Data Lake Tools for Visual Studio를 사용하여 Azure HDInsight에 연결 및 Apache Hive 쿼리 실행
Visual Studio용 Microsoft Azure Data Lake 및 Stream Analytics 도구 (Data Lake 도구)를 사용하는 방법에 대해 알아봅니다. 도구를 사용하여 Azure HDInsight에서 Apache Hadoop 클러스터에 연결하 고, Hive 쿼리를 제출합니다.
HDInsight 사용에 대한 자세한 내용은 HDInsight 시작하기를 참조하세요.
Data Lake Tools for Visual Studio를 사용하여 Azure Data Lake Analytics 및 HDInsight에 액세스할 수 있습니다. Data Lake Tools에 대한 자세한 내용은 Data Lake Tools for Visual Studio를 사용하여 U-SQL 스크립트 개발을 참조하세요.
필수 조건
이 문서를 작성하고 Visual Studio용 Data Lake Tools를 사용하려면 다음 항목이 필요합니다:
Azure HDInsight 클러스터를 만듭니다. HDInsight 클러스터를 만들려면 Azure HDInsight에서 Apache Hadoop 사용 시작을 참조하세요. 대화형 Apache Hive 쿼리를 실행하려면 HDInsight 대화형 쿼리 클러스터가 필요합니다.
Visual Studio. Visual Studio Community 에디션은 무료입니다. 여기에 표시된 지침은 Visual Studio 2019에 대한 것입니다.
Data Lake Tools for Visual Studio 설치
Visual Studio 버전에 따른 적합한 설명에 따라 Data Lake 도구를 설치합니다:
Visual Studio 2017 또는 Visual Studio 2019의 경우:
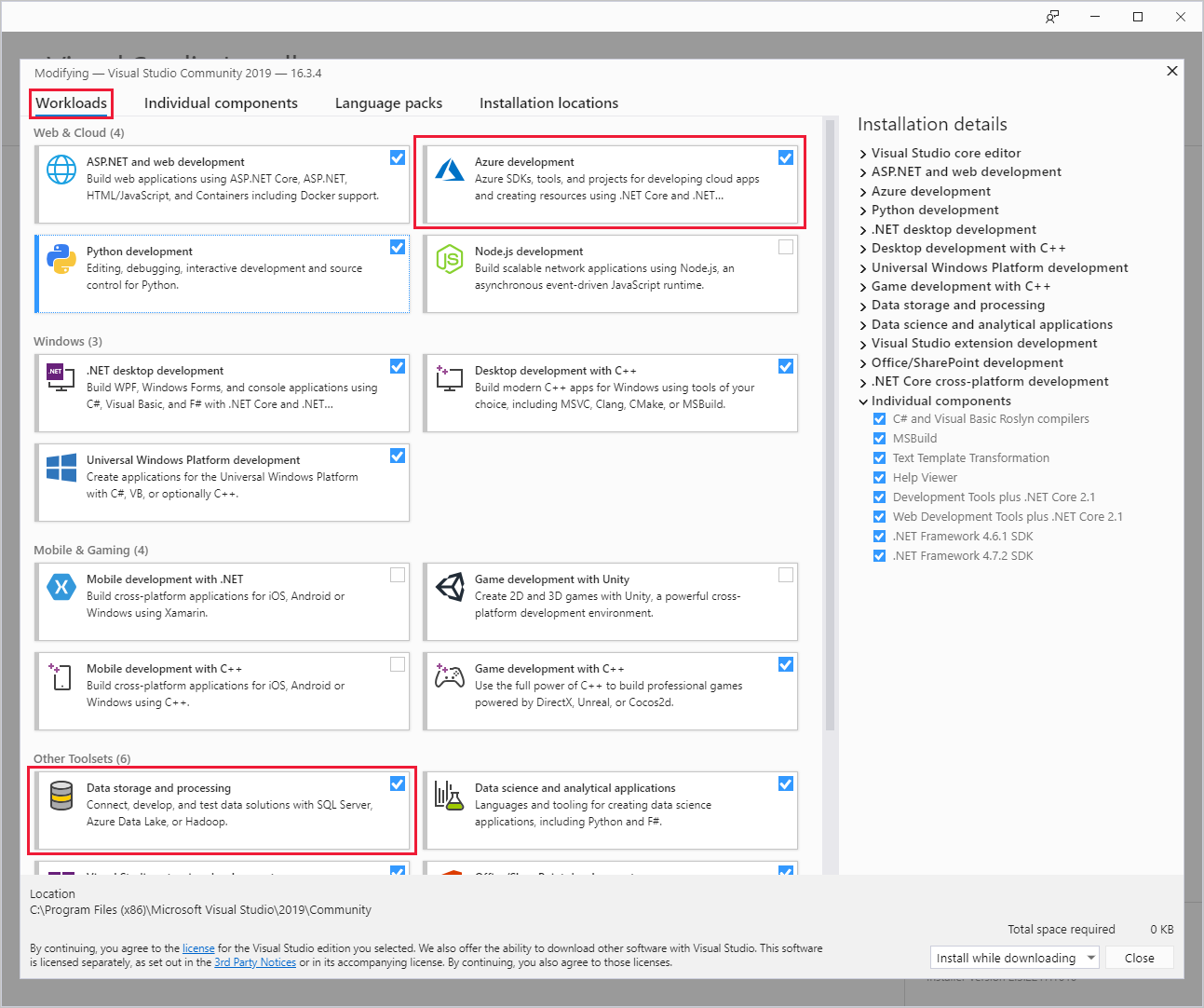
Visual Studio를 설치하는 동안 Azure 개발 워크로드 또는 데이터 저장 및 처리 워크로드를 포함해야 합니다.
