한 자세한 내용은 [HDInsight에서 Apache Hive 사용][hdinsight-use-hive]를 참조하세요.
Sqoop 동작은 새 Hive 테이블의 내용을 Azure SQL Database에서 만든 테이블로 내보냅니다. Sqoop에 대한 자세한 내용은 HDInsight에서 Apache Sqoop 사용을 참조하세요.
참고 항목
HDInsight 클러스터에서 지원되는 Oozie 버전에 대해서는 HDInsight에서 제공하는 Hadoop 클러스터 버전의 새 소식을 참조하세요.
작업 디렉터리 만들기
Oozie에는 작업을 같은 디렉터리에 저장하는 데 사용되는 리소스가 필요합니다. 이 예제에서는 wasbs:///tutorials/useoozie를 사용합니다. 이 디렉터리를 만들려면 다음 단계를 완료합니다.
아래 코드를 편집하여
sshuser를 클러스터의 SSH 사용자 이름으로 바꾸고CLUSTERNAME를 클러스터의 이름으로 바꿉니다. 그런 다음 SSH를 사용하여 HDInsight 클러스터에 연결하는 코드를 입력합니다.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net디렉터리를 만들려면 다음 명령을 사용합니다.
hdfs dfs -mkdir -p /tutorials/useoozie/data참고 항목
-p매개 변수는 경로의 모든 디렉터리가 만들어지도록 합니다.data디렉터리는useooziewf.hql스크립트에서 사용하는 데이터를 저장하는 데 사용됩니다.아래 코드를 편집하여
sshuser를 SSH 사용자 이름으로 바꿉니다. Oozie가 사용자 계정을 가장할 수 있도록 다음 명령을 사용합니다.sudo adduser sshuser users참고 항목
사용자가 이미
users그룹의 구성원이라는 오류는 무시해도 됩니다.
데이터베이스 드라이버 추가
이 워크플로에서는 Sqoop를 사용하여 SQL Database로 데이터를 내보냅니다. 그러므로 SQL Database와 상호 작용하는 데 사용되는 JDBC 드라이버의 복사본을 제공해야 합니다. JDBC 드라이버를 작업 디렉터리로 복사하려면 SSH 세션에서 다음 명령을 사용합니다.
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
Important
/usr/share/java/에 있는 실제 JDBC 드라이버를 확인합니다.
워크플로에서 MapReduce 애플리케이션이 포함된 jar 등의 다른 리소스를 사용하는 경우 이러한 리소스도 추가해야 합니다.
Hive 쿼리 정의
다음 단계를 사용하여 쿼리를 정의하는 Hive 쿼리 언어(HiveQL) 스크립트를 만듭니다. 이 문서의 뒷부분에 나오는 Oozie 워크플로에서 쿼리를 사용합니다.
SSH 연결에서 다음 명령을 사용하여
useooziewf.hql이라는 파일을 만듭니다.nano useooziewf.hqlGNU nano 편집기가 열리면 파일 내용으로 다음 쿼리를 사용합니다.
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;스크립트에서 사용되는 두 가지 변수는 다음과 같습니다.
${hiveTableName}: 만들려는 테이블의 이름을 포함합니다.${hiveDataFolder}: 테이블의 데이터 파일을 저장할 위치를 포함합니다.워크플로 정의 파일(이 문서의 경우 workflow.xml)은 런타임 시 이러한 값을 이 HiveQL 스크립트에 전달합니다.
파일을 저장하려면 Ctrl + X를 선택하고 Y를 입력한 다음 입력을 선택합니다.
다음 명령을 사용하여
useooziewf.hql를wasbs:///tutorials/useoozie/useooziewf.hql로 복사합니다.hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hql이 명령은 클러스터용 HDFS 호환 스토리지에
useooziewf.hql파일을 저장합니다.
워크플로 정의
Oozie 워크플로 정의는 XML 프로세스 정의 언어인 hPDL(Hadoop 프로세스 정의 언어)로 작성됩니다. 다음 단계를 사용하여 워크플로를 정의합니다.
다음 문을 사용하여 새 파일을 만들고 편집합니다.
nano workflow.xmlnano 편집기가 열리면 파일 내용으로 다음 XML을 입력합니다.
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>워크플로에 정의된 두 가지 동작은 다음과 같습니다.
