Express.js 앱은 Azure AI Speech를 사용하여 텍스트를 음성으로 변환합니다.
이 자습서에서는 Azure AI Speech 서비스를 사용하여 텍스트에서 음성으로 변환을 추가하는 기존 Express.js 앱에 Azure AI Speech를 추가합니다. 텍스트를 음성으로 변환하면 오디오를 수동으로 생성하는 데 비용을 들이지 않고 오디오를 제공할 수 있습니다.
이 자습서에서는 Azure AI Speech에서 텍스트를 음성으로 변환하는 세 가지 방법을 보여줍니다.
- 클라이언트 JavaScript가 오디오를 직접 가져옵니다.
- 서버 JavaScript가 파일에서 오디오를 가져옵니다(*.MP3)
- 서버 JavaScript가 메모리 내 arrayBuffer에서 오디오를 가져옵니다.
애플리케이션 아키텍처
이 자습서에서는 최소 Express.js 앱을 사용하고 다음의 조합을 사용하여 기능을 추가합니다.
- 텍스트에서 음성으로 변환하여 MP3 스트림을 반환하는 서버 API의 새 경로
- 정보를 입력할 수 있도록 HTML 양식의 새 경로
- JavaScript를 사용하는 새 HTML 양식은 Speech Service에 대한 클라이언트 쪽 호출을 제공합니다.
이 애플리케이션은 음성을 텍스트로 변환하는 세 가지 호출을 제공합니다.
- 첫 번째 서버 호출은 서버에 파일을 만든 다음 클라이언트에 반환합니다. 일반적으로 두 번 이상 제공되어야 한다는 것을 알고 있는 긴 텍스트 또는 텍스트에 이 값을 사용합니다.
- 두 번째 서버 호출은 짧은 기간 텍스트에 대한 것이며 클라이언트로 반환되기 전에 메모리에 보관됩니다.
- 클라이언트 호출은 SDK를 사용하여 Speech Service에 대한 직접 호출을 보여 줍니다. 서버가 없는 클라이언트 전용 애플리케이션이 있는 경우 이 호출을 수행하도록 선택할 수 있습니다.
필수 조건
Node.js LTS - 로컬 컴퓨터에 설치됩니다.
Visual Studio Code - 로컬 컴퓨터에 설치됩니다.
VS Code에 대한 Azure 앱 서비스 확장입니다(VS Code 내에서 설치됨).
Git - GitHub에 푸시하는 데 사용되며 GitHub 작업을 활성화합니다.
bash를 사용하여 Azure Cloud Shell 사용

원하는 경우 Azure CLI를 설치하여 CLI 참조 명령을 실행합니다.
- 로컬 설치를 사용하는 경우 az login 명령을 사용하여 Azure CLI로 로그인합니다. 인증 프로세스를 완료하려면 터미널에 표시되는 단계를 수행합니다. 더 많은 로그인 옵션은 Azure CLI로 로그인을 참조하세요.
- 메시지가 표시되면 처음 사용할 때 Azure CLI 확장을 설치합니다. 확장에 대한 자세한 내용은 Azure CLI에서 확장 사용을 참조하세요.
- az version을 실행하여 설치된 버전과 종속 라이브러리를 찾습니다. 최신 버전으로 업그레이드하려면 az upgrade를 실행합니다.
샘플 Express.js 리포지토리 다운로드
git을 사용하여 Express.js 샘플 리포지토리를 로컬 컴퓨터에 복제합니다.
git clone https://github.com/Azure-Samples/js-e2e-express-server샘플의 새 디렉터리로 변경합니다.
cd js-e2e-express-serverVisual Studio Code에서 프로젝트를 엽니다.
code .Visual Studio Code에서 새 터미널을 열고 프로젝트 종속성을 설치합니다.
npm install
JavaScript용 Azure AI Speech SDK 설치
Visual Studio Code 터미널에서 Azure AI Speech SDK를 설치합니다.
npm install microsoft-cognitiveservices-speech-sdk
Express.js 앱용 음성 모듈 만들기
Speech SDK를 Express.js 애플리케이션에 통합하려면 폴더에
src파일을azure-cognitiveservices-speech.js만듭니다.다음 코드를 추가하여 종속성을 끌어오고 텍스트를 음성으로 변환하는 함수를 만듭니다.
