자습서: 고가용성 및 재해 복구를 사용하여 Oracle WebLogic Server를 Azure Virtual Machines로 마이그레이션
이 자습서에서는 Azure VM(Virtual Machines)에서 Oracle WLS(WebLogic Server)를 사용하여 Java용 HA/DR(고가용성 및 재해 복구)을 구현하는 간단하고 효과적인 방법을 보여 줍니다. 이 솔루션은 WLS에서 실행되는 간단한 데이터베이스 기반 Jakarta EE 애플리케이션을 사용하여 RTO(복구 시간 목표) 및 RPO(복구 지점 목표)를 달성하는 방법을 보여 줍니다. HA/DR은 여러 가지 가능한 솔루션을 갖춘 복잡한 주제입니다. 최상의 솔루션은 고유한 요구 사항에 따라 달라집니다. HA/DR을 구현하는 다른 방법은 이 문서의 끝에 있는 리소스를 참조하세요.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Azure 최적화 모범 사례를 사용하여 고가용성 및 재해 복구를 달성합니다.
- 쌍을 이루는 지역에서 Microsoft Azure SQL Database 장애 조치(failover) 그룹을 설정합니다.
- Azure VM에서 쌍을 이루는 WLS 클러스터를 설정합니다.
- Azure Traffic Manager를 설정합니다.
- 고가용성 및 재해 복구를 위해 WLS 클러스터를 구성합니다.
- 기본에서 보조로 장애 조치(failover)를 테스트합니다.
다음 다이어그램에서는 빌드하는 아키텍처를 보여 줍니다.

Azure Traffic Manager는 지역 상태를 확인하고 그에 따라 트래픽을 애플리케이션 계층으로 라우팅합니다. 주 지역과 보조 지역 모두 WLS 클러스터의 전체 배포가 있습니다. 그러나 주 지역만 사용자의 네트워크 요청을 적극적으로 서비스합니다. 보조 지역은 수동이며 주 지역에서 서비스 중단이 발생하는 경우에만 트래픽을 수신하도록 활성화됩니다. Azure Traffic Manager는 Azure 애플리케이션 Gateway의 상태 검사 기능을 사용하여 이 조건부 라우팅을 구현합니다. 주 WLS 클러스터가 실행 중이며 보조 클러스터가 종료됩니다. 애플리케이션 계층의 지역 장애 조치(failover) RTO는 VM을 시작하고 보조 WLS 클러스터를 실행하는 시간에 따라 달라집니다. 데이터가 Azure SQL Database 장애 조치(failover) 그룹에 유지되고 복제되기 때문에 RPO는 Azure SQL Database에 따라 달라집니다.
데이터베이스 계층은 주 서버와 보조 서버가 있는 Azure SQL Database 장애 조치(failover) 그룹으로 구성됩니다. 주 서버는 활성 읽기/쓰기 모드이며 주 WLS 클러스터에 연결됩니다. 보조 서버는 수동 준비 전용 모드이며 보조 WLS 클러스터에 연결됩니다. 지역 장애 조치(failover)는 그룹의 모든 보조 데이터베이스를 주 역할로 전환합니다. Azure SQL Database의 지역 장애 조치(failover) RPO 및 RTO는 비즈니스 연속성 개요를 참조 하세요.
이 문서는 해당 서비스의 HA(고가용성) 기능을 사용하므로 Azure SQL Database 서비스를 사용하여 작성되었습니다. 다른 데이터베이스 선택도 가능하지만 선택한 데이터베이스의 HA 기능을 고려해야 합니다. 복제를 위해 데이터 원본의 구성을 최적화하는 방법에 대한 자세한 내용은 Oracle Fusion 미들웨어 활성-수동 배포에 대한 데이터 원본 구성을 참조하세요.
필수 구성 요소
- Azure 구독 Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
- 구독에
Owner역할 또는Contributor역할과User Access Administrator역할이 있는지 확인합니다. Azure Portal을 사용하여 Azure 역할 할당 나열의 단계에 따라 할당을 확인할 수 있습니다. - Windows, Linux 또는 macOS가 설치된 로컬 컴퓨터를 준비합니다.
- Git을 설치하고 설정합니다.
- Java SE 구현 버전 17 이상을 설치합니다(예: OpenJDK의 Microsoft 빌드).
- Maven 버전 3.9.3 이상을 설치합니다.
쌍을 이루는 지역에서 Azure SQL Database 장애 조치(failover) 그룹 설정
이 섹션에서는 WLS 클러스터 및 앱과 함께 사용할 쌍을 이루는 지역에 Azure SQL Database 장애 조치(failover) 그룹을 만듭니다. 이후 섹션에서는 세션 데이터 및 TLOG(트랜잭션 로그) 데이터를 이 데이터베이스에 저장하도록 WLS를 구성합니다. 이 방법은 Oracle의 MAA(최대 가용성 아키텍처)와 일치합니다. 이 지침은 MAA에 대한 Azure 적응을 제공합니다. MAA에 대한 자세한 내용은 Oracle 최대 가용성 아키텍처를 참조 하세요.
먼저 빠른 시작: 단일 데이터베이스 만들기 - Azure SQL Database의 Azure Portal 단계에 따라 기본 Azure SQL Database를 만듭니다. "리소스 정리" 섹션을 포함하지만 포함하지 않는 단계를 수행합니다. 문서를 진행할 때 다음 지침을 사용한 다음, Azure SQL Database를 만들고 구성한 후 이 문서로 돌아갑니다.
단일 데이터베이스 만들기 섹션에 도달하면 다음 단계를 사용합니다.
- 새 리소스 그룹을 만들기 위한 4단계에서 리소스 그룹 이름 값(예: myResourceGroup)을 따로 저장합니다.
- 데이터베이스 이름에 대한 5단계에서 데이터베이스 이름 값(예: mySampleDatabase)을 따로 저장합니다.
- 서버를 만들기 위한 6단계에서 다음 단계를 사용합니다.
- 고유한 서버 이름(예 : sqlserverprimary-ejb120623)을 따로 저장합니다.
- 위치의 경우 (미국) 미국 동부를 선택합니다.
- 인증 방법의 경우 SQL 인증 사용을 선택합니다.
- 서버 관리자 로그인 값(예: azureuser)을 따로 저장합니다.
- 암호 값을 따로 저장합니다.