RunHiveScript: 이 동작은 시작 동작이며useooziewf.hqlHive 스크립트를 실행합니다.RunSqoopExport: 이 작업은 Sqoop을 사용하여 Hive 스크립트에서 만든 데이터를 SQL 데이터베이스로 내보냅니다. 이 동작은RunHiveScript동작이 성공한 경우에만 실행됩니다.워크플로에
${jobTracker}등의 여러 항목이 있습니다. 이러한 항목을 작업 정의에서 사용하는 값으로 바꿉니다. 이 문서의 뒷부분에서 작업 정의를 만들 예정입니다.Sqoop 섹션의
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>항목도 있습니다. 이 항목은 이 동작을 실행할 때 이 보관 파일을 Sqoop에 사용할 수 있게 설정하도록 Oozie에 지시합니다.
파일을 저장하려면 Ctrl + X를 선택하고 Y를 입력한 다음 입력을 선택합니다.
다음 명령을 사용하여
workflow.xml파일을/tutorials/useoozie/workflow.xml에 복사합니다.hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
테이블 만들기
참고 항목
여러 가지 방법으로 SQL Database에 연결하여 테이블을 생성할 수 있습니다. 다음 단계는 HDInsight 클러스터의 FreeTDS를 사용합니다.
다음 명령을 사용하여 HDInsight 클러스터에 FreeTDS를 설치합니다.
sudo apt-get --assume-yes install freetds-dev freetds-bin아래 코드를 편집하여
<serverName>을 논리 SQL Server 이름으로 바꾸고,<sqlLogin>을 서버 로그인으로 바꿉니다. 명령을 입력하여 필수 구성 요소 SQL 데이터베이스에 연결합니다. 프롬프트에서 암호를 입력합니다.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietest다음 텍스트와 비슷한 출력이 제공됩니다.
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>1>프롬프트에 다음 행을 입력합니다.CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GOGO문을 입력하면 이전 문이 평가됩니다. 이러한 명령문은 워크플로에서 사용되는mobiledata라는 테이블을 만듭니다.테이블이 생성되었는지 확인하려면 다음 명령을 사용합니다.
SELECT * FROM information_schema.tables GO다음 텍스트와 같은 출력이 표시됩니다.
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLEexit을1>프롬프트에 입력하여 tsql 유틸리티를 종료합니다.
작업 정의 만들기
작업 정의는 workflow.xml을 찾을 수 있는 위치를 설명합니다. 또한 워크플로에서 사용되는 기타 파일(예: useooziewf.hql)을 찾을 수 있는 위치를 설명합니다. 또한 워크플로 내에서 사용되는 속성과 관련 파일에 대한 값을 정의합니다.
기본 스토리지의 전체 주소를 가져오려면 다음 명령을 사용합니다. 이 주소는 다음 단계에서 만드는 구성 파일에서 사용됩니다.
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xml이 명령은 다음 XML과 유사한 정보를 반환합니다.
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>참고 항목
HDInsight 클러스터에서 Azure Storage를 기본 스토리지로 사용하면
<value>요소의 내용은wasbs://로 시작합니다. Azure Data Lake Storage Gen1을 대신 사용하는 경우adl://로 시작합니다. Azure Data Lake Storage Gen2를 사용하는 경우abfs://로 시작합니다.다음 단계에서 사용되므로
<value>요소의 내용을 저장합니다.아래의 xml을 다음과 같이 편집합니다.
자리 표시자 값 바꾼 값 wasbs://mycontainer@mystorageaccount.blob.core.windows.net 1단계에서 받은 값입니다. 관리자 관리자가 아닌 경우 HDInsight 클러스터의 로그인 이름입니다. serverName Azure SQL Database 서버 이름. sqlLogin Azure SQL Database 서버 로그인. sqlPassword Azure SQL Database 서버 로그인 암호. <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>이 파일의 정보는 대부분 workflow.xml 또는 ooziewf.hql 파일에서 사용되는 값(예:
${nameNode})을 채우는 데 사용됩니다.wasbs경로인 경우 전체 경로를 사용해야 합니다. 단순하게wasbs:///로 줄이지 마세요.oozie.wf.application.path항목은 workflow.xml 파일을 찾을 위치를 정의합니다. 이 파일에는 이 작업에서 실행된 워크플로가 포함되어 있습니다.Oozie 작업 정의 구성을 만들려면 다음 명령을 사용합니다.
nano job.xmlnano 편집기가 열리면 파일 콘텐츠로 다음 편집된 XML을 붙여넣습니다.
