Spark 작업 간 간격
따라서 작업 타임라인에 다음과 같은 간격이 표시됩니다.
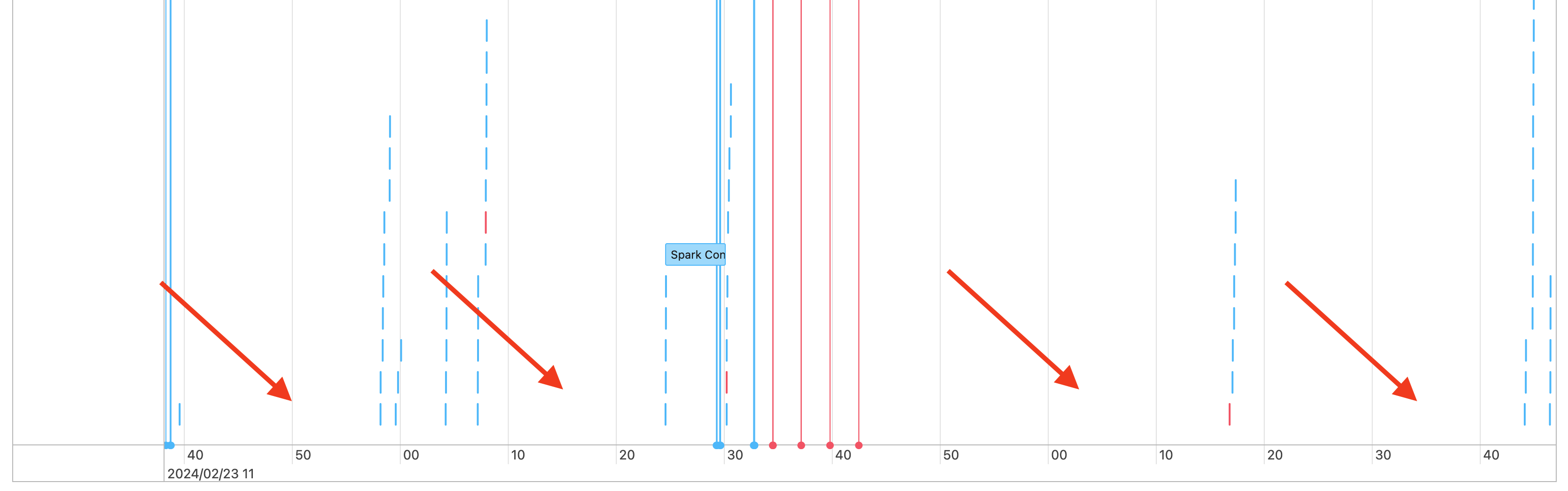
이런 일이 일어날 수 있는 몇 가지 이유가 있습니다. 간격이 워크로드에 소요된 시간의 높은 비율을 구성하는 경우 이러한 간격의 원인과 예상되는지 여부를 파악해야 합니다. 간격 중에 발생할 수 있는 몇 가지 사항이 있습니다.
- 수행할 작업이 없습니다.
- 드라이버가 복잡한 실행 계획을 컴파일하고 있습니다.
- Spark가 아닌 코드 실행
- 드라이버가 오버로드됨
- 클러스터가 오작동하고 있습니다.
작업 없음
다목적 컴퓨팅에서 수행할 작업이 없다는 것이 간격에 대한 가장 가능성이 높은 설명입니다. 클러스터가 실행 중이고 사용자가 쿼리를 제출하므로 간격이 예상됩니다. 이러한 간격은 쿼리 제출 사이의 시간입니다.
복잡한 실행 계획
예를 들어 루프에서 사용하는 withColumn() 경우 매우 비용이 많이 드는 처리 계획을 만듭니다. 격차는 운전자가 단순히 계획을 구축하고 처리하는 데 소비하는 시간이 될 수 있습니다. 이 경우 코드 단순화를 시도합니다. selectExpr()을 사용하여 다중 withColumn() 호출을 하나의 식으로 결합하거나 코드를 SQL로 변환합니다. Python을 사용해서 문자열 함수가 있는 쿼리를 조작하여 Python 코드에 SQL을 포함할 수 있습니다. 이렇게 하면 이러한 유형의 문제가 해결되는 경우가 많습니다.
