시각화 형식
이 문서에서는 Azure Databricks Notebook 및 Databricks SQL에서 사용할 수 있는 시각화 유형을 간략하게 설명하고 각 시각화 형식의 예제를 만드는 방법을 보여 줍니다.
참고 항목
AI/BI 대시보드에 사용할 수 있는 시각화 유형에 대해 알아보려면
막대형 차트
가로 막대형 차트는 시간에 따른 메트릭의 변화를 나타내거나 원형 차트와 유사하게 비례성을 표시합니다.
참고 항목
세로 막대형 차트는 백엔드 집계를 지원하며, 결과 집합이 잘리지 않도록 64K가 넘는 데이터 행을 반환하는 쿼리를 지원합니다.
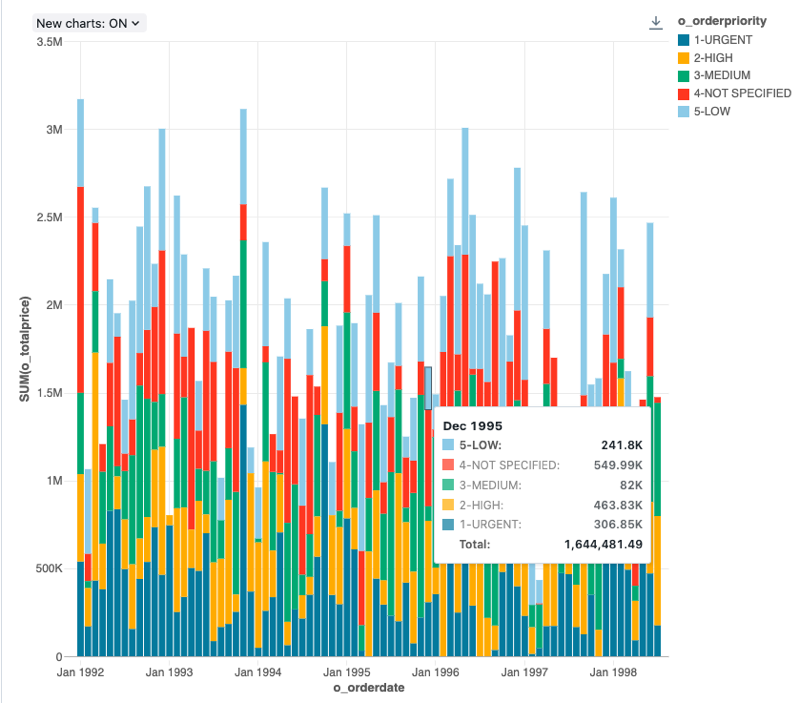
구성 값: 이 가로 막대형 차트 시각화의 경우 다음 값이 설정되었습니다.
- X 열:
- 데이터 세트 열:
o_orderdate - 날짜 수준:
Months
- 데이터 세트 열:
- Y 열:
- 데이터 세트 열:
o_totalprice - 집계 유형:
Sum
- 데이터 세트 열:
- 그룹화 기준(데이터셋 열):
o_orderpriority - 스태킹:
Stack - X축 이름(기본값 재정의):
Order month - Y축 이름(기본값 재정의):
Total price
구성 옵션: 가로 막대형 차트 구성 옵션은 차트 구성 옵션을 참조 하세요.
SQL 쿼리: 이 가로 막대형 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.orders
꺾은선형 차트
꺾은선형 차트는 시간이 지남에 따라 하나 이상의 메트릭에서 변경 내용을 표시합니다.
참고 항목
라인 차트는 백엔드 집계를 지원하며, 결과 집합이 잘리지 않고 64K가 넘는 데이터 행을 반환하는 쿼리를 지원합니다.
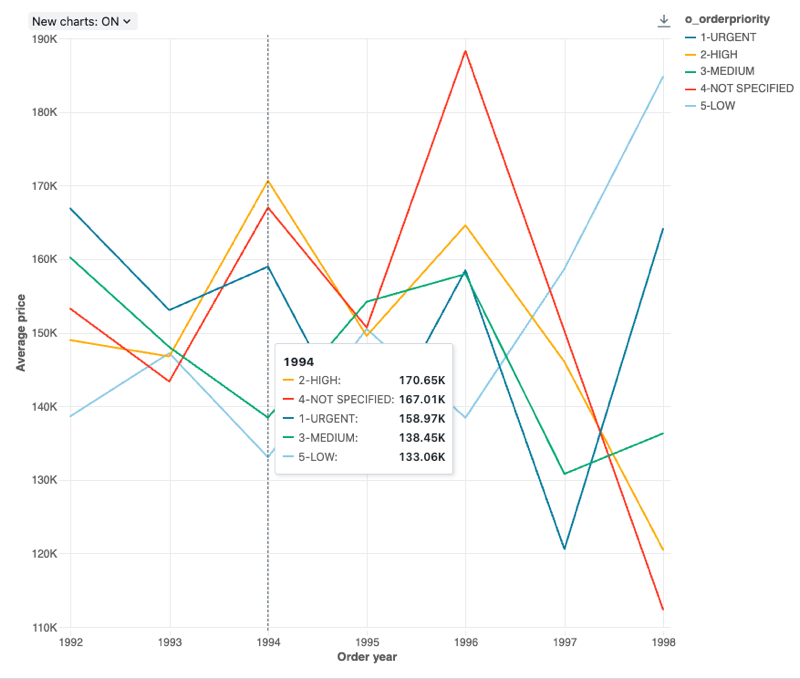
구성 값: 이 꺾은선형 차트 시각화의 경우 다음 값이 설정되었습니다.
- X 열:
- 데이터셋 열:
o_orderdate - 날짜 수준:
Years
- 데이터셋 열:
- Y 열:
- 데이터 세트 열:
o_totalprice - 집계 유형:
Average
- 데이터 세트 열:
- 그룹화 기준(데이터 세트 열):
o_orderpriority - X축 이름(기본값 재정의):
Order year - Y축 이름(기본값 재정의):
Average price
구성 옵션: 꺾은선형 차트 구성 옵션은 차트 구성 옵션을 참조 하세요.
SQL 쿼리: 이 꺾은선형 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.orders
영역형 차트
영역형 차트는 꺾은선형 차트와 세로 막대형 차트를 결합하여 두 번째 변수의 진행에 대해 하나 이상의 그룹의 숫자 값이 변경되는 방식을 보여주며, 일반적으로 시간입니다. 구매 과정의 시간별 변화를 표시하는 데 자주 사용됩니다.
참고 항목
영역형 차트는 백엔드 집계를 지원하여 결과 집합이 잘림 없이 64K가 넘는 데이터 행을 반환하는 쿼리를 지원합니다.