파일을 저장하려면 Ctrl + X를 선택하고 Y를 입력한 다음 입력을 선택합니다.
작업 제출 및 관리
다음 단계에서는 Oozie 명령을 사용하여 클러스터에서 Oozie 워크플로를 제출 및 관리합니다. Oozie 명령은 Oozie REST API를 통해 제공되는 친숙한 인터페이스입니다.
Important
Oozie 명령을 사용할 때는 HDInsight 헤드 노드에 대한 FQDN을 사용해야 합니다. 이 FQDN은 클러스터에서만 액세스할 수 있으며, 클러스터가 Azure Virtual Network에 있는 경우에는 같은 네트워크에 있는 다른 컴퓨터에서 액세스할 수 있습니다.
Oozie 서비스의 URL을 가져오려면 다음 명령을 사용합니다.
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xml이 명령은 다음 XML과 유사한 정보를 반환합니다.
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie부분은 Oozie 명령에서 사용할 URL입니다.코드를 편집하여 이전에 받은 URL로 바꿉니다. URL에 대한 환경 변수를 만들려면 다음을 사용합니다. 모든 명령에 이렇게 입력할 필요는 없습니다.
export OOZIE_URL=http://HOSTNAMEt:11000/oozie작업을 제출하려면 다음 코드를 사용합니다.
oozie job -config job.xml -submit이 명령은
job.xml에서 작업 정보를 로드하고 Oozie로 전송하지만, 실행하지는 않습니다.명령이 완료되면 작업의 ID(예:
0000005-150622124850154-oozie-oozi-W)가 반환됩니다. 이 ID는 작업을 관리하는 데 사용됩니다.아래 코드를 편집하여
<JOBID>을 이전 단계에서 반환된 ID로 바꿉니다. 작업 상태를 확인하려면 다음 명령을 사용합니다.oozie job -info <JOBID>이 명령은 다음 텍스트와 유사한 정보를 반환합니다.
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------이 작업의 상태는
PREP입니다. 이 상태는 작업이 만들어졌지만 시작되지 않았음을 나타냅니다.아래 코드를 편집하여
<JOBID>을 이전에 반환된 ID로 바꿉니다. 작업을 시작하려면 다음 명령을 사용합니다.oozie job -start <JOBID>이 명령 후에 상태를 확인하면 실행 중 상태가 표시되고 작업 내 동작에 대한 정보를 반환합니다. 작업을 완료하는 데 몇 분 정도 걸립니다.
아래 코드를 편집하여
<serverName>를 서버 이름으로 바꾸고,<sqlLogin>를 서버 로그인으로 바꿉니다. 작업이 성공적으로 완료되면 다음 명령을 사용하여 데이터가 생성되고 SQL 데이터베이스 테이블로 내보내졌음을 확인할 수 있습니다. 프롬프트에서 암호를 입력합니다.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietest1>프롬프트에 다음 쿼리를 입력합니다.SELECT * FROM mobiledata GO반환되는 정보는 다음 텍스트와 유사합니다.
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Oozie 명령에 대한 자세한 내용은 Apache Oozie 명령줄 도구를 참조하세요.
Oozie REST API
Oozie REST API를 사용하면 Oozie와 함께 작동하는 사용자 고유의 도구를 빌드할 수 있습니다. Oozie REST API 사용에 대한 다음 HDInsight 관련 정보는 다음과 같습니다.
URI:
https://CLUSTERNAME.azurehdinsight.net/oozie에서 클러스터 외부의 REST API에 액세스할 수 있습니다.인증: 인증을 받으려면 API와 클러스터 HTTP 계정(admin) 및 암호를 사용합니다. 예시:
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Oozie REST API 사용 방법에 대한 자세한 내용은 Apache Oozie 웹 서비스 API를 참조하세요.
Oozie web UI
Oozie 웹 UI는 클러스터의 Oozie 작업 상태에 대한 웹 기반 보기를 제공합니다. 이 웹 UI를 사용하여 다음 정보를 볼 수 있습니다.