- 8단계에서 워크로드 환경의 경우 개발을 선택합니다. 설명을 살펴보고 워크로드에 대한 다른 옵션을 고려합니다.
- 11단계에서 Backup 스토리지 중복성에 대해 로컬 중복 백업 스토리지를 선택합니다. 백업에 대한 다른 옵션을 고려합니다. 자세한 내용은 Azure SQL Database에서 자동화된 백업의 Backup 스토리지 중복성 섹션을 참조하세요.
- 14단계의 방화벽 규칙 구성에서 Azure 서비스 및 리소스가 이 서버에 액세스하도록 허용하려면 [예]를 선택합니다.
데이터베이스 쿼리 섹션에 도달하면 다음 단계를 사용합니다.
3단계에서 로그인할 SQL 인증 서버 관리자 로그인 정보를 입력합니다.
참고 항목
IP 주소가 'xx.xx.xx.xx.xx'인 클라이언트와 유사한 오류 메시지와 함께 로그인이 실패하면 오류 메시지 끝에 있는 서버<에서> 허용 목록 IP xx.xx.xx.xx.xx를 선택합니다. 서버 방화벽 규칙 업데이트가 완료될 때까지 기다린 다음 확인을 다시 선택합니다.
5단계에서 샘플 쿼리를 실행한 후 편집기를 지우고 테이블을 만듭니다.
다음 쿼리를 입력하여 TLOG에 대한 스키마를 만듭니다.
create table TLOG_msp1_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table TLOG_msp2_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table TLOG_msp3_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table wl_servlet_sessions (wl_id VARCHAR(100) NOT NULL, wl_context_path VARCHAR(100) NOT NULL, wl_is_new CHAR(1), wl_create_time DECIMAL(20), wl_is_valid CHAR(1), wl_session_values VARBINARY(MAX), wl_access_time DECIMAL(20), wl_max_inactive_interval INTEGER, PRIMARY KEY (wl_id, wl_context_path));
성공적으로 실행되면 쿼리 성공: 영향을 받은 행 수: 0 메시지가 표시됩니다.
이러한 데이터베이스 테이블은 WLS 클러스터 및 앱에 대한 TLOG(트랜잭션 로그) 및 세션 데이터를 저장하는 데 사용됩니다. 자세한 내용은 JDBC TLOG 저장소 사용 및 영구 스토리지용 데이터베이스 사용(JDBC 지속성)을 참조하세요.
다음으로, Azure SQL Database에 대한 장애 조치(failover) 그룹 구성의 Azure Portal 단계에 따라 Azure SQL Database 장애 조치(failover) 그룹을 만듭니다. 장애 조치(failover) 그룹 만들기 및 테스트 계획된 장애조치 섹션만 있으면 됩니다. 문서를 진행하면서 다음 단계를 수행한 다음, Azure SQL Database 장애 조치(failover) 그룹을 만들고 구성한 후 이 문서로 돌아갑니다.
장애 조치(failover) 그룹 만들기 섹션에 도달하면 다음 단계를 사용합니다.
- 장애 조치(failover) 그룹을 만들기 위한 5단계에서 새 보조 서버를 만드는 옵션을 선택한 다음, 다음 단계를 사용합니다.
- 장애 조치(failover) 그룹 이름(예 : failovergroupname-ejb120623)을 입력하고 저장합니다.
- 고유한 서버 이름(예 : sqlserversecondary-ejb120623)을 입력하고 저장합니다.
- 주 서버와 동일한 서버 관리자 및 암호를 입력합니다.
- 위치의 경우 주 데이터베이스에 사용한 지역과 다른 지역을 선택합니다.
- Azure 서비스에서 서버에 액세스하도록 허용이 선택되어 있는지 확인합니다.
- 그룹 내의 데이터베이스를 구성하기 위한 5단계에서 주 서버에서 만든 데이터베이스(예: mySampleDatabase)를 선택합니다.
- 장애 조치(failover) 그룹을 만들기 위한 5단계에서 새 보조 서버를 만드는 옵션을 선택한 다음, 다음 단계를 사용합니다.
테스트 계획된 장애조치 섹션의 모든 단계를 완료한 후 장애 조치(failover) 그룹 페이지를 열어 두고 나중에 WLS 클러스터의 장애 조치(failover) 테스트에 사용합니다.
참고 항목
이 문서에서는 이 문서에 중점을 둔 HA/DR 설정이 이미 매우 복잡하기 때문에 단순성을 위해 SQL 인증을 사용하여 Azure SQL Database 단일 데이터베이스를 만드는 방법을 안내합니다. 더 안전한 방법은 데이터베이스 서버 연결을 인증하기 위해 Azure SQL
Azure VM에서 쌍을 이루는 WLS 클러스터 설정
이 섹션에서는 Azure VM의 Oracle WebLogic Server 클러스터 제품을 사용하여 Azure VM에 두 개의 WLS 클러스터를 만듭니다 . 미국 동부의 클러스터는 주 클러스터이며 나중에 활성 클러스터로 구성됩니다. 미국 서부의 클러스터는 보조 클러스터이며 나중에 수동 클러스터로 구성됩니다.
기본 WLS 클러스터 설정
먼저 브라우저에서 Azure VM 제품에서 Oracle WebLogic Server 클러스터를 열고 만들기를 선택합니다. 제품의 기본 창이 표시됩니다.
다음 단계를 사용하여 기본 사항 창을 작성 합니다 .
- 구독에 대해 표시된 값이 필수 구성 요소 섹션에 나열된 역할이 있는 값과 동일한지 확인합니다.
- 리소스 그룹 필드에서 새로 만들기를 선택하고 리소스 그룹에 대한 고유 값(예: wls-cluster-eastus-ejb120623)을 입력합니다.
- 인스턴스 세부 정보에서 지역에 대해 미국 동부를 선택합니다.
- Virtual Machines 및 WebLogic에 대한 자격 증명 아래에서 각각 VM 및 WebLogic 관리자의 관리자 계정에 대한 암호를 제공합니다. WebLogic 관리자의 사용자 이름과 암호를 따로 저장합니다. 보안을 강화하려면 SSH 공개 키 VM 인증 유형으로 사용하는 것이 좋습니다.
- 다른 필드의 기본값을 그대로 둡니다.
- 다음을 선택하여 TLS/SSL 구성 창으로 이동합니다.