기존 Visual Studio 설치의 경우, IDE 메뉴 모음으로 이동하고 도구 > 및 기능 가져오기를 선택하여 Visual Studio 설치 관리자를 엽니다. 워크로드 탭에서 최소한 Azure 개발 워크로드 ( 웹 & 클라우드에서)를 선택합니다. 또는 데이터 저장 및 처리 워크로드를 선택합니다 ( 기타 도구 집합에서).
Visual Studio 2015의 경우:
Data Lake 도구를 다운로드합니다. Visual Studio 버전과 일치하는 Data Lake Tools 버전을 선택하세요.
Visual Studio용 Data Lake 도구 업데이트
그런 다음 Data Lake 도구를 가장 최신 버전으로 업데이트해야 합니다.
Visual Studio를 엽니다.
시작 창에서 코드를 사용하지 않고 계속을 선택합니다.
Visual Studio IDE 메뉴 모음에서 확장 > 관리 확장을 선택합니다.
확장 관리 대화 상자에서 업데이트 노드를 확장합니다.
사용 가능한 업데이트 목록에 Azure Data Lake 및 Stream 분석 도구가 포함되어 있는 경우, 해당 업데이트를 선택합니다. 그런 다음 해당 업데이트 단추를 선택합니다. 다운로드 및 설치 대화 상자가 표시되었다가 사라진 후, Visual Studio에서 Azure Data Lake 및 Stream 분석 도구 확장을 업데이트 일정에 추가합니다.
모든 Visual Studio 창을 닫습니다. VSIX 설치 대화 상자가 나타납니다.
라이선스를 선택하여 사용 조건을 읽고, 닫기를 선택하여 VSIX 설치 프로그램 대화 상자로 돌아갑니다.
수정을 선택합니다. 확장 업데이트 설치가 시작됩니다. 잠시 후에 대화 상자가 바뀌면서 수정 완료를 표시합니다. 닫기를 선택하고 Visual Studio를 다시 시작하여 설치를 완료합니다.
참고 항목
Data Lake Tools 버전 2.3.0.0 이상만 사용하여 대화형 쿼리 클러스터에 연결하고 대화형 Hive 쿼리를 실행할 수 있습니다.
Azure 구독에 연결
Visual Studio용 Data Lake 도구를 사용하여 HDInsight 클러스터에 연결하고, 몇 가지 기본 관리 작업을 수행하면 Hive 쿼리를 실행할 수 있습니다.
참고 항목
일반 Hadoop 클러스터에 연결하는 방법에 대한 자세한 내용은 Visual Studio를 사용한 Hive 쿼리 작성 및 제출 방법을 참조하세요.
Azure 구독에 연결
Azure 구독에 연결하려면,
Visual Studio를 엽니다.
시작 창에서 코드를 사용하지 않고 계속을 선택합니다.
IDE 메뉴 모음에서 뷰 > 서버 탐색기를 선택합니다.
서버 탐색기에서 Azure를 마우스 오른쪽 단추로 클릭하고, Microsoft Azure 구독에 연결을 선택하여 인증 프로세스를 완료합니다. 서버 탐색기에서 Azure > hdinsight를 확장하여 기존 HDInsight 클러스터 목록을 조회합니다.
클러스터가 없는 경우 Azure Portal, Azure PowerShell 또는 HDInsight SDK를 사용하여 클러스터를 만들 수 있습니다. 자세한 내용은 HDInsight에서 클러스터 설정하기를 참조하세요.
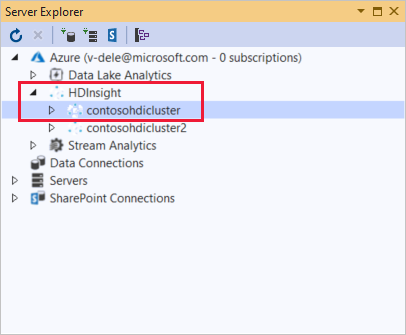
HDInsight 클러스터를 확장합니다. 클러스터에는 Hive 데이터베이스용 노드가 포함되어 있습니다. 기본 스토리지 계정, 연결된 스토리지 계정 및 Hadoop 서비스 로그도 그러합니다. 엔터티를 더 확장할 수 있습니다.
Azure 구독에 연결되면 다음 작업을 수행할 수 있습니다.
Visual Studio에서 Azure에 연결
Visual Studio에서 Azure Portal에 연결하려면,
서버 탐색기에서 Azure > HDInsight를 확장하고 클러스터를 선택합니다.
HDInsight 클러스터를 마우스 오른쪽 단추로 클릭한 다음, Azure Portal에서 클러스터 관리를 선택합니다.
Visual Studio에서 문의하거나 의견을 제공하려면
Visual Studio에서 문의하거나 사용자 의견을 제공하려면:
서버 탐색기에서 Azure > HDInsight를 선택합니다.