- 작업 상태
- 작업 정의
- 구성
- 작업의 동작 그래프
- 작업 로그
또한 작업 내의 동작에 대한 세부 정보를 볼 수 있습니다.
Oozie 웹 UI에 액세스하려면 다음 단계를 완료하세요.
HDInsight 클러스터에 대한 SSH 터널을 만듭니다. 자세한 내용은 HDInsight와 SSH 터널링 사용을 참조하세요.
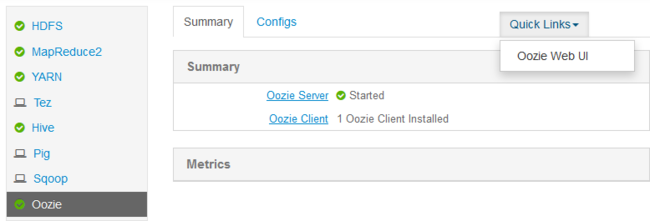
터널을 만든 후, URI
http://headnodehost:8080를 이용해 웹 브라우저에서 Ambari 웹 UI를 엽니다.페이지의 왼쪽부터 Oozie>빠른 링크>Oozie 웹 UI를 선택합니다.
Oozie 웹 UI는 기본적으로 실행 중인 워크플로 작업을 표시합니다. 모든 워크플로 작업을 보려면 모든 작업을 선택합니다.
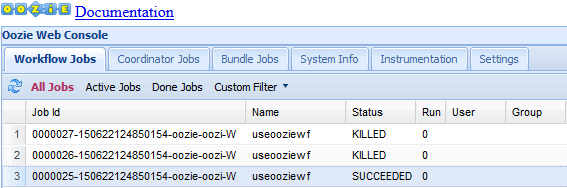
작업에 대한 자세한 내용을 보려면 해당 작업을 선택합니다.
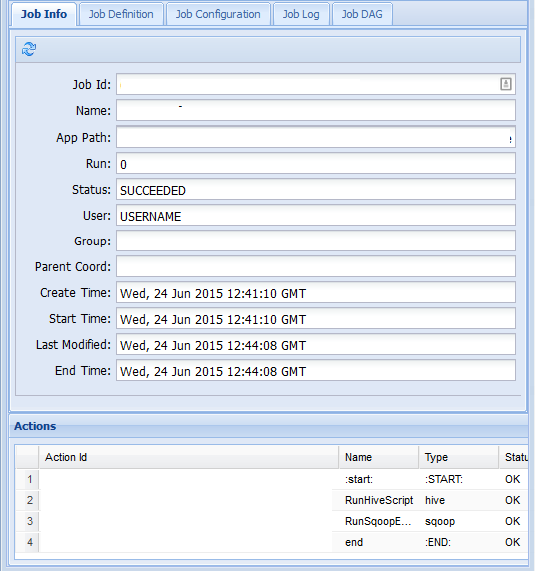
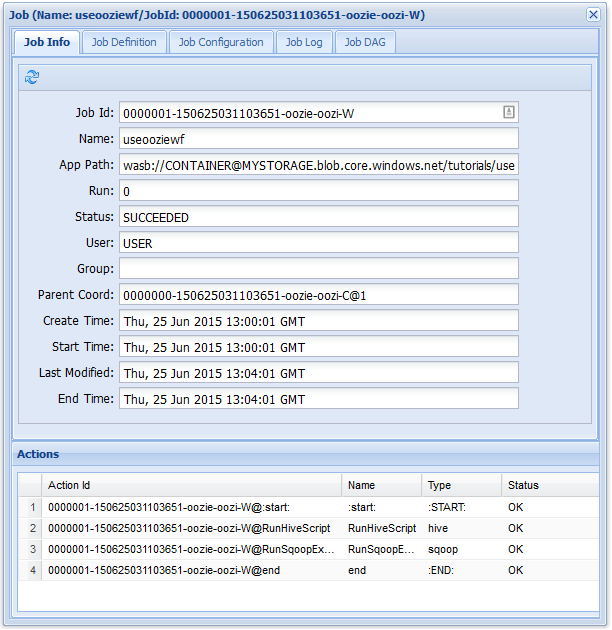
작업 정보 탭에서 기본 작업 정보 및 작업 내의 개별 동작을 볼 수 있습니다. 맨 위에 있는 탭을 사용하여 작업 정의, 작업 구성을 보거나, 작업 로그에 액세스하거나, 작업 DAG에서 작업의 DAG(방향성 비순환 그래프)를 확인할 수 있습니다.