TLS/SSL 구성 창에 기본값을 그대로 두고 다음을 선택하여 Azure 애플리케이션 게이트웨이 창으로 이동한 다음, 다음 단계를 사용합니다.
- Azure 애플리케이션 게이트웨이에 연결하려면 [예]를 선택합니다.
- 원하는 TLS/SSL 인증서 선택 옵션의 경우 자체 서명된 인증서 생성을 선택합니다.
- 다음을 선택하여 네트워킹 창으로 이동합니다.

네트워킹 창에 기본값으로 미리 채워진 모든 필드가 표시됩니다. 다음 단계를 사용하여 네트워크 구성을 저장합니다.
가상 네트워크 편집을 선택합니다. 가상 네트워크의 주소 공간(예 : 10.1.4.0/23)을 따로 저장합니다.

서브넷을 편집하려면 선택합니다
wls-subnet. 서브넷 세부 정보에서 시작 주소와 서브넷 크기(예: 10.1.5.0 및 /28)를 따로 저장합니다.
수정하는 경우 변경 내용을 저장합니다.
네트워킹 창으로 돌아갑니다.
다음을 선택하여 데이터베이스 창으로 이동합니다.


다음 단계에서는 데이터베이스 창을 채우는 방법을 보여줍니다.
- 데이터베이스에 연결하려면 [예]를 선택합니다.
- 데이터베이스 유형 선택에서 Microsoft SQL Server(암호 없는 연결 지원)를 선택합니다.
- JNDI 이름에 jdbc/WebLogicCafeDB를 입력합니다.
- DataSource 연결 문자열의 경우 자리 표시자를 주 SQL Database의 이전 섹션에서 저장한 값(예: jdbc:sqlserver://sqlserverprimary-ejb120623.database.windows.net:1433;)으로 바꿉니다. database=mySampleDatabase.
- 전역 트랜잭션 프로토콜의 경우 없음을 선택합니다.
- 데이터베이스 사용자 이름의 경우 자리 표시자를 기본 SQL Database의 이전 섹션에서 저장한 값(예: azureuser@sqlserverprimary-ejb120623)으로 바꿉니다.
- 데이터베이스 암호에 대해 이전에 저장한 서버 관리자 로그인 암호를 입력합니다. 암호 확인에 대해 동일한 값을 입력합니다.
- 다른 필드의 기본값을 그대로 둡니다.
- 검토 + 만들기를 선택합니다.
- 최종 유효성 검사 실행이 완료될 때까지 기다린 다음 만들기를 선택합니다.

참고 항목
이 문서에서는 이 문서에 중점을 둔 HA/DR 설정이 이미 매우 복잡하기 때문에 단순성을 위해 SQL 인증을 사용하여 Azure SQL Database에 연결하는 방법을 안내합니다. 더 안전한 방법은 데이터베이스 서버 연결을 인증하기 위해 Azure SQL
잠시 후 배포가 진행 중인 배포 페이지가 표시됩니다.
참고 항목
최종 유효성 검사를 실행하는 동안 문제가 표시되는 경우 문제를 해결한 후 다시 시도하세요.
선택한 지역의 네트워크 조건 및 기타 활동에 따라 배포를 완료하는 데 최대 50분이 걸릴 수 있습니다. 그런 다음 배포가 완료됨이라는 텍스트가 배포 페이지에 표시됩니다.
그 동안 보조 WLS 클러스터를 병렬로 설정할 수 있습니다.
보조 WLS 클러스터 설정
다음 차이점을 제외하고 주 WLS 클러스터를 설정하여 미국 서부 지역에 보조 WLS 클러스터를 설정하는 섹션과 동일한 단계를 수행합니다.
기본 창에서 다음 단계를 사용합니다.
- 리소스 그룹 필드에서 새로 만들기를 선택하고 리소스 그룹에 대한 다른 고유 값(예: wls-cluster-westtus-ejb120623)을 입력합니다.
- 인스턴스 세부 정보에서 지역에 대해 미국 서부를 선택합니다.
네트워킹 창에서 다음 단계를 사용합니다.
가상 네트워크 편집의 경우 기본 WLS 클러스터와 동일한 가상 네트워크 주소 공간(예: 10.1.4.0/23)을 입력합니다.
참고 항목
주소 공간 '10.1.4.0/23(10.1.4.0 - 10.1.5.255)'과 유사한 경고 메시지가 표시됩니다. 가상 네트워크 'wls-vnet'의 주소 공간 '10.1.4.0/23(10.1.4.0 - 10.1.5.255)'이 있는 경우 주소 공간이 겹치는 가상 네트워크는 피어될 수 없습니다. 이러한 가상 네트워크를 피어로 연결하려면 주소 공간 '10.1.4.0/23(10.1.4.0 - 10.1.5.255)'을 변경합니다. 동일한 네트워크 구성을 사용하는 두 개의 WLS 클러스터가 필요하기 때문에 이 메시지를 무시할 수 있습니다.
의 경우
wls-subnet기본 WLS 클러스터와 동일한 시작 주소 및 서브넷 크기를 입력합니다(예 : 10.1.5.0 및 /28).
데이터베이스 창에서 다음 단계를 사용합니다.
- DataSource 연결 문자열의 경우 자리 표시자를 보조 SQL Database의 이전 섹션에서 저장한 값(예: jdbc:sqlserver://sqlserversecondary-ejb120623.database.windows.net:1433)으로 바꿉니다. database=mySampleDatabase.
- 데이터베이스 사용자 이름의 경우 자리 표시자를 보조 SQL Database의 이전 섹션에서 저장한 값(예: azureuser@sqlserversecondary-ejb120623)으로 바꿉니다.
두 클러스터에 대한 네트워크 설정 미러링
장애 조치(failover) 후 보조 WLS 클러스터에서 보류 중인 트랜잭션을 재개하는 단계에서 WLS는 TLOG 저장소의 소유권을 확인합니다. 검사를 성공적으로 통과하려면 보조 클러스터의 모든 관리되는 서버에 주 클러스터와 동일한 개인 IP 주소가 있어야 합니다.
이 섹션에서는 주 클러스터에서 보조 클러스터로 네트워크 설정을 미러링하는 방법을 보여줍니다.
먼저 다음 단계를 사용하여 배포가 완료된 후 주 클러스터에 대한 네트워크 설정을 구성합니다.