Spark가 아닌 코드 실행
Spark 코드는 SQL로 작성되거나 PySpark와 같은 Spark API를 사용합니다. Spark가 아닌 코드의 실행은 타임라인에 간격으로 표시됩니다. 예를 들어 Python에서 네이티브 Python 함수를 호출하는 루프가 있을 수 있습니다. 이 코드는 Spark에서 실행되지 않으며 타임라인에 간격으로 표시할 수 있습니다. 코드가 Spark를 실행하고 있는지 확실하지 않은 경우 Notebook에서 대화형으로 실행해 보세요. 코드에서 Spark를 사용하는 경우 셀 아래에 Spark 작업이 표시됩니다.

또한 셀 아래에 있는 Spark 작업 드롭다운을 확장하여 작업이 현재 실행 중인지 확인할 수 있습니다(Spark가 유휴 상태인 경우). Spark를 사용하지 않는 경우 셀 아래에 Spark 작업이 표시되지 않거나 활성 상태임을 알 수 있습니다. 코드를 대화형으로 실행할 수 없는 경우 코드에서 로깅을 시도하고 타임스탬프를 통해 코드 섹션과 간격을 일치시킬 수 있는지 확인할 수 있지만 이는 까다로울 수 있습니다.
비 Spark 코드를 실행하여 타임라인에 간격이 표시되는 경우 이는 작업자가 모두 유휴 상태이며 간격 중에 돈을 낭비할 가능성이 있음을 의미합니다. 의도적이고 불가피한 작업일 수도 있지만 Spark를 사용하기 위해 이 코드 작성이 가능한 경우 클러스터를 완전히 활용하게 됩니다. Spark를 사용하여 작업하는 방법을 알아보려면 이 자습서로 시작하세요.
드라이버가 오버로드됨
드라이버가 오버로드되었는지 확인하려면 클러스터 메트릭을 확인해야 합니다.
클러스터가 DBR 13.0 이상인 경우 이 스크린샷에 강조 표시된 메트릭을 클릭합니다.
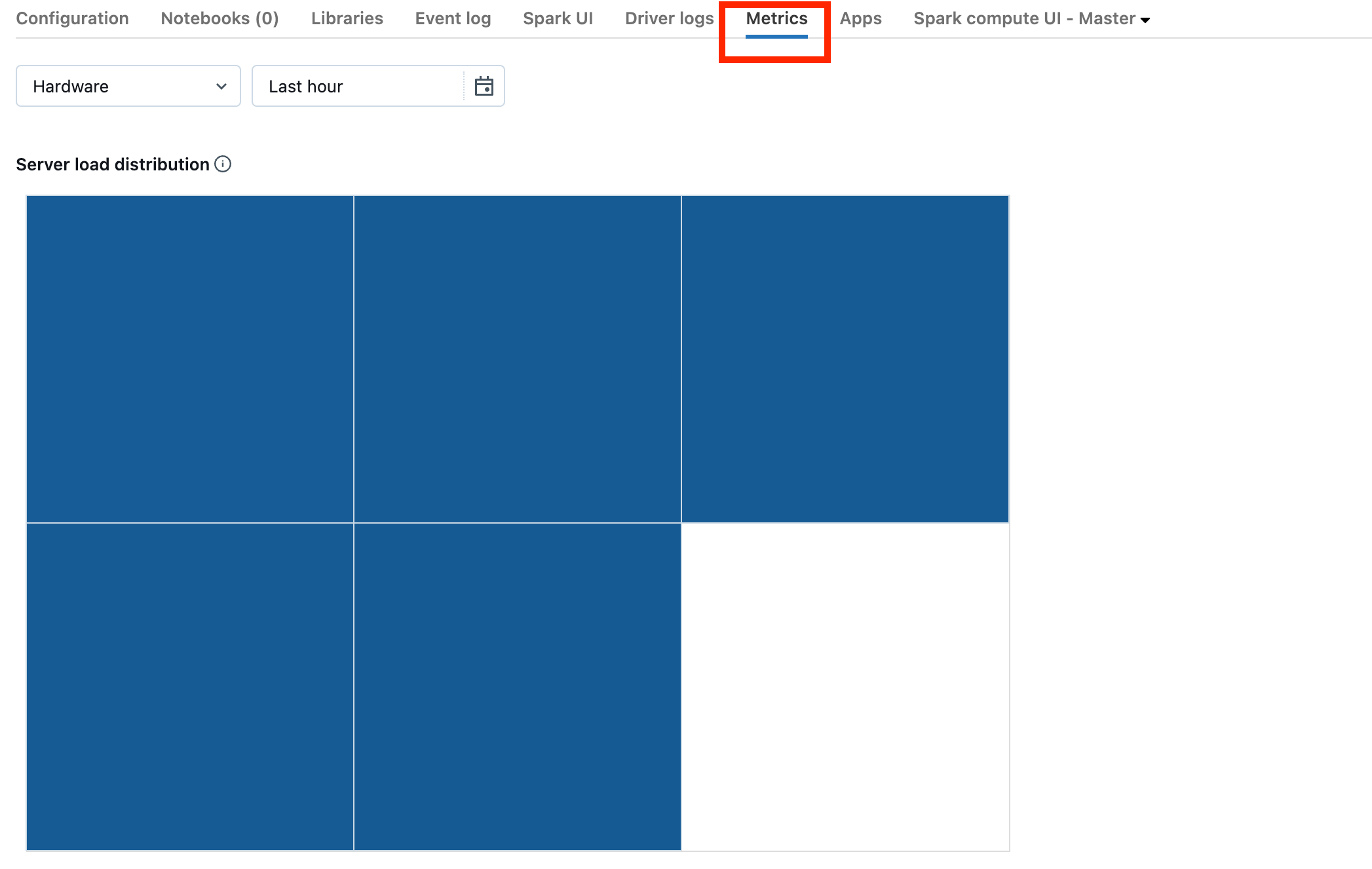
서버 부하 분산 시각화를 확인합니다. 드라이버가 많이 로드되었는지 확인해야 합니다. 이 시각화에는 클러스터의 각 컴퓨터에 대한 색 블록이 있습니다. 빨간색은 많이 로드되고 파란색은 전혀 로드되지 않음을 의미합니다.
이전 스크린샷은 기본적으로 유휴 클러스터를 보여줍니다. 드라이버가 오버로드되면 다음과 같이 표시됩니다.