// azure-cognitiveservices-speech.js const sdk = require('microsoft-cognitiveservices-speech-sdk'); const { Buffer } = require('buffer'); const { PassThrough } = require('stream'); const fs = require('fs'); /** * Node.js server code to convert text to speech * @returns stream * @param {*} key your resource key * @param {*} region your resource region * @param {*} text text to convert to audio/speech * @param {*} filename optional - best for long text - temp file for converted speech/audio */ const textToSpeech = async (key, region, text, filename)=> { // convert callback function to promise return new Promise((resolve, reject) => { const speechConfig = sdk.SpeechConfig.fromSubscription(key, region); speechConfig.speechSynthesisOutputFormat = 5; // mp3 let audioConfig = null; if (filename) { audioConfig = sdk.AudioConfig.fromAudioFileOutput(filename); } const synthesizer = new sdk.SpeechSynthesizer(speechConfig, audioConfig); synthesizer.speakTextAsync( text, result => { const { audioData } = result; synthesizer.close(); if (filename) { // return stream from file const audioFile = fs.createReadStream(filename); resolve(audioFile); } else { // return stream from memory const bufferStream = new PassThrough(); bufferStream.end(Buffer.from(audioData)); resolve(bufferStream); } }, error => { synthesizer.close(); reject(error); }); }); }; module.exports = { textToSpeech };- 매개 변수 - 파일이 SDK, 스트림, 버퍼 및 파일 시스템(fs)을 사용하기 위한 종속성을 가져옵니다.
textToSpeech함수는 4개의 인수를 사용합니다. 로컬 경로를 가진 파일 이름이 전송되면 텍스트가 오디오 파일로 변환됩니다. 파일 이름이 전송되지 않으면 메모리 내 오디오 스트림이 생성됩니다. - Speech SDK 메서드 - Speech SDK 메서드 synthesizer.speakTextAsync는 수신한 구성에 따라 서로 다른 형식을 반환합니다.
메서드는 메서드가 수행하도록 요청된 내용에 따라 다른 결과를 반환합니다.
- 파일 만들기
- 메모리 내 스트림을 버퍼 배열로 만들기
- 오디오 형식 - 선택한 오디오 형식은 MP3이지만 다른 오디오 구성 방법과 함께 다른 형식이 있습니다.
로컬 메서드인
textToSpeech는 SDK 콜백 함수를 래핑하고 프라미스로 변환합니다.- 매개 변수 - 파일이 SDK, 스트림, 버퍼 및 파일 시스템(fs)을 사용하기 위한 종속성을 가져옵니다.
Express.js 앱에 대한 새 경로 만들기
src/server.js파일을 엽니다.모듈을
azure-cognitiveservices-speech.js파일 맨 위에 종속성으로 추가합니다.const { textToSpeech } = require('./azure-cognitiveservices-speech');자습서의 이전 섹션에서 만든 textToSpeech 메서드를 호출하는 새 API 경로를 추가합니다. 경로 후에 이 코드를 추가합니다
/api/hello.// creates a temp file on server, the streams to client /* eslint-disable no-unused-vars */ app.get('/text-to-speech', async (req, res, next) => { const { key, region, phrase, file } = req.query; if (!key || !region || !phrase) res.status(404).send('Invalid query string'); let fileName = null; // stream from file or memory if (file && file === true) { fileName = `./temp/stream-from-file-${timeStamp()}.mp3`; } const audioStream = await textToSpeech(key, region, phrase, fileName); res.set({ 'Content-Type': 'audio/mpeg', 'Transfer-Encoding': 'chunked' }); audioStream.pipe(res); });이 메서드는 쿼리 문자열에서 메서드에
textToSpeech대한 필수 및 선택적 매개 변수를 사용합니다. 파일을 만들어야 하는 경우 고유한 파일 이름이 개발됩니다. 메서드는textToSpeech비동기적으로 호출되고 결과를 응답(res) 개체로 파이프합니다.
양식으로 클라이언트 웹 페이지 업데이트
필수 매개 변수를 수집하는 양식을 사용하여 클라이언트 HTML 웹 페이지를 업데이트합니다. 선택적 매개 변수는 사용자가 선택하는 오디오 컨트롤에 따라 전달됩니다. 이 자습서에서는 클라이언트에서 Azure Speech Service를 호출하는 메커니즘을 제공하므로 해당 JavaScript도 제공됩니다.
/public/client.html 파일을 열고 해당 내용을 다음으로 바꿉니다.