배포 페이지의 개요 창에서 리소스 그룹으로 이동을 선택합니다.
네트워크 인터페이스
adminVM_NIC_with_pub_ip를 선택합니다.- 설정에서 IP 구성을 선택합니다.
-
ipconfig1를 선택합니다. - 개인 IP 주소 설정에서 할당에 대해 정적을 선택합니다. 개인 IP 주소를 따로 저장합니다.
- 저장을 선택합니다.
기본 WLS 클러스터의 리소스 그룹으로 돌아가서 네트워크 인터페이스에 대해 3단계를 반복합니다
mspVM1_NIC_with_pub_ipmspVM2_NIC_with_pub_ipmspVM3_NIC_with_pub_ip.모든 업데이트가 완료될 때까지 기다립니다. Azure Portal에서 알림 아이콘을 선택하여 상태 모니터링에 대한 알림 창을 열 수 있습니다.

기본 WLS 클러스터의 리소스 그룹으로 돌아가서 프라이빗 엔드포인트 형식의 리소스 이름을 복사합니다(예: 7e8c8bsaep). 이 이름을 사용하여 나머지 네트워크 인터페이스(예: 7e8c8bsaep.nic.c0438c1a-1936-4b62-864c-6792eec3741a)를 찾습니다. 이를 선택하고 이전 단계에 따라 개인 IP 주소를 가져옵니다.
그런 다음, 다음 단계를 사용하여 배포가 완료된 후 보조 클러스터에 대한 네트워크 설정을 구성합니다.
배포 페이지의 개요 창에서 리소스 그룹으로 이동을 선택합니다.
네트워크 인터페이스
adminVM_NIC_with_pub_ipmspVM1_NIC_with_pub_ipmspVM2_NIC_with_pub_ipmspVM3_NIC_with_pub_ip의 경우 이전 단계에 따라 개인 IP 주소 할당을 Static으로 업데이트합니다.모든 업데이트가 완료될 때까지 기다립니다.
네트워크 인터페이스
mspVM1_NIC_with_pub_ipmspVM2_NIC_with_pub_ip의 경우 이전mspVM3_NIC_with_pub_ip단계를 수행하지만 개인 IP 주소를 주 클러스터에 사용되는 것과 동일한 값으로 업데이트합니다. 네트워크 인터페이스의 현재 업데이트가 완료될 때까지 기다렸다가 다음 단계로 진행합니다.참고 항목
프라이빗 엔드포인트의 일부인 네트워크 인터페이스의 개인 IP 주소는 변경할 수 없습니다. 관리되는 서버에 대한 네트워크 인터페이스의 개인 IP 주소를 쉽게 미러링하려면 사용되지 않는 IP 주소로
adminVM_NIC_with_pub_ip개인 IP 주소를 업데이트하는 것이 좋습니다. 두 클러스터의 개인 IP 주소 할당에 따라 기본 클러스터에서도 개인 IP 주소를 업데이트해야 할 수 있습니다.
다음 표에서는 두 클러스터에 대한 네트워크 설정을 미러링하는 예제를 보여 줍니다.
| 클러스터 | 네트워크 인터페이스 | 개인 IP 주소(이전) | 개인 IP 주소(이후) | 업데이트 시퀀스 |
|---|---|---|---|---|
| 기본 | 7e8c8bsaep.nic.c0438c1a-1936-4b62-864c-6792eec3741a |
10.1.5.4 |
10.1.5.4 |
|
| 기본 | adminVM_NIC_with_pub_ip |
10.1.5.7 |
10.1.5.7 |
|
| 기본 | mspVM1_NIC_with_pub_ip |
10.1.5.5 |
10.1.5.5 |
|
| 기본 | mspVM2_NIC_with_pub_ip |
10.1.5.8 |
10.1.5.9 |
1 |
| 기본 | mspVM3_NIC_with_pub_ip |
10.1.5.6 |
10.1.5.6 |
|
| 보조 | 1696b0saep.nic.2e19bf46-9799-4acc-b64b-a2cd2f7a4ee1 |
10.1.5.8 |
10.1.5.8 |
|
| 보조 | adminVM_NIC_with_pub_ip |
10.1.5.5 |
10.1.5.4 |
4 |
| 보조 | mspVM1_NIC_with_pub_ip |
10.1.5.7 |
10.1.5.5 |
5 |
| 보조 | mspVM2_NIC_with_pub_ip |
10.1.5.6 |
10.1.5.9 |
2 |
| 보조 | mspVM3_NIC_with_pub_ip |
10.1.5.4 |
10.1.5.6 |
3 |
각 클러스터에 배포한 Azure 애플리케이션 Gateway의 백 엔드 풀로 구성된 모든 관리되는 서버에 대한 개인 IP 주소 집합을 확인합니다. 업데이트되는 경우 다음 단계를 사용하여 Azure 애플리케이션 게이트웨이 백 엔드 풀을 적절하게 업데이트합니다.
- 클러스터의 리소스 그룹을 엽니다.
- Application Gateway 형식을 사용하여 myAppGateway 리소스를 찾습니다. 저장소 계정을 선택하여 엽니다.
-
설정 섹션에서 백 엔드 풀을 선택한 다음, .를 선택합니다
myGatewayBackendPool. - 업데이트된 개인 IP 주소 또는 주소를 사용하여 백 엔드 대상 값을 변경한 다음 저장을 선택합니다. 완료될 때까지 기다립니다.
- 설정 섹션에서 상태 프로브를 선택한 다음, HTTPhealthProbe를 선택합니다.
-
상태 프로브를 추가하기 전에 백 엔드 상태를 테스트하고 테스트를 선택해야 합니다. 백 엔드 풀 의
myGatewayBackendPool값이 정상으로 표시됩니다. 그렇지 않은 경우 개인 IP 주소가 예상대로 업데이트되고 VM이 실행 중인지 확인한 다음 상태 프로브를 다시 테스트합니다. 계속하기 전에 문제를 해결하고 해결해야 합니다.