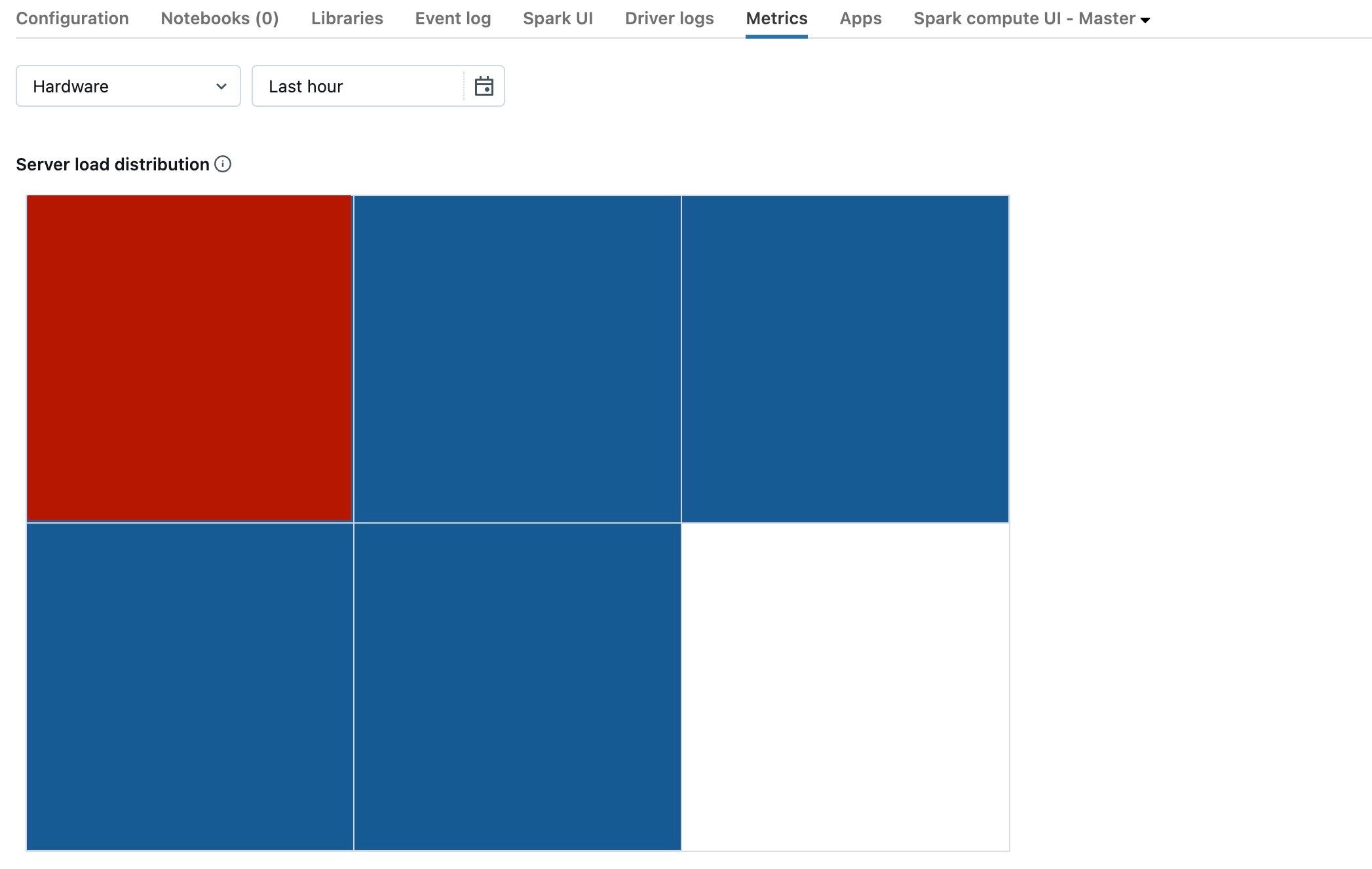
한 사각형은 빨간색이고 다른 사각형은 파란색임을 알 수 있습니다. 빨간색 사각형 위로 마우스를 굴려 빨간색 블록이 드라이버를 나타내는지 확인합니다.
오버로드된 드라이버를 수정하려면 오버로드된 Spark 드라이버를 참조하세요.
클러스터가 오작동하고 있습니다.
클러스터 오작동은 드물지만 이 경우 발생한 상황을 확인하기 어려울 수 있습니다. 클러스터를 다시 시작하여 문제가 해결되었는지 확인할 수 있습니다. 로그를 조사하여 의심스러운 항목이 있는지 확인할 수도 있습니다. 아래 스크린샷에서 강조 표시된 이벤트 로그 탭 및 드라이버 로그 탭은 다음을 확인할 수 있는 장소입니다.
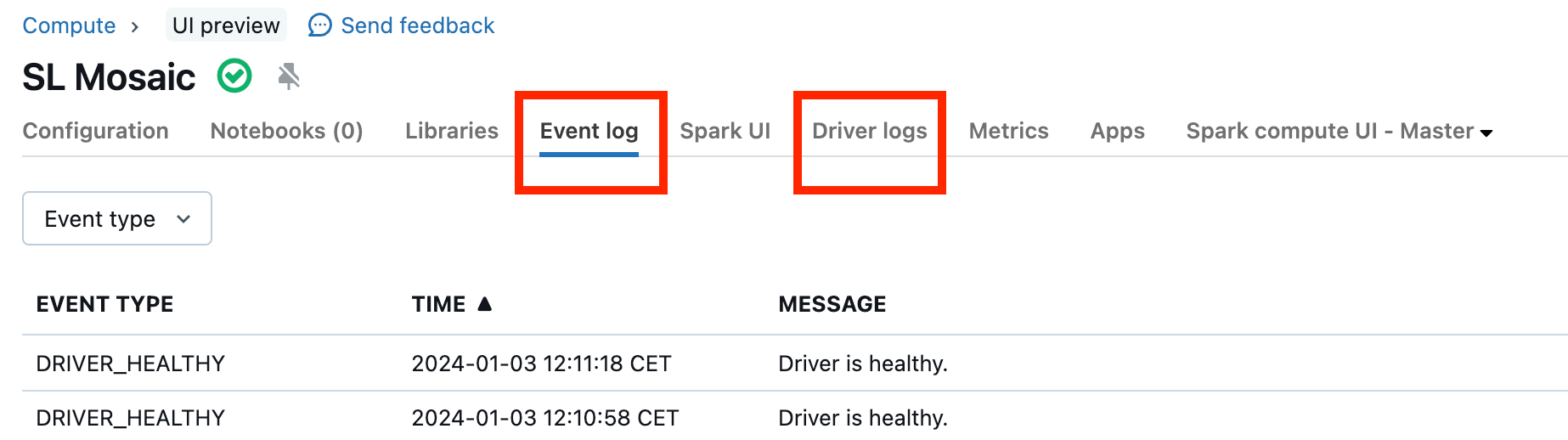
작업자의 로그에 액세스하기 위해 클러스터 로그 제공을 사용하도록 설정할 수 있습니다. 로그 수준을 변경할 수 있지만 Databricks 계정 팀에 도움을 요청해야 할 수도 있습니다.