<!DOCTYPE html>
<html lang="en">
<head>
<title>Microsoft Cognitive Services Demo</title>
<meta charset="utf-8" />
</head>
<body>
<div id="content" style="display:none">
<h1 style="font-weight:500;">Microsoft Cognitive Services Speech </h1>
<h2>npm: microsoft-cognitiveservices-speech-sdk</h2>
<table width="100%">
<tr>
<td></td>
<td>
<a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/get-started" target="_blank">Azure
Cognitive Services Speech Documentation</a>
</td>
</tr>
<tr>
<td align="right">Your Speech Resource Key</td>
<td>
<input id="resourceKey" type="text" size="40" placeholder="Your resource key (32 characters)" value=""
onblur="updateSrc()">
</tr>
<tr>
<td align="right">Your Speech Resource region</td>
<td>
<input id="resourceRegion" type="text" size="40" placeholder="Your resource region" value="eastus"
onblur="updateSrc()">
</td>
</tr>
<tr>
<td align="right" valign="top">Input Text (max 255 char)</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:50px" maxlength="255"
onblur="updateSrc()">all good men must come to the aid</textarea></td>
</tr>
<tr>
<td align="right">
Stream directly from Azure Cognitive Services
</td>
<td>
<div>
<button id="clientAudioAzure" onclick="getSpeechFromAzure()">Get directly from Azure</button>
</div>
</td>
</tr>
<tr>
<td align="right">
Stream audio from file on server</td>
<td>
<audio id="serverAudioFile" controls preload="none" onerror="DisplayError()">
</audio>
</td>
</tr>
<tr>
<td align="right">Stream audio from buffer on server</td>
<td>
<audio id="serverAudioStream" controls preload="none" onerror="DisplayError()">
</audio>
</td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script
src="https://cdn.jsdelivr.net/npm/microsoft-cognitiveservices-speech-sdk@latest/distrib/browser/microsoft.cognitiveservices.speech.sdk.bundle-min.js">
</script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var resultDiv;
// subscription key and region for speech services.
var resourceKey = null;
var resourceRegion = "eastus";
var authorizationToken;
var SpeechSDK;
var synthesizer;
var phrase = "all good men must come to the aid"
var queryString = null;
var audioType = "audio/mpeg";
var serverSrc = "/text-to-speech";
document.getElementById('serverAudioStream').disabled = true;
document.getElementById('serverAudioFile').disabled = true;
document.getElementById('clientAudioAzure').disabled = true;
// update src URL query string for Express.js server
function updateSrc() {
// input values
resourceKey = document.getElementById('resourceKey').value.trim();
resourceRegion = document.getElementById('resourceRegion').value.trim();
phrase = document.getElementById('phraseDiv').value.trim();
// server control - by file
var serverAudioFileControl = document.getElementById('serverAudioFile');
queryString += `%file=true`;
const fileQueryString = `file=true®ion=${resourceRegion}&key=${resourceKey}&phrase=${phrase}`;
serverAudioFileControl.src = `${serverSrc}?${fileQueryString}`;
console.log(serverAudioFileControl.src)
serverAudioFileControl.type = "audio/mpeg";
serverAudioFileControl.disabled = false;
// server control - by stream
var serverAudioStreamControl = document.getElementById('serverAudioStream');
const streamQueryString = `region=${resourceRegion}&key=${resourceKey}&phrase=${phrase}`;
serverAudioStreamControl.src = `${serverSrc}?${streamQueryString}`;
console.log(serverAudioStreamControl.src)
serverAudioStreamControl.type = "audio/mpeg";
serverAudioStreamControl.disabled = false;
// client control
var clientAudioAzureControl = document.getElementById('clientAudioAzure');
clientAudioAzureControl.disabled = false;
}
function DisplayError(error) {
window.alert(JSON.stringify(error));
}
// Client-side request directly to Azure Cognitive Services
function getSpeechFromAzure() {
// authorization for Speech service
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(resourceKey, resourceRegion);
// new Speech object
synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig);
synthesizer.speakTextAsync(
phrase,
function (result) {
// Success function
// display status
if (result.reason === SpeechSDK.ResultReason.SynthesizingAudioCompleted) {
// load client-side audio control from Azure response
audioElement = document.getElementById("clientAudioAzure");
const blob = new Blob([result.audioData], { type: "audio/mpeg" });
const url = window.URL.createObjectURL(blob);
} else if (result.reason === SpeechSDK.ResultReason.Canceled) {
// display Error
throw (result.errorDetails);
}
// clean up
synthesizer.close();
synthesizer = undefined;
},
function (err) {
// Error function
throw (err);
audioElement = document.getElementById("audioControl");
audioElement.disabled = true;
// clean up
synthesizer.close();
synthesizer = undefined;
});
}
// Initialization
document.addEventListener("DOMContentLoaded", function () {
var clientAudioAzureControl = document.getElementById("clientAudioAzure");
var resultDiv = document.getElementById("resultDiv");
resourceKey = document.getElementById('resourceKey').value;
resourceRegion = document.getElementById('resourceRegion').value;
phrase = document.getElementById('phraseDiv').value;
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
clientAudioAzure.disabled = false;
document.getElementById('content').style.display = 'block';
}
});
</script>
</body>
</html>
파일의 강조 표시된 줄:
- 74줄: Azure Speech SDK는 사이트를 사용하여
cdn.jsdelivr.netNPM 패키지를 배달하여 클라이언트 라이브러리로 끌어옵니다. - 줄 102: 메서드는
updateSrc키, 지역 및 텍스트를 포함한 쿼리 문자열을 사용하여 오디오 컨트롤의srcURL을 업데이트합니다. - 줄 137: 사용자가 단추를 선택하면
Get directly from Azure웹 페이지가 클라이언트 페이지에서 Azure로 직접 호출하고 결과를 처리합니다.