다음 예제에서는 각 클러스터에 대한 Azure 애플리케이션 게이트웨이 백 엔드 풀이 업데이트됩니다.
| 클러스터 | Azure 애플리케이션 게이트웨이 백 엔드 풀 | 백 엔드 대상(이전) | 백 엔드 대상(이후) |
|---|---|---|---|
| 기본 | myGatewayBackendPool |
(10.1.5.5, 10.1.5.8, 10.1.5.6) |
(10.1.5.5, 10.1.5.9, 10.1.5.6) |
| 보조 | myGatewayBackendPool |
(10.1.5.7, 10.1.5.6, 10.1.5.4) |
(10.1.5.5, 10.1.5.9, 10.1.5.6) |
네트워크 설정 미러링을 자동화하려면 Azure CLI를 사용하는 것이 좋습니다. 자세한 내용은 Azure CLI 시작을 참조하세요.
클러스터 배포 확인
각 클러스터에 Azure 애플리케이션 게이트웨이 및 WLS 관리 서버를 배포했습니다. Azure 애플리케이션 게이트웨이는 클러스터의 모든 관리되는 서버에 대한 부하 분산 장치 역할을 합니다. WLS 관리 서버는 클러스터 구성을 위한 웹 콘솔을 제공합니다.
다음 단계를 사용하여 각 클러스터의 Azure 애플리케이션 게이트웨이 및 WLS 관리 콘솔이 다음 단계로 이동하기 전에 작동하는지 확인합니다.
- 배포 페이지로 돌아가서 출력을 선택합니다.
- appGatewayURL 속성의 값을 복사합니다. weblogic/ready 문자열을 추가한 다음 새 브라우저 탭에서 해당 URL을 엽니다. 오류 메시지 없이 빈 페이지가 표시됩니다. 그렇지 않은 경우 계속하기 전에 문제를 해결하고 해결해야 합니다.
- adminConsole 속성 값을 복사하여 저장합니다. 새 브라우저 탭에서 엽니다. WebLogic Server 관리 콘솔의 로그인 페이지가 표시됩니다. 이전에 저장한 WebLogic 관리자의 사용자 이름과 암호를 사용하여 콘솔에 로그인합니다. 로그인할 수 없는 경우 계속하기 전에 문제를 해결하고 해결해야 합니다.
다음 단계를 사용하여 각 클러스터에 대한 Azure 애플리케이션 게이트웨이의 IP 주소를 가져옵니다. 나중에 Azure Traffic Manager를 설정할 때 이러한 값을 사용합니다.
- 클러스터가 배포된 리소스 그룹을 엽니다. 예를 들어 개요를 선택하여 배포 페이지의 개요 창으로 다시 전환합니다. 그런 다음 리소스 그룹으로 이동을 선택합니다.
- 공용 IP 주소
gwip이 있는 리소스를 찾은 다음 해당 리소스 를 선택하여 엽니다. IP 주소 필드를 찾아 값을 따로 저장합니다.
Azure Traffic Manager 설정
이 섹션에서는 전역 Azure 지역에 걸쳐 공용 애플리케이션에 트래픽을 배포하기 위한 Azure Traffic Manager를 만듭니다. 기본 엔드포인트는 주 WLS 클러스터의 Azure 애플리케이션 게이트웨이를 가리키고 보조 엔드포인트는 보조 WLS 클러스터의 Azure 애플리케이션 게이트웨이를 가리킵니다.
빠른 시작: Azure Portal을 사용하여 Traffic Manager 프로필을 만들어 Azure Traffic Manager 프로필을 만듭니다. 필수 구성 요소 섹션을 건너뜁니다. Traffic Manager 프로필 만들기, Traffic Manager 엔드포인트 추가 및 Traffic Manager 프로필 테스트 섹션만 있으면 됩니다. 다음 단계를 사용하여 이러한 섹션을 진행한 다음, Azure Traffic Manager를 만들고 구성한 후 이 문서로 돌아갑니다.
Traffic Manager 프로필만들기
섹션에 도달하면, 2단계 Traffic Manager 프로필 만들기의 다음 단계를 따르십시오.-
이름 고유한 Traffic Manager 프로필 이름(예:
tmprofile-ejb120623)을 따로 저장합니다. -
리소스 그룹 새 리소스 그룹 이름(예:
myResourceGroupTM1)을 따로 저장합니다.
-
이름 고유한 Traffic Manager 프로필 이름(예:
Traffic Manager 엔드포인트 추가 섹션 에 도달하면 다음 단계를 사용합니다.
검색 결과에서 프로필 선택 단계를 수행한 후 이 추가 작업을 수행합니다.
설정에서 구성을 선택합니다.
DNS TTL(Time to Live)의 경우 10을 입력합니다.
엔드포인트 모니터 설정에서 경로에 대해 /weblogic/ready를 입력합니다.
빠른 엔드포인트 장애 조치 설정에서 다음 값을 사용하십시오.
- 내부 검색의 경우 10을 입력합니다.
- 허용되는 오류 수의 경우 3을 입력합니다.
- 프로브 시간 제한의 경우 5입니다.
저장을 선택합니다. 완료될 때까지 기다립니다.
기본 엔드포인트
myPrimaryEndpoint추가하기 위한 4단계에서 다음 단계를 사용합니다.대상 리소스 유형의 경우 공용 IP 주소를 선택합니다.
공용 IP 주소 선택 드롭다운을 선택하고 이전에 저장한 미국 동부 WLS 클러스터에 배포된 Application Gateway의 IP 주소를 입력합니다. 일치하는 항목이 하나 표시됩니다. 공용 IP 주소에 대해 선택합니다.
장애 조치(failover) / 보조 엔드포인트
myFailoverEndpoint를 추가하기 위한 여섯 번째 단계에서는 다음 절차를 따르십시오.대상 리소스 유형의 경우 공용 IP 주소를 선택합니다.
드롭다운 목록에서 공용 IP 주소 선택을 선택한 후, 사전에 저장해 둔 미국 서부 2 WLS 클러스터에 배포된 Application Gateway의 IP 주소를 입력합니다. 일치하는 항목이 하나 표시됩니다. 공용 IP 주소에 대해 선택합니다.
잠시 기다립니다. 두 엔드포인트의 모니터 상태 값이 온라인이 될 때까지 새로 고침을 선택합니다.
Test Traffic Manager 프로필 섹션에 도달하면 다음 단계를 사용합니다.
섹션에서 DNS 이름확인합니다. 3단계에서 Traffic Manager 프로필의 DNS 이름(예:
http://tmprofile-ejb120623.trafficmanager.net)을 따로 저장합니다.섹션에서 Traffic Manager를 작동 중에 보는 작업을 따라, 다음 단계를 따르세요.