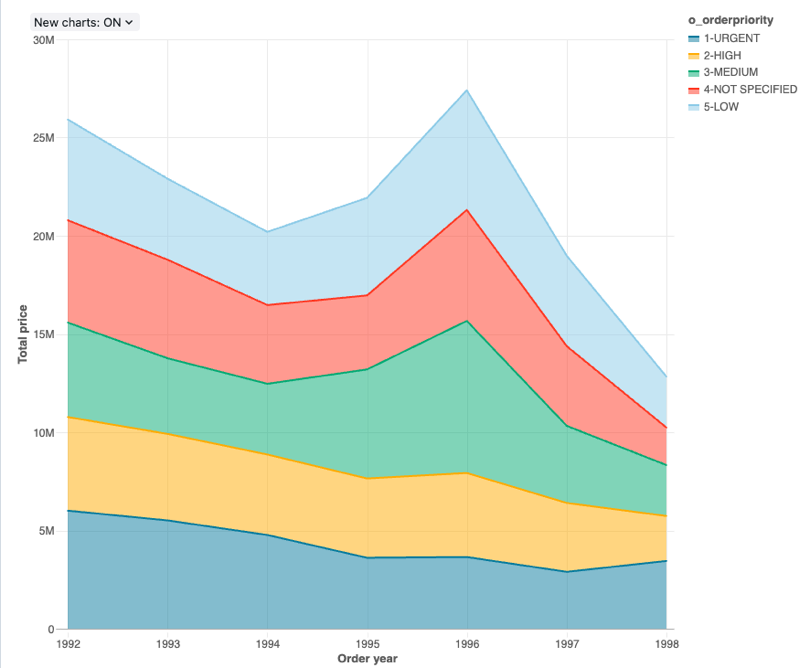
구성 값: 이 영역형 차트 시각화의 경우 다음 값이 설정되었습니다.
- X 열:
- 데이터 세트 열:
o_orderdate - 날짜 수준:
Years
- 데이터 세트 열:
- Y 열:
- 데이터 세트 열:
o_totalprice - 집계 유형:
Sum
- 데이터 세트 열:
- 그룹화 기준(데이터셋 열):
o_orderpriority - 스태킹:
Stack - X축 이름(기본값 재정의):
Order year - Y축 이름(기본값 재정의):
Total price
구성 옵션: 영역형 차트 구성 옵션은 차트 구성 옵션을 참조 하세요.
SQL 쿼리: 이 영역형 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.orders
원형 차트
원형 차트는 메트릭 간의 비례성을 표시합니다. 시계열 데이터를 전달하기 위한 것이 아닙니다.
참고 항목
원형 차트는 백엔드 집계를 지원하여 결과 집합이 잘리지 않고 64K 이상의 데이터 행을 반환하는 쿼리를 지원합니다.
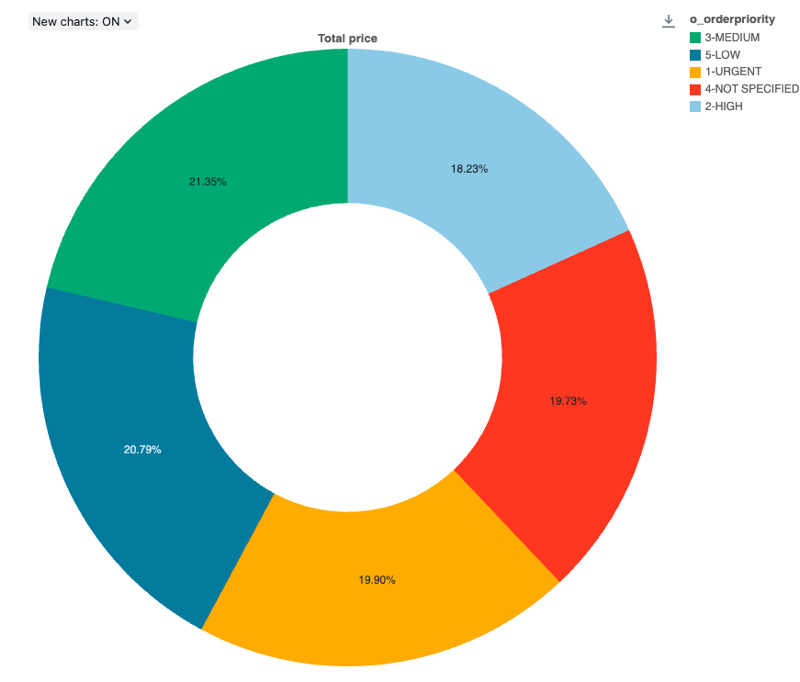
구성 값: 이 원형 차트 시각화의 경우 다음 값이 설정되었습니다.
- X 열(데이터 세트 열):
o_orderpriority - Y 열들:
- 데이터 세트 열:
o_totalprice - 집계 유형:
Sum
- 데이터 세트 열:
- 레이블(기본값 재정의):
Total price
구성 옵션: 원형 차트 구성 옵션은 차트 구성 옵션을 참조 하세요.
SQL 쿼리: 이 원형 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.orders
히스토그램 차트
히스토그램은 지정된 값이 데이터 세트에서 발생하는 빈도를 그립니다. 히스토그램을 사용하면 데이터 세트에 적은 수의 범위 주위에 클러스터된 값이 있는지 아니면 더 많이 분산되어 있는지를 이해할 수 있습니다. 히스토그램은 고유 막대(bin이라고도 함)의 수를 제어하는 가로 막대형 차트로 표시됩니다.
참고 항목
히스토그램 차트는 백엔드 집계를 지원함으로써 결과 집합이 잘리지 않도록 64K가 넘는 데이터 행을 반환하는 쿼리를 지원합니다.
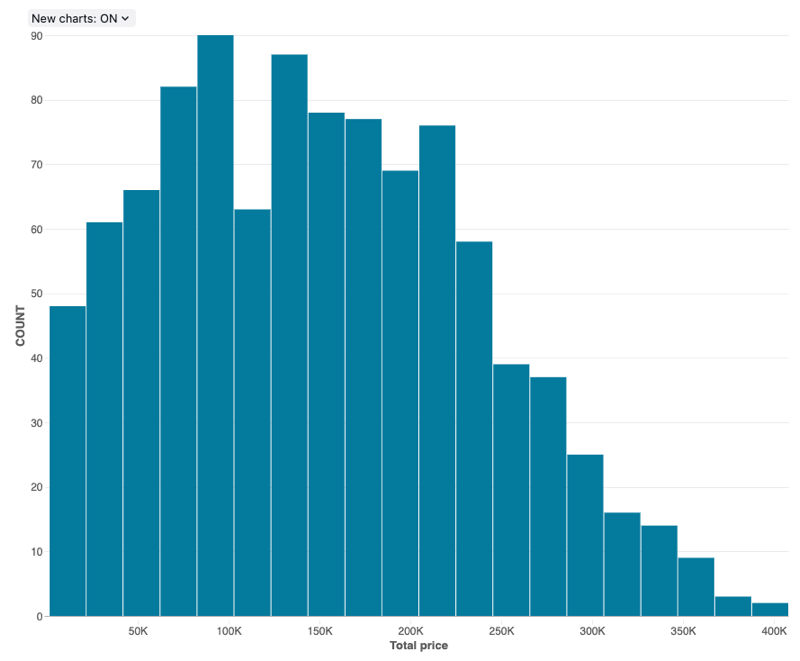
구성 값: 이 히스토그램 차트 시각화의 경우 다음 값이 설정되었습니다.