HDInsight를 마우스 오른쪽 단추로 클릭하고 MSDN 포럼을 선택하여 문의하거나 피드백을 제공해 주세요.
클러스터에 연결 또는 편집
참고 항목
현재 연결할 수 있는 HDInsight 클러스터의 유일한 형식은 Hive 타입입니다.
HDInsight cluster에 연결하려면:
HDInsight를 마우스 오른쪽 단추로 클릭한 다음, HDInsight 클러스터 연결을 선택하여 HDInsight 클러스터 연결 대화 상자를 표시합니다.
양식에
https://CLUSTERNAME.azurehdinsight.net연결 Url을 입력합니다. 클러스터 이름은 다른 필드로 이동할 때 URL의 클러스터 이름 부분으로 자동으로 채워집니다. 그 후에 사용자 이름 및 암호를 입력하고, 다음을 선택합니다.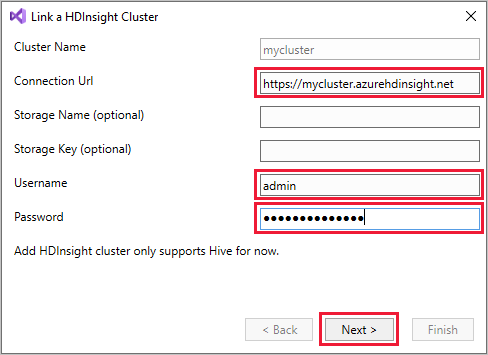
마침을 선택합니다. 클러스터가 성공적으로 연결되면, 클러스터는 HDInsight 노드 아래에 나열됩니다.
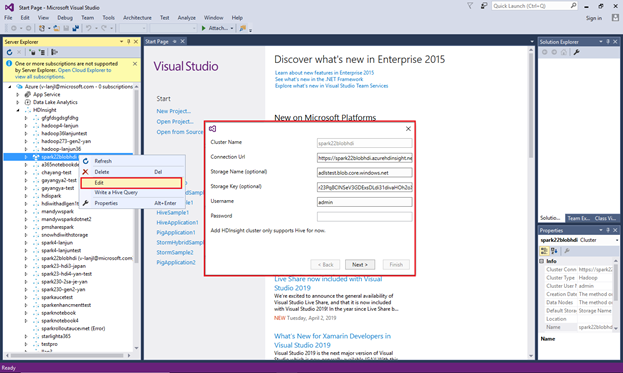
연결된 클러스터를 업데이트하려면 클러스터를 마우스 오른쪽 단추로 클릭하고 편집을 선택합니다. 그런 다음 클러스터 정보를 업데이트할 수 있습니다.
연결된 리소스 탐색
서버 탐색기에서 기본 스토리지 계정 및 연결된 스토리지 계정을 확인할 수 있습니다. 기본 스토리지 계정을 확장한 경우 스토리지 계정의 컨테이너를 확인할 수 있습니다. 기본 스토리지 계정과 기본 컨테이너가 표시되어 있습니다.
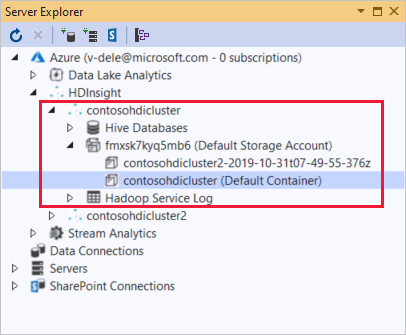
컨테이너의 내용을 보려면 컨테이너를 마우스 오른쪽 단추로 클릭하고 컨테이너 보기를 선택합니다. 컨테이너를 연 후 도구 모음 단추를 사용하여 콘텐츠 목록을 새로 고치고, Blob을 업로드하고, 선택한 Blob을 삭제하고, Blob을 열고, 선택한 Blob을 다운로드(다른 이름으로 저장)할 수 있습니다.