1단계와 3단계에서는 웹 브라우저에서 Traffic Manager 프로필의 DNS 이름(예: )에 /weblogic/ready
http://tmprofile-ejb120623.trafficmanager.net/weblogic/ready합니다. 오류 메시지 없이 빈 페이지가 표시됩니다.모든 단계를 완료한 후 2단계를 참조하여 기본 엔드포인트를 사용하도록 설정해야 하지만 사용 안 함으로 대체합니다. 그런 다음 엔드포인트 페이지로 돌아갑니다.
이제 Traffic Manager 프로필에 엔드포인트와 Online이 모두 사용되도록 설정되었습니다. 페이지를 열어 두고 나중에 엔드포인트 상태를 모니터링하는 데 사용합니다.
고가용성 및 재해 복구를 위해 WLS 클러스터 구성
이 섹션에서는 고가용성 및 재해 복구를 위해 WLS 클러스터를 구성합니다.
샘플 앱 준비
이 섹션에서는 장애 조치(failover) 테스트를 위해 나중에 WLS 클러스터에서 배포하고 실행하는 샘플 CRUD Java/JakartaEE 애플리케이션을 빌드하고 패키지합니다.
앱은 WebLogic Server JDBC 세션 지속성을 사용하여 HTTP 세션 데이터를 저장합니다. 데이터 원본 jdbc/WebLogicCafeDB 은 세션 데이터를 저장하여 WebLogic 서버 클러스터에서 장애 조치(failover) 및 부하 분산을 사용하도록 설정합니다. 동일한 데이터 원본에 coffee를 구성합니다.
다음 단계를 사용하여 샘플을 빌드하고 패키지합니다.
다음 명령을 사용하여 샘플 리포지토리를 복제하고 이 문서에 해당하는 태그를 확인합니다.
git clone https://github.com/Azure-Samples/azure-cafe.git cd azure-cafe git checkout 20231206메시지가
Detached HEAD표시되면 무시해도 안전합니다.다음 명령을 사용하여 샘플 디렉터리로 이동한 다음 샘플을 컴파일하고 패키지합니다.
cd weblogic-cafe mvn clean package
패키지가 성공적으로 생성되면 부모 경로에서 local-clone</azure-café/weblogic-café/target/weblogic-café.war>찾을 수 있습니다. 이 패키지가 표시되지 않으면 문제를 해결한 후 계속 진행합니다.
샘플 앱 배포
이제 다음 단계를 사용하여 기본 클러스터에서 시작하여 샘플 앱을 클러스터에 배포합니다.
- 웹 브라우저의 새 탭에서 클러스터의 adminConsole 을 엽니다. 이전에 저장한 WebLogic 관리자의 사용자 이름과 암호를 사용하여 WebLogic Server 관리 콘솔에 로그인합니다.
- 탐색 창에서 도메인 구조습니다. 배포를 선택합니다.
- 이전에 준비한 weblogic-café.war 파일을 선택합니다.
- 다음 다음>을 선택합니다. 배포 대상에 대한 클러스터
cluster1선택합니다. 다음>마침을 선택합니다. 변경 내용 활성화를 선택합니다. - 컨트롤 탭으로 전환하고 배포 테이블에서 weblogic-café 선택합니다. 모든 요청으로 시작을> 잠시 기다렸다가 배포 weblogic-cafe의 상태가 활성인지 확인할 때까지 페이지를 새로 고치세요. 모니터링 탭으로 전환하고 배포된 애플리케이션의 컨텍스트 루트가 /weblogic-café인지 확인합니다. 나중에 추가 구성에 사용할 수 있도록 WLS 관리 콘솔을 열어 두세요.
WebLogic Server 관리 콘솔에서 동일한 단계를 반복하지만 미국 서부 지역의 보조 클러스터에 대해 반복합니다.
프런트 엔드 호스트 업데이트
다음 단계를 사용하여 WLS 클러스터가 Azure Traffic Manager를 인식하도록 합니다. Azure Traffic Manager는 사용자 요청의 진입점이므로 WebLogic Server 클러스터의 프런트 호스트를 기본 클러스터에서 시작하여 Traffic Manager 프로필의 DNS 이름으로 업데이트합니다.
- WebLogic Server 관리 콘솔에 로그인했는지 확인합니다.
- 탐색 창에서 >로 이동합니다. 클러스터를 선택합니다.
- 클러스터 테이블에서 선택합니다
cluster1. - 잠금 및 HTTP 프론트엔드 호스트의
현재 설정된 값을 제거하고, 이전에 저장한 트래픽 관리자 프로필의 DNS 이름을 앞에 http:// 을(를) 제외하고 입력합니다(예:tmprofile-ejb120623.trafficmanager.net ). 변경 내용>.
WebLogic Server 관리 콘솔에서 미국 서부 지역의 보조 클러스터에 대해 동일한 단계를 반복합니다.
트랜잭션 로그 저장소 구성
다음으로, 주 클러스터부터 시작하여 모든 관리되는 클러스터 서버에 대해 JDBC 트랜잭션 로그 저장소를 구성합니다. 이 방법은 트랜잭션 로그 파일을 사용하여 트랜잭션을 복구하는 방법에 대해 설명 합니다.
미국 동부 지역의 주 WLS 클러스터에서 다음 단계를 사용합니다.
- WebLogic Server 관리 콘솔에 로그인했는지 확인합니다.
- 탐색 창에서 >로 이동합니다. 서버를 선택합니다.
- 서버 테이블에 msp1, msp2및 msp3 서버가 나열되어야 합니다.
- 서비스 잠금 및 편집을
msp1>선택합니다.> 트랜잭션 로그 저장소에서 JDBC를 선택합니다. 형식 데이터 원본 에 대해, jdbc/WebLogicCafeDB를선택합니다. - 접두사 이름 값이 기본값인 TLOG_msp1_ 있는지 확인합니다. 값이 다른 경우 TLOG_msp1_ 변경합니다.
- 저장을 선택합니다.
- Server>msp2선택하고 접두사 이름 기본값이 TLOG_msp2_것을 제외하고 동일한 단계를 반복합니다.
- Server>msp3을 선택한 다음 접두사 이름 의 기본값이 TLOG_msp3_인 것을 제외하고 동일한 단계를 반복합니다.
- 변경 내용 활성화를 선택합니다.
