Azure Data Explorer 및 Apache Flink® 통합
Azure Data Explorer는 거의 실시간으로 대량의 데이터를 쉽게 분석할 수 있는 완전 관리형 고성능 빅 데이터 분석 플랫폼입니다.
ADX는 사용자가 스트리밍 애플리케이션, 웹 사이트, IoT 디바이스 등에서 대량의 데이터를 분석하는 데 도움이 됩니다. Apache Flink를 ADX와 통합하면 실시간 데이터를 처리하고 ADX에서 분석할 수 있습니다.
필수 구성 요소
Flink에서 Azure Data Explorer를 싱크로 사용하는 단계
Flink 클러스터을 만듭니다.
필요에 따라 데이터베이스 및 테이블을 사용하여 ADX를 만듭니다.
Kusto에서 관리형 ID에 대한 데이터 수집기 권한을 추가합니다.
.add database <DATABASE_NAME> ingestors ('aadapp=CLIENT_ID_OF_MANAGED_IDENTITY')Kusto 클러스터 URI(Uniform Resource Identifier), 사용된 데이터베이스 및 관리 ID 및 작성해야 하는 테이블을 정의하는 샘플 프로그램을 실행합니다.
flink-connector-kusto 프로젝트 복제: https://github.com/Azure/flink-connector-kusto.git
다음 명령을 사용하여 ADX에서 테이블 만들기
.create table CryptoRatesHeartbeatTimeBatch (processing_dttm: datetime, ['type']: string, last_trade_id: string, product_id: string, sequence: long, ['time']: datetime)올바른 Kusto 클러스터 URI, 데이터베이스 및 사용된 관리 ID로 FlinkKustoSinkSample.java 파일을 업데이트합니다.
String database = "sdktests"; //ADX database name String msiClientId = “xxxx-xxxx-xxxx”; //Provide the client id of the Managed identity which is linked to the Flink cluster String cluster = "https://trdp-1665b5eybxs0tbett.z8.kusto.fabric.microsoft.com/"; //Data explorer Cluster URI KustoConnectionOptions kustoConnectionOptions = KustoConnectionOptions.builder() .setManagedIdentityAppId(msiClientId).setClusterUrl(cluster).build(); String defaultTable = "CryptoRatesHeartbeatTimeBatch"; //Table where the data needs to be written KustoWriteOptions kustoWriteOptionsHeartbeat = KustoWriteOptions.builder() .withDatabase(database).withTable(defaultTable).withBatchIntervalMs(30000)나중에 "mvn clean package"를 사용하여 프로젝트를 빌드합니다.
'sample-java/target' 폴더에서 'samples-java-1.0-SNAPSHOT-shaded.jar'이라는 JAR 파일을 찾은 다음 Flink UI에 이 JAR 파일을 업로드하고 작업을 제출합니다.
Kusto 테이블을 쿼리하여 출력 확인
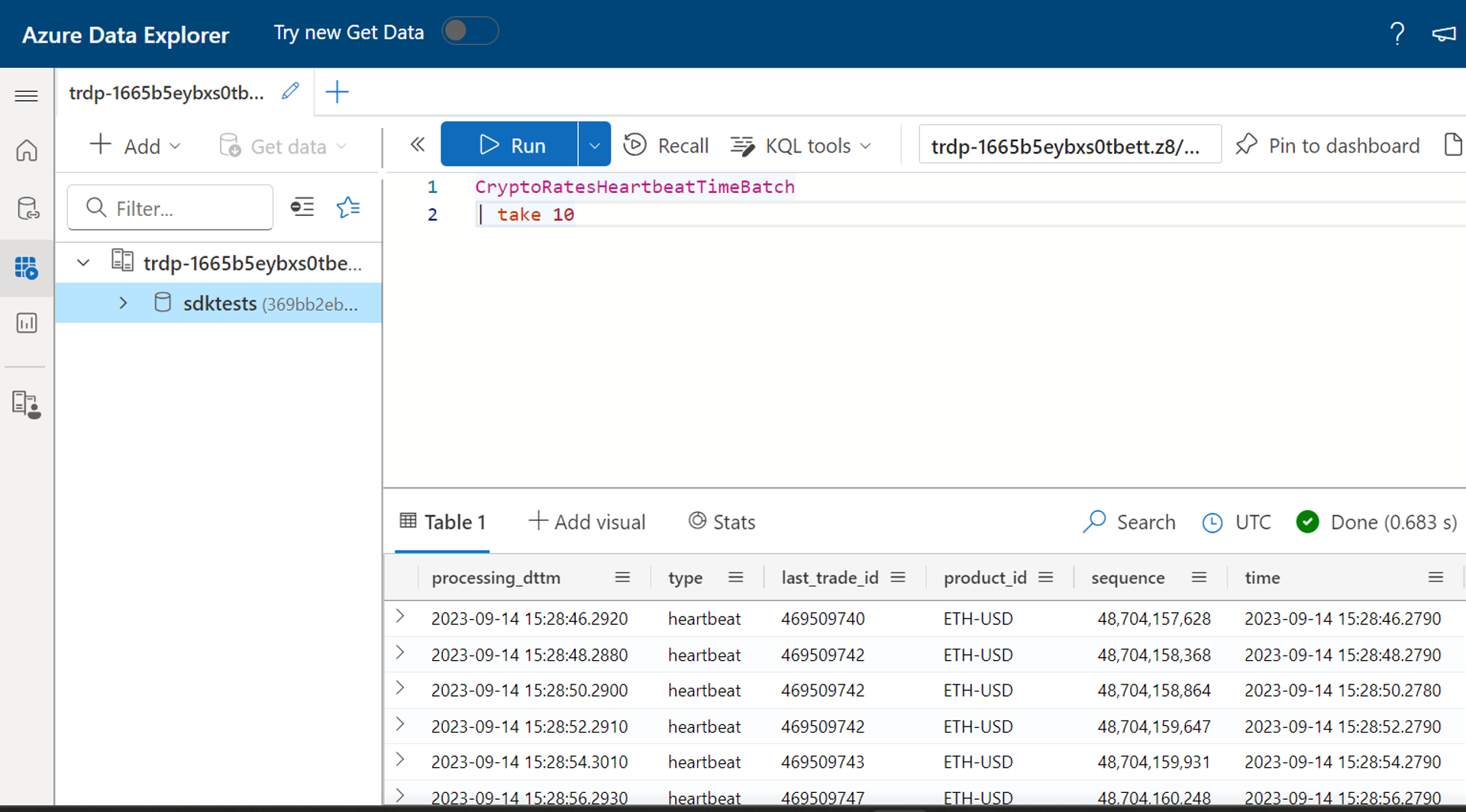
Flink에서 Kusto 테이블에 데이터를 쓰는 데 지연이 없습니다.

참조
- Apache Flink 웹 사이트
- Apache, Apache Flink, Flink 및 관련 오픈 소스 프로젝트 이름은 asF(Apache Software Foundation)의 상표입니다.