- X 열(데이터셋 열):
o_totalprice - Bin 수: 20
- X축 이름(기본값 재정의):
Total price
구성 옵션: 히스토그램 차트 구성 옵션은 히스토그램 차트 구성 옵션을 참조하세요.
SQL 쿼리: 이 히스토그램 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.orders
열 지도 차트
열 지도 차트는 가로 막대형 차트, 누적형 차트 및 거품형 차트의 기능을 혼합하여 색을 사용하여 숫자 데이터를 시각화할 수 있습니다. 열 지도에서 공통적으로 사용되는 색상표는 주황색이나 빨간색과 같은 따뜻한 색으로 가장 높은 값을 표시하고, 파란색이나 자주색과 같은 차가운 색으로 가장 낮은 값을 표시합니다.
예를 들어 다음 열 지도에서는 매일 가장 자주 발생하는 택시 승차 거리를 시각화하고 요일, 거리, 총 요금별로 결과를 그룹화합니다.
참고 항목
히트맵 차트는 백엔드 집계를 지원하여, 결과 집합이 잘리지 않고 64K가 넘는 데이터 행을 반환하는 쿼리를 지원합니다.
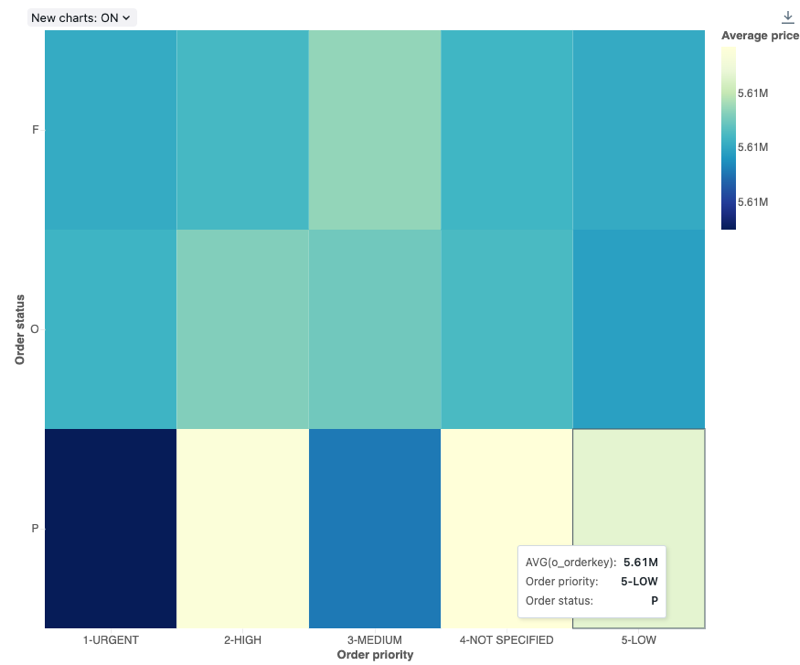
구성 값: 이 열 지도 차트 시각화의 경우 다음 값이 설정되었습니다.
- X 열(데이터셋 열):
o_orderpriority - Y 열(데이터셋 열):
o_orderstatus - 색 열:
- 데이터 세트 열:
o_totalprice - 집계 유형:
Average
- 데이터 세트 열:
- X축 이름(기본값 재정의):
Order priority - Y축 이름(기본값 재정의):
Order status - 색상 이름 (기본값 대체):
Average price - 색 구성표(기본값 재정의):
YIGnBu
구성 옵션: 열 지도 구성 옵션은 열 지도 차트 구성 옵션을 참조 하세요.
SQL 쿼리: 이 열 지도 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.orders
분산형 차트
분산 시각화는 일반적으로 두 숫자 변수 간의 관계를 표시하는 데 사용됩니다. 또한 세 번째 차원을 색으로 인코딩하여 그룹 간에 숫자 변수가 어떻게 다른지 보여 줄 수 있습니다.
참고 항목
분산형 차트는 백 엔드 집계를 지원하여 결과 집합을 잘림하지 않고 64K가 넘는 데이터 행을 반환하는 쿼리를 지원합니다.
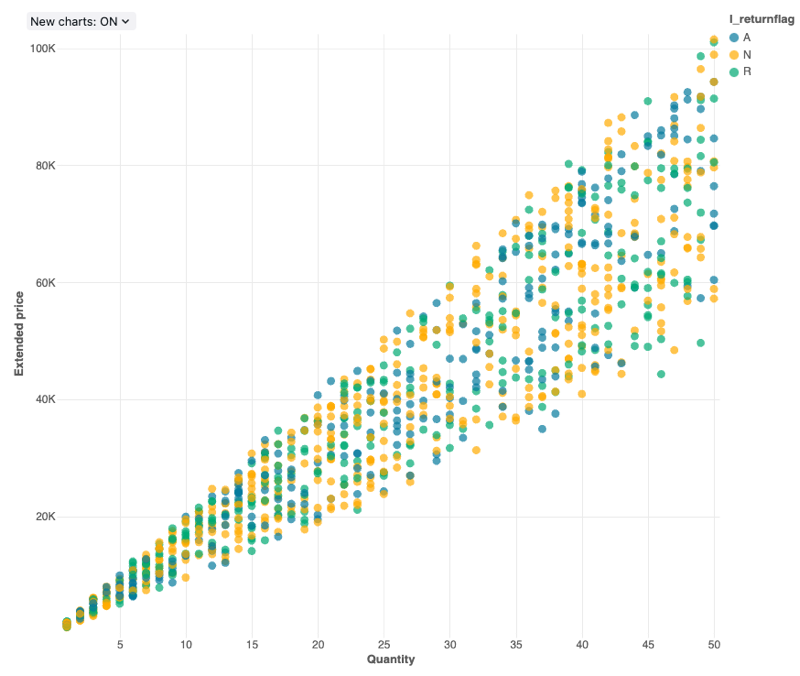
구성 값: 이 분산형 차트 시각화의 경우 다음 값이 설정되었습니다.
- X 열 (데이터 세트 열):
l_quantity - Y 열(데이터 세트 열):
l_extendedprice - 그룹화 기준(데이터 세트 열):
l_returnflag - X축 이름(기본값 재정의):
Quantity - Y축 이름(기본값 재정의):
Extended price
구성 옵션: 분산형 차트 구성 옵션은 차트 구성 옵션을 참조 하세요.