WebLogic Server 관리 콘솔에서 동일한 단계를 반복하지만 미국 서부 지역의 보조 클러스터에 대해 반복합니다.
주 클러스터의 관리되는 서버 다시 시작
그런 다음, 다음 단계를 사용하여 변경 내용을 적용하기 위해 주 클러스터의 모든 관리되는 서버를 다시 시작합니다.
- WebLogic Server 관리 콘솔에 로그인되어 있는지 확인합니다.
- 탐색 창에서 >로 이동합니다. 서버를 선택합니다.
- 컨트롤 탭을 선택합니다. msp1, msp2및 msp3선택합니다. 작업이 완료된 경우 [예] 옵션을 사용하여 종료를>. 새로 고침 아이콘을 선택합니다. 마지막 작업 값의 상태가 TASK COMPLETED가 될 때까지 기다립니다. 선택한 서버의 상태 값이 SHUTDOWN임을 알 수 있습니다. 새로 고침 아이콘을 다시 선택하여 상태 모니터링을 중지합니다.
- msp1, msp2, msp3 다시 선택합니다. [예 시작]을> 선택합니다. 새로 고침 아이콘을 선택합니다. 마지막 작업 값의 상태가 TASK COMPLETED가 될 때까지 기다립니다. 선택한 서버의 상태 값이 실행 중임을 확인할 수 있습니다. 새로 고침 아이콘을 다시 선택하여 상태 모니터링을 중지합니다.
보조 클러스터에서 VM 중지
이제 다음 단계를 사용하여 보조 클러스터의 모든 VM을 중지하여 수동적으로 만듭니다.
- 브라우저의 새 탭에서 Azure Portal 홈을 열고 모든 리소스를 선택합니다. 필드 필터... 상자에 보조 클러스터가 배포되는 리소스 그룹 이름(예: wls-cluster-westus-ejb120623)을 입력합니다.
- 형식 필터를 열려면 모두 같은 형식을 선택합니다. 값의 경우 가상 머신을 입력합니다. 일치하는 항목이 하나 표시됩니다. 값으로 선택합니다. 적용을 선택합니다. adminVM, mspVM1, mspVM2및 mspVM3포함하여 4개의 VM이 나열됩니다.
- 각 VM을 열려면 선택합니다. 중지를 선택하고 각 VM에 대해 확인합니다.
- Azure Portal에서 알림 아이콘을 선택하여 알림 창을 엽니다.
- 값이 성공적으로 중지된 가상 머신이 될 때까지 각 VM에 대한 가상 머신 중지 이벤트를 모니터링합니다. 나중에 장애 조치(failover) 테스트에 사용할 수 있도록 페이지를 열어 두세요.
이제 엔드포인트의 Traffic Manager 상태를 모니터링하는 브라우저 탭으로 전환합니다. myFailoverEndpoint
참고 항목
프로덕션 준비가 완료된 HA/DR 솔루션은 VM을 실행 중인 상태로 두지만 VM에서 실행되는 WLS 소프트웨어만 중지하여 더 낮은 RTO를 달성하려고 할 것입니다. 그런 다음 장애 조치(failover) 시 VM이 이미 실행 중이며 WLS 소프트웨어를 시작하는 데 시간이 더 적게 소요됩니다. 이 문서에서는 Azure VM의 Oracle WebLogic Server 클러스터에서 배포한 소프트웨어가 VM 이 시작될 때 WLS 소프트웨어를 자동으로 시작하기 때문에 VM을 중지하도록 선택했습니다.
앱 확인
주 클러스터는 실행 중이므로 활성 클러스터 역할을 하며 Traffic Manager 프로필에서 라우팅된 모든 사용자 요청을 처리합니다.
브라우저의 새 탭에서 Azure Traffic Manager 프로필의 DNS 이름을 열고 배포된 앱의 컨텍스트 루트 /weblogic-café 를 추가합니다. 예를 들면 다음과 같습니다 http://tmprofile-ejb120623.trafficmanager.net/weblogic-cafe. 이름 및 가격으로 새 커피를 만듭니다(예: 가격이 10인 커피 1). 이 항목은 데이터베이스의 애플리케이션 데이터 테이블과 세션 테이블 모두에 유지됩니다. 표시되는 UI는 다음 스크린샷과 유사해야 합니다.

UI가 비슷하지 않으면 계속하기 전에 문제를 해결하고 해결합니다.
페이지를 열어 두면 나중에 장애 조치(failover) 테스트에 사용할 수 있습니다.
기본에서 보조로 장애 조치(failover) 테스트
장애 조치(failover)를 테스트하려면 주 데이터베이스 서버 및 클러스터를 보조 데이터베이스 서버 및 클러스터로 수동으로 장애 조치(failover)한 다음, 이 섹션의 Azure Portal을 사용하여 장애 복구(failback)합니다.
보조 사이트로 장애 조치(failover)
먼저 다음 단계를 사용하여 주 클러스터에서 VM을 종료합니다.
- 기본 WLS 클러스터가 배포되는 리소스 그룹의 이름(예 : wls-cluster-eastus-ejb120623)을 찾습니다. 그런 다음 보조 클러스터 섹션의 VM 중지 단계에 따라 대상 리소스 그룹을 기본 WLS 클러스터로 변경하여 해당 클러스터의 모든 VM을 중지합니다.
- Traffic Manager의 브라우저 탭으로 전환하고 엔드포인트 myPrimaryEndpoint의 모니터 상태 값이 저하될 때까지 페이지를 새로 고칩니다.
- 샘플 앱의 브라우저 탭으로 전환하고 페이지를 새로 고칩니다. 액세스할 수 있는 엔드포인트가 없으므로 504 게이트웨이 제한 시간 또는 502 잘못된 게이트웨이가 표시됩니다.
다음으로, 다음 단계를 사용하여 Azure SQL Database를 주 서버에서 보조 서버로 장애 조치(failover)합니다.
- Azure SQL Database 장애 조치(failover) 그룹의 브라우저 탭으로 전환합니다.
- 장애 조치(Failover
- 완료될 때까지 기다립니다.
그런 다음, 다음 단계를 사용하여 보조 클러스터의 모든 서버를 시작합니다.
- 보조 클러스터의 모든 VM을 중지한 브라우저 탭으로 전환합니다.