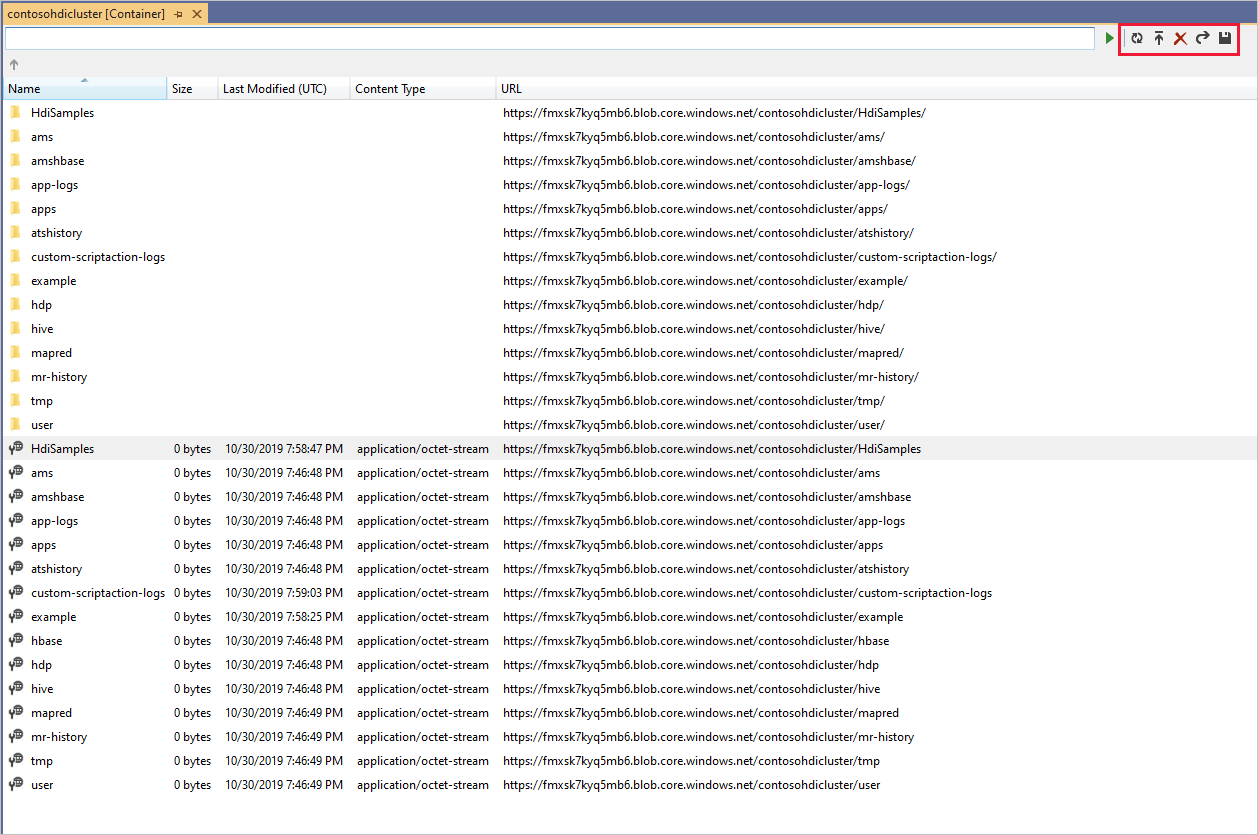
대화형 Apache Hive 쿼리 실행
Apache Hive는 Hadoop을 기반으로 하는 데이터 웨어하우스 인프라입니다. Hive는 데이터 요약, 쿼리 및 분석에 사용됩니다. Data Lake Tools for Visual Studio를 사용하여 Visual Studio에서 Hive 쿼리를 실행할 수 있습니다. Hive에 대한 자세한 내용은 Azure HDInsight의 Apache Hive 및 HiveQL이란?을 참조하세요.
Azure HDInsight의 대화형 쿼리는 Apache Hive 2.1에서 LLAP의 Hive를 사용합니다. 대화형 쿼리는 저장된 큰 데이터 세트에 대해 복잡한 데이터 웨어하우스 스타일의 쿼리에 대화형 기능을 제공합니다. 대화형 쿼리에서 Hive 쿼리를 실행하면 기존의 Hive batch 작업에 비해 훨씬 빠릅니다.
참고 항목
HDInsight 대화형 쿼리 클러스터에 연결하는 경우에만 대화형 Hive 쿼리를 실행할 수 있습니다.
또한 Visual Studio용 Data Lake 도구를 사용하여 Hive 작업에 대해 자세히 확인할 수도 있습니다. Data Lake Tools for Visual Studio는 특정 Hive 작업에 대한 YARN 로그를 수집하고 표시합니다.
서버 탐색기에서 Azure > HDInsight를 고르고 클러스터를 선택합니다. 이 노드는 수행할 섹션의 서버 탐색기에서 시작점입니다.
hivesampletable 보기
모든 HDInsight 클러스터에는 기본적으로 hivesampletable이라는 샘플 Hive이라는 테이블이 있습니다.
클러스터에서 Hive 데이터베이스 > 기본 > hivesampletable를 선택합니다.
hivesampletable스키마를 보려면:hivesampletable을 확장합니다.
hivesampletable열의 이름 및 데이터 형식이 표시됩니다.hivesampletable데이터를 보려면:hivesampletable을 마우스 오른쪽 버튼으로 클릭하고, 상위 100행 보기를 선택합니다. 100 결과의 목록이 Hive 테이블: hivesampletable 창에 표시됩니다. 이는 Hive ODBC 드라이버를 사용하여 다음 Hive 쿼리를 실행하는 것과 동일합니다:
SELECT * FROM hivesampletable LIMIT 100행의 수를 변경하여 이를 사용자 지정할 수 있습니다; 드롭다운 목록에서 50, 100, 200 또는 1000행을 선택할 수 있습니다.
Hive 테이블 만들기
Hive 테이블을 만들려면 GUI를 사용하거나 Hive 쿼리를 사용할 수 있습니다. Hive 쿼리 사용에 대한 자세한 내용은 Hive 쿼리 생성과 실행을 참조하세요.
클러스터에서 Hive 데이터베이스 > 기본을 선택합니다.
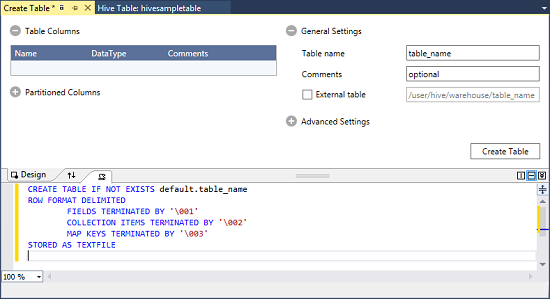
기본값을 마우스 오른쪽 단추로 클릭한 다음, 테이블 생성을 선택합니다.