작업 로그: 로그 가져오기 단추를 선택하여 작업에 대한 모든 로그를 얻거나 필드를 사용하여
Enter Search Filter로그를 필터링합니다.
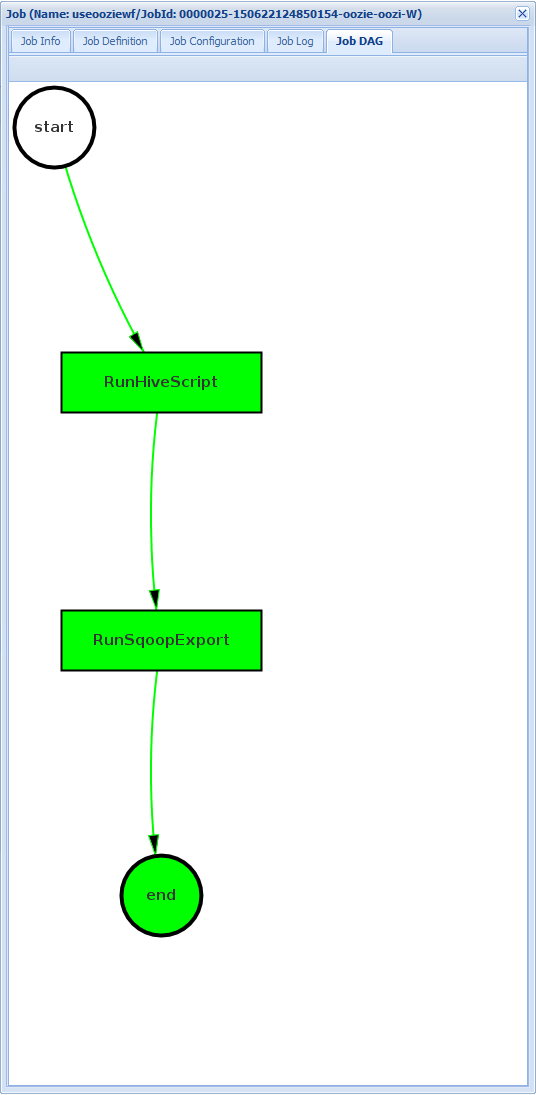
작업 DAG: DAG는 워크플로를 통해 가져온 데이터 경로의 그래픽 개요입니다.
작업 정보 탭에서 동작 중 하나를 선택하면 해당 동작에 대한 정보가 표시됩니다. 예를 들어 RunHiveScript 동작을 선택합니다.
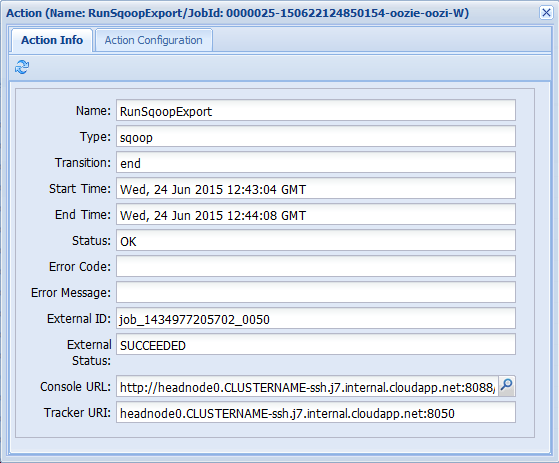
콘솔 URL 링크 등 작업에 대한 세부 정보를 확인할 수 있습니다. 이 링크를 사용하여 작업에 대한 작업 추적기 정보를 볼 수 있습니다.
작업 예약
코디네이터를 사용하여 작업의 시작, 종료 및 발생 빈도를 지정할 수 있습니다. 워크플로 일정을 정의하려면 다음 단계를 완료합니다.
다음 명령을 사용하여 coordinator.xml이라는 파일을 만듭니다.
nano coordinator.xml파일 내용으로 다음 XML을 사용합니다.