- VM
adminVM을 선택합니다. 시작을 선택합니다. - 알림 창에서 가상 머신
adminVM모니터링하고 값이 시작 가상 머신이 될 때까지 기다립니다. - 보조 클러스터에 대한 WebLogic Server 관리 콘솔의 브라우저 탭으로 전환한 다음 로그인 시작 페이지가 표시될 때까지 페이지를 새로 고칩니다.
- 보조 클러스터의 모든 VM이 나열된 브라우저 탭으로 다시 전환합니다. VM의 경우 각 VM을
mspVM1mspVM2mspVM3선택하여 열고 시작을 선택합니다. - VM 및
mspVM1mspVM2mspVM3알림 창에서 가상 머신 시작 이벤트를 모니터링하고 값이 시작 가상 머신이 될 때까지 기다립니다.
마지막으로 다음 단계를 사용하여 엔드포인트 myFailoverEndpoint가 온라인 상태인 후 샘플 앱을 확인합니다.
Traffic Manager의 브라우저 탭으로 전환한 다음 엔드포인트 의 모니터 상태 값이 온라인 상태로
myFailoverEndpoint될 때까지 페이지를 새로 고칩니다.샘플 앱의 브라우저 탭으로 전환하고 페이지를 새로 고칩니다. 다음 스크린샷과 같이 애플리케이션 데이터 테이블과 UI에 표시되는 세션 테이블에 동일한 데이터가 유지됩니다.
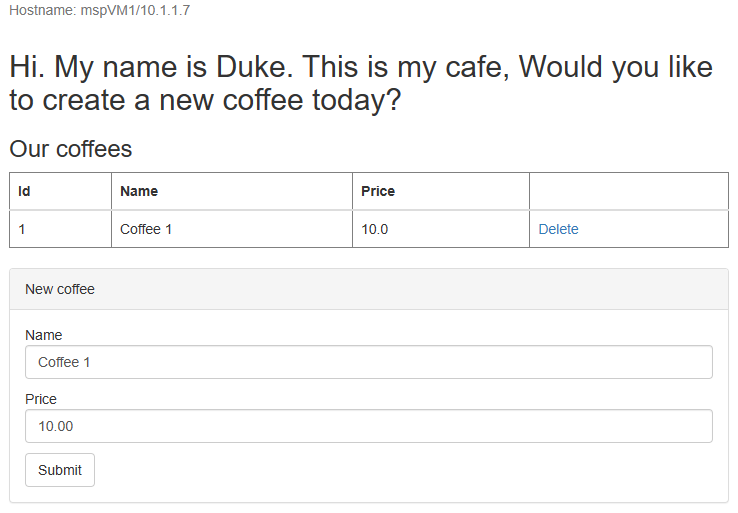
이 동작을 관찰하지 않으면 Traffic Manager가 장애 조치(failover) 사이트를 가리키도록 DNS를 업데이트하는 데 시간이 걸리기 때문일 수 있습니다. 문제는 브라우저가 실패한 사이트를 가리키는 DNS 이름 확인 결과를 캐시한 것일 수도 있습니다. 잠시 기다렸다가 페이지를 다시 새로 고칩니다.
참고 항목
프로덕션 준비 HA/DR 솔루션은 정기적으로 주 클러스터에서 보조 클러스터로 WLS 구성을 지속적으로 복사하는 것을 고려합니다. 이 작업을 수행하는 방법에 대한 자세한 내용은 이 문서의 끝에 있는 Oracle 설명서에 대한 참조를 참조하세요.
장애 조치(failover)를 자동화하려면 Traffic Manager 메트릭 및 Azure Automation에 대한 경고를 사용하는 것이 좋습니다. 자세한 내용은 Traffic Manager 메트릭 및 경고의 Traffic Manager 메트릭에 대한 경고 섹션을 참조하고 경고를 사용하여 Azure Automation Runbook을 트리거합니다.
기본 사이트로 장애 복구
다음 차이점을 제외하고 보조 사이트 섹션에 대한 장애 조치(failover)의 동일한 단계를 사용하여 데이터베이스 서버 및 클러스터를 포함한 기본 사이트로 장애 복구합니다.
- 먼저 보조 클러스터에서 VM을 종료합니다. 엔드포인트 myFailoverEndpoint 이 성능 저하로 변경됩니다.
- 다음으로, 보조 서버에서 주 서버로 Azure SQL Database를 장애 조치(failover)합니다.
- 그런 다음 주 클러스터의 모든 서버를 시작합니다.
- 마지막으로 엔드포인트
myPrimaryEndpoint 온라인후 샘플 앱을 확인합니다.
리소스 정리
WLS 클러스터 및 기타 구성 요소를 계속 사용하지 않려면 다음 단계를 사용하여 리소스 그룹을 삭제하여 이 자습서에서 사용되는 리소스를 정리합니다.
- Azure Portal 맨 위에 있는 검색 상자에 Azure SQL Database 서버의 리소스 그룹 이름(예
myResourceGroup: )을 입력하고 검색 결과에서 일치하는 리소스 그룹을 선택합니다. - 리소스 그룹 삭제를 선택합니다.
- 리소스 그룹 이름을 입력하여 삭제를 확인하려면 리소스 그룹 이름을 입력합니다.
- 삭제를 선택합니다.
- Traffic Manager의 리소스 그룹에 대해 1-4단계를 반복합니다(예:
myResourceGroupTM1). - 기본 WLS 클러스터의 리소스 그룹에 대해 1-4단계를 반복합니다(예
wls-cluster-eastus-ejb120623: .). - 보조 WLS 클러스터의 리소스 그룹에 대해 1-4단계를 반복합니다. 예를 들면 다음과 같습니다
wls-cluster-westus-ejb120623.
다음 단계
이 자습서에서는 활성-수동 데이터베이스 계층이 있는 활성-수동 애플리케이션 인프라 계층으로 구성되고 두 계층이 지리적으로 다른 두 사이트에 걸쳐 있는 HA/DR 솔루션을 설정합니다. 첫 번째 사이트에서는 애플리케이션 인프라 계층과 데이터베이스 계층이 모두 활성화됩니다. 두 번째 사이트에서는 보조 도메인이 종료되고 보조 데이터베이스가 대기 상태입니다.
HA/DR 솔루션을 빌드하고 Azure에서 WLS를 실행하는 추가 옵션에 대한 다음 참조를 계속 살펴봅니다.