테이블을 구성합니다.
테이블 생성 단추를 선택하여 작업을 제출하면 새 Hive 테이블이 생성됩니다.
Hive 쿼리 생성 및 실행
Hive 쿼리를 만들고 실행하기 위한 두 가지 옵션이 있습니다.
- 임시 쿼리 만들기
- Hive 애플리케이션 만들기
ad-hoc query 만들기
ad-hoc 쿼리를 만들고 실행하려면:
쿼리를 실행하려는 클러스터를 마우스 오른쪽 단추로 클릭한 다음, Hive 쿼리 작성을 선택합니다.
Hive 쿼리를 입력합니다.
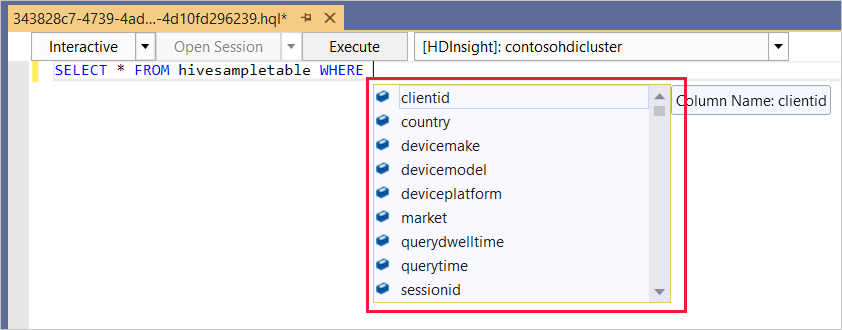
Hive 편집기는 IntelliSense를 지원합니다. Data Lake Tools for Visual Studio는 Hive 스크립트를 편집할 때 원격 메타데이터 로드를 지원합니다. 예를 들어
SELECT * FROM을 입력하면 IntelliSense에서 제시된 테이블 이름을 모두 나열합니다. 테이블 이름이 지정되면 IntelliSense에서 열 이름을 나열합니다. 이 도구는 대부분의 Hive DML 문, 하위 쿼리 및 기본 제공 UDF를 지원합니다.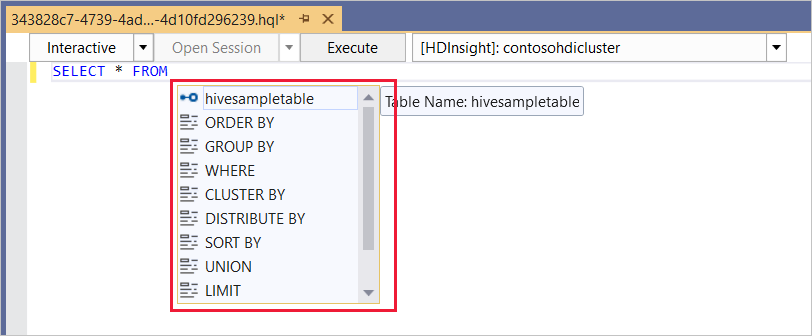
참고 항목
IntelliSense는 HDInsight 도구 모음에서 선택한 클러스터의 메타데이터만 제안합니다.
다음은 사용할 수 있는 샘플 쿼리입니다:
SELECT devicemodel, COUNT(devicemodel) AS deviceCount FROM hivesampletable GROUP BY devicemodel ORDER BY devicemodel실행 모드를 선택합니다:
대화형
첫 번째 드롭다운 목록에서 Interactive를 선택하고 실행을 선택합니다.

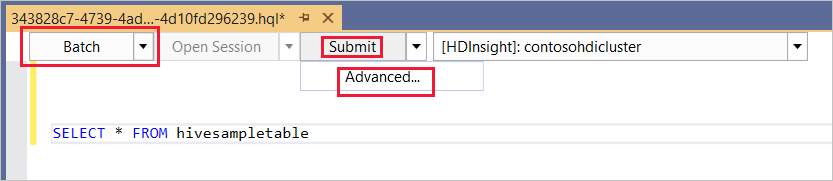
Batch
첫 번째 드롭다운 목록에서 Batch를 선택하고, 제출을 선택합니다. 또는 제출 옆에 있는 드롭다운 아이콘을 선택하고, 고급을 선택합니다.
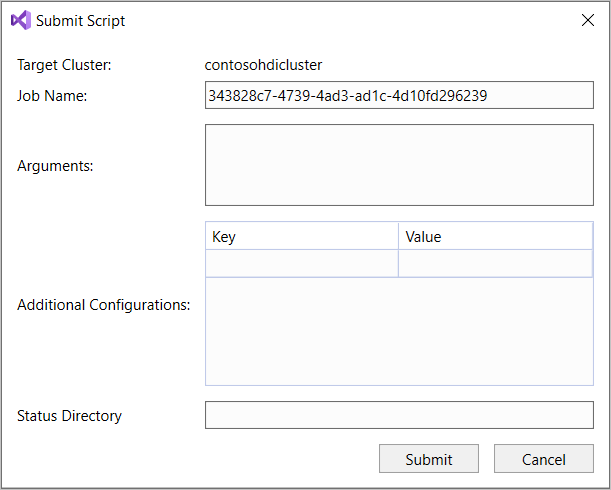
고급 제출 옵션을 선택하면 스크립트 제출 대화 상자가 나타납니다. 스크립트에 대해 작업 이름 , 인수, 추가 구성 및 상태 디렉터리를 구성하십시오.