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>참고 항목
${...}변수는 런타임에 작업 정의의 값으로 대체됩니다. 변수는 다음과 같습니다.${coordFrequency}: 작업 인스턴스 실행 간격입니다.${coordStart}: 작업 시작 시간입니다.${coordEnd}: 작업 종료 시간입니다.${coordTimezone}: 일광 절약 시간제(일반적으로 UTC를 사용하여 표시됨) 없이 고정된 표준 시간대에서 코디네이터 작업을 처리합니다. 해당 시간대를 Oozie 처리 시간대라고 합니다.${wfPath}: workflow.xml의 경로입니다.
파일을 저장하려면 Ctrl + X를 선택하고 Y를 입력한 다음 입력을 선택합니다.
이 작업의 작업 디렉터리에 파일을 복사하려면 다음 명령을 사용합니다.
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xml이전에 만든
job.xml파일을 수정하려면 다음 명령을 사용합니다.nano job.xml다음과 같이 변경합니다.
Oozie에서 워크플로 대신 코디네이터 파일을 실행하도록 지시하려면
<name>oozie.wf.application.path</name>를<name>oozie.coord.application.path</name>로 변경하세요.코디네이터에서 사용하는
workflowPath변수를 설정하려면 다음 XML을 추가하세요.<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>wasbs://mycontainer@mystorageaccount.blob.core.windows텍스트를 job.xml 파일의 다른 항목에 사용된 값으로 바꿉니다.코디네이터에 대한 시작, 종료 및 빈도를 정의하려면 다음 XML을 추가하세요.
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>이러한 값은 시작 시간을 2018년 5월 10일 오후 12:00로 설정하고, 종료 시간을 2018년 5월 12일로 설정합니다. 이 작업을 실행하는 간격은 매일로 설정됩니다. 빈도는 분 단위이므로 24시간 x 60분 = 1,440분입니다. 마지막으로, 표준 시간대는 UTC로 설정됩니다.
파일을 저장하려면 Ctrl + X를 선택하고 Y를 입력한 다음 입력을 선택합니다.
작업을 제출하고 시작하려면 다음 명령을 사용합니다.
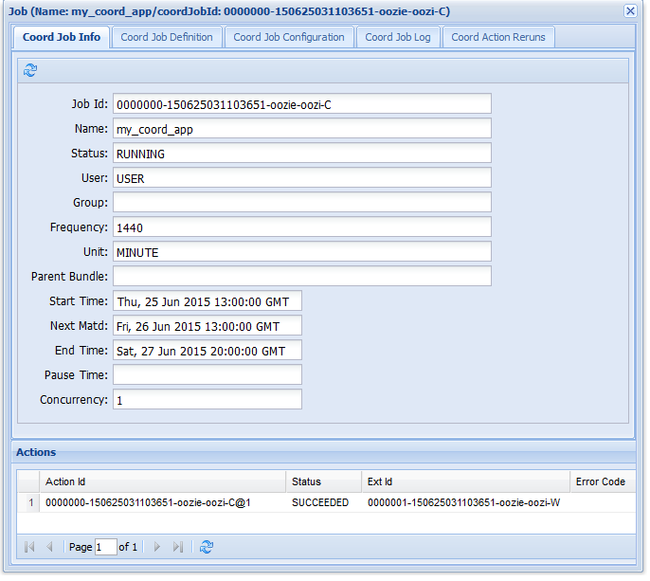
oozie job -config job.xml -runOozie 웹 UI를 방문하여 코디네이터 작업 탭을 선택하면 다음 그림과 유사한 정보가 표시됩니다.

다음 구체화 항목에는 다음에 작업이 실행되는 시간이 포함됩니다.
이전의 워크플로 작업과 마찬가지로 웹 UI에서 작업 항목을 선택하면 작업에 대한 정보가 표시됩니다.
참고 항목
이 이미지는 성공한 작업 실행만 표시하며, 예약된 워크플로 내의 개별 동작은 표시하지 않습니다. 개별 작업을 보려면 동작 항목 중 하나를 선택합니다.
다음 단계
이 문서에서는 Oozie 워크플로를 정의하는 방법 및 Oozie 작업을 실행하는 방법을 알아보았습니다. HDInsight 작업 방법에 대한 자세한 내용은 다음 문서를 참조하세요.