Azure AI 음성 리소스 만들기
Azure Cloud Shell에서 Azure CLI 명령을 사용하여 Speech 리소스를 만듭니다.
Azure Cloud Shell에 로그인합니다. 이렇게 하려면 유효한 Azure 구독에 대한 권한이 있는 사용자 계정으로 브라우저에 인증해야 합니다.
Speech 리소스에 대한 리소스 그룹을 만듭니다.
az group create \ --location eastus \ --name tutorial-resource-group-eastus리소스 그룹에 Speech 리소스를 만듭니다.
az cognitiveservices account create \ --kind SpeechServices \ --location eastus \ --name tutorial-speech \ --resource-group tutorial-resource-group-eastus \ --sku F0이 명령은 사용 가능 음성 리소스만 이미 만들어진 경우 실패합니다.
명령을 사용하여 새 Speech 리소스의 키 값을 가져옵니다.
az cognitiveservices account keys list \ --name tutorial-speech \ --resource-group tutorial-resource-group-eastus \ --output table두 키 중 하나를 복사합니다.
키를 Express 앱의 웹 양식에 붙여넣어 Azure Speech Service에 인증합니다.
Express.js 앱을 실행하여 텍스트를 음성으로 변환
다음 bash 명령을 사용하여 앱을 시작합니다.
npm start브라우저에서 웹앱을 엽니다.
http://localhost:3000강조 표시된 텍스트 상자에 Speech 키를 붙여넣습니다.
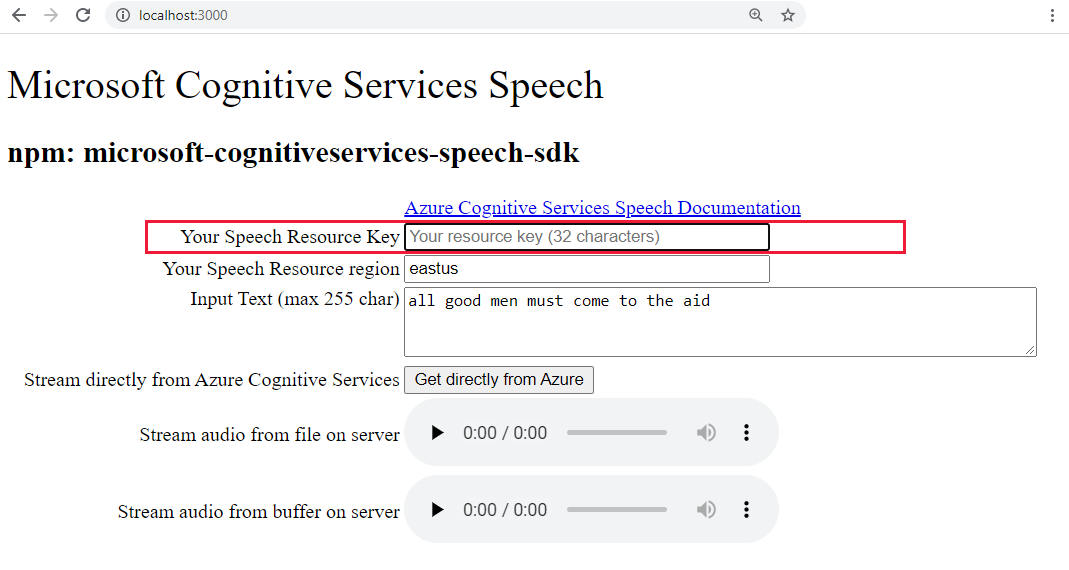
필요에 따라 텍스트를 새 항목으로 변경합니다.