참고 항목
batch를 대화형 쿼리 클러스터로 전송할 수 없습니다. 대화형 모드를 사용해야 합니다.
Hive 애플리케이션 만들기
Hive 솔루션을 만들고 실행하려면,
메뉴 모음에서 파일>새로 만들기>프로젝트을 차례로 선택합니다.
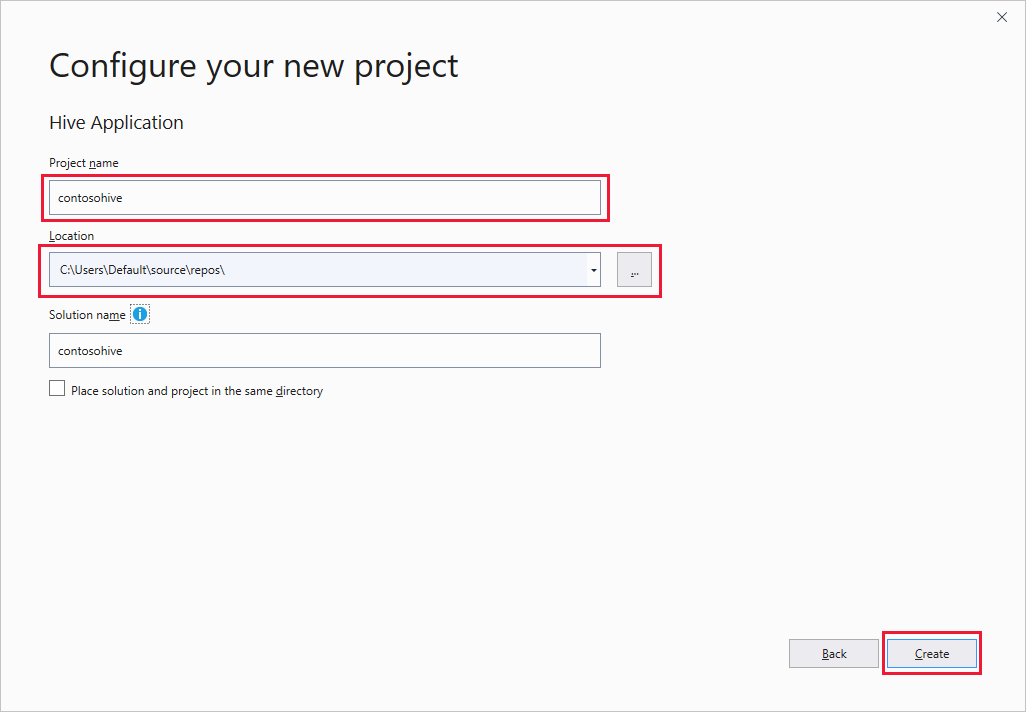
새 프로젝트 만들기 창에서 검색 상자를 선택하고 Hive를 입력합니다. 그런 다음, Hive 애플리케이션을 선택하고 다음을 선택합니다.
새 프로젝트 구성 창에서 프로젝트 이름을 입력하고, 새 프로젝트의 위치를 선택하거나 만든 다음, 생성하기를 선택합니다.
솔루션 탐색기에서 Script.hql을 두 번 클릭하여 이 스크립트를 엽니다.
작업 요약 및 출력 보기
작업 요약은 일괄 처리 모드와 대화형 모드 간에 약간 다릅니다.
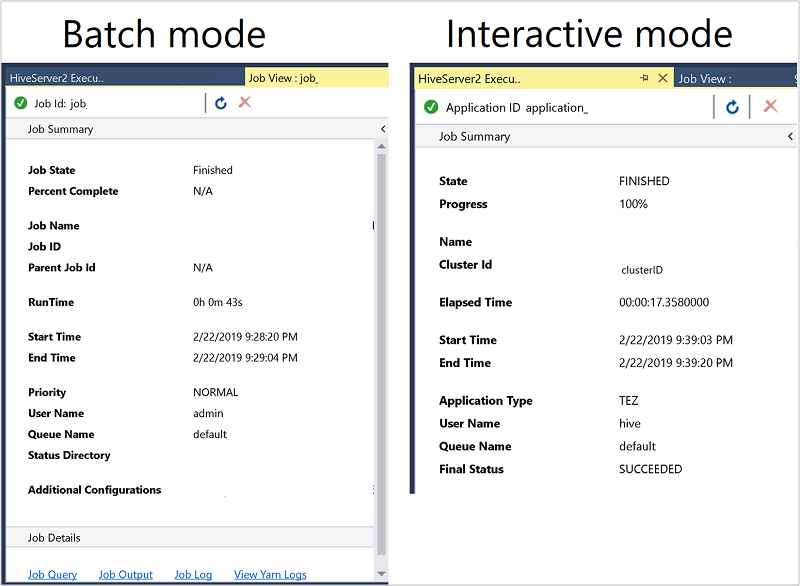
작업 상태가 완료로 변경될 때까지 새로 고침 단추를 사용하여 상태를 업데이트합니다.
