Apache Spark™ 클러스터를 사용하여 AKS의 Azure HDInsight에서 Delta Lake 사용(미리 보기)
참고 항목
2025년 1월 31일에 Azure HDInsight on AKS가 사용 중지됩니다. 2025년 1월 31일 이전에 워크로드가 갑자기 종료되지 않도록 워크로드를 Microsoft Fabric 또는 동등한 Azure 제품으로 마이그레이션해야 합니다. 구독의 나머지 클러스터는 호스트에서 중지되고 제거됩니다.
사용 중지 날짜까지 기본 지원만 사용할 수 있습니다.
Important
이 기능은 현지 미리 보기로 제공됩니다. Microsoft Azure 미리 보기에 대한 보충 사용 약관에는 베타 또는 미리 보기로 제공되거나 아직 일반 공급으로 릴리스되지 않은 Azure 기능에 적용되는 더 많은 약관이 포함되어 있습니다. 이 특정 미리 보기에 대한 자세한 내용은 Azure HDInsight on AKS 미리 보기 정보를 참조하세요. 질문이나 기능 제안이 있는 경우 세부 정보와 함께 AskHDInsight에 요청을 제출하고 Azure HDInsight 커뮤니티에서 추가 업데이트를 보려면 팔로우하세요.
AKS의 Azure HDInsight는 조직이 대량의 데이터를 처리하는 데 도움이 되는 빅 데이터 분석을 위한 관리형 클라우드 기반 서비스입니다. 이 자습서에서는 Apache Spark™ 클러스터를 사용하여 AKS의 Azure HDInsight에서 Delta Lake를 사용하는 방법을 보여 줍니다.
전제 조건
AKS의 Azure HDInsight에서 Apache Spark™ 클러스터 만들기
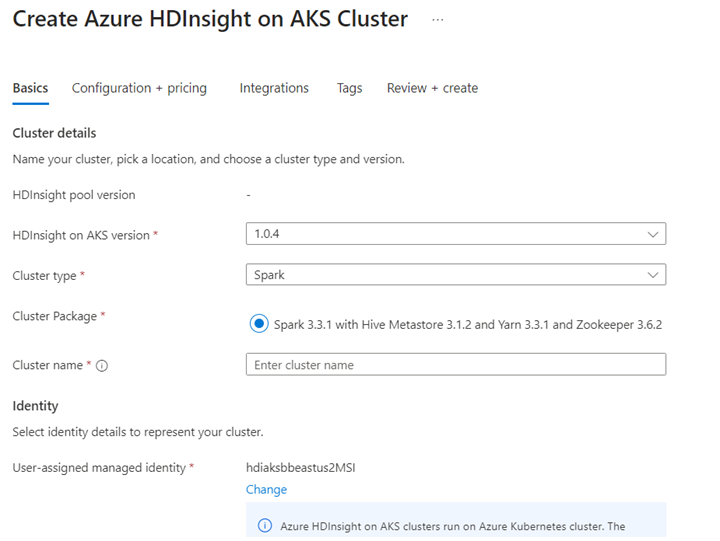
Jupyter Notebook에서 Delta Lake 시나리오를 실행합니다. 다음 예제는 Scala에 있으므로 Jupyter Notebook을 만들고 Notebook을 만드는 동안 "Spark"를 선택합니다.
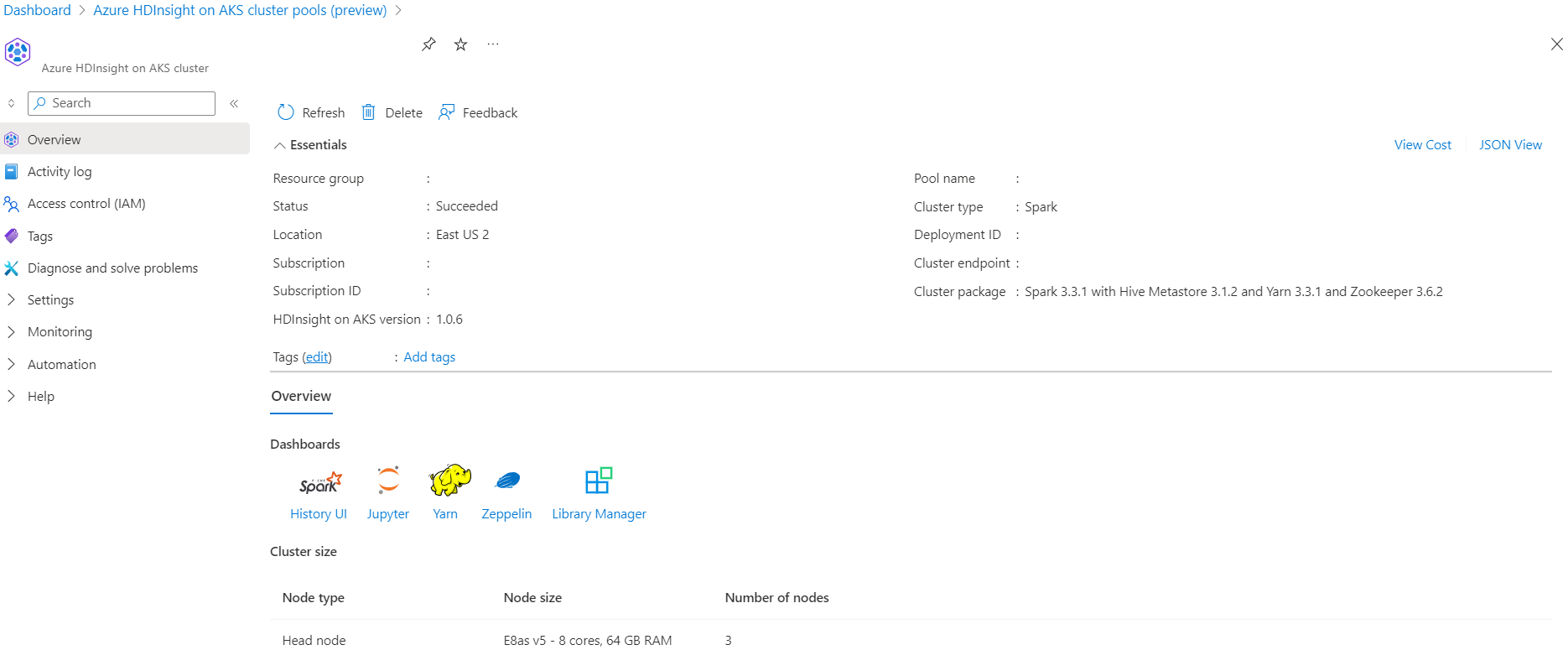