SQL 쿼리: 이 분산형 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.lineitem
거품형 차트
거품형 차트는 각 점 표식의 크기가 관련 메트릭을 반영하는 분산형 차트입니다.
참고 항목
거품형 차트는 백엔드 집계를 지원하여 결과 집합이 잘리지 않고 64,000개 이상의 데이터 행을 반환하는 쿼리를 처리할 수 있습니다.
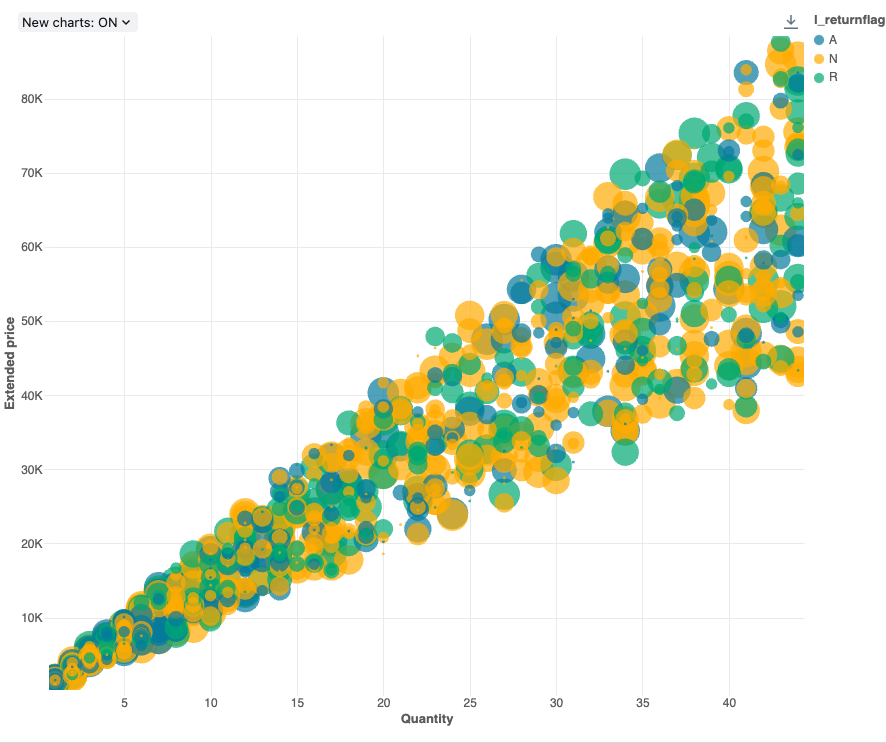
구성 값: 이 거품형 차트 시각화의 경우 다음 값이 설정되었습니다.
- X(데이터 세트 열):
l_quantity - Y 열(데이터 세트 열):
l_extendedprice - 그룹화 기준(데이터 세트 열):
l_returnflag - 거품 크기 열(데이터 세트 열):
l_tax - 거품 크기 계수: 20
- 거품 크기:
Area에 비례함 - X축 이름(기본값 재정의):
Quantity - Y축 이름(기본값 재정의):
Extended price
구성 옵션: 거품형 차트 구성 옵션은 차트 구성 옵션을 참조 하세요.
SQL 쿼리: 이 거품형 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.lineitem where l_quantity < 45
상자 차트
상자 차트 시각화는 범주별로 선택적으로 그룹화된 숫자 데이터의 분포 요약을 보여줍니다. 상자형 차트를 사용하면 범주 간 값의 범위를 빠르게 비교하고 사분위수를 통해 값의 지역성, 분산 및 왜도를 시각화할 수 있습니다. 각 상자에서 어두운 선은 사분위수 범위를 나타냅니다. 상자 그림 시각화 해석에 대한 자세한 내용은 Wikipedia의 상자 차트 문서를 참조하세요.
참고 항목
상자 차트는 최대 64,000개의 행에 대한 집계만 지원합니다. 데이터 세트가 64,000개 행보다 크면 데이터가 잘립니다.
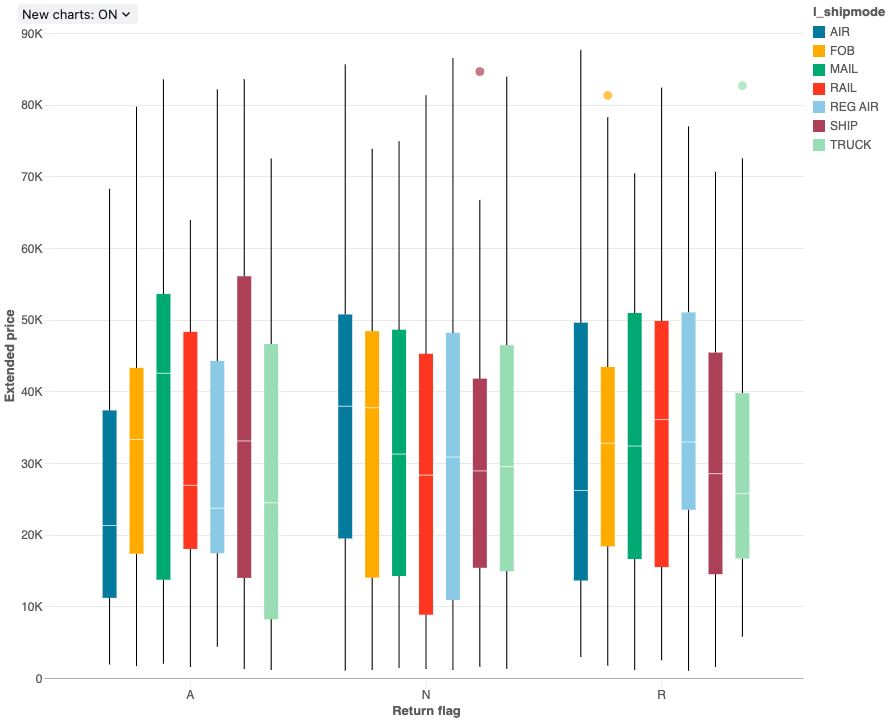
구성 값: 이 상자 차트 시각화의 경우 다음 값이 설정되었습니다.
- X 열(데이터셋 열):
l_returnflag - Y 열(데이터 세트 열):
l_extendedprice - 그룹화 기준(데이터셋 열):
l_shipmode - X축 이름(기본값 재정의):
Return flag - Y축 이름(기본값 재정의):
Extended price
구성 옵션: 상자 차트 구성 옵션의 경우 상자 차트 구성 옵션을 참조 하세요.
SQL 쿼리: 이 상자 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.lineitem
콤보 차트
콤보 차트는 선 차트와 가로 막대형 차트를 결합하여 시간에 따른 변경 내용을 비례적으로 표시합니다.
참고 항목
콤보 차트는 백엔드 집계를 지원하여 결과 집합이 잘리지 않고 64K 이상의 데이터 행을 반환하는 쿼리를 처리할 수 있습니다.