일괄 처리 모드의 작업 세부 정보를 보려면, 아래의 링크를 선택하여 작업 쿼리, 작업 출력또는 작업 로그, 혹은 Yarn 로그를 확인합니다.
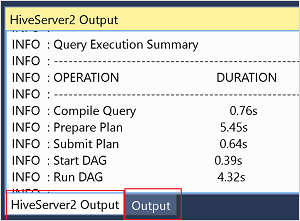
대화형 모드의 작업 세부 정보는 출력 and HiveServer2 출력 창을 참조하세요.
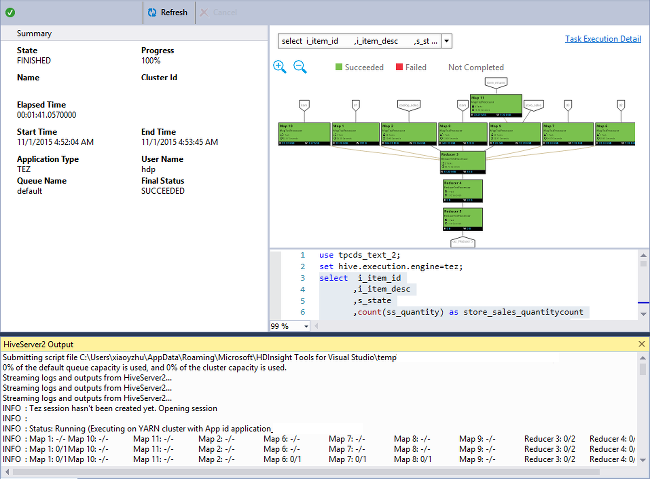
작업 그래프 보기
현재 작업 그래프는 Tez를 실행 엔진으로 사용하는 Hive 작업에 대해서만 표시됩니다. Tez 사용에 대한 자세한 내용은 Azure HDInsight의 Apache Hive 및 HiveQL이란?을 참조하세요. Map Reduce 대신 Apache Tez 사용 역시 참조하세요.
꼭짓점 내의 모든 연산자를 보려면 작업 그래프의 꼭짓점을 두 번 클릭합니다. 또한 특정 연산자를 가리켜서 연산자에 대한 자세한 정보를 볼 수도 있습니다.
Tez가 실행 엔진으로 지정된 경우라도 Tez 애플리케이션이 시작되지 않으면 작업 그래프가 표시되지 않을 수 있습니다. 이 상황은 작업에 DML문이 포함되어 있지 않기 때문에 발생할 수 있습니다. 또는 Tez 애플리케이션을 실행하지 않고 DML 문이 반환될 수 있기 때문입니다. 예를 들어, SELECT * FROM table1은 Tez 애플리케이션을 시작하지 않습니다.
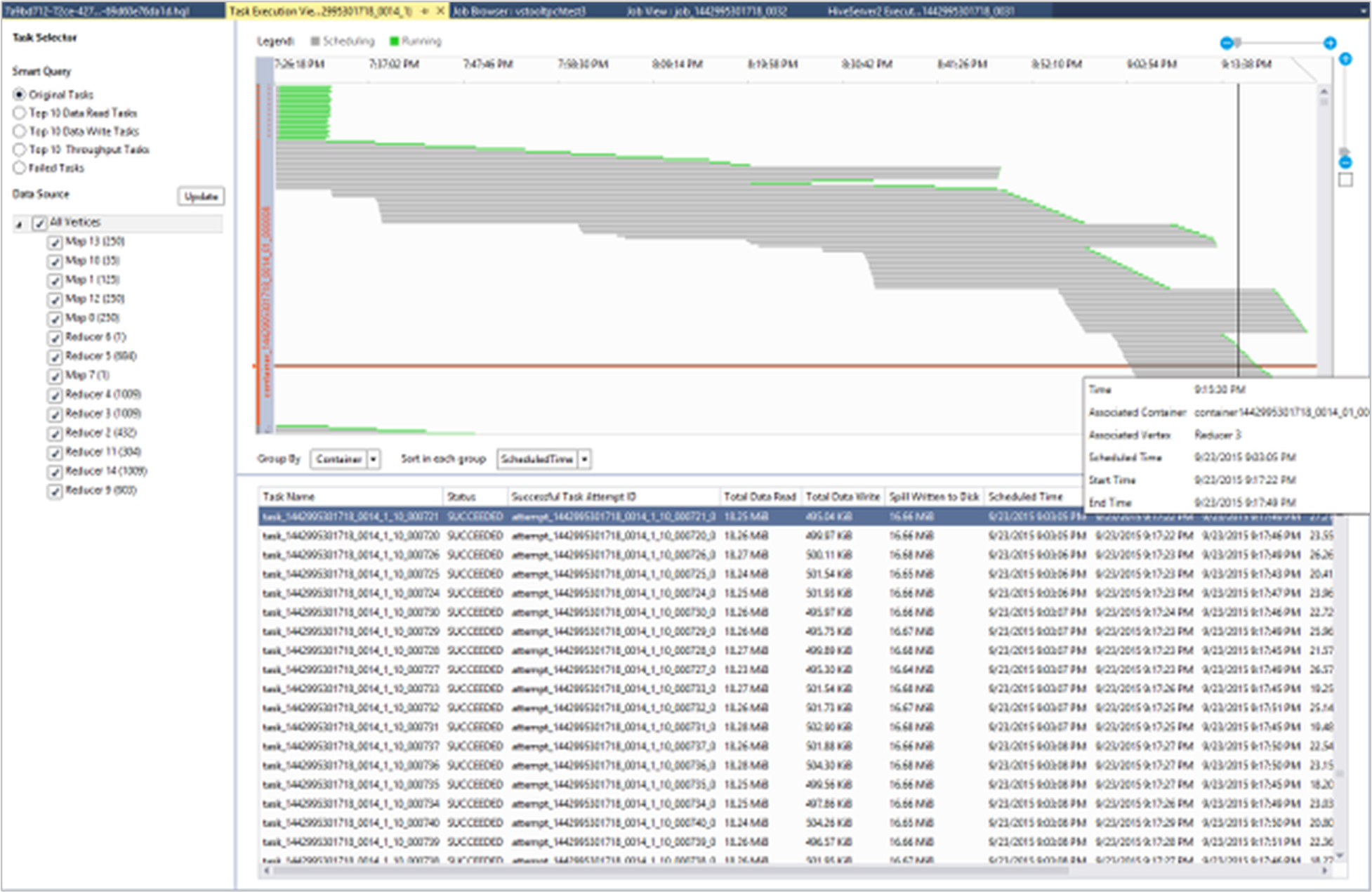
태스크 실행 세부 정보
작업 그래프에서 작업 실행 세부 정보를 선택하여 Hive 작업에 대한 구조화되고 시각화된 정보를 가져올 수 있습니다. 또한 더 많은 작업 세부 정보도 얻을 수도 있습니다. 성능 문제가 발생하면 보기를 사용하여 문제에 대한 자세한 정보를 얻을 수 있습니다. 예를 들어 각 작업의 동작 방식 및 각 태스크에 대한 자세한 정보(데이터 읽기/쓰기, 일정/시작/종료 시간 등)를 얻을 수 있습니다. 이 정보를 사용하여 시각화된 정보에 따라 작업 구성 또는 시스템 아키텍처를 튜닝합니다.
Hive 작업 보기