시나리오
- NYC Taxi Parquet 데이터 형식 읽기 - Parquet 파일 URL 목록은 NYC 택시 & 리무진 위원회에서 제공됩니다.
- 각 URL(파일)에 대해 일부 변환을 수행하고 델타 형식으로 저장합니다.
- 증분 로드를 사용하여 Delta 테이블의 평균 거리, 마일당 평균 비용 및 평균 비용을 계산합니다.
- 델타 형식의 3단계에서 계산된 값을 KPI 출력 폴더에 저장합니다.
- 델타 형식 출력 폴더에서 Delta 테이블을 만듭니다(자동 새로 고침).
- KPI 출력 폴더에는 여러 버전의 평균 거리와 여정의 마일당 평균 비용이 있습니다.
Delta Lake에 대한 필수 구성 제공
Apache Spark 호환성 매트릭스를 사용하는 Delta Lake - Delta Lake는 Apache Spark 버전에 따라 Delta Lake 버전을 변경합니다.
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

데이터 파일 목록
참고 항목
이러한 파일 URL은 NYC 택시 & 리무진 위원회에서 가져옵니다.
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

출력 디렉터리 만들기
델타 형식 출력을 만들고 필요한 경우 변수 transformDeltaOutputPath 및 avgDeltaOutputKPIPath을(를) 변경하려는 위치입니다.
avgDeltaOutputKPIPath- 평균 KPI를 델타 형식으로 저장transformDeltaOutputPath- 변환된 출력을 델타 형식으로 저장
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Parquet 형식에서 델타 형식 데이터 만들기
입력 데이터는 https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page에서 다운로드한 데이터
listOfDataFile에서 가져옵니다.시간 이동 및 버전을 보여 주려면 데이터를 개별적으로 로드합니다.
증분 로드에서 비즈니스 KPI에 따라 변환 및 계산을 수행합니다.
- 평균 거리
- 마일당 평균 비용
- 평균 비용
변환된 데이터 및 KPI 데이터를 델타 형식으로 저장
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Delta 테이블을 사용하여 델타 형식 읽기
- 변환된 데이터 읽기
- KPI 데이터 읽기
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
인쇄 스키마
- 변환된 KPI 데이터1 및 평균 KPI 데이터1에 대한 Delta 테이블 스키마를 인쇄합니다.
// transform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema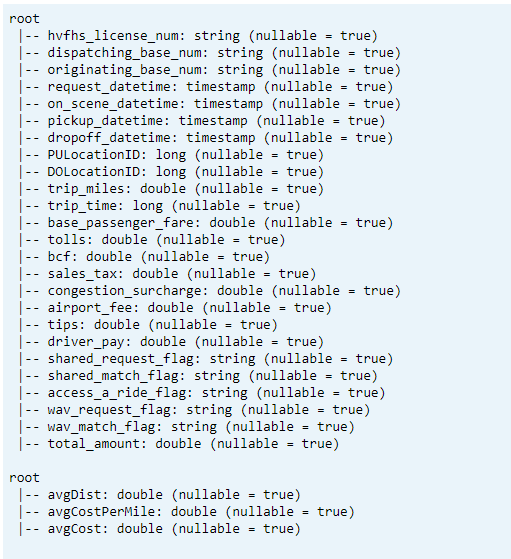
데이터 테이블에서 마지막 계산 KPI 표시
dtAvgKpi.toDF.show(false)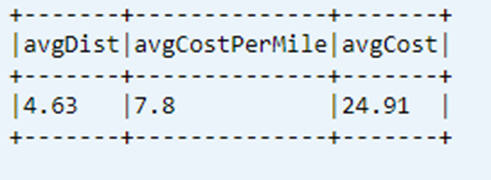


계산된 KPI 기록 표시
이 단계에서는 _delta_log에서 KPI 트랜잭션 테이블의 기록을 표시합니다.
dtAvgKpi.history().show(false)

각 데이터 로드 후 KPI 데이터 표시
- 시간 이동 사용 시 각 로드 후 KPI 변경 내용을 볼 수 있습니다.
- Power BI에서 이러한 변경 내용을 읽을 수 있도록 모든 버전 변경 내용을 CSV 형식으로
avgMoMKPIChangePath에 저장할 수 있습니다.
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

참조
- Apache, Apache Spark, Spark 및 관련 오픈 소스 프로젝트 이름은 ASF(Apache Software Foundation)의 상표입니다.