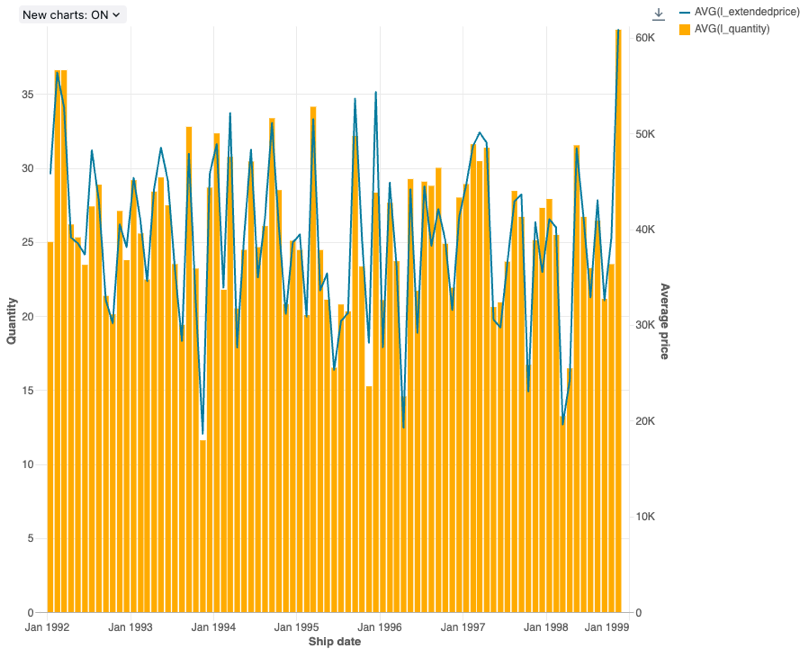
구성 값: 이 콤보 차트 시각화의 경우 다음 값이 설정되었습니다.
- X 열:
- 데이터 세트 열:
l_shipdate - 날짜 수준:
Months
- 데이터 세트 열:
- Y 열:
- 첫 번째 데이터셋 열:
l_extendedprice - 집계 유형: 평균
- 두 번째 데이터 세트 열:
l_quantity - 집계 유형: 평균
- 첫 번째 데이터셋 열:
- X축 이름(기본값 재정의):
Ship date - 왼쪽 Y축 이름(기본값 재정의):
Quantity - 오른쪽 Y축 이름(기본값 재정의):
Average price - 시리즈:
- Order1(데이터 세트 열):
AVG(l_extendedprice) - Y축: 오른쪽
- 형식: 선
- Order2(데이터 세트 열):
AVG(l_quantity) - Y축: 왼쪽
- 형식: 막대
- Order1(데이터 세트 열):
구성 옵션: 콤보 차트 구성 옵션은 차트 구성 옵션을 참조 하세요.
SQL 쿼리: 이 콤보 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.lineitem
코호트 분석
코호트 분석은 일련의 단계를 진행하면서 코호트라고 하는 미리 결정된 그룹의 결과를 검사합니다. 코호트 시각화는 날짜에 대해서만 집계됩니다(월별 집계를 허용). 결과 집합 내의 다른 데이터 집계는 수행하지 않습니다. 다른 모든 집계는 쿼리 자체 내에서 수행됩니다.
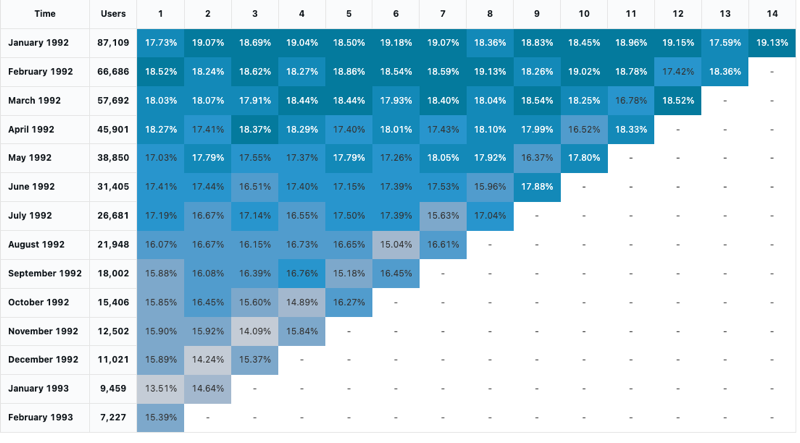
구성 값: 이 코호트 시각화의 경우 다음 값이 설정되었습니다.
- 날짜(버킷)(데이터베이스 열):
cohort_month - 스테이지(데이터베이스 열):
months - 버킷 개체 수(데이터베이스 열):
size - 단계 값(데이터베이스 열):
active - 시간 간격:
monthly
구성 옵션: 코호트 구성 옵션은 코호트 차트 구성 옵션을 참조 하세요.
SQL 쿼리: 이 코호트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
-- match each customer with its cohort by month
with cohort_dates as (
SELECT o_custkey, min(date_trunc('month', o_orderdate)) as cohort_month
FROM samples.tpch.orders
GROUP BY 1
),
-- find the size of each cohort
cohort_size as (
SELECT cohort_month, count(distinct o_custkey) as size
FROM cohort_dates
GROUP BY 1
)
-- for each cohort and month thereafter, find the number of active customers
SELECT
cohort_dates.cohort_month,
ceil(months_between(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month)) as months,
count(distinct samples.tpch.orders.o_custkey) as active,
first(size) as size
FROM samples.tpch.orders
left join cohort_dates on samples.tpch.orders.o_custkey = cohort_dates.o_custkey
left join cohort_size on cohort_dates.cohort_month = cohort_size.cohort_month
WHERE datediff(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month) != 0
GROUP BY 1, 2
ORDER BY 1, 2
카운터 표시
카운터는 단일 값을 눈에 띄게 표시하고 대상 값과 비교하는 옵션을 제공합니다. 카운터를 사용하려면
참고 항목
카운터는 최대 64,000개의 행에 대한 집계만 지원합니다. 데이터 세트가 64,000개 행보다 크면 데이터가 잘립니다.

구성 값: 이 카운터 시각화 표시의 경우 다음 값이 설정되었습니다.
- 값 열
- 데이터셋 열:
avg(o_totalprice) - 행: 1
- 데이터셋 열:
- 대상 열:
- 데이터 세트 열:
avg(o_totalprice) - 행: 2
- 데이터 세트 열:
- 형식 대상 값: 사용
SQL 쿼리: 이 카운터 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select o_orderdate, avg(o_totalprice)
from samples.tpch.orders
GROUP BY 1
ORDER BY 1 DESC
깔때기형 시각화
깔때기형 시각화는 다양한 단계에서 메트릭의 변경 사항을 분석하는 데 도움이 됩니다. 깔때기를 사용하려면 step 및 value 열을 지정합니다.