세 개의 단추 중 하나를 선택하여 오디오 형식으로 변환을 시작합니다.
- Azure에서 직접 가져오기 - Azure에 대한 클라이언트 쪽 호출
- 파일의 오디오에 대한 오디오 컨트롤
- 버퍼의 오디오에 대한 오디오 컨트롤
컨트롤을 선택한 후 오디오가 재생되기 전까지 약간의 지연이 발생할 수 있습니다.
Visual Studio Code에서 새 Azure 앱 서비스 만들기
명령 팔레트(Ctrl+Shift+P)에서 "웹 만들기"를 입력하고 Azure 앱 서비스를 선택합니다. 새 웹앱 만들기... 고급. 고급 명령을 사용하여 Linux 기본값을 사용하는 대신 리소스 그룹, App Service 계획 및 운영 체제를 포함한 배포를 완전히 제어할 수 있습니다.
프롬프트에 다음과 같이 응답합니다.
- 구독 계정을 선택합니다.
- 전역 적으로 고유한 이름 (예: )
my-text-to-speech-app을 입력합니다.- 모든 Azure에서 고유한 이름을 입력합니다. 영숫자 문자('A-Z', 'a-z', '0-9') 및 하이픈('-') 사용
- 리소스 그룹에
tutorial-resource-group-eastus를 선택합니다. - 포함
Node되는 버전의 런타임 스택을LTS선택합니다. - Linux 운영 체제를 선택합니다.
- 새 App Service 계획 만들기를 선택하고 다음과 같은
my-text-to-speech-app-plan이름을 제공합니다. - F1 무료 가격 책정 계층을 선택합니다. 구독에 무료 웹앱이 이미 있는 경우 계층을
Basic선택합니다. - Application Insights 리소스에 대해 지금 건너뛰기를 선택합니다.
eastus위치를 선택합니다.
잠시 후 Visual Studio Code는 만들기가 완료되었다는 것을 알 수 있습니다. X 단추를 사용하여 알림을 닫습니다.
Visual Studio Code에서 원격 App Service에 로컬 Express.js 앱 배포
웹앱을 사용하여 로컬 컴퓨터에서 코드를 배포합니다. Azure 아이콘을 선택하여 Azure App Service 탐색기를 열고, 구독 노드를 펼치고, 마우스 오른쪽 단추로 방금 만든 웹앱 이름을 클릭하고, 웹앱에 배포를 선택합니다.
배포 프롬프트가 있는 경우 Express.js 앱의 루트 폴더를 선택하고 구독 계정을 다시 선택한 다음, 이전에 만든 웹앱
my-text-to-speech-app의 이름을 선택합니다.Linux에 배포할 때 실행하라는 메시지가 표시되면 대상 서버에서 실행
npm installnpm install되도록 구성을 업데이트하라는 메시지가 표시되면 예를 선택합니다.
배포가 완료되면 프롬프트에서 웹 사이트 찾아보기를 선택하여 새로 배포된 웹앱을 봅니다.
(선택 사항): 코드 파일을 변경한 다음, Azure 앱 서비스 확장에서 웹앱에 배포를 사용하여 웹앱을 업데이트할 수 있습니다.
Visual Studio Code에서 원격 서비스 로그 스트림
실행 중인 앱에서 console.log에 대한 호출을 통해 생성한 출력을 보거나 추적합니다. 이 출력은 Visual Studio Code의 출력 창에 나타납니다.
Azure 앱 Service 탐색기에서 새 앱 노드를 마우스 오른쪽 단추로 클릭하고 스트리밍 로그 시작을 선택합니다.
Starting Live Log Stream ---
브라우저에서 페이지를 몇 번 새로 고치면 로그 출력이 추가로 표시됩니다.
리소스 그룹을 제거하여 리소스 정리
이 자습서를 완료한 후에는 리소스를 포함하는 리소스 그룹을 제거하여 더 이상 사용량에 대한 요금이 청구되지 않도록 해야 합니다.
Azure Cloud Shell에서 Azure CLI 명령을 사용하여 리소스 그룹을 삭제합니다.
az group delete --name tutorial-resource-group-eastus -y
이 명령은 몇 분 정도 걸릴 수 있습니다.