Hive 작업에 대한 작업 쿼리, 작업 출력, 작업 로그 및 Yarn 로그를 볼 수 있습니다.
최신 출시된 도구에서는 YARN 로그를 수집하고 표시하여 Hive 작업에 대한 자세한 정보를 확인할 수 있습니다. Yarn 로그는 성능 문제를 조사하는 데 도움이 됩니다. HDInsight에서 YARN 로그를 수집하는 방법에 대한 자세한 내용은 Apache Hadoop YARN 애플리케이션 로그에 액세스를 참조하세요.
Hive 작업을 보려면,
HDInsight 클러스터를 마우스 오른쪽 단추로 클릭한 다음, 작업 보기를 선택합니다.
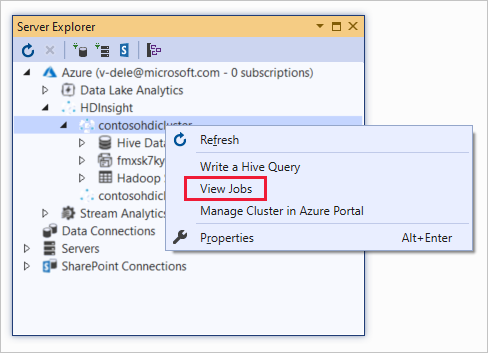
클러스터에서 실행한 Hive 작업 목록이 표시됩니다.
작업을 선택합니다. Hive 작업 요약 창에서 다음 링크 중 하나를 선택합니다.
- 작업 쿼리
- 작업 출력
- 작업 로그
- Yarn 로그
Apache Pig 스크립트 실행
메뉴 모음에서 파일>새로 만들기>프로젝트을 차례로 선택합니다.
시작 창에서 검색 상자를 선택하고 Pig를 입력합니다. 그 다음 Pig 애플리케이션을 선택하고 다음을 선택합니다.
새 프로젝트 구성 창에서 프로젝트 이름을 입력하고, 새 프로젝트를 저장할 위치를 선택하거나 해당 위치를 만듭니다. 다음으로 만들기를 선택합니다.
IDE 솔루션 탐색기 창에서 Script.pig를 두 번 클릭하여 스크립트를 엽니다.
사용자 의견 및 알려진 문제
null 값으로 시작되는 결과가 표시되지 않는 문제는 해결되었습니다. 이 문제로 인해 차단되는 경우 지원 팀에 문의하세요.
Visual Studio에서 생성한 HQL 스크립트는 사용자의 로컬 지역 설정에 따라 인코딩됩니다. 클러스터에 스크립트를 이진 파일로 업로드하면 스크립트가 제대로 실행되지 않습니다.
다음 단계
이 문서에서는 Data Lake Tools for Visual Studio 패키지를 사용하여 Visual Studio에서 HDInsight 클러스터에 연결하는 방법을 알아보았습니다. 또한 Hive 쿼리를 실행하는 방법도 알아보았습니다.