참고 항목
깔때기는 최대 64,000개의 행에 대한 집계만 지원합니다. 데이터 세트가 64,000개 행보다 크면 데이터가 잘립니다.
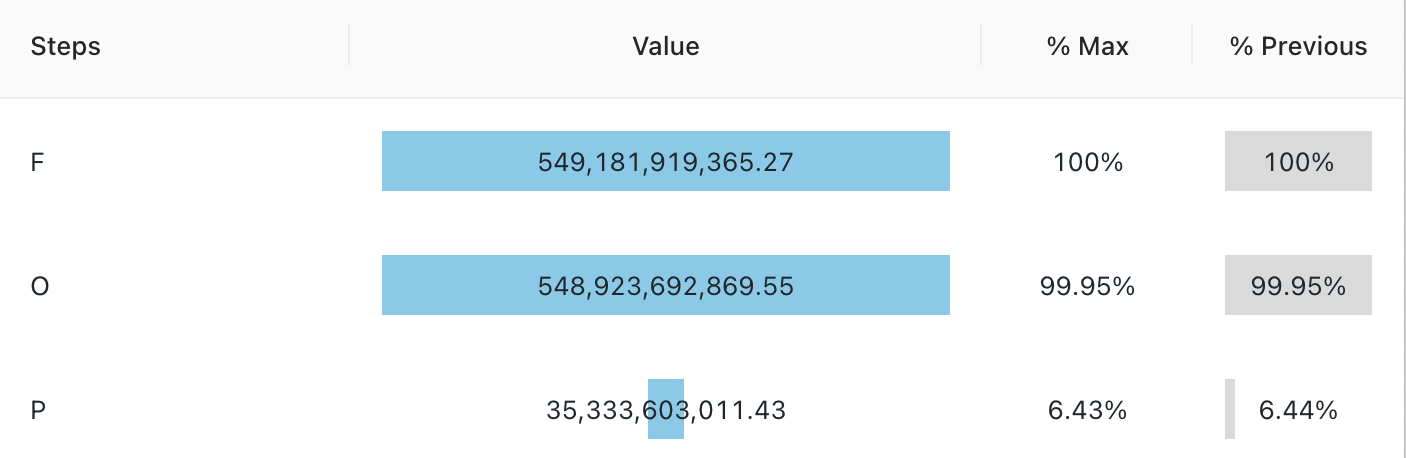
구성 값: 이 깔때기 시각화의 경우 다음 값이 설정되었습니다.
- 단계 열(데이터 세트 열):
o_orderstatus - 값 열(데이터 세트 열):
Revenue
SQL 쿼리: 이 깔때기 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT o_orderstatus, sum(o_totalprice) as Revenue
FROM samples.tpch.orders
GROUP BY 1
지도(Choropleth) 시각화
초로프 시각화에서 국가 또는 주와 같은 지리적 지역은 각 키 열의 집계 값에 따라 색이 지정됩니다. 쿼리는 지리적 위치를 이름으로 반환해야 합니다.
참고 항목
Choropleth 시각화는 결과 집합 내의 데이터를 집계하지 않습니다. 모든 집계는 쿼리 자체 내에서 계산되어야 합니다.
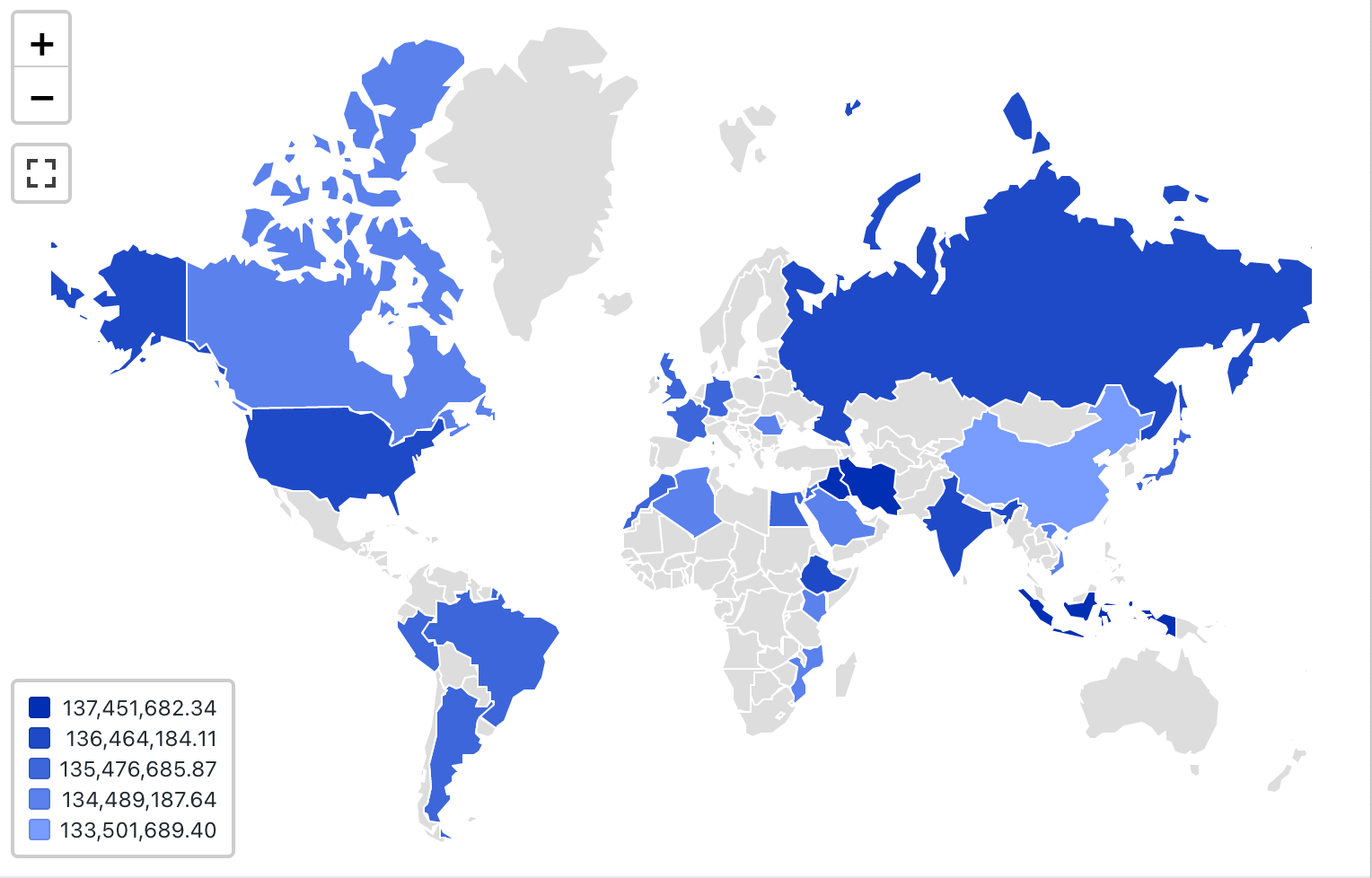
구성 값: 이 초로프 시각화의 경우 다음 값이 설정되었습니다.
- 지도(데이터 세트 열):
Countries - 지리적 열(데이터셋 열):
Country - 지리적 유형: 짧은 이름
- 값 열(데이터 세트 열):
Revenue - 클러스터링 모드: 등가
구성 옵션: choropleth 구성 옵션의 경우 choropleth 구성 옵션을 참조 하세요.
SQL 쿼리: 이 초로플스 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT
initcap(n_name) as Country,
sum(c_acctbal)
FROM samples.tpch.customer
join samples.tpch.nation where n_nationkey = c_nationkey
GROUP BY 1
표식 지도 시각화
표식 시각화에서 표식은 지도의 좌표 집합에 배치됩니다. 쿼리 결과는 위도 및 경도 쌍을 반환해야 합니다.
참고 항목
표식은 결과 집합 내의 데이터를 집계하지 않습니다. 모든 집계는 쿼리 자체 내에서 계산되어야 합니다.
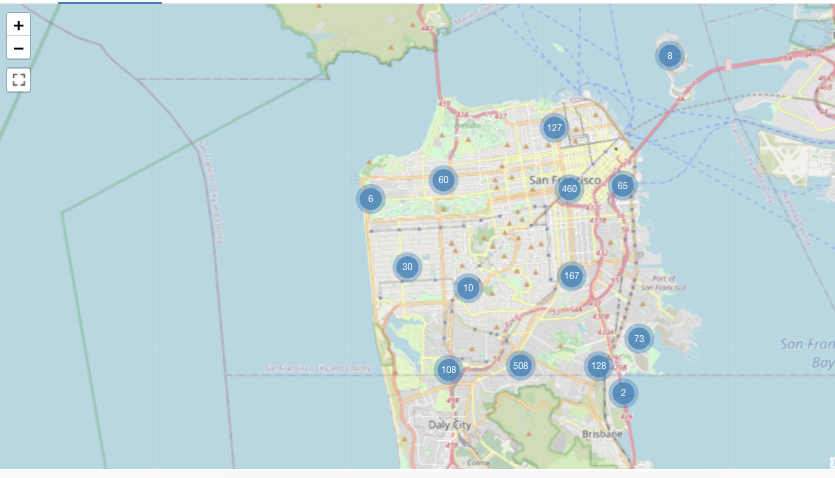
이 표식 예제는 Databricks 샘플 데이터 세트에서 사용할 수 없는 위도 및 경도 값을 모두 포함하는 데이터 세트에서 생성됩니다. 초로프 구성 옵션은 표식 구성 옵션을 참조 하세요.
피벗 테이블 시각화
피벗 테이블 시각화는 쿼리 결과의 레코드를 새 테이블 형식 디스플레이로 집계합니다. SQL의 PIVOT 또는 GROUP BY 문과 유사합니다. 드래그 앤 드롭 필드를 사용하여 피벗 테이블의 시각화를 구성합니다.
참고 항목
피벗 테이블은 백 엔드 집계를 지원하여 결과 집합을 잘림하지 않고 64K가 넘는 데이터 행을 반환하는 쿼리를 지원합니다. 그러나 피벗 테이블(레거시)은 최대 64,000개의 행에 대한 집계만 지원합니다. 데이터 세트가 64,000개 행보다 크면 데이터가 잘립니다.
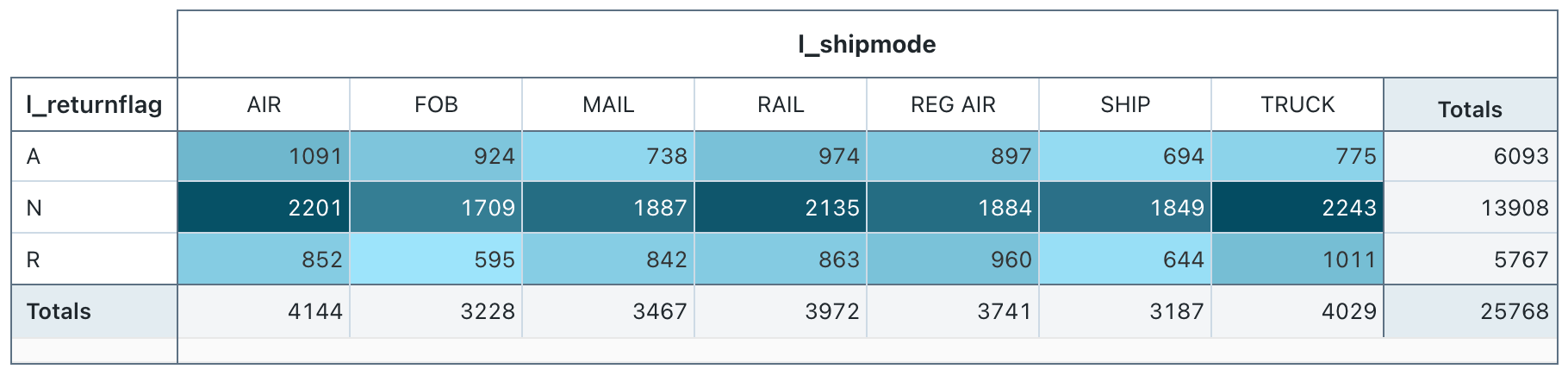
구성 값: 이 피벗 테이블 시각화의 경우 다음 값이 설정되었습니다.
- 행 선택(데이터 세트 열):
l_returnflag - 열 선택(데이터 세트 열):
l_shipmode - 셀
- 데이터 세트 열:
l_quantity - 집계 형식: Sum
- 값별 셀 색 지정: 켜기
- 데이터 세트 열:
SQL 쿼리: 이 피벗 테이블 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.lineitem
Sankey
sankey 다이어그램은 값 집합에서 다른 값 집합으로의 흐름을 시각화합니다.
참고 항목
Sankey 시각화는 결과 집합 내의 데이터를 집계하지 않습니다. 모든 집계는 쿼리 자체 내에서 계산되어야 합니다.

SQL 쿼리: 이 Sankey 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
선버스트 시퀀스
선버스트 다이어그램은 동심원을 사용하여 계층적 데이터를 시각화하는 데 도움이 됩니다.
참고 항목
선버스트 시퀀스는 결과 집합 내의 데이터를 집계하지 않습니다. 모든 집계는 쿼리 자체 내에서 계산되어야 합니다.
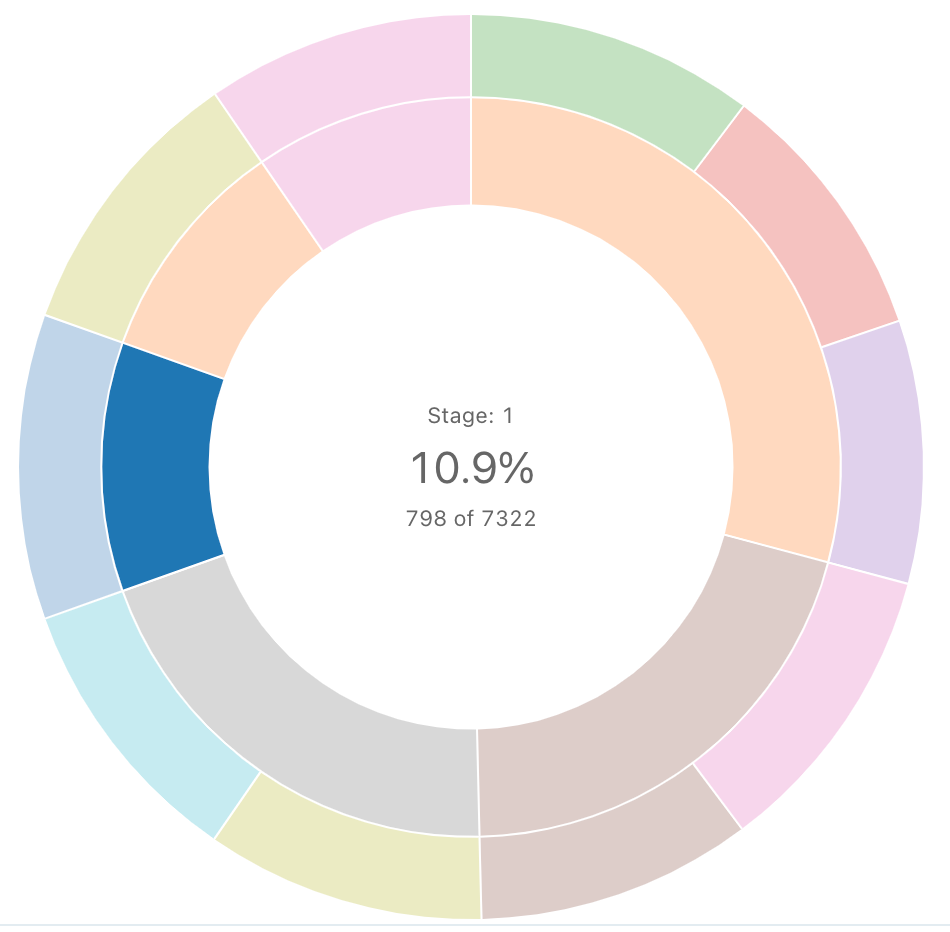
SQL 쿼리: 이 선버스트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
테이블
테이블 시각화는 데이터를 표준 테이블에 표시하지만 데이터를 수동으로 다시 정렬, 숨기기 및 서식을 지정할 수 있습니다. 테이블 옵션을 확인하세요.
참고 항목
테이블 시각화는 결과 집합 내의 데이터를 집계하지 않습니다. 모든 집계는 쿼리 자체 내에서 계산되어야 합니다.
테이블 구성 옵션은
Word Cloud(워드 클라우드)
단어 클라우드는 데이터에서 단어가 발생하는 빈도를 시각적으로 나타냅니다.
참고 항목
Word Cloud는 최대 64,000개의 행에 대한 집계만 지원합니다. 데이터 세트가 64,000개 행보다 크면 데이터가 잘립니다.
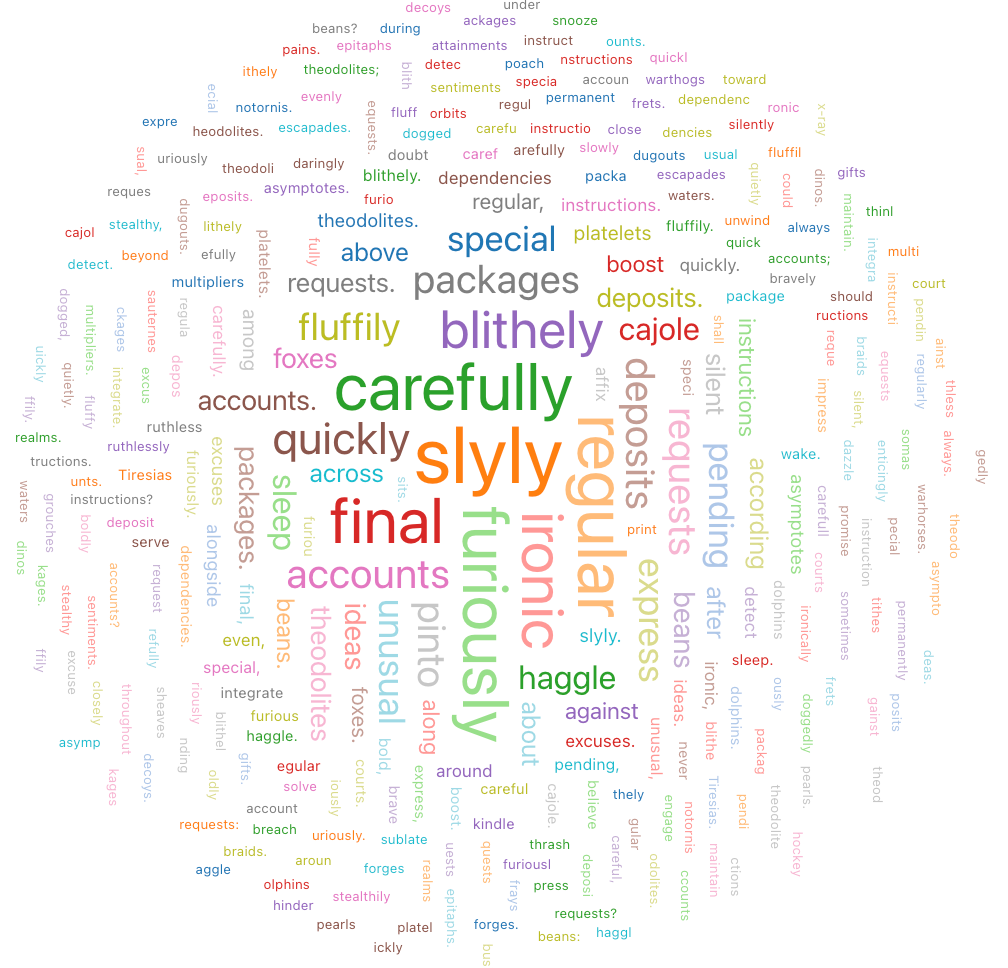
구성 값: 이 단어 클라우드 시각화를 위해 다음과 같은 값이 설정되었습니다: test
- 단어 열(데이터 세트 열):
o_comment - 단어 길이 제한: 최소 = 5
- 빈도 제한: 최소 = 2
SQL 쿼리: 이 단어 클라우드 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
select * from samples